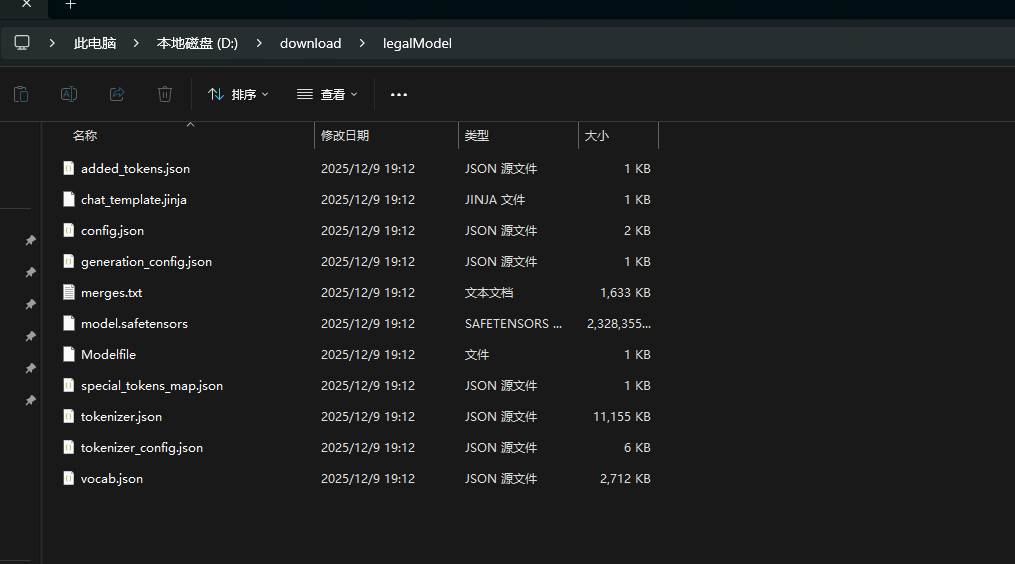
1、LLaMA-Factory安装部署
下载LLaMA-Factory代码:
https://github.com/hiyouga/LLaMA-Factory
2、创建Python虚拟环境并安装依赖
我本机用的是Python3.9.10。版本太高会出错,这个要注意下。
python -m venv ./env也可以用conda创建,看个人习惯;
接下来激活环境,在当前窗口中,输入:env\Scripts\activate
进入到环境后,就可以下载依赖
pip install -r requirements.txt
如果下载依赖很慢,可以设置为清华镜像源:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple3、启动LLaMA-Factory服务
在启动之前,我们先调整下两个文件runner.py 和loader.py代码,因为在微调的过程中,会有些错误,所以需要提前做下调整。
首先是runner.py,这个文件在LLaMA-Factory-main\src\llamafactory\webui\目录下,需要修改378行左右的代码:
self.trainer = Popen(["llamafactory-cli", "train", save_cmd(args)], env=env, stderr=PIPE, text=True)
修改成下面的代码:
self.trainer = Popen([sys.executable, "-m","llamafactory.cli", "train", save_cmd(args)], env=env, stderr=PIPE, text=True)然后在根目录下。输入:pip install -e .
之后可以在env\Scripts下看到一个llamafactory-cli.exe执行文件
这样操作的目的就可以解决虚拟环境下,找不到llamafactory-cli模块的问题。
接下来就是修改loader.py,这个文件在LLaMA-Factory-main\src\llamafactory\data\目录下
找到load_dataset关键字,增加配置keep_in_memory=True
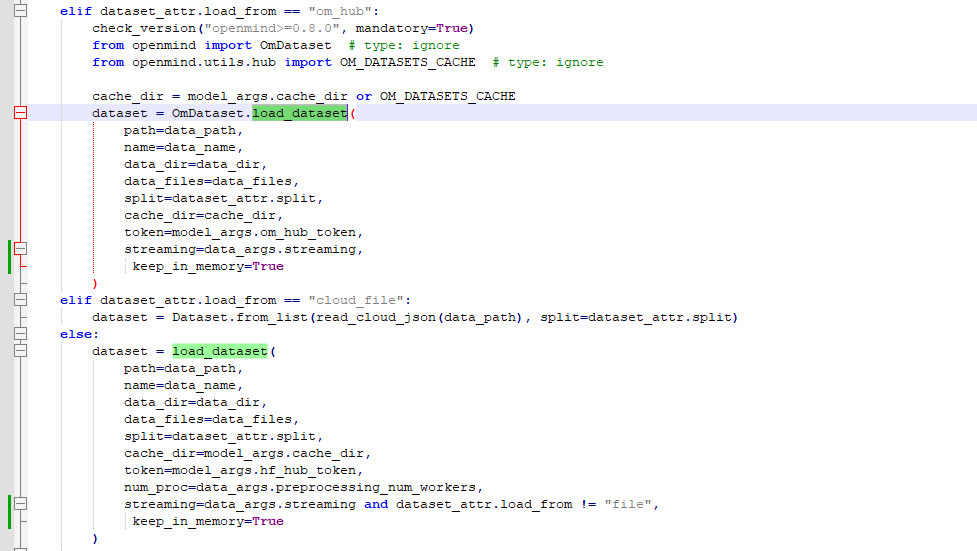
这样能解决多次训练一个模型的时候,不会出现文件命名问题。
FileExistsError: [WinError 183] 当文件已存在时,无法创建该文件。: 'C:\\Users\\EDY\\.cache\\huggingface\\datasets\\json\\default-8afa3bb648c61b3a\\0.0.0\\f4e89e8750d5d5ffbef2c078bf0ddfedef29dc2faff52a6255cf513c05eb1092\\tmpjaayunn7' ->
上面的错误我删除这个文件夹后重新微调也不行,所以增加那个配置,不进行缓存就可以解决没问题后运行:python src\webui.py

4、准备法律数据集
我用的是这个数据集https://www.modelscope.cn/datasets/Robin021/DISC-Law-SFT/files,自己也可以按需选择。
下载的数据集格式为:
{"id": "judgement_predit-1", "reference": "《刑法》第一百一十四条:xxxx。", "input": "基于下列案件,推测可能的判决结果。\n经审理查明,2015年6月21日15时许,xxxx", "output": "根据《刑法》第一百一十四条的规定,被告人白某某以危险方法危害公共安全,xxxx。"}
我们要调整指令微调(Instruction Tuning) 中最常见的 Alpaca 格式(或 Alpaca-style 格式) ,是当前开源大模型(如 LLaMA、Qwen、Baichuan 等)进行 监督微调(Supervised Fine-Tuning, SFT) 时广泛采用的数据结构:
{
"instruction": "请对以下政策或法规文件内容进行专业、清晰的解读:",
"input": "打架斗殴......",
"output": "此问题......。"
}所以要进行转换,我这里编写了转换的脚本:
import json
# 输入和输出文件路径(请根据实际情况修改)
input_file = './legal.json' # 原始文件,每行一个 JSON 对象
output_file = './data/legal.json' # 转换后的 JSON 列表文件
converted_data = []
with open(input_file, 'r', encoding='utf-8') as f:
for line in f:
line = line.strip()
if not line:
continue
try:
item = json.loads(line)
new_item = {
"instruction": "请对以下政策或法规文件内容进行专业、清晰的解读:",
"input": item["title"],
"output": item["contentText"]
}
converted_data.append(new_item)
except json.JSONDecodeError as e:
print(f"跳过无效行: {line[:100]}... 错误: {e}")
# 写入输出文件(格式化为 JSON 数组)
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(converted_data, f, ensure_ascii=False, indent=2)
print(f"转换完成!共处理 {len(converted_data)} 条记录,已保存到 {output_file}")执行后会放到data目里下。

我们需要在dataset_info.json把这个文件加进去。这个文件在data目录下
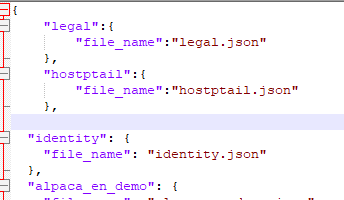
配置完后,重启LLaMA-Factory服务。
数据集那栏选项就可以看到legal
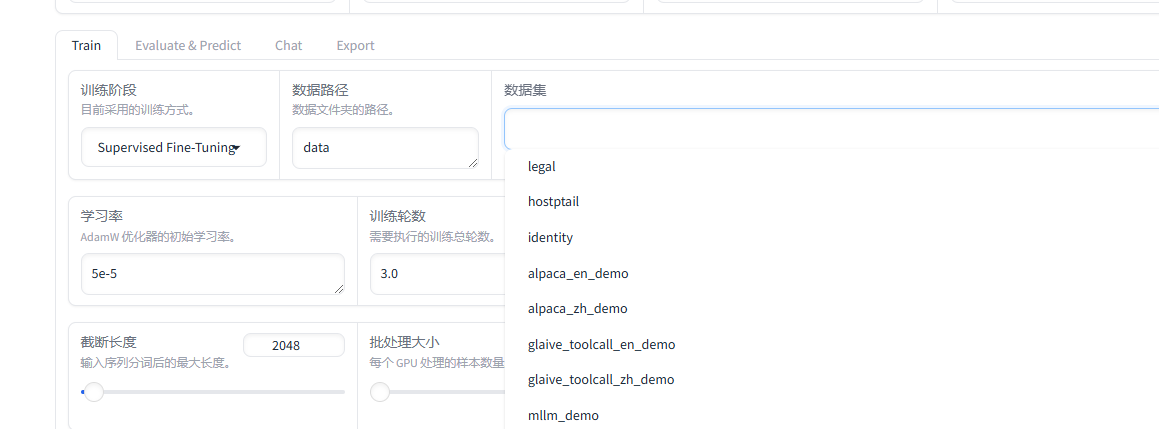
5、用Qwen3-0.6B-Base进行实战微调
我们可以先测试下Qwen3-0.6B对法律的解读,用于对后面微调完成的模型进行对比。
配置微调参数,计算类型选择fp32,是因为我的电脑没有GPU,最大样本设置200,调试阶段不需要用太多
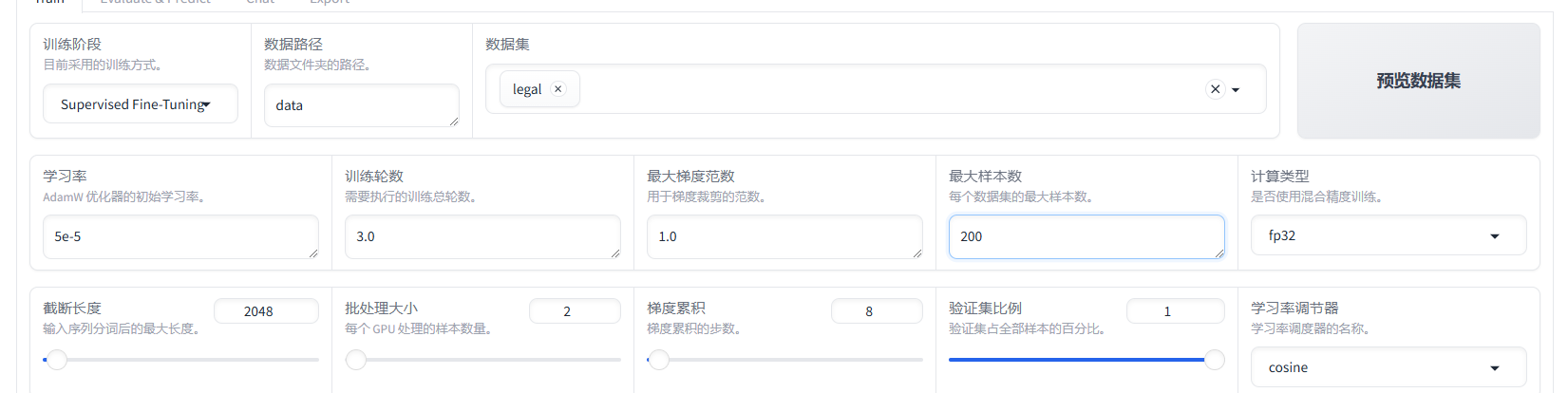
配置参考:
| 参数名 | 英文参数名 | 类型 | 默认值 | 建议范围 | 作用与影响 | 注意事项 |
|---|---|---|---|---|---|---|
| 学习率 | learning_rate |
浮点数 | 5e-5 | 1e-5 ~ 5e-4 | AdamW优化器的初始学习率,控制参数更新的步长 | - 值太大:训练不稳定,可能发散 - 值太小:收敛过慢 - 大模型用较小学习率(1e-5 ~ 2e-5) - 小模型可用较大学习率(3e-5 ~ 5e-5) |
| 训练轮数 | num_train_epochs |
浮点数 | 3.0 | 1.0 ~ 10.0 | 整个数据集被完整训练的次数 | - 3.0表示训练3轮 - 数据量少可增加轮数 - 数据量多可减少轮数 - 配合早停(early stopping)使用 |
| 最大梯度范数 | max_grad_norm |
浮点数 | 1.0 | 0.5 ~ 2.0 | 梯度裁剪阈值,防止梯度爆炸 | - 超过此值的梯度会被缩放 - 值太小:梯度信息损失过多 - 值太大:梯度爆炸风险增加 - 推荐1.0作为起点 |
| 最大样本数 | max_samples |
整数 | 无限制 | 100 ~ 10000 | 限制每个数据集使用的最大样本数 | - 设为200表示最多用200条数据 - 用于快速测试或小规模实验 - 设为-1或None表示用全部数据 |
| 计算类型 | dtype |
字符串 | fp16 | fp32/fp16/bf16 | 训练时使用的浮点数精度 | - fp32 :32位浮点,最精确但最慢 - fp16 :16位浮点,快但可能数值溢出 - bf16:16位脑浮点,范围大精度低,推荐用于训练 |
| 截断长度 | cutoff_len |
整数 | 1024 | 512 ~ 4096 | 输入序列分词后的最大长度 | - 2048表示文本会被截断或填充到2048个token - 影响: - 长文本任务需要设置较大值 - 值越大显存占用越高 - 超过模型最大长度会出错 |
| 批处理大小 | per_device_train_batch_size |
整数 | 1 | 1 ~ 16 | 每个GPU一次处理的样本数量 | - 2表示每次前向传播处理2个样本 - 主要受GPU显存限制 - 8GB显存:建议1-2 - 16GB显存:建议2-4 - 24GB+显存:建议4-8 |
| 梯度累积 | gradient_accumulation_steps |
整数 | 1 | 1 ~ 32 | 累积多个批次的梯度后再更新参数 | - 8表示累积8个批次的梯度才更新一次 - 有效批次大小 = 批处理大小 × 梯度累积步数 - 用于模拟大批次训练 - 可减少显存占用 |
| 验证集比例 | val_size |
浮点数/整数 | 0.0 | 0.05 ~ 0.2 或 100~1000 | 从训练集中划分验证集的比例或数量 | - 浮点数 :0.1表示10%数据作为验证集 - 整数 :200表示200条数据作为验证集 - 设为0则不划分验证集 - 用于监控模型过拟合 |
点击开始
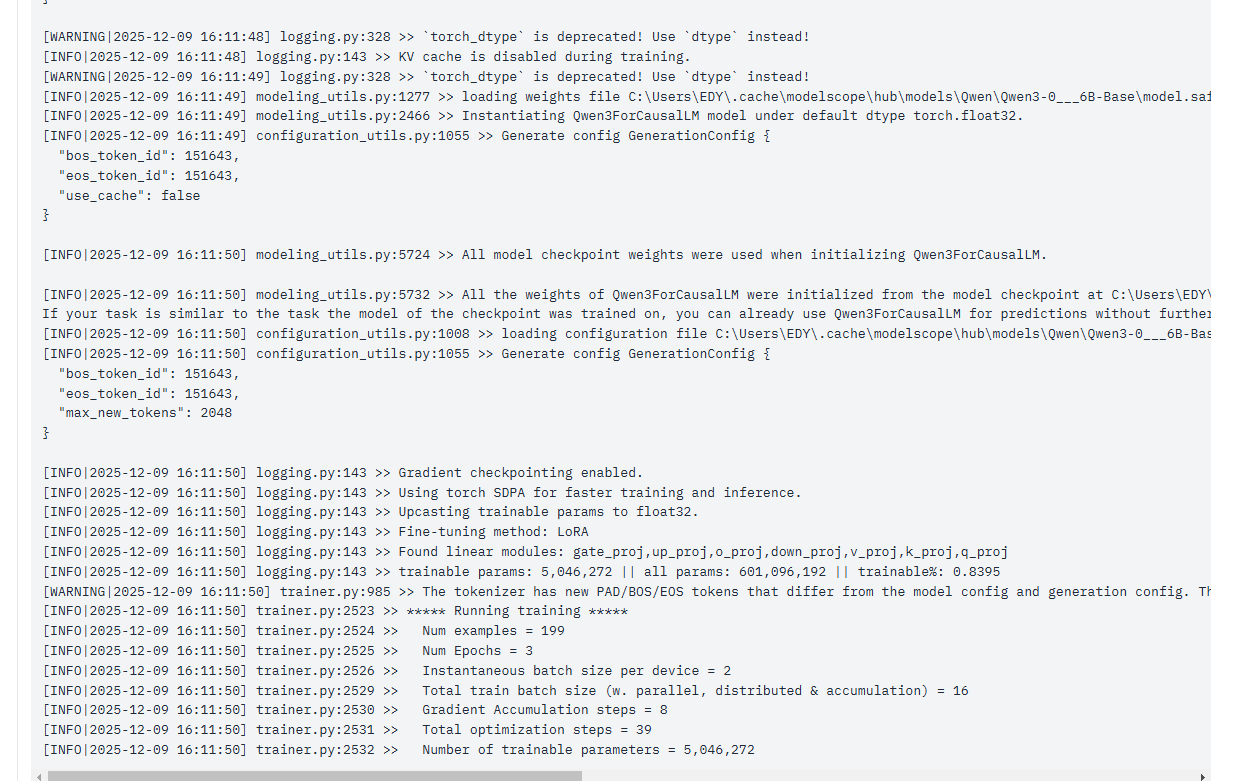
最后运行完成后。
6、用微调的模型进行测试
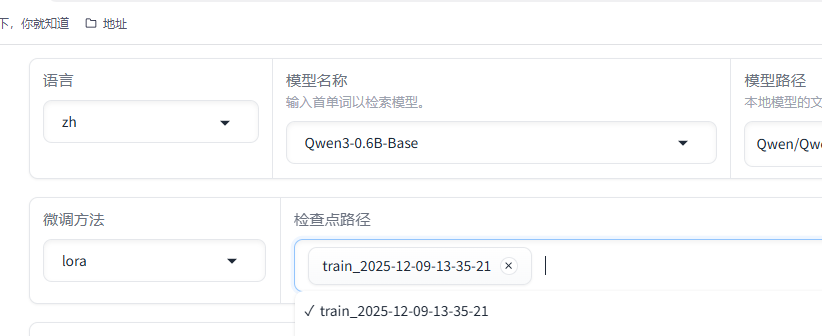
选择检查点路径,就是对应微调的模型
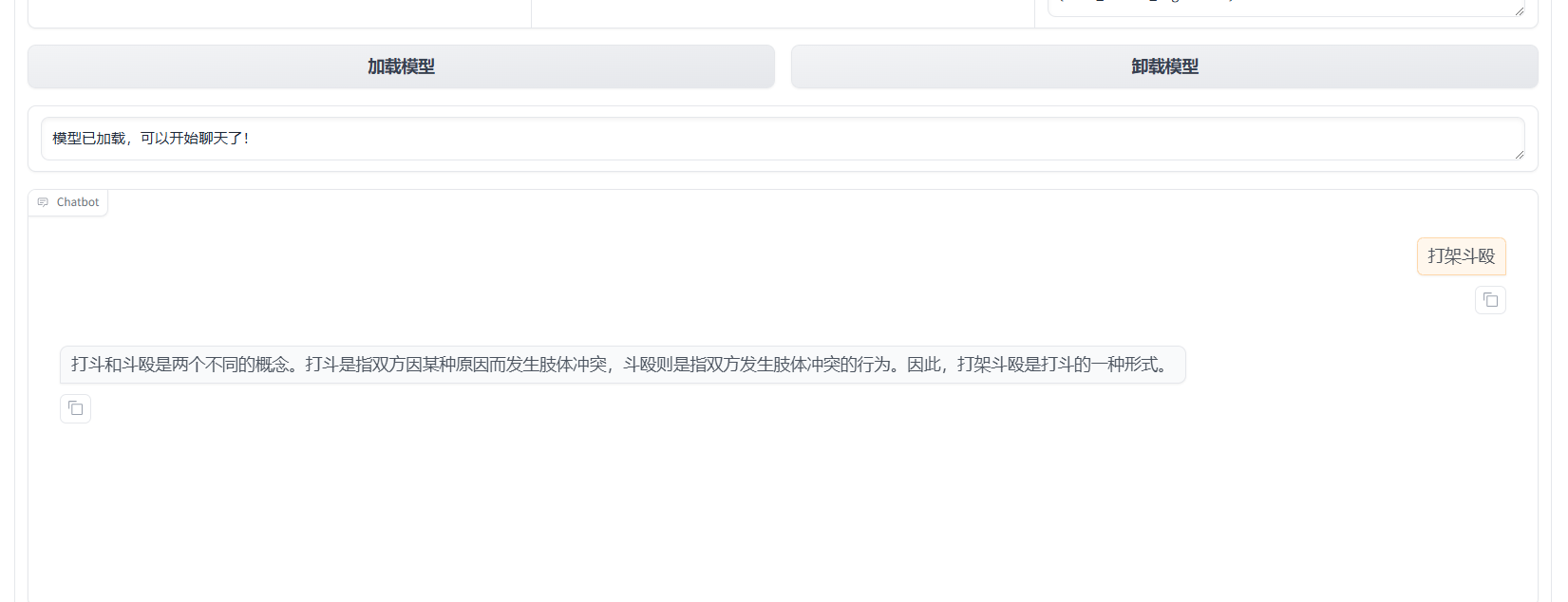
就可以进行测试,因为我用的模型,法律推理/判决预测(Legal Judgment Prediction)任务 的结构化样本,所以输出的内容是这样的
7、导出模型
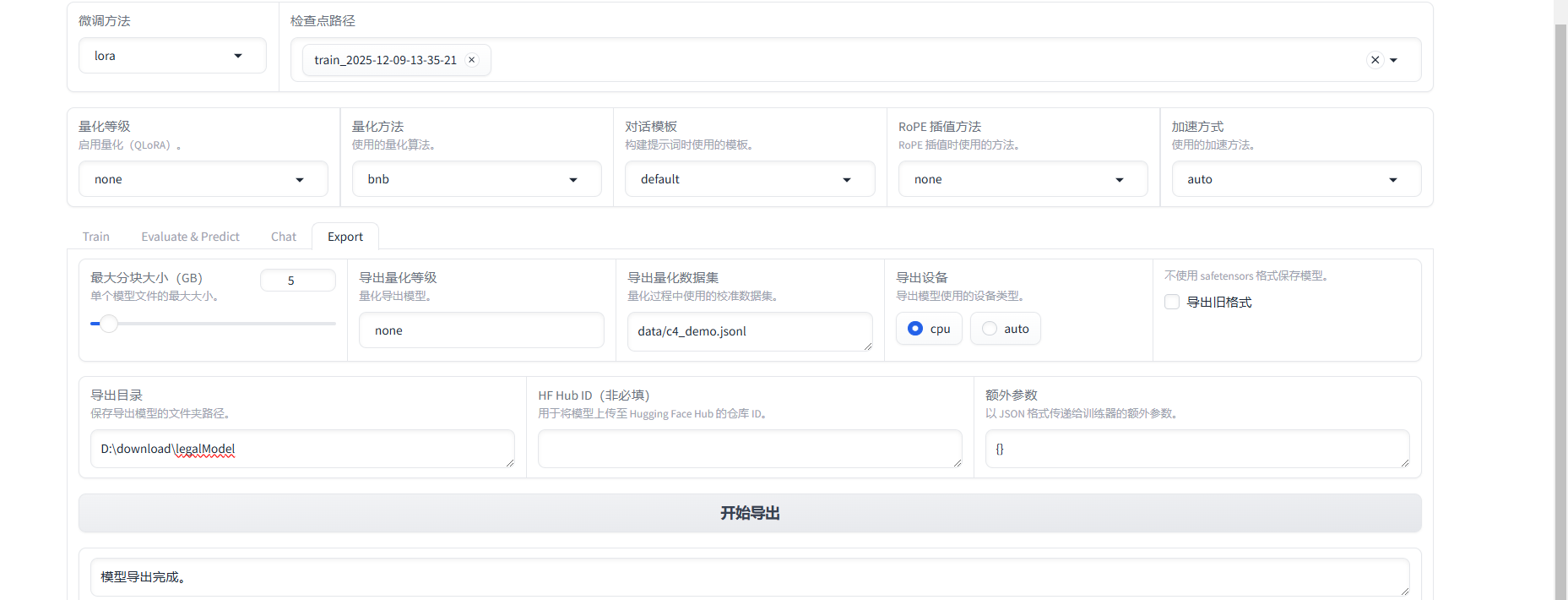
然后就可以从文件夹下看到这个模型了