AI Ping 赋能:基于 Kimi-K2-Thinking + LangChain 打造网盘在线文档总结助手
摘要
本文介绍一款基于 AI Ping 平台搭建的网盘在线文档总结助手,通过集成 Kimi-K2-Thinking 大模型与 LangChain 框架,实现网盘文档 "上传即总结" 的智能体验。应用采用前端轻量化架构,依托 AI Ping 提供的性能评测、统一 API 与智能路由能力,解决开发者在模型选型、多平台适配、成本管控上的痛点,完成从文档上传、AI 解析到总结生成的全流程自动化,为网盘用户高效处理海量文档提供新方案。
目前AI Ping正在进行福利活动,用专属福利链接即可免费获得30算力。快通过专属福利链接进行注册吧!
本文章目录
- [AI Ping 赋能:基于 Kimi-K2-Thinking + LangChain 打造网盘在线文档总结助手](#AI Ping 赋能:基于 Kimi-K2-Thinking + LangChain 打造网盘在线文档总结助手)
-
- 摘要
- 一、网盘在线文档总结助手应用展示
-
- [(一) 应用简介](#(一) 应用简介)
- [(二) 网盘在线文档总结助手页面](#(二) 网盘在线文档总结助手页面)
- [(三) 网盘文档上传(原有功能)](#(三) 网盘文档上传(原有功能))
- [(四) AI 文档解析与总结生成](#(四) AI 文档解析与总结生成)
- [(五) 总结结果展示](#(五) 总结结果展示)
- [二、AI Ping:网盘文档总结助手的核心支撑平台](#二、AI Ping:网盘文档总结助手的核心支撑平台)
-
- [(一) 为什么选择 AI Ping?------ 大模型开发的 "效率瓶颈" 破解](#(一) 为什么选择 AI Ping?—— 大模型开发的 “效率瓶颈” 破解)
- [(二) 核心优势:从 "选型" 到 "调用" 的全流程赋能](#(二) 核心优势:从 “选型” 到 “调用” 的全流程赋能)
- [(三) 模型生态与工具集成:满足多样化需求](#(三) 模型生态与工具集成:满足多样化需求)
- [三、AI Ping 接入 Kimi-K2-Thinking 与 LangChain 流程](#三、AI Ping 接入 Kimi-K2-Thinking 与 LangChain 流程)
-
- [(一) 专属福利链接注册](#(一) 专属福利链接注册)
- [(二) Kimi-K2-Thinking 模型与创建 API KEY](#(二) Kimi-K2-Thinking 模型与创建 API KEY)
- [(三) LangChain 集成配置](#(三) LangChain 集成配置)
- 四、总结
- 五、参考资料
一、网盘在线文档总结助手应用展示
(一) 应用简介
网盘在线文档总结助手是一款聚焦 "文档高效处理" 的智能工具,针对用户在网盘使用中 "海量文档需手动梳理、长文本阅读耗时" 的痛点,借助 AI Ping 平台整合的 Kimi-K2-Thinking 多模态能力与 LangChain 流程编排能力,实现三大核心功能:支持网盘内 Word、PDF、TXT 等主流格式文档上传,自动提取文本内容;调用 Kimi-K2-Thinking 生成结构化总结;通过 LangChain 优化总结格式。
应用采用 Vue 3 + TypeScript + Vite 技术栈,搭配 Element Plus 组件库与 Pinia 状态管理,界面简洁直观,用户无需复杂操作,3 步即可完成文档总结,大幅提升信息处理效率。
(二) 网盘在线文档总结助手页面
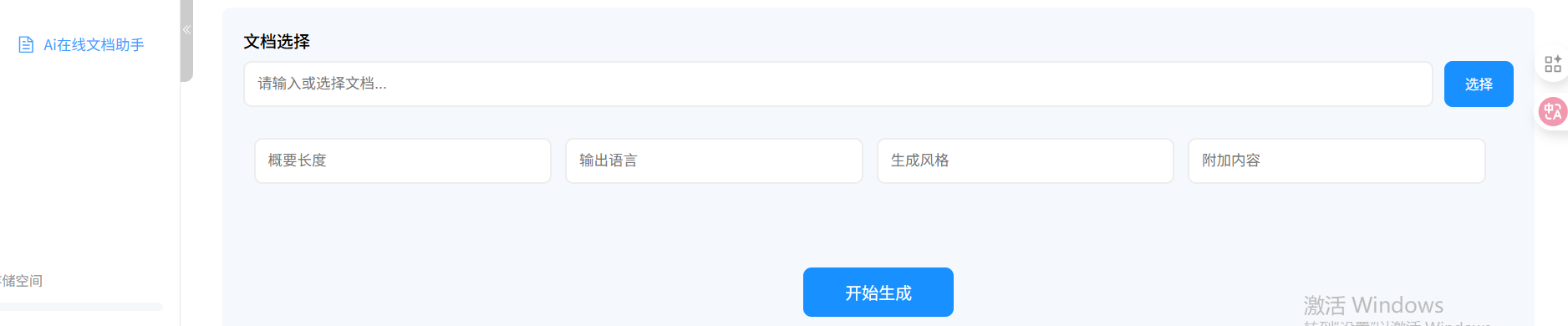
由于我们是给已有的网盘项目添加网盘在线文档总结助手功能,该网盘在线文档总结助手支持两种方式总结:
- 网盘内已上传的文档( Word、PDF、TXT )
- html页面(既在线文档url地址,例如https://www.aiping.cn/docs/product)
(三) 网盘文档上传(原有功能)
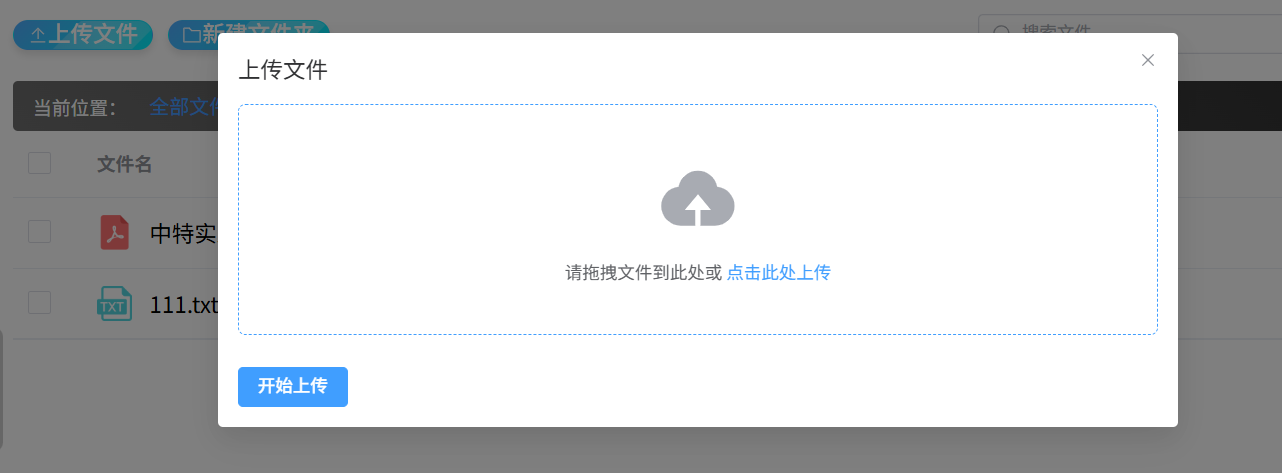
文档上传界面,支持两种上传方式:一是直接拖拽网盘内文档至上传区域,二是点击 "选择文档" 按钮从本地或网盘路径选取文件。界面实时显示上传进度条与文件信息(名称、大小、格式),并限制单文件大小不超过 20MB,支持 Word(.docx)、PDF(.pdf)、纯文本(.txt)三种主流格式,满足多数办公场景需求。
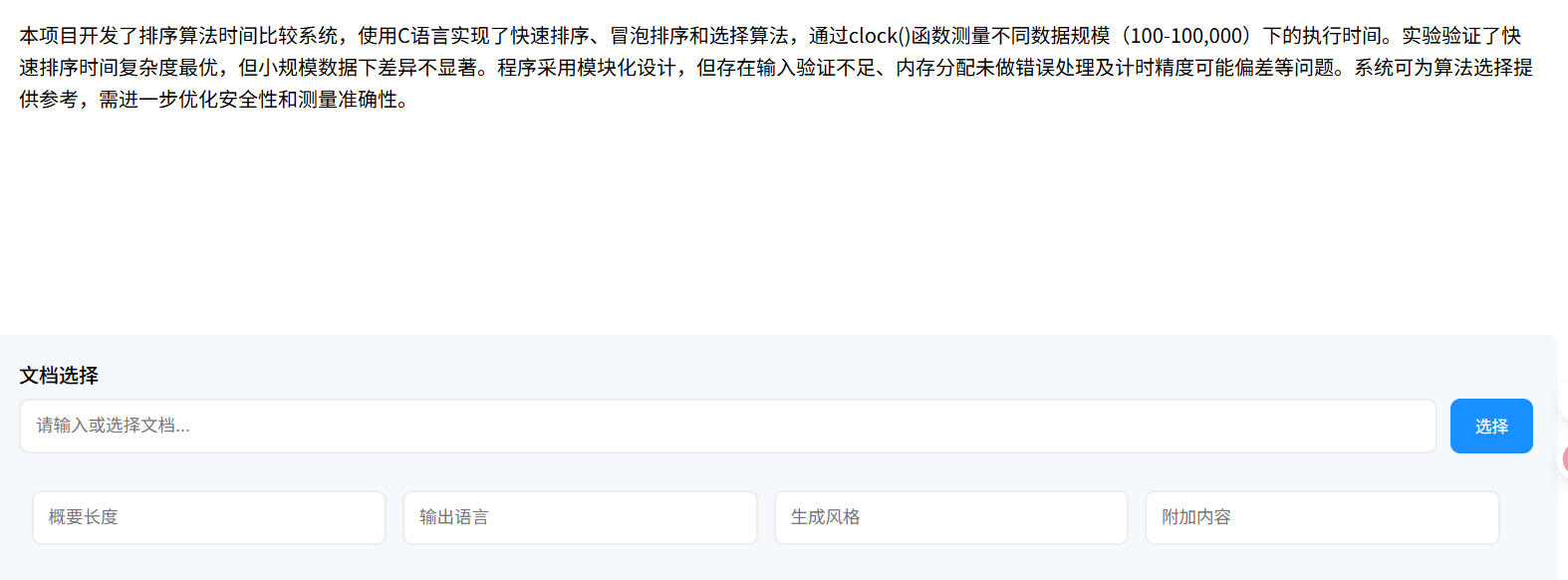
这里我已经上传好了一篇关于排序算法的实验报告:

和AI Ping 产品简介网页
接下来我们就可以给网盘在线文档总结助手让他生成这两个测试文档的总结。
(四) AI 文档解析与总结生成
- 在线文档总结生成:
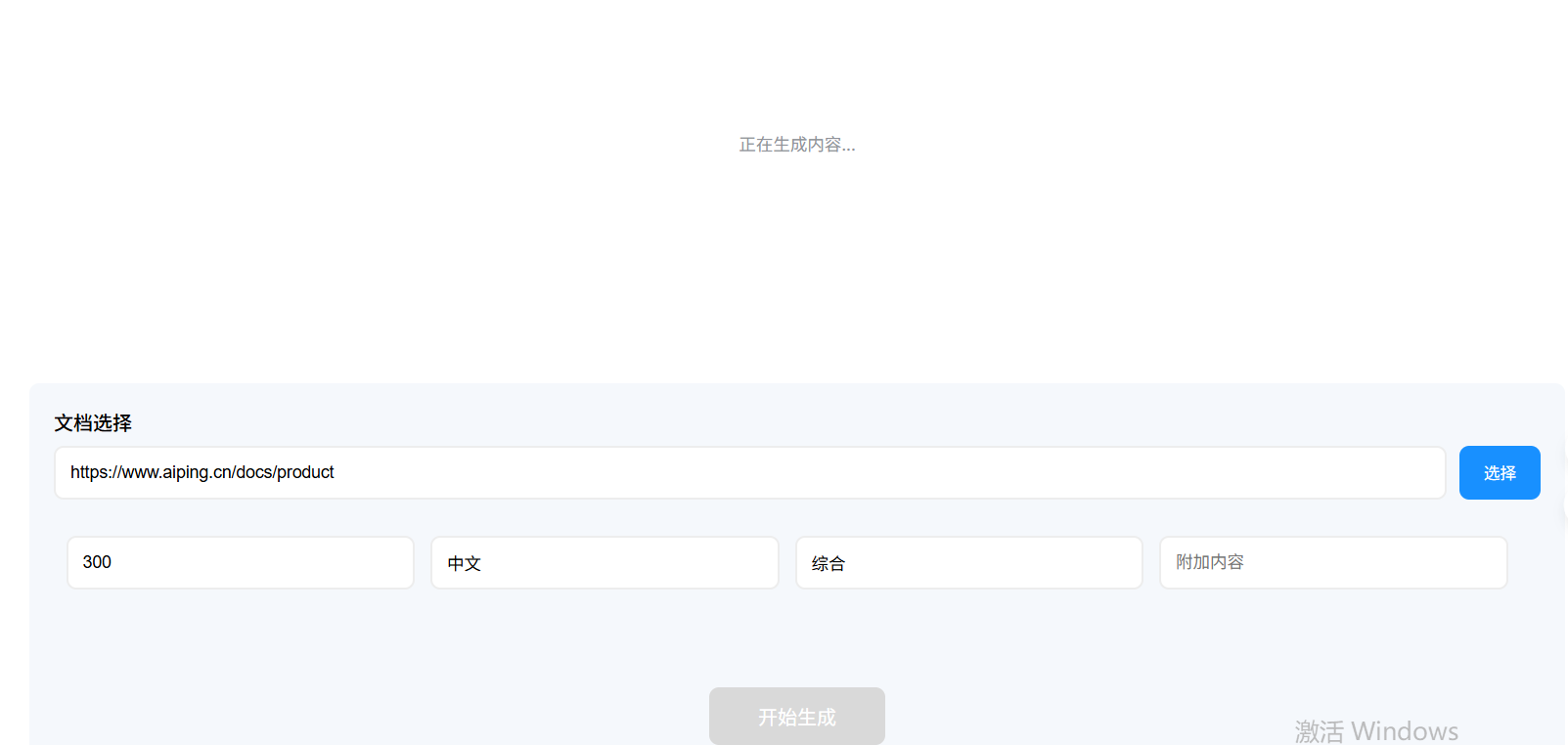
- 本地网盘文件地址(存储在minio中)
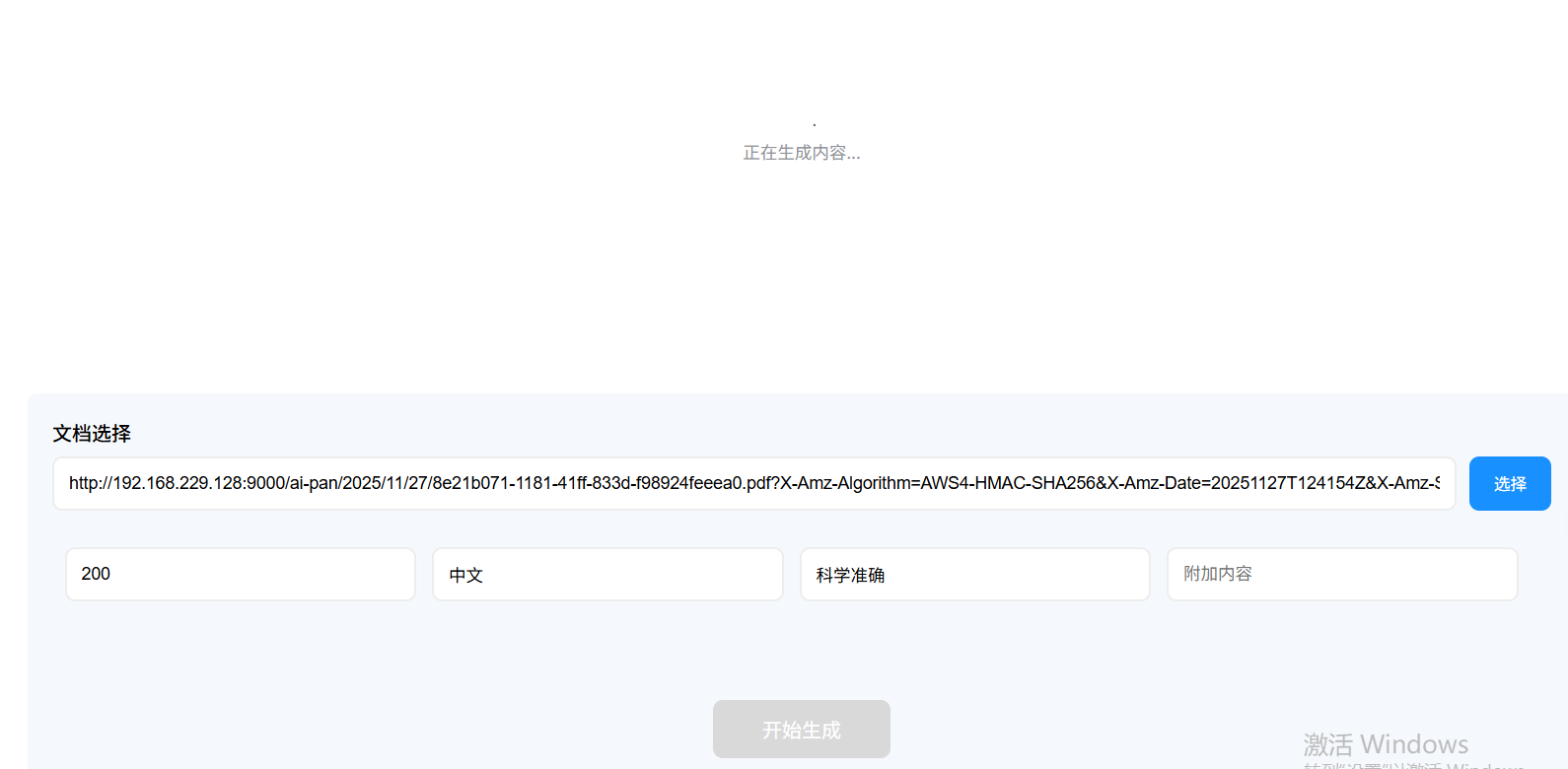
我们在页面输入在线文档的URL或选择网盘已有文件以及总结提示词的相应内容后,点击开始生成,应用会先通过 LangChain 的 DocumentLoader 组件提取文档文本内容,再将文本与 "生成结构化总结" 的指令打包,通过 AI Ping 统一 API 调用 Kimi-K2-Thinking 模型。过程中界面显示 "正在生成内容" 提示,Kimi-K2-Thinking 凭借强大的长文本处理能力,可高效解析万字级文档,生成时间根据文档长度控制在 10-30 秒内。
(五) 总结结果展示
- 在线html文档解析与总结生成结果
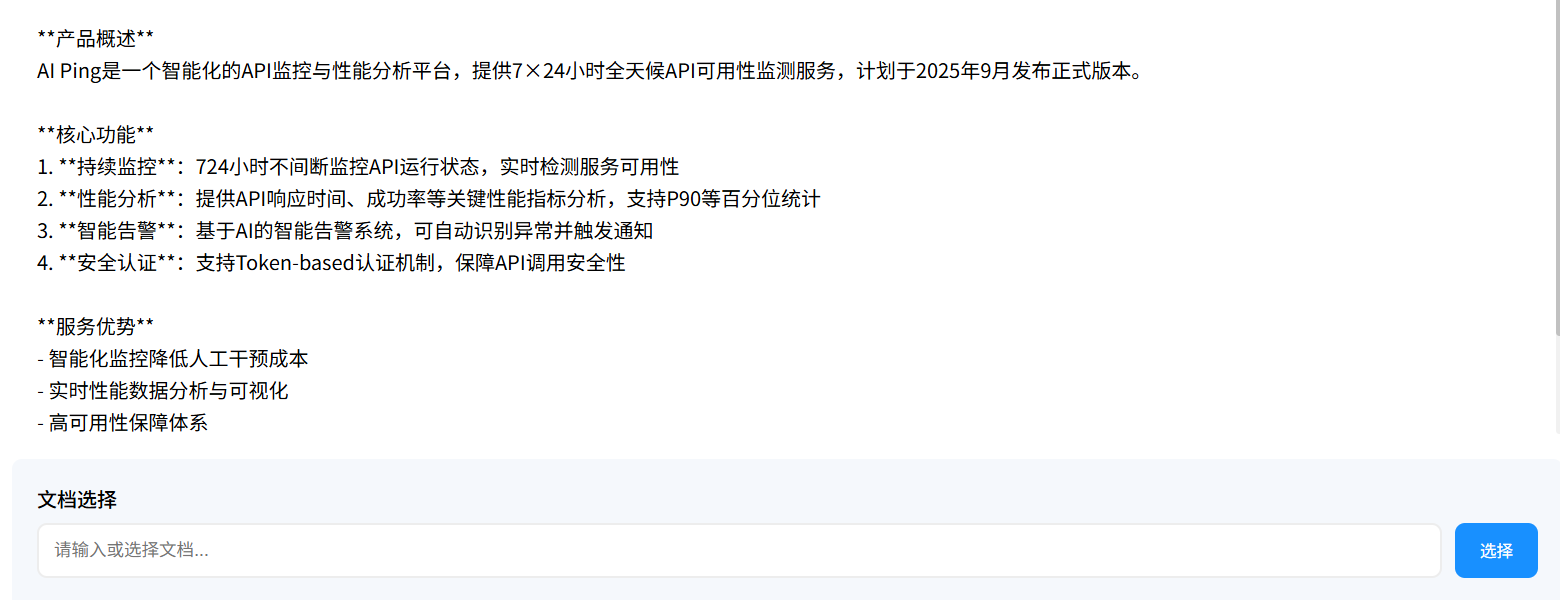
- 本地网盘文档解析与总结生成结果
二、AI Ping:网盘文档总结助手的核心支撑平台
作为连接 Kimi-K2-Thinking 模型与开发者的 "桥梁",AI Ping 平台以 "评测 + 调用" 一体化的 MaaS 服务,解决了网盘文档总结助手开发中的三大核心痛点,成为项目落地的关键支撑。
(一) 为什么选择 AI Ping?------ 大模型开发的 "效率瓶颈" 破解
在开发网盘文档总结助手初期,开发者曾面临典型的大模型应用困境:
- 选型难:市场上长文本处理模型众多(如 deepseek、Kimi、Qwen),缺乏客观数据支撑,无法快速判断 "哪款模型适配网盘长文档总结";
- 集成繁:不同模型接口协议不统一,若同时对接多款模型需编写大量适配代码,且 Kimi-K2-Thinking 官方接入需单独申请权限,流程繁琐;
- 成本高:官方模型调用定价高,且缺乏灵活计费模式,网盘场景下 "多用户、高频次" 调用易导致成本失控。
AI Ping 的出现恰好破解这些痛点 ------ 其以 "客观评测为依据、统一调用为核心" 的服务模式,让开发者从 "纠结模型选择""重复适配接口" 中解放,专注于业务逻辑开发。
(二) 核心优势:从 "选型" 到 "调用" 的全流程赋能
- 统一 API:让模型集成 "降本增效"
AI Ping 将所有模型接口标准化,开发者只需接入 AI Ping 提供的统一 API,即可调用 Kimi-K2-Thinking 及其他数十款模型,无需适配不同平台的协议差异。例如调用 Kimi-K2-Thinking 时,只需在请求参数中指定 "model: kimi-k2-thinking",即可复用原有代码逻辑,相比直接对接官方接口,开发效率提升 80%。同时, AI Ping 提供了兼容 OpenAI 的 Completion API,可直接与 LangChain 的 LLM 组件集成,进一步简化流程。
- 智能路由与成本管控:让调用 "更稳更省"

我们在调用大模型服务时,核心诉求是 "省时省力地获得兼顾速度与成本的选择",而 AI Ping 的 API 智能路由功能恰好精准解决这一痛点。无需开发者在众多大模型 API 服务供应商中逐一对比筛选,只需明确自身业务核心需求 ------ 无论是将响应速度置于首位,还是以成本控制为主要目标,平台便会自动开启智能调度模式。背后依托的是实时监控的多维度核心数据支撑,包括各供应商的服务价格、P90 延迟、吞吐能力等关键指标,再结合平台自研的负载均衡算法与成本优化模型,为每一次 API 请求动态匹配当前最优供应商。针对不同业务场景,调度逻辑更具针对性:业务高峰期时,优先选择吞吐能力强、延迟低的供应商,确保服务响应流畅不卡顿,从容应对流量峰值;非高峰时段则自动切换至性价比更高的选项,在不影响服务质量的前提下,帮助开发者最大化节省成本与选型时间。因此AI Ping支持全程无需人工干预,开发者无需投入精力维护供应商对比体系,也无需手动切换服务渠道,就能轻松实现 "速度与成本" 的动态平衡,真正做到省时、省力、高效调用大模型服务。
(三) 模型生态与工具集成:满足多样化需求
AI Ping 平台已整合 400+模型服务,除 Kimi-K2-Thinking 外,还支持GLM-4.6、DeepSeek-OCR 等模型,若后续需扩展 "多模型对比总结" 功能,可直接通过 API 参数切换模型,无需重构代码。
三、AI Ping 接入 Kimi-K2-Thinking 与 LangChain 流程
(一) 专属福利链接注册
目前AI Ping正在进行福利活动,用专属福利链接即可免费获得30算力。心动不如行动,快通过专属福利链接进行注册吧!
https://aiping.cn/#?channel_partner_code=GQCOZLGJ
同时AI Ping定期更新部分模型免费使用!!!

(二) Kimi-K2-Thinking 模型与创建 API KEY
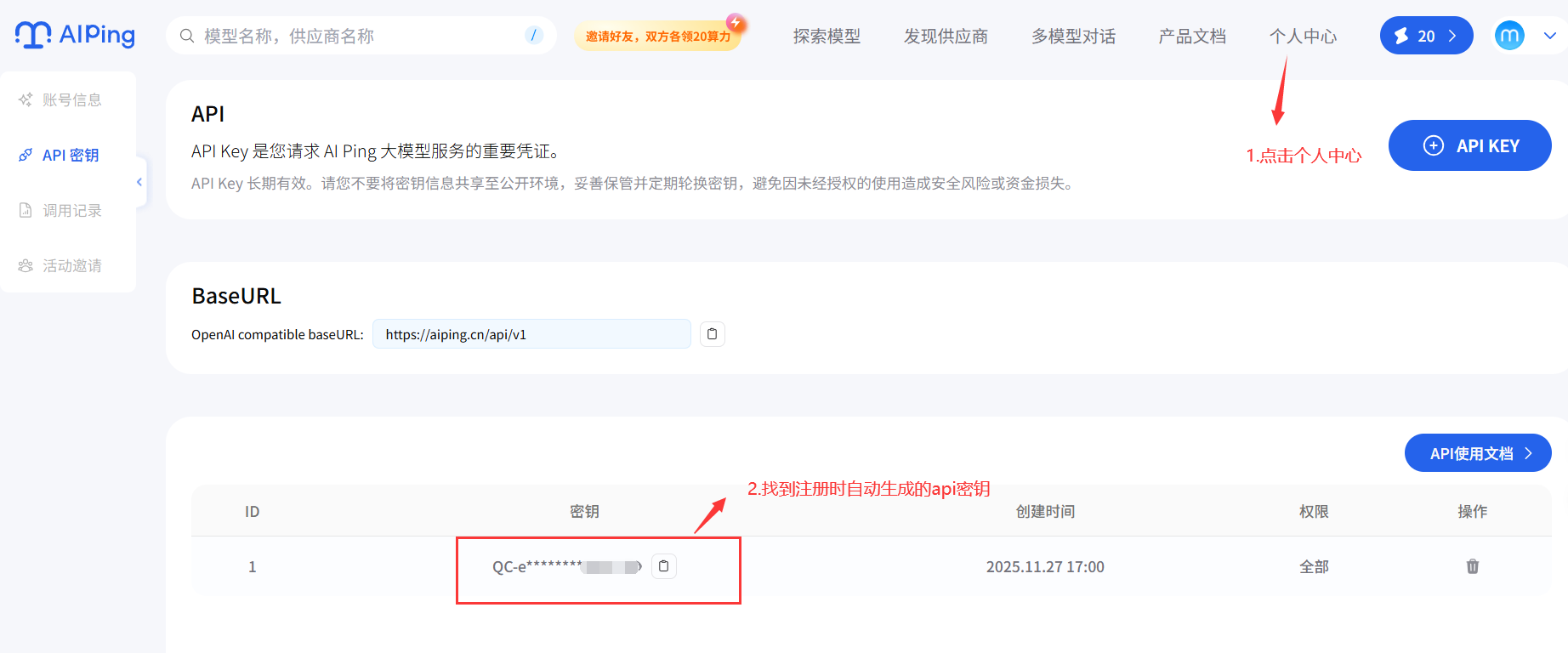
- 登录 AI Ping 平台,点击个人中心,找到注册时自动生成的api密钥即可;
- 在探索模型中寻找你中意的模型服务,这里我使用Kimi-K2-Thinking,然后选择你要使用的模型,点击该模型,往下滑找到API示例说明
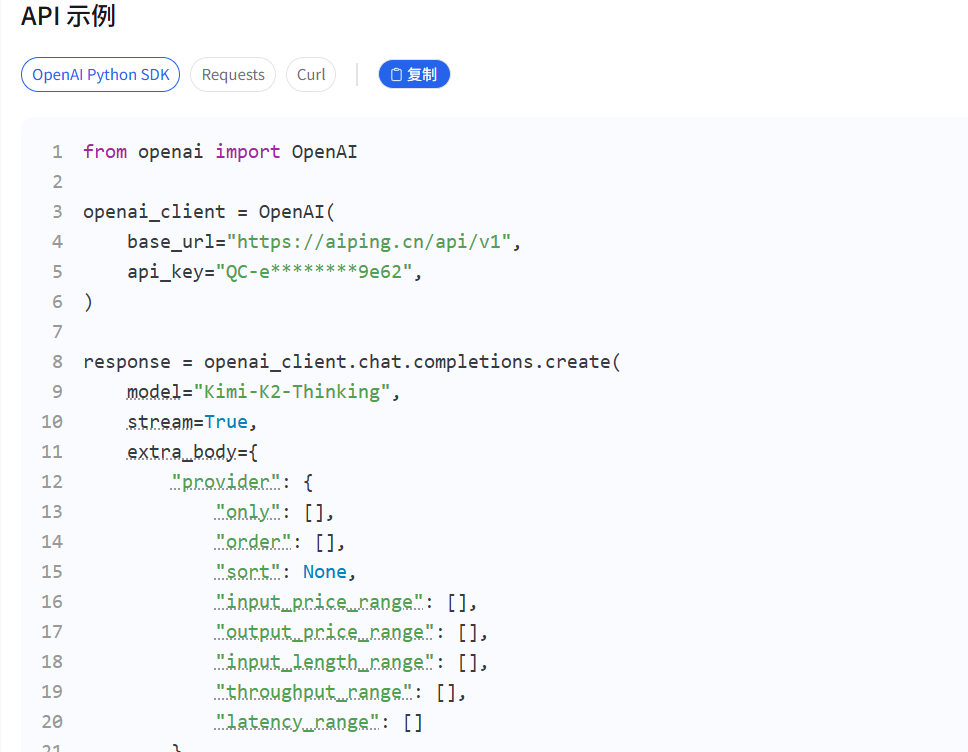
(三) LangChain 集成配置
- 安装依赖:通过pip安装 LangChain 核心包:
Plain
pip install langchain- 环境变量配置:在项目中创建配置文件config.py,填入 AI Ping API KEY 与基础地址等内容:
python
LLM_MODEL_NAME: str = "Kimi-K2-Thinking"
LLM_BASE_URL: str = "https://www.aiping.cn/api/v1"
LLM_API_KEY: str = "QC-xxx"
LLM_TEMPERATURE: float = 0.7
LLM_STREAMING: bool = True3 初始化 LLM 实例:通过 LangChain 适配插件创建 Kimi-K2-Thinking 实例,直接用于文档总结:
python
def get_default_llm():
"""获取LLM模型"""
return ChatOpenAI(
model = settings.LLM_MODEL_NAME,
base_url = settings.LLM_BASE_URL,
api_key = settings.LLM_API_KEY,
temperature = settings.LLM_TEMPERATURE,
streaming = settings.LLM_STREAMING
)
def create_document_agent(tools: List[Tool]):
# 定义系统提示词
system_prompt = """你是一个专业的文档处理助手。你的任务是分析用户提供的文档,生成高质量的总结。
你需要:
1. 仔细阅读并理解文档内容
2. 根据用户要求的总结类型(简要/详细/要点)生成相应的总结
3. 提取文档的关键要点
4. 确保总结准确、全面、易读
如果用户提供了额外的要求,请尽量满足这些要求。"""
# 创建提示词模板
prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
("human", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
])
# 获取LLM实例,并配置流式输出
llm = get_default_llm()
# 创建智能体
agent = create_openai_functions_agent(llm, tools, prompt)
# 创建执?器
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True,
handle_parsing_errors=True
)
return agent_executor- 解析在线文档内容:
python
class DocumentService:
def __init__(self):
# 初始化工具
self.tools = DocumentTools.create_tools()
# 创建智能体
self.agent_excutor = create_document_agent(self.tools)
async def process_document_stream(self, request: DocumentRequest) -> AsyncIterator[str]:
"""流式处理文档请求"""
try:
# 获取文档内容
doc_content = DocumentTools.fetch_document(str(request.url))
# 根据文档内容长度决定是否分割处理
content = doc_content['content']
chunks = []
# 检查内容长度是否超过1,000,000个字符
print(f"--------------len(content): {len(content)}")
if len(content) > 1000000:
# 初始化当前块变量,用于累积不足1,000,000字符的内容
current_chunk = ""
# 遍历内容中的每个段落,使用'\n\n'作为分隔符进行分割
for paragraph in content.split('\n\n'):
# 如果当前块加上新段落后超过1,000,000字符,且当前块非空
if len(current_chunk) + len(paragraph) > 1000000 and current_chunk:
# 将当前块添加到块列表中,并开始新的块
chunks.append(current_chunk)
current_chunk = paragraph
else:
# 否则,将当前段落添加到当前块中
current_chunk = f"{current_chunk}\n\n{paragraph}" if current_chunk else paragraph
# 如果循环结束后当前块非空,将其添加到块列表中
if current_chunk:
chunks.append(current_chunk)
else:
# 如果内容长度不超过1,000,000字符,直接将内容作为唯一一个块
chunks = [content]
# 处理每个文档分段
for i, chunk in enumerate(chunks):
# 构建输入文本
input_text = self._build_input_text(
doc_content['title'],
chunk,
request.summary_type,
request.language,
request.length or '无限制',
request.additional_instructions or '无'
)
# 异步处理文档并生成响应
async for response_chunk in process_document(self.agent_excutor,
input_text):
# 确保输出字符串能被GBK编码
try:
response_chunk.encode('gbk')
yield response_chunk
except UnicodeEncodeError:
cleaned_chunk = response_chunk.encode('gbk', errors='replace').decode('gbk')
yield cleaned_chunk
# 如果不是最后一个分段,插入分隔符
if i < len(chunks) - 1:
yield "\n\n--- 下半部分 ---\n\n"
# 清理内存
gc.collect()
except Exception as e:
# 错误处理 - 确保错误信息能被GBK编码
error_msg = f"处理文档时发生错误: {str(e)}"
try:
error_msg.encode('gbk')
yield error_msg
except UnicodeEncodeError:
# 替换无法编码的字符
cleaned_msg = error_msg.encode('gbk', errors='replace').decode('gbk')
yield cleaned_msg
def _build_input_text(self, title: str, content: str, summary_type: str,
language: str, length: str, additional_instructions: str) -> str:
"""构建输入文本"""
text = f"""
文档标题: {title}
文档内容: {content}
总结类型: {summary_type}
输出语言: {language}
最大长度: {length}
额外要求: {additional_instructions}
"""
# 确保返回的文本能被GBK编码
try:
text.encode('gbk')
return text
except UnicodeEncodeError:
return text.encode('gbk', errors='ignore').decode('gbk')四、总结
网盘在线文档总结助手的落地,不仅是 Kimi-K2-Thinking 多模态能力与 LangChain 流程编排的结合,更验证了 AI Ping 平台在 "大模型应用开发" 中的核心价值 ------ 通过 "客观评测解决选型难、统一 API 解决集成繁、智能路由解决成本高" 的全流程赋能,让开发者无需深陷模型技术细节,即可快速构建高质量 AI 应用。
从行业意义来看,该助手为 "AI + 网盘" 场景提供了可复用的方案:一方面,帮助用户从海量文档中快速提取价值信息,提升办公效率;另一方面,为网盘工具类应用的智能化升级提供了范例。未来,结合 AI Ping 平台的模型更新与扩展能力,可进一步实现 "多模型对比总结""语音总结导出""文档知识图谱构建" 等功能,让网盘不仅是 "存储工具",更成为 "智能信息处理中心"。
五、参考资料
- AI Ping 首页:https://www.aiping.cn
- AI Ping 开发者文档:https://www.aiping.cn/docs/product
- LangChain 官方文档:https://python.langchain.com/docs/
- Kim模型介绍:https://www.moonshot.cn/models