在 Apache Iceberg 的数据管理体系中,数据压缩(Compaction)是优化存储布局、提升查询性能的核心维护任务之一。通过 Binpack 重写策略、排序策略及 Z 序排序等机制,Iceberg 可高效合并小文件、重组数据分布,减少元数据冗余与查询扫描成本。本文结合表维护流程,深入解析 Compaction 的核心策略原理,以及过期快照清理、旧元数据删除、孤儿文件处理等配套机制,为优化 Iceberg 表存储效率提供实践指引。
原文:www.dremio.com/blog/compac...
Maintenance Tasks with Iceberg Tables
在 数据湖上使用 iceberg有很多好处,如 partition/schema evolution、time-travel、version rollback 等等
但数据摄取时会出现很多小问题,对于 hive 来说是很大问题,对于 ice-berg 可以用 压缩来解决
对于 任何表格式来说,都需要定期清理,确保元数据文件不要太多
iceberg提供 API的方式,可以
- expire snapshots
- remove old metadata files
- delete orphan files
Compaction
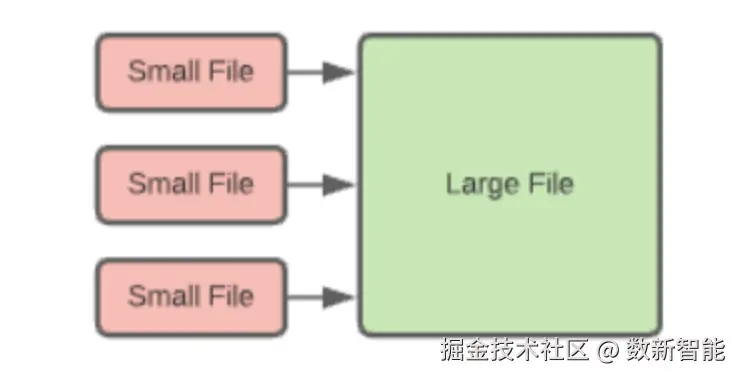
太多的小文件会导致性能问题,当执行压缩时
- 使用 rewriteDataFiles procedure 来做压缩,可以选择压缩的文件,以及期望的结果大小
- spark 会将这些小文件读取,然后合并压缩为大文件
- 之后是写 manifest files、manifest list、表元数据,最后提交这次修改到 catalog
之前的旧文件还在,但不会被查询到了,除非指定了 time-travel
 使用 RewriteDataFiles 来做压缩,支持 spark3 和 flink
使用 RewriteDataFiles 来做压缩,支持 spark3 和 flink
这里指定了 event_date,大于 7 天前的数据 sql 方式
sql 方式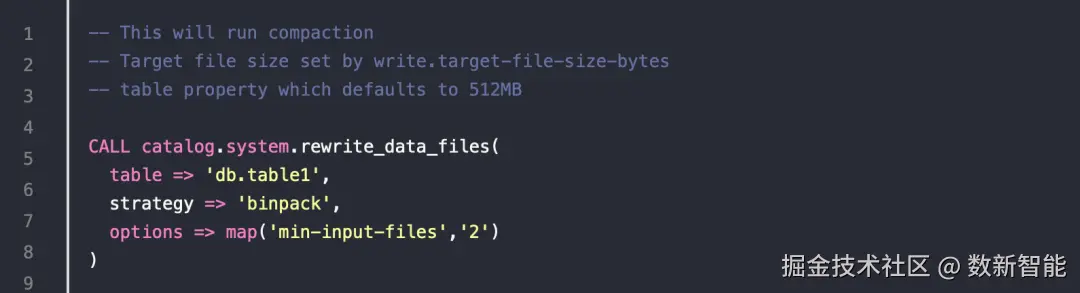
一些参数
- The table: Which table to run the operation on
- The strategy: Whether to use the "binpack" or "sort" strategy (each are elaborated upon in the sections below)
- Options: Settings to tailor how the job is run, for example, the minimum number of files to compact, and the minimum/maximum file size of the files to be compacted
其他参数
- Where: Criteria to filter files to compact based on the data in them (in case you only want to target a particular partition for compaction)
- Sort order: How to sort the data when using the "sort" strategy
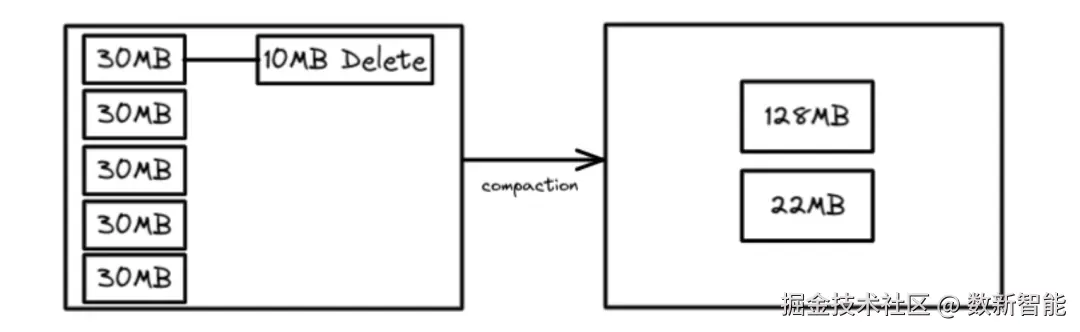
The Binpack Rewrite Strategy
这是默认的策略,将 很多小文件合并为目标大文件,没有再做其他优化了,所以压缩速度会很快 默认的目标 size 为 512M
默认的目标 size 为 512M
下面是压缩 最近一小时的数据
The Sort Strategy
除了压缩小文件,还做了排序,这意味着最小/最大过滤的好处将会更大(扫描的文件越少,速度越快)
未排序的压缩如下: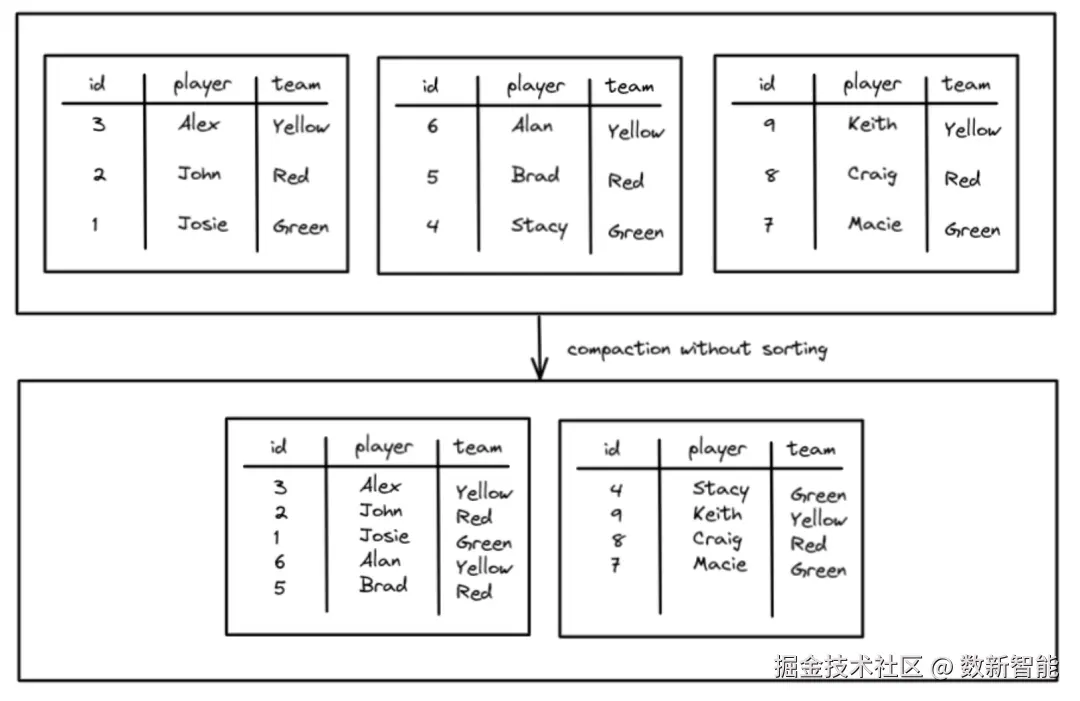 由于没有排序,查询时需要扫描两个文件,而经过排序之后,就可以减少扫描文件的数量
由于没有排序,查询时需要扫描两个文件,而经过排序之后,就可以减少扫描文件的数量 排序策略如下,增加了 sort_order 参数:
排序策略如下,增加了 sort_order 参数: 排序多个字段,以及如何对待 NULL
排序多个字段,以及如何对待 NULL
Z-Order Sorting
跟多列排序不一样,他是将所有列等值的对待
假设有 heigh_in_cm,以及 age,将他们记录到 四个象限中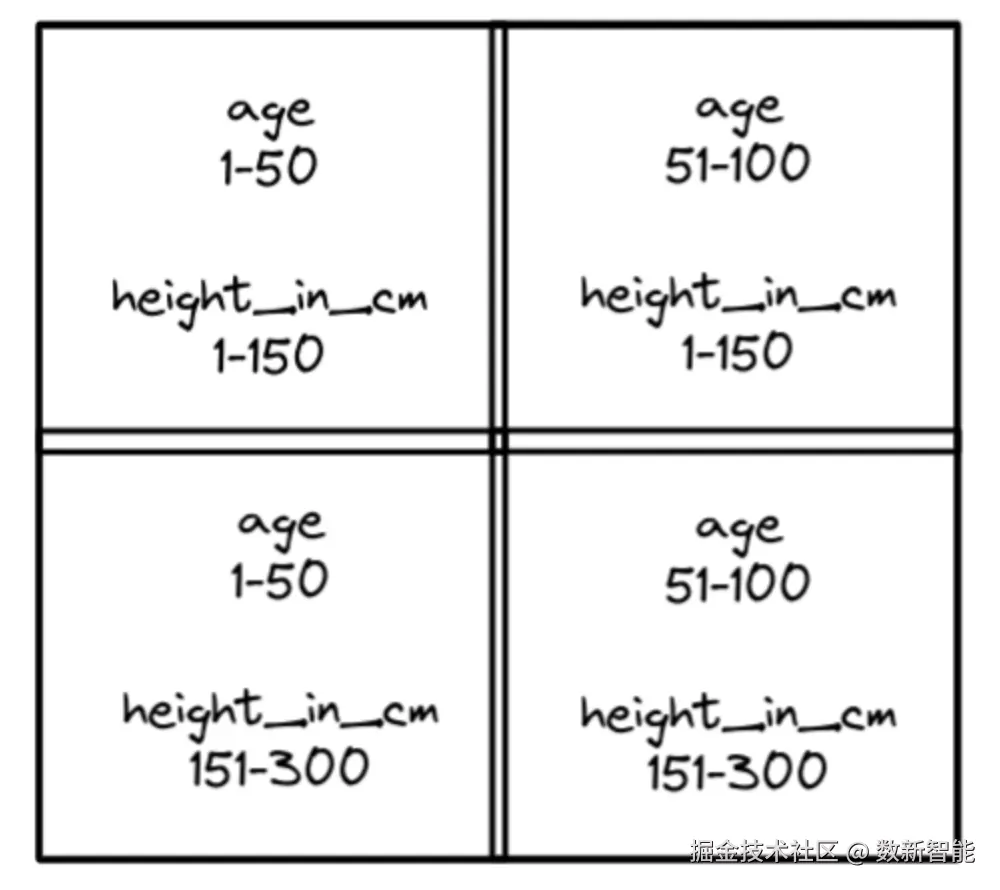 之后将所有的记录 put 到这四个象限中,并将他们写入到合适的文件中,这对于 min/max 来说很有益
之后将所有的记录 put 到这四个象限中,并将他们写入到合适的文件中,这对于 min/max 来说很有益
比如当你搜索 age = 25,高度未 200cm,这样只会定位到一个文件,也就是左下方的象限
z-order可以重复多次,在一个象限内创建另外四个象限,用户进一步微调集群,比如对左下进一步微调,就得到了下面这样: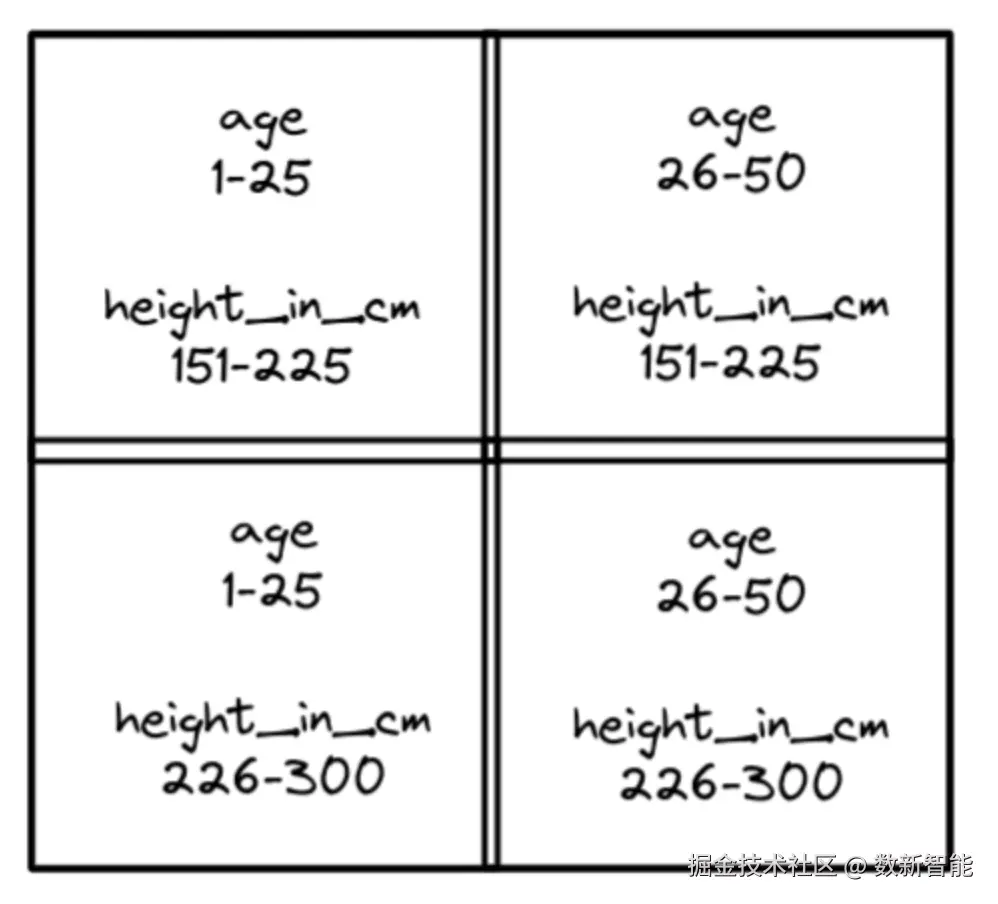 当运行 age 和 heigh_in_cm 查询时,可以有效的做裁剪,所以z-order适合多维度,也就是多个列同时查询
当运行 age 和 heigh_in_cm 查询时,可以有效的做裁剪,所以z-order适合多维度,也就是多个列同时查询
可以通过下面这样配置z-order压缩
Expire Snapshots
iceberg的有一个好处是,通过快照可以做 time-travel,verion rolback, 快照中的 manifest files不会被删除
当手动指定删除不需要的快照时,对应的 manifest list、manifest files、data files 都会被删除
如果这个 数据文件还被其他 有效的manifest files 关联,则不会被删除
孤儿文件不关联任何快照,需要用其他的方式将其删除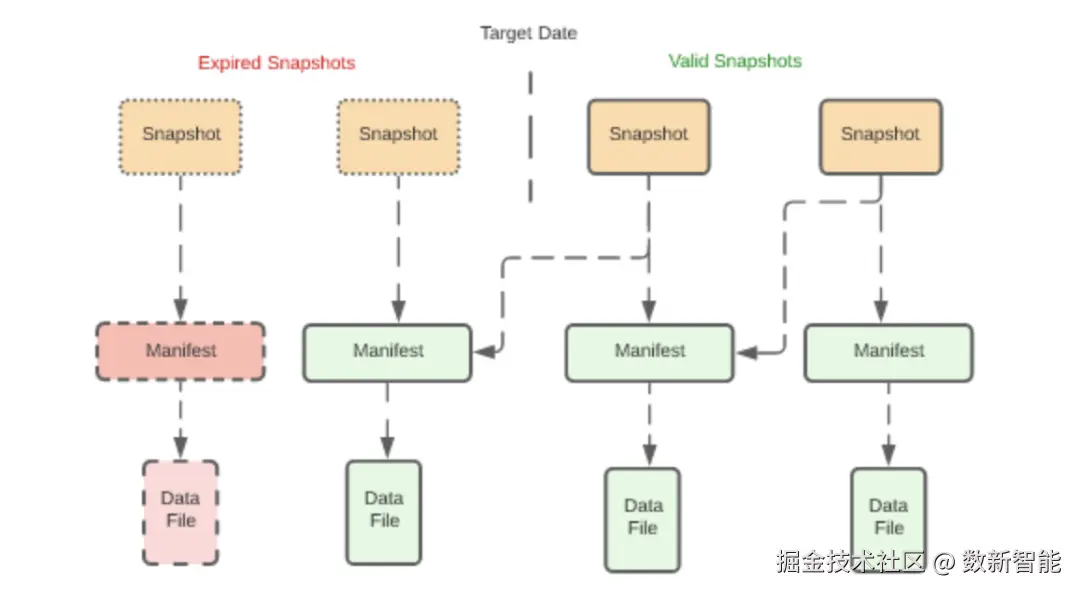 下面是 删除所有 tsToExpire 之前的快照,也可以指定删除任意处理的快照,或者快照 ID
下面是 删除所有 tsToExpire 之前的快照,也可以指定删除任意处理的快照,或者快照 ID
Removing Old Metadata files
Snapshot isolation 是iceberg中非常有用的一个特性
但流写入时,会出现很多新的小文件,删除过期文件可以将这些文件数据删除,但是处理不了 manifest 文件
iceberg 可以允许你设置开启 最老的 manifest 文件删除功能,当新的一个创建时,就会删除掉老的 manifest文件
还可以指定要保留的 manifest文件数量,下面是 保留 4 个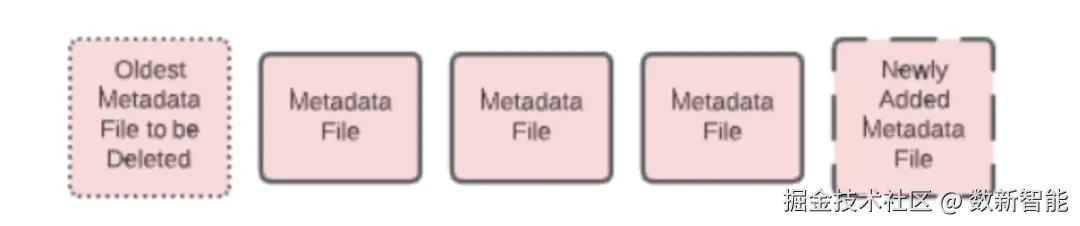 下面是设置删除最老的 manifest 文件,当新的创建时,默认为 false:
下面是设置删除最老的 manifest 文件,当新的创建时,默认为 false: 下面设置要保留多少个 manifest文件,默认为 100
下面设置要保留多少个 manifest文件,默认为 100
Delete Orphan Files
job、task执行失败,可能会导致写入了部分数据,这些数据没有任何关联任何快照,因此也不能用正常的方式删除他们,因为没有任何关联关系
正常的 快照过期,删除元数据都不行,需要用其他方式扫描表的目录,然后找到他们 deleteOrphanFiles 操作如下
deleteOrphanFiles 操作如下
这个操作是扫描每个有效的快照,然后找到哪些文件 关联了这些快照
对于在 数据目录中,没有被有效快照关联的文件,就可以被删除了
表的文件也可以存储在数据目录之外,因此需要定期的做清理
- olderThan,帮助预防删除正常处理的文件
- location,删除指定目录下的数据,这些数据不在 主数据目录中,肯恩是之前从其他地方迁移到 iceberg 中的
Reference
- How Z-Ordering in Apache Iceberg Helps Improve Performance
- What Is a Data Lakehouse?
- OneTable github
相关文章
- The Life of a Read/Write Query for Apache Iceberg Tables