本文 :AgentChat
autogenstudio
core
ext
重要 :API Reference
书接上回: AgentChat-Tutorial
自定义 Agents(略)
AgentChat 中的所有Agent都继承自 BaseChatAgent 创建一个类并实现以下抽象方法和属性:
- on_messages() :定义agent
响应消息行为的抽象方法。它返回一个 Response 对象。 - on_reset() :将agent重置为其初始状态的抽象方法。
- produced_message_types :agent在其响应中可能生成的消息类型列表(BaseChatMessage)。
SelectorGroupChat
SelectorGroupChat 实现了一个团队协作模式,团队成员轮流向所有其他成员广播消息。生成模型(例如 LLM)会根据共享上下文选择下一个发言者 ,从而实现动态的、上下文感知的协作。
关键功能包括:
- 基于模型的发言者选择(Model-based speaker selection)
- 可配置的参与者角色和描述
- 防止同一发言者连续发言(可选)
- 可定制的选择提示(Customizable selection prompting)
- 可定制的选择函数(selection function),用于覆盖默认的基于模型的选择
- 可定制的候选函数(candidate function),用于使用模型缩小供选择的智能体集合
How Does it Work
SelectorGroupChat 是一种群聊,类似于 RoundRobinGroupChat,但它采用基于模型的下一发言者选择机制。当团队通过 run() 或 run_stream() 接收到任务时,将执行以下步骤:
- 团队分析当前的对话上下文,包括对话历史和参与者的
name 和 description属性,以使用模型确定下一位发言者。
默认情况下,团队不会连续选择同一位发言者,除非它是唯一可用的智能体。可以通过设置
allow_repeated_speaker=True来更改此行为。你也可以通过提供自定义的选择函数来覆盖模型。
- 团队提示选定的发言者智能体提供响应,然后将该响应**广播(broadcast)**给所有其他参与者。
- 检查终止条件以确定对话是否应该结束,如果否,则从步骤
1重复该过程。 - 当对话结束时,团队返回包含该任务对话历史的 TaskResult。
一旦团队完成任务,对话上下文会保留在团队和所有参与者中,因此下一个任务可以从先前的对话上下文继续。你可以通过调用 reset() 来重置对话上下文。
示例: Web Search/Analysis
我们将通过一个简单的示例来演示如何使用 SelectorGroupChat 进行网络搜索和数据分析任务。
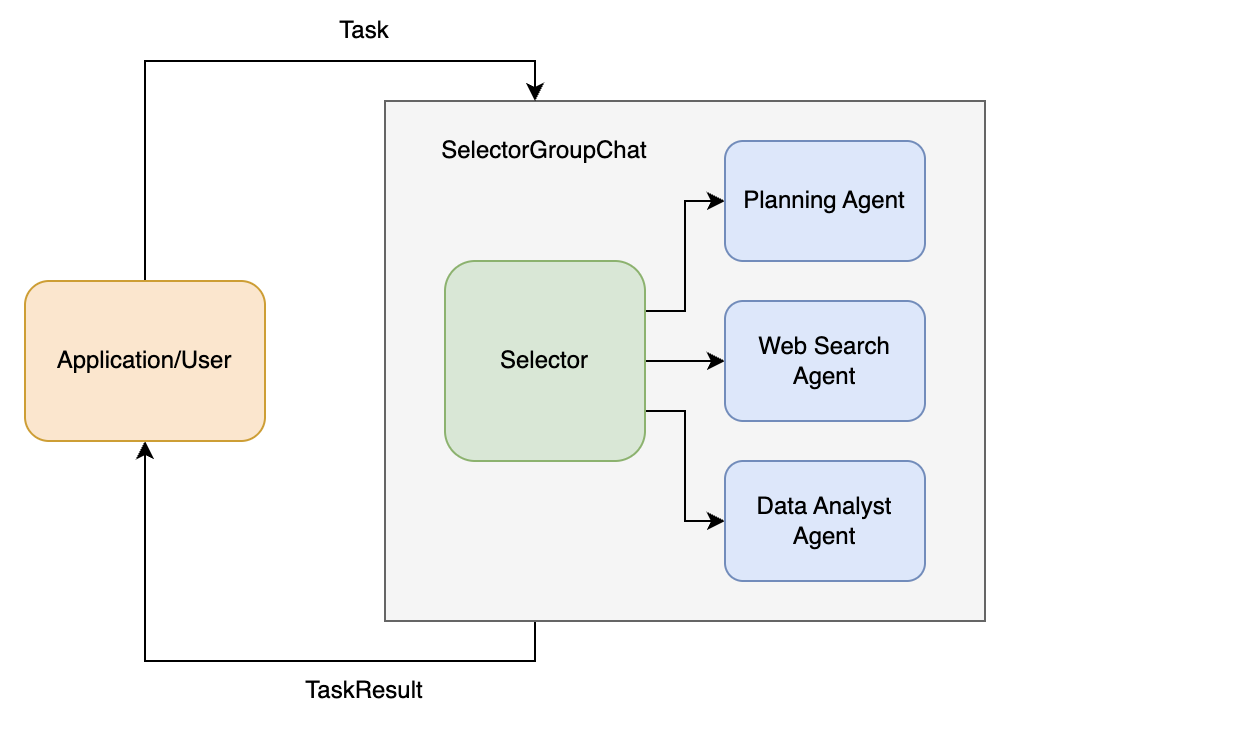
该系统使用三个专门的代理:
- 任务规划代理:Planning Agent: 将复杂任务分解为可管理子任务.
- Web 搜索代理:Web Search Agent : 使用
search_web_tool的信息检索专家。 - 数据分析代理:Data Analyst Agent : 使用
percentage_change_tool进行数据分析
定义tools
python
def search_web_tool(query: str) -> str:
if "2006-2007" in query:
return """Here are the total points scored by Miami Heat players in the 2006-2007 season:
Udonis Haslem: 844 points
Dwayne Wade: 1397 points
James Posey: 550 points
...
"""
elif "2007-2008" in query:
return "The number of total rebounds for Dwayne Wade in the Miami Heat season 2007-2008 is 214."
elif "2008-2009" in query:
return "The number of total rebounds for Dwayne Wade in the Miami Heat season 2008-2009 is 398."
return "No data found."
def percentage_change_tool(start: float, end: float) -> float:
return ((end - start) / start) * 100定义Agents
模型会使用代理的 name 和 description 属性来确定下一个说话人,因此建议提供有意义的名称和描述。
python
planning_agent = AssistantAgent(
"PlanningAgent",
description="An agent for planning tasks, this agent should be the first to engage when given a new task.",
model_client=model_client,
system_message="""
You are a planning agent.
Your job is to break down complex tasks into smaller, manageable subtasks.
Your team members are:
WebSearchAgent: Searches for information
DataAnalystAgent: Performs calculations
You only plan and delegate tasks - you do not execute them yourself.
When assigning tasks, use this format:
1. <agent> : <task>
After all tasks are complete, summarize the findings and end with "TERMINATE".
""",
)
web_search_agent = AssistantAgent(
"WebSearchAgent",
description="An agent for searching information on the web.",
tools=[search_web_tool],
model_client=model_client,
system_message="""
You are a web search agent.
Your only tool is search_tool - use it to find information.
You make only one search call at a time.
Once you have the results, you never do calculations based on them.
""",
)
data_analyst_agent = AssistantAgent(
"DataAnalystAgent",
description="An agent for performing calculations.",
model_client=model_client,
tools=[percentage_change_tool],
system_message="""
You are a data analyst.
Given the tasks you have been assigned, you should analyze the data and provide results using the tools provided.
If you have not seen the data, ask for it.
""",
)工作流程
- 任务由 SelectorGroupChat 接收,选择器群聊根据代理描述选择最合适的代理来处理初始任务(通常是planning_agent)。
- planning_agent分析任务并将其分解为子任务,然后使用以下格式将每个子任务分配给最合适的代理:
<agent> : <task> - 根据对话上下文和代理描述, SelectorGroupChat 管理器动态选择下一个代理来处理其分配的子任务。
web_search_agent一次执行一个搜索,并将结果存储在共享的对话历史记录中。data_analyst_agent在选择时使用可用的计算工具处理收集到的信息。- 工作流程继续进行,代理程序会动态选择,直到出现以下情况之一:
- 规划代理确定所有子任务均已完成,并发送
"TERMINATE"消息。 - 满足其他终止条件(例如,消息数量达到上限)
在定义代理人时,请务必包含有用的 description 因为这将用于决定接下来选择哪个代理人。
终止条件
python
# Planning Agent 发送"TERMINATE"时结束对话
text_mention_termination = TextMentionTermination("TERMINATE")
# 用于将对话限制为 25 条消息,以避免无限循环。
max_messages_termination = MaxMessageTermination(max_messages=25)
termination = text_mention_termination | max_messages_terminationSelector Prompt
SelectorGroupChat 使用一种模型,根据对话上下文选择下一位发言人。我们将使用自定义选择器提示,以便更好地配合工作流程。
python
selector_prompt = """Select an agent to perform task.
{roles}
Current conversation context:
{history}
Read the above conversation, then select an agent from {participants} to perform the next task.
Make sure the planner agent has assigned tasks before other agents start working.
Only select one agent.
"""选择器提示符中可用的字符串变量有:
{participants}:候选人的姓名。格式为["<name1>", "<name2>", ...]。{roles}:候选代理人的姓名和描述以换行符分隔的列表。每行的格式为:"<name> : <description>"。
3.{history}:对话历史记录,格式为双换行符分隔姓名和消息内容。每条消息的格式为:"<name> : <message content>"。
Running the Team
python
## build a team
team = SelectorGroupChat(
[planning_agent, web_search_agent, data_analyst_agent],
model_client=model_client,
termination_condition=termination,
selector_prompt=selector_prompt,
allow_repeated_speaker=True, # Allow an agent to speak multiple turns in a row.
)
task = "Who was the Miami Heat player with the highest points in the 2006-2007 season, and what was the percentage change in his total rebounds between the 2007-2008 and 2008-2009 seasons?"
asyncio.run( Console(team.run_stream(task=task)))输出

自定义选择器函数: selector_func
我们常常希望更好地控制选择过程。为此,我们可以通过设置 selector_func 参数来指定自定义选择函数,从而覆盖默认的基于模型的选择方式。这使我们能够实现更复杂的选择逻辑和基于状态的转换。
例如,我们希望PlanningAgent在任何专业代理人发言后立即发言,以检查进度。
python
from typing import List, Sequence
from autogen_agentchat.messages import BaseAgentEvent, BaseChatMessage
def selector_func(messages: Sequence[BaseAgentEvent | BaseChatMessage]) -> str | None:
if messages[-1].source != planning_agent.name:
return planning_agent.name
return None # 返回 None 将使用默认的基于模型的选择。
asyncio.run(team.reset())
team = SelectorGroupChat(
[planning_agent, web_search_agent, data_analyst_agent],
model_client=model_client,
termination_condition=termination,
selector_prompt=selector_prompt,
allow_repeated_speaker=True,
selector_func=selector_func, # 设置selector_func
)
asyncio.run( Console(team.run_stream(task=task)))输出

自定义候选人函数: candidate_func
另一个可能的需求是从筛选后的代理列表中自动选择下一位发言者。为此,我们可以设置 candidate_func 参数,并传入一个自定义的候选函数,以便在每次群聊中筛选出合适的发言者。
这使我们能够在给定代理人之后,将说话人选择限制在一组特定的代理人之间。
python
def candidate_func(messages: Sequence[BaseAgentEvent | BaseChatMessage]) -> List[str]:
# 确保planning_agent 总是第一个发言
if messages[-1].source == "user":
return [planning_agent.name]
last_message = messages[-1]
# 如果上一个发言者是planning_agent,则根据其内容选择下一个发言者
if last_message.source == planning_agent.name:
participants = []
# 如果web_search_agent或data_analyst_agent的名字出现在planning_agent的最后一条消息中,则将其添加到候选列表中
if web_search_agent.name in last_message.to_text():
participants.append(web_search_agent.name)
if data_analyst_agent.name in last_message.to_text():
participants.append(data_analyst_agent.name)
if participants:
return participants # 如果已经有候选人participants,则返回它们
# 一旦 web_search_agent # 和 data_analyst_agent完成了他们的回合,就让planning_agent发言
previous_set_of_agents = set(message.source for message in messages)
if web_search_agent.name in previous_set_of_agents and data_analyst_agent.name in previous_set_of_agents:
return [planning_agent.name]
# 否则,返回所有代理作为候选人 -- 不能返回[]
return [planning_agent.name, web_search_agent.name, data_analyst_agent.name]
asyncio.run( team.reset())
team = SelectorGroupChat(
[planning_agent, web_search_agent, data_analyst_agent],
model_client=model_client,
termination_condition=termination,
candidate_func=candidate_func, # 设置candidate_func
)
asyncio.run( Console(team.run_stream(task=task)))用户反馈(UserProxyAgent)
我们可以将 UserProxyAgent 添加到团队中,以便在运行过程中提供用户反馈。
我们只需将其添加到团队,并更新选择器函数(selector_func),使其在规划代理发言后始终检查用户反馈。
如果用户回复 "APPROVE" ,则对话继续;
否则,规划代理将再次尝试,直到用户同意为止。
python
user_proxy_agent = UserProxyAgent("UserProxyAgent", description="A proxy for the user to approve or disapprove tasks.")
def selector_func_with_user_proxy(messages: Sequence[BaseAgentEvent | BaseChatMessage]) -> str | None:
if messages[-1].source != planning_agent.name and messages[-1].source != user_proxy_agent.name:
# Planning agent should be the first to engage when given a new task, or check progress.
return planning_agent.name
if messages[-1].source == planning_agent.name:
if messages[-2].source == user_proxy_agent.name and "APPROVE" in messages[-1].content.upper(): # type: ignore
# User has approved the plan, proceed to the next agent.
return None
# Use the user proxy agent to get the user's approval to proceed.
return user_proxy_agent.name
if messages[-1].source == user_proxy_agent.name:
# If the user does not approve, return to the planning agent.
if "APPROVE" not in messages[-1].content.upper(): # type: ignore
return planning_agent.name
return None
# Reset the previous agents and run the chat again with the user proxy agent and selector function.
asyncio.run( team.reset())
team = SelectorGroupChat(
[planning_agent, web_search_agent, data_analyst_agent, user_proxy_agent],
model_client=model_client,
termination_condition=termination,
selector_prompt=selector_prompt,
selector_func=selector_func_with_user_proxy,
allow_repeated_speaker=True,
)
asyncio.run( Console(team.run_stream(task=task)))Using Reasoning Models
如果您使用的是像 o3-mini 这样的推理模型 ,则需要尽可能保持选择器提示和系统消息的简洁明了。这是因为推理模型已经能够根据所提供的上下文自行生成指令 。
这也意味着我们不再需要planning_agent来分解任务 ,因为使用推理模型的 SelectorGroupChat 可以自行完成这项工作。
Swarm
Swarm 实现了一种团队,其中智能体可以根据彼此的能力将任务移交(hand off)给其他智能体。
Swarm: 像"蜂群智能":多 agent 合作补充
- 多个 agent 可"同时提交提案(reply proposals)"
- 每个 agent 尝试改进/补充别人的回答,而不是替代
- 有"message budget"和"协作深度"概念 - 防止 agent 无限补充。
Swarm 的目标是让多个 AI 共同解决一个复杂问题 ,不是轮流 不是挑选,而是:所有人都参与 → 互相补充 → 产生一个融合后的最佳答案 , 更像"智能体集群共同思考"。
How Does It Work?
Swarm 团队的核心是一个群聊,其中的agents轮流生成回复 。
它与SelectorGroupChat和 RoundRobinGroupChat有着本质的区别:
RoundRobinGroupChat: 顺序固定:A → B → C → A → B → C ...SelectorGroupChat: 由一个"selector agent" 决定明确下一个执行agentSwarm: 在每个回合中, 发言代理都是根据上下文中最新的 HandoffMessage 消息来选择的。
对于 AssistantAgent ,您可以设置 使用 handoffs 参数可以指定可以转接给哪些代理。
整个过程可以总结如下:
- 每个智能体都有能力生成 HandoffMessage 来标志它可以**移交(hand off)**给哪些其他智能体。对于 AssistantAgent 而言,这意味着设置 handoffs 参数。
- 当团队开始执行任务时,第一个发言者智能体处理任务,并做出关于是否移交以及移交给谁的本地化决策。
- 当一个智能体生成 HandoffMessage 时,接收智能体会接管任务,并使用相同的消息上下文。
- 这个过程持续进行,直到满足终止条件。
示例:Customer Support(航班退款场景)
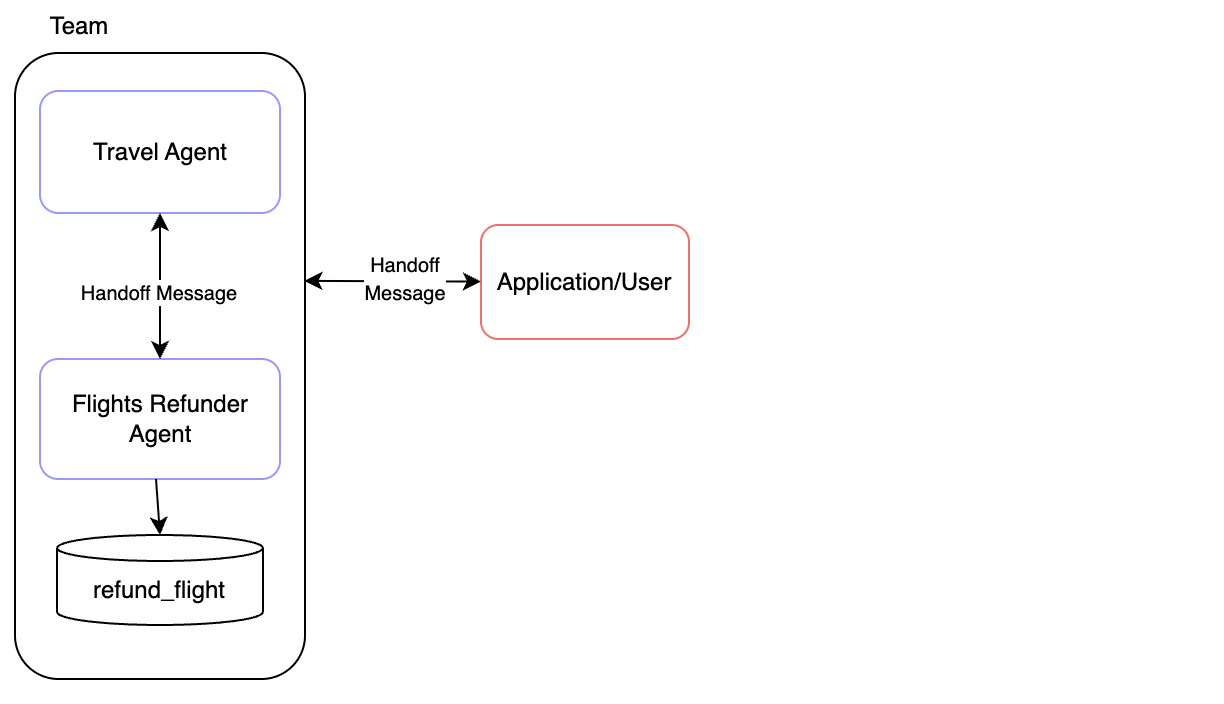 该系统实现了包含两个代理的
该系统实现了包含两个代理的航班退款场景:
- 旅行社代理:Travel Agent : 负责
一般旅行和退款协调工作。 - 航班退款员:Flights Refunder : 门使用
refund_flight 工具处理航班退款
当代理将任务移交给 "user" 时,我们允许用户与代理进行交互.
Workflow
旅行社代理发起对话并评估用户的请求。- 根据请求
- 对于
退款相关的任务,旅行社将任务移交给航班退款员。 - 如需从客户处获取信息,任一代理都可以将信息转交给
"user"。
- 对于
- 航班退款员会在适当的时候使用
refund_flight 工具处理退款。 - 如果代理将任务交给 "user" ,团队执行将停止,
并等待用户输入响应。 - 当用户提供输入时,该输入会以 HandoffMessage 形式发送回团队。此消息会发送给最初请求用户输入的客服人员。
- 该过程将持续进行,直到旅行社确认任务完成并终止工作流程为止。
定义工具
python
def refund_flight(flight_id: str) -> str:
"""Refund a flight"""
return f"Flight {flight_id} refunded"定义Agents
python
travel_agent = AssistantAgent(
"travel_agent",
model_client=model_client,
handoffs=["flights_refunder", "user"],
system_message="""You are a travel agent.
The flights_refunder is in charge of refunding flights.
If you need information from the user, you must first send your message, then you can handoff to the user.
Use TERMINATE when the travel planning is complete.""",
)
flights_refunder = AssistantAgent(
"flights_refunder",
model_client=model_client,
handoffs=["travel_agent", "user"],
tools=[refund_flight],
system_message="""You are an agent specialized in refunding flights.
You only need flight reference numbers to refund a flight.
You have the ability to refund a flight using the refund_flight tool.
If you need information from the user, you must first send your message, then you can handoff to the user.
When the transaction is complete, handoff to the travel agent to finalize.""",
)定义Termination & Team执行
python
# 当前任务完成TERMINATE时,或者移交给user时,终止团队协作。
termination = HandoffTermination(target="user") | TextMentionTermination("TERMINATE")
team = Swarm([travel_agent, flights_refunder], termination_condition=termination)
task = "I need to refund my flight."
async def run_team_stream() -> None:
task_result = await Console(team.run_stream(task=task))
# 执行到此处,说明这一轮团队任务结束。
last_message = task_result.messages[-1]
# 如果最后的消息是移交给user的handoff,则启动与user的交互环节。
# 否则,说明任务已经COMPLETED,直接结束。
while isinstance(last_message, HandoffMessage) and last_message.target == "user":
user_message = input("User: ")
task_result = await Console(
# 把message 发还给 last_message.source对应的agent
team.run_stream(task=HandoffMessage(source="user", target=last_message.source, content=user_message))
)
last_message = task_result.messages[-1]
asyncio.run(run_team_stream())
asyncio.run(model_client.close())示例: 股票研究
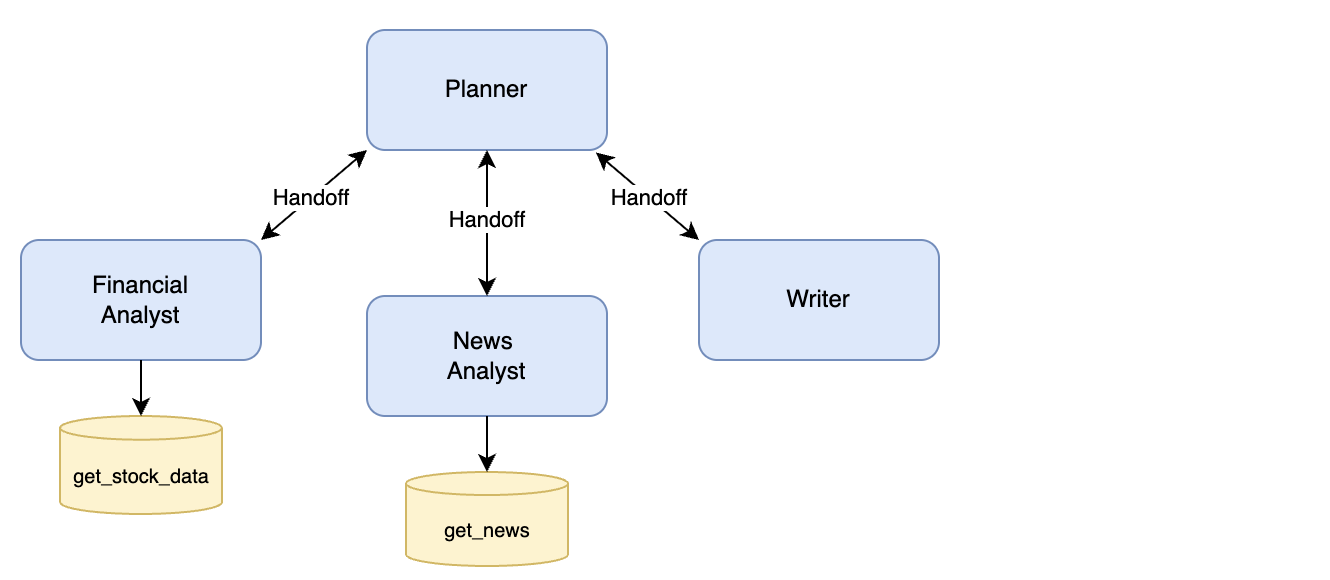
该系统旨在通过利用四个代理来执行股票研究任务:
- 规划员:Planner : 作为中央协调人,
规划员根据专业人员的专长将具体任务分配给他们。规划员确保每位专业人员都得到高效利用,并监督整体工作流程。 - 财务分析师:Financial Analyst : 专门负责使用
get_stock_data 等工具分析财务指标和股票数据的专业人员。 - 新闻分析师:News Analyst : 注于收集和总结与股票相关的最新新闻文章的代理人,使用诸如
get_news之类的工具。 - 撰稿人:Writer:: 负责将股票和新闻分析结果汇编成一份连贯的最终报告的代理人。
Workflow
- 规划者通过逐步将任务委派给合适的代理人来启动研究过程。
- 每个智能体独立执行任务,并将工作成果添加到共享消息线程/历史记录中 。智能体
不会直接将结果返回给规划器,而是共同参与并读取此共享消息历史记录。当智能体使用 LLM 生成工作时,它们可以访问此共享消息历史记录,从而获得上下文信息并帮助跟踪任务的整体进度。 - 代理完成任务后,会将控制权交还给规划器。
- 该过程持续进行,直到规划人员确定所有必要任务均已完成并决定终止工作流程为止。
Tools
python
async def get_stock_data(symbol: str) -> Dict[str, Any]:
"""Get stock market data for a given symbol"""
return {"price": 180.25, "volume": 1000000, "pe_ratio": 65.4, "market_cap": "700B"}
async def get_news(query: str) -> List[Dict[str, str]]:
"""Get recent news articles about a company"""
return [
{
"title": "Tesla Expands Cybertruck Production",
"date": "2024-03-20",
"summary": "Tesla ramps up Cybertruck manufacturing capacity at Gigafactory Texas, aiming to meet strong demand.",
},
{
"title": "Tesla FSD Beta Shows Promise",
"date": "2024-03-19",
"summary": "Latest Full Self-Driving beta demonstrates significant improvements in urban navigation and safety features.",
},
{
"title": "Model Y Dominates Global EV Sales",
"date": "2024-03-18",
"summary": "Tesla's Model Y becomes best-selling electric vehicle worldwide, capturing significant market share.",
},
]Agents
python
planner = AssistantAgent(
"planner",
model_client=model_client,
handoffs=["financial_analyst", "news_analyst", "writer"],
system_message="""You are a research planning coordinator.
Coordinate market research by delegating to specialized agents:
- Financial Analyst: For stock data analysis
- News Analyst: For news gathering and analysis
- Writer: For compiling final report
Always send your plan first, then handoff to appropriate agent.
Always handoff to a single agent at a time.
Use TERMINATE when research is complete.""",
)
financial_analyst = AssistantAgent(
"financial_analyst",
model_client=model_client,
handoffs=["planner"],
tools=[get_stock_data],
system_message="""You are a financial analyst.
Analyze stock market data using the get_stock_data tool.
Provide insights on financial metrics.
Always handoff back to planner when analysis is complete.""",
)
news_analyst = AssistantAgent(
"news_analyst",
model_client=model_client,
handoffs=["planner"],
tools=[get_news],
system_message="""You are a news analyst.
Gather and analyze relevant news using the get_news tool.
Summarize key market insights from news.
Always handoff back to planner when analysis is complete.""",
)
writer = AssistantAgent(
"writer",
model_client=model_client,
handoffs=["planner"],
system_message="""You are a financial report writer.
Compile research findings into clear, concise reports.
Always handoff back to planner when writing is complete.""",
)定义Termination & Team执行
python
text_termination = TextMentionTermination("TERMINATE")
termination = text_termination
research_team = Swarm(
participants=[planner, financial_analyst, news_analyst, writer], termination_condition=termination
)
task = "Conduct market research for TSLA stock"
asyncio.run(Console(research_team.run_stream(task=task)))
asyncio.run(model_client.close())Magentic-One(略)
Magentic-One 是 Microsoft 在 2024 年推出的一套 面向 AI 多智能体(multi-agent)系统的框架与参考实现,主要用于让多个 AI 模型(包括 LLM、工具代理、规划代理等)协同完成复杂任务。
Magentic =
Multi-Agent + Orchestration
One = 统一(One)工作流,用一个统一框架整合不同类型的智能体。
它不是一个「模型」,而是一套 多代理编排(orchestration)+ 工具调用 + 规划能力 的体系。
你可以把它理解成微软版的 AutoGen / OpenAI Swarm / LangGraph 的「官方强化版」。
工作流-GraphFlow (Workflows)
在本节中,您将学习如何使用 GraphFlow (简称"flow")创建多智能体工作流 。它采用结构化执行方式,并精确控制智能体如何交互以完成任务。
AutoGen AgentChat 提供了一个用于定向图执行的团队:
- GraphFlow :一个遵循 DiGraph 团队 控制代理之间的执行流程。 支持
顺序、并行、条件和循环行为。
为什么需要GraphFlow
GroupChat (RoundRobin / Selector)= 自由协作、无严格顺序
- RoundRobinGroupChat:按顺序轮流发言
- SelectorGroupChat:让某个 agent 决定下一个发言者
它们特点:
- 很像"群聊"
- 对话流向是动态的
- 代理之间随时可能互相回应
- 适合临时性的协作任务
它的弱点:
- 无法严格保证顺序
- 无法表达 if/else
- 无法表示循环
- 不适合复杂多步骤流程
就是个"群聊",不是流程引擎。
创建和运行流程
DiGraphBuilder 是一个流畅的实用工具,可让您轻松构建工作流的执行图。它支持构建:
- 顺序链(Sequential chains)
- 并行扇出(Parallel fan-outs):可以理解为工作流中的并行网关
- 条件分支(Conditional branching)
- 带有安全退出条件的循环(Loops with safe exit conditions)
图中的每个节点都代表一个智能体(agent),而边(edges)定义了允许的执行路径。边可以根据智能体消息选择性地添加条件。
Sequential Flow
我们将首先创建一个简单的流程图:
- 作者撰写一段文字,
- 审阅者提供反馈。
- 该流程图在审阅者对作者的文字进行评论后结束。
python
from autogen_agentchat.teams import DiGraphBuilder, GraphFlow
writer = AssistantAgent("writer", model_client=model_client, system_message="Draft a short paragraph on climate change.")
reviewer = AssistantAgent("reviewer", model_client=model_client, system_message="Review the draft and suggest improvements.")
# Build the graph
builder = DiGraphBuilder()
builder.add_node(writer).add_node(reviewer) # add nodes
builder.add_edge(writer, reviewer) # writer -> reviewer
graph = builder.build()
# Create the flow
flow = GraphFlow([writer, reviewer], graph=graph)
asyncio.run(Console(flow.run_stream(task="Write a short paragraph about climate change.")))```输出

Parallel Flow with Join
现在我们创建一个稍微复杂一些的流程图:
- 作者:writer正在撰写一段文字。
- 两位编辑:editors独立进行语法和风格编辑(平行扇出)。
- 最后一位审阅者:reviewer将他们的修改意见合并(合并)。
python
writer = AssistantAgent("writer", model_client=model_client, system_message="Draft a short paragraph on climate change.")
editor1 = AssistantAgent("editor1", model_client=model_client, system_message="Edit the paragraph for grammar.")
editor2 = AssistantAgent("editor2", model_client=model_client, system_message="Edit the paragraph for style.")
final_reviewer = AssistantAgent("final_reviewer",model_client=model_client,system_message="Consolidate the grammar and style edits into a final version.")
# Build the workflow graph
builder = DiGraphBuilder()
builder.add_node(writer).add_node(editor1).add_node(editor2).add_node(final_reviewer)
# Fan-out from writer to editor1 and editor2
builder.add_edge(writer, editor1)
builder.add_edge(writer, editor2)
# Fan-in both editors into final reviewer
builder.add_edge(editor1, final_reviewer)
builder.add_edge(editor2, final_reviewer)
# Build and validate the graph
graph = builder.build()
# Create the flow
flow = GraphFlow(
participants=builder.get_participants(),
graph=graph,
)
# Run the workflow
asyncio.run(Console(flow.run_stream(task="Write a short paragraph about climate change.")))输出

Message Filtering
执行图(Execution Graph) 与 消息图(Message Graph)
在 GraphFlow 中, 执行图是使用以下方式定义的: DiGraph 控制着代理的执行顺序。
然而,执行图并不控制代理从其他代理接收哪些消息。默认情况下,所有消息都会发送给图中的所有代理。
消息过滤 是一项独立功能,允许您过滤每个代理接收到的消息,并将它们的模型上下文限制为仅包含相关信息。消息过滤器集定义了流程中的消息图 。
指定消息图有助于:
- 减少幻觉
- 控制内存加载
- 关注相关信息
您可以将 MessageFilterAgent 与 MessageFilterConfig 和 PerSourceFilter 结合使用来定义这些规则。
work flow
有三个agent:researcher -> analyst -> presenter,
我们希望,
- analyst只关注来自researcher的数据
- presenter 只关注来自analyst的数据
Agents
python
researcher = AssistantAgent("researcher", model_client=model_client, system_message="Summarize key facts about climate change.")
analyst = AssistantAgent("analyst", model_client=model_client, system_message="Review the summary and suggest improvements.")
presenter = AssistantAgent("presenter", model_client=model_client, system_message="Prepare a presentation slide based on the final summary.")Filter Message Agents
python
# Apply message filtering
filtered_analyst_wrapped = MessageFilterAgent(
name="analyst",
wrapped_agent=analyst,
filter=MessageFilterConfig(per_source=[PerSourceFilter(source="researcher", position="last", count=1)]), # analyst only keep the last message from researcher
)
filtered_presenter_wrapped = MessageFilterAgent(
name="presenter",
wrapped_agent=presenter,
filter=MessageFilterConfig(per_source=[PerSourceFilter(source="analyst", position="last", count=1)]), # presenter only keep the last message from analyst
)构建执行flow
python
# Build the flow
# researcher -> analyst -> presenter
builder = DiGraphBuilder()
builder.add_node(researcher).add_node(filtered_analyst_wrapped).add_node(filtered_presenter_wrapped)
builder.add_edge(researcher, filtered_analyst_wrapped).add_edge(filtered_analyst_wrapped, filtered_presenter_wrapped)
# Create the flow
flow = GraphFlow(
participants=builder.get_participants(),
graph=builder.build(),
)
asyncio.run(Console(flow.run_stream(task="Summarize key facts about climate change.")))高级示例:Conditional Loop + Filtered Summary(略)
进阶示例:Cycles With Activation Group(略)
Memory and RAG
在某些情况下,维护一个包含有用信息的存储库非常重要,这些信息可以在执行特定步骤之前智能地添加到代理的上下文中 。
典型的用例是 RAG 模式,即使用查询从数据库中检索相关信息,然后将其添加到代理的上下文中。
AgentChat 提供了一个 Memory 协议,可以通过扩展来实现此功能。关键方法包括:
- add :向内存存储添加新条目
- query :从内存存储中检索相关信息
- update_context :通过添加检索到的信息来修改代理的内部
model_context上下文(在 AssistantAgent 类中使用)。 - clear :清除内存存储中的所有条目
- close :清理内存存储使用的所有资源
ListMemory 示例
ListMemory 是 Memory 协议的一个示例实现。它是一个简单的基于列表的内存实现,按时间顺序维护记忆,并将最新的记忆添加到模型的上下文中。该实现设计简洁明了、易于预测,便于理解和调试。
在下面的示例中,我们将使用 ListMemory 来维护用户偏好记忆库,并演示如何利用它为代理响应提供一致的上下文。
python
from autogen_core.memory import ListMemory, MemoryContent, MemoryMimeType
# 默认为英制: imperial ,即°F
async def get_weather(city: str, units: str = "imperial") -> str:
if units == "imperial":
return f"The weather in {city} is 73 °F and Sunny."
elif units == "metric":
return f"The weather in {city} is 23 °C and Sunny."
else:
return f"Sorry, I don't know the weather in {city}."
async def main() -> None:
user_memory = ListMemory()
# 使用 公制:metric,即°C
await user_memory.add(MemoryContent(content="The weather should be in metric units", mime_type=MemoryMimeType.TEXT))
await user_memory.add(MemoryContent(content="Meal recipe must be vegan", mime_type=MemoryMimeType.TEXT))
assistant_agent = AssistantAgent(
name="assistant_agent",
model_client=model_client,
tools=[get_weather],
memory=[user_memory],
)
await Console(assistant_agent.run_stream(task="What is the weather in New York?"))
asyncio.run(main())输出

查看messages
python
print("\n","*"*20,"\n")
messages = await assistant_agent._model_context.get_messages()
for message in messages:
print(f"{message.type} : {message.content}")输出

自定义内存存储(向量数据库等)
您可以基于 Memory 协议来实现更复杂的内存存储。例如,
- 您可以实现一个自定义内存存储,该存储使用向量数据库来存储和检索信息;
- 或者实现一个内存存储,该存储使用机器学习模型根据用户的偏好生成个性化响应等等。
具体来说,您需要重载 add 、 query 和 update_context 方法来实现所需的功能,并将内存存储传递给您的代理。
以下示例内存存储作为 autogen_ext 扩展包的一部分提供。
autogen_ext.memory.chromadb.ChromaDBVectorMemory:一种使用向量数据库来存储和检索信息的内存存储系统。autogen_ext.memory.chromadb.SentenceTransformerEmbeddingFunctionConfig: 存储所使用的 SentenceTransformer 嵌入函数的配置类,以及如何将它作为 Embedding Function 使用。autogen_ext.memory.redis.RedisMemory: 使用 Redis向量数据库 来存储和检索信息的内存存储。
sentence_transformers是什么?
sentence_transformers 是一个非常常用的 文本向量化(Embedding)库,专门用于把句子、段落、文档编码成高质量向量,用于:
• 语义搜索
• 文本相似度计算
• 聚类
• RAG(Retrieval Augmented Generation)
• 多智能体共享向量记忆
• 推荐系统
• 多语言语义匹配
案例测试
安装依赖:
uv add chromadb sentence_transformers
python
from autogen_core.memory import MemoryContent, MemoryMimeType
from autogen_ext.memory.chromadb import (
ChromaDBVectorMemory,
PersistentChromaDBVectorMemoryConfig,
SentenceTransformerEmbeddingFunctionConfig,
)
# Use a temporary directory for ChromaDB persistence
async def main() -> None:
with tempfile.TemporaryDirectory() as tmpdir:
chroma_user_memory = ChromaDBVectorMemory(
config=PersistentChromaDBVectorMemoryConfig(
collection_name="preferences",
persistence_path=tmpdir, # Use the temp directory here
k=2, # Return top k results
score_threshold=0.4, # Minimum similarity score
embedding_function_config=SentenceTransformerEmbeddingFunctionConfig(
model_name="all-MiniLM-L6-v2" # Use default model for testing
),
)
)
# Add user preferences to memory
await chroma_user_memory.add(
MemoryContent(
content="The weather should be in metric units",
mime_type=MemoryMimeType.TEXT,
metadata={"category": "preferences", "type": "units"},
)
)
await chroma_user_memory.add(
MemoryContent(
content="Meal recipe must be vegan",
mime_type=MemoryMimeType.TEXT,
metadata={"category": "preferences", "type": "dietary"},
)
)
# Create assistant agent with ChromaDB memory
assistant_agent = AssistantAgent(
name="assistant_agent",
model_client=model_client,
tools=[get_weather],
memory=[chroma_user_memory],
)
stream = assistant_agent.run_stream(task="What is the weather in New York?")
await Console(stream)
await model_client.close()
await chroma_user_memory.close()
asyncio.run(main())