大家好,又见面了,我是你们的朋友全栈君。
一、三范式
为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则。在关系型数据库中这种规则就称为范式。范式是符合某一种设计要求的总结。要想设计一个结构合理的关系型数据库,必须满足一定的范式。
1.第一范式
确保每列保持原子性
- 列不可分
- 有主键
根据实际需求来定。比如某些数据库系统中需要用到"地址"这个属性,本来直接将"地址"属性设计成一个数据库表的字段就行。但是如果系统经常会访问"地址"属性中的"城市"部分,那么就非要将"地址"这个属性重新拆分为省份、城市、详细地址等多个部分进行存储,这样在对地址中某一部分操作的时候将非常方便。这样设计才算满足了数据库的第一范式,如下表所示。
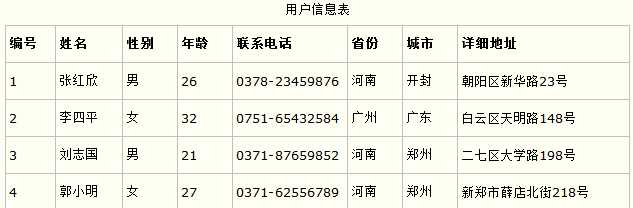
2.第二范式
确保表中的每列都和主键相关
- 每个表只描述一件事
- 主要针对联合主键而言,不存在部分依赖,每一列都跟联合主键有关系,而与联合主键中的其中一个键无关系
比如要设计一个订单信息表,因为订单中可能会有多种商品,所以要将订单编号和商品编号作为数据库表的联合主键,如下表所示。
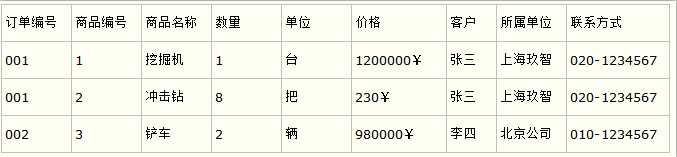
这样就产生一个问题:这个表中是以订单编号和商品编号作为联合主键。这样在该表中商品名称、单位、商品价格等信息不与该表的联合主键相关,而仅仅是与商品编号相关。所以在这里违反了第二范式的设计原则。而如果把这个订单信息表进行拆分,把商品信息分离到另一个表中,把订单项目表也分离到另一个表中,就非常完美了。如下所示。

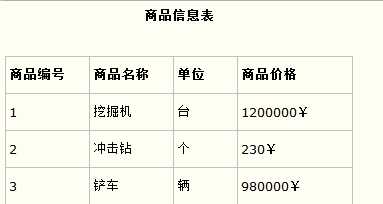
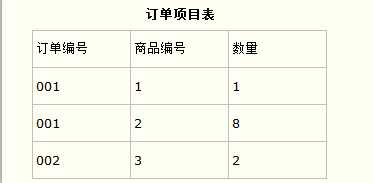
这样设计,在很大程度上减小了数据库的冗余。如果要获取订单的商品信息,使用商品编号到商品信息表中查询即可。
3.第三范式
确保每列都和主键列直接相关,而不是间接相关,不存在传递依赖。第三范式需要确保数据表中的,每一列数据都和主键直接相关,而不能间接相关解决间接相关,把不直接相关的再建一张表,采用外键形式将两张表关联.
比如在设计一个订单数据表的时候,可以将客户编号作为一个外键和订单表建立相应的关系。而不可以在订单表中添加关于客户其它信息(比如姓名、所属公司等)的字段,因为添加后就会出现传递依赖 :
订单编号--》客户编号, 客户编号--》客户详细信息
如下面这两个表所示的设计就是一个满足第三范式的数据库表。
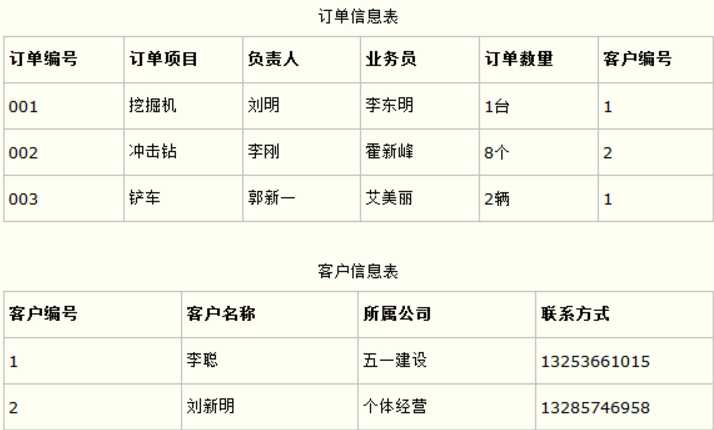
这样在查询订单信息的时候,就可以使用客户编号来引用客户信息表中的记录,也不必在订单信息表中多次输入客户信息的内容,减小了数据冗余。
二、数据库表设计规范
1.表与字段的规范
(1)表达是与否概念的字段,必须使用 is _ xxx 的方式命名,数据类型是 unsigned tinyint( 1 表示是,0 表示否 ) 。
说明:任何字段如果为非负数,必须是 unsigned 。
正例:表达逻辑删除的字段名 is_deleted ,1 表示删除,0 表示未删除。
(2)表名、字段名必须使用小写字母或数字并以下划线分隔 , 禁止出现数字开头,禁止两个下划线中间只出现数字,名字要做到见名思意,不要超过32个字符。
说明:MySQL 在 Windows 下不区分大小写,但在 Linux 下默认是区分大小写。
正例: aliyun _ admin , rdc _ config , level 3_ name
反例: AliyunAdmin , rdcConfig , level 3 name
(3)小数类型为 decimal ,禁止使用 float 和 double 。
说明: float 和 double 在存储的时候,存在精度损失的问题,很可能在值的比较时,得到不正确的结果。如果存储的数据范围超过 decimal 的范围,建议将数据拆成整数和小数分开存储。
(4)表必备三字段: id 主键, gmt _ create创建时间 , gmt _ modified更新时间 。
(5)不同表之间存储相同数据的列名和列类型必须一致(关联列)
(6)优先选择符合存储需要的最小、最简单的数据类型。
选择数据类型只要遵循小而简单的原则就好,越小的数据类型通常会更快,占用更少的磁盘、内存,处理时需要的CPU周期也更少。越简单的数据类型在计算时需要更少的CPU周期,比如,整型就比字符操作代价低,因而会使用整型来存储ip地址,使用DATETIME来存储时间,而不是使用字符串。
①尽量使用数字型字段
若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
②尽量使用位数较少的类型 ,比如能使用TINYINT/SMALLINT就不使用int,能使用无符号位就不适用有符号数据类型
③尽可能的使用 varchar/nvarchar 代替 char/nchar
因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。只有在存储的字符串长度几乎相等,使用 char 定长字符串类型。
(7)不得使用外键与级联,一切外键概念必须在应用层解决。
(8)表和字段名要加注释
(9)将字段很多的表分解成多个表
将使用频率低的字段拿出来新建一个表,完成分表,从而提高效率
(10)增加冗余字段
适当的不遵循范式的要求,对于经查查询的外表字段可以在本表中增加冗余字段。比如经常要查一个学生的系名,就可以在学生表加一个系名的字段
2.索引规范
(1)业务上具有唯一特性的字段,即使是多个字段的组合,也必须建成唯一索引。
说明:不要以为唯一索引影响了 insert 速度,这个速度损耗可以忽略,但提高查找速度是明显的 。
(2)主键索引名为 pk_ 字段名;唯一索引名为 uk _字段名 ; 普通索引名则为 idx _字段名。
(3)在 varchar 字段上建立索引时,必须指定索引长度,没必要对全字段建立索引,根据实际文本区分度决定索引长度即可。
(4)限制每张表的索引数量,建议每张表的索引数量不超过5个,并且针对复合索引,最常用的、区分度最高的(列中不同值数量/列的总行数)、字段长度小的放到最左侧
(5)索引列定义为 not null
索引null列需要额外空间保存,需要占用更多地空间,运算和比较的时候会占用更多的空间
(6)值分布稀少的字段不适合建立索引,比如性别