大家是否觉得并发编程中的各种锁和同步机制让人头大?别担心,这篇指南将带你从性能的角度理解不同的并发计数器实现。我们将按照性能从快到慢的顺序,探索 6 种不同的实现方式,让你彻底理解并发编程的精髓!
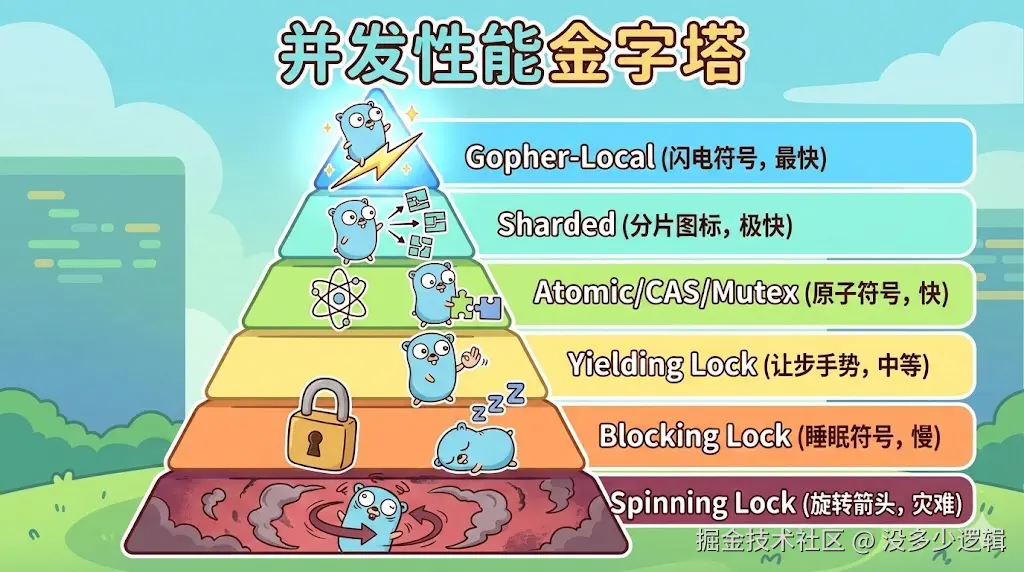
第一部分:性能金字塔 (Performance Pyramid)
在并发编程中,不同的同步机制有着天壤之别的性能表现。让我们先建立一个性能认知框架。
性能等级划分
一句话概念:并发计数器的性能取决于竞争激烈程度和同步开销。
- Level 0 - 最快:Goroutine-Local(本地计数)
- Level 1 - 极快:Sharded Counter(分片计数器)
- Level 2 - 快:Atomic、CAS、Mutex(原子操作、比较交换、互斥锁)
- Level 3 - 中等:Yielding Ticket Lock(让步票据锁)
- Level 4 - 慢:Blocking Ticket Lock(阻塞票据锁)
- Level 5 - 灾难性:Spinning Ticket Lock(自旋票据锁)
核心原理:
- 竞争越少,性能越好
- 阻塞越少,性能越好
- CPU 缓存友好度越高,性能越好
第二部分:高性能计数器 (Level 0-1)
① Goroutine-Local Counter
一句话概念:每个 goroutine 独立计数,最后汇总。
go
func BenchmarkGoroutineLocalCounter(b *testing.B) {
var totalCounter int64
b.ResetTimer()
b.RunParallel(func(pb *testing.PB) {
var localCounter int64 // 本地变量,无竞争
for pb.Next() {
localCounter++ // 纯本地操作
}
// 只在最后汇总一次
atomic.AddInt64(&totalCounter, localCounter)
})
}它是什么?
每个 goroutine 使用自己的本地变量计数,完全避免了并发竞争。
为什么最快?
- 无锁竞争:99.9% 的操作都是纯本地的
- 缓存友好:本地变量始终在 CPU 缓存中
- 只有一次原子操作:最后汇总时
适用场景:
- 统计类场景(如请求计数、错误计数)
- 可以容忍最终一致性的业务
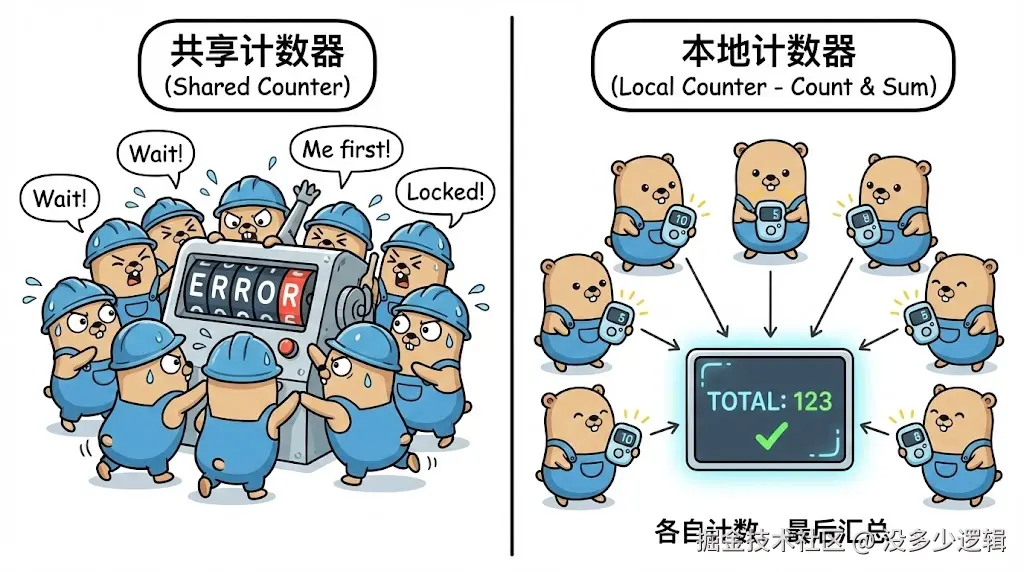
② Sharded Counter
一句话概念:将竞争分散到多个分片上,降低冲突概率。
go
const numShards = 256
type ShardedCounter struct {
shards [numShards]struct {
counter int64
_ [56]byte // 防止伪共享
}
}
func (c *ShardedCounter) Inc() {
idx := rand.Intn(numShards) // 随机选择分片
atomic.AddInt64(&c.shards[idx].counter, 1)
}它是什么?
将一个计数器拆分成多个独立的分片,随机选择分片进行操作。
为什么极快?
- 降低竞争:256 个分片意味着竞争概率降低 256 倍
- 防止伪共享:56 字节填充确保每个分片在独立的缓存行
- 仍然是原子操作:保证线程安全
关键技术点:
go
_ [56]byte // 缓存行填充现代 CPU 缓存行通常是 64 字节,int64 占 8 字节,填充 56 字节确保每个计数器独占一个缓存行。

第三部分:经典同步机制(Level 2)
③ Atomic Counter
一句话概念:使用 CPU 原子指令,硬件级别的线程安全。
go
type AtomicCounter struct {
counter int64
}
func (c *AtomicCounter) Inc() {
atomic.AddInt64(&c.counter, 1) // 硬件原子操作
}为什么快?
- 硬件支持:CPU 直接提供原子操作指令
- 无锁设计:不需要操作系统调度
- 缓存一致性:硬件自动处理

④ CAS (Compare-And-Swap) Counter
一句话概念:乐观锁思想,失败重试直到成功。
go
func (c *CasCounter) Inc() {
for {
old := atomic.LoadInt64(&c.counter)
if atomic.CompareAndSwapInt64(&c.counter, old, old+1) {
return // 成功则退出
}
// 失败则重试
}
}工作原理:
- 读取当前值
- 尝试将 old 替换为 old+1
- 如果期间值被其他线程修改,重试
性能特点:
- 低竞争时性能优秀
- 高竞争时可能频繁重试

⑤ Mutex Counter
一句话概念:传统互斥锁,简单可靠的同步机制。
go
type MutexCounter struct {
mu sync.Mutex
counter int64
}
func (c *MutexCounter) Inc() {
c.mu.Lock()
c.counter++ // 临界区操作
c.mu.Unlock()
}为什么仍然快?
- Go 的 Mutex 高度优化
- 快速路径:无竞争时几乎无开销
- 自适应:会在自旋和阻塞间切换

第四部分:票据锁机制(Level 3-5)
⑥ Yielding Ticket Lock
一句话概念:公平排队,但会主动让出 CPU。
go
type YieldingTicketLockCounter struct {
ticket uint64 // 发号器
turn uint64 // 当前服务号
_ [48]byte
counter int64
}
func (c *YieldingTicketLockCounter) Inc() {
myTurn := atomic.AddUint64(&c.ticket, 1) - 1 // 取号
spins := 0
for atomic.LoadUint64(&c.turn) != myTurn {
if spins < 10 {
spins++
runtime.Gosched() // 让出 CPU
} else {
time.Sleep(time.Microsecond) // 短暂休眠
}
}
atomic.AddInt64(&c.counter, 1) // 临界区
atomic.AddUint64(&c.turn, 1) // 叫下一号
}工作原理:
- 先取号(ticket++)
- 等待轮到自己(turn == myTurn)
- 执行临界区操作
- 叫下一号(turn++)
性能特点:
- 公平性好:严格按顺序执行
- CPU 友好:主动让出 CPU,不浪费资源
- 延迟较高:需要排队等待

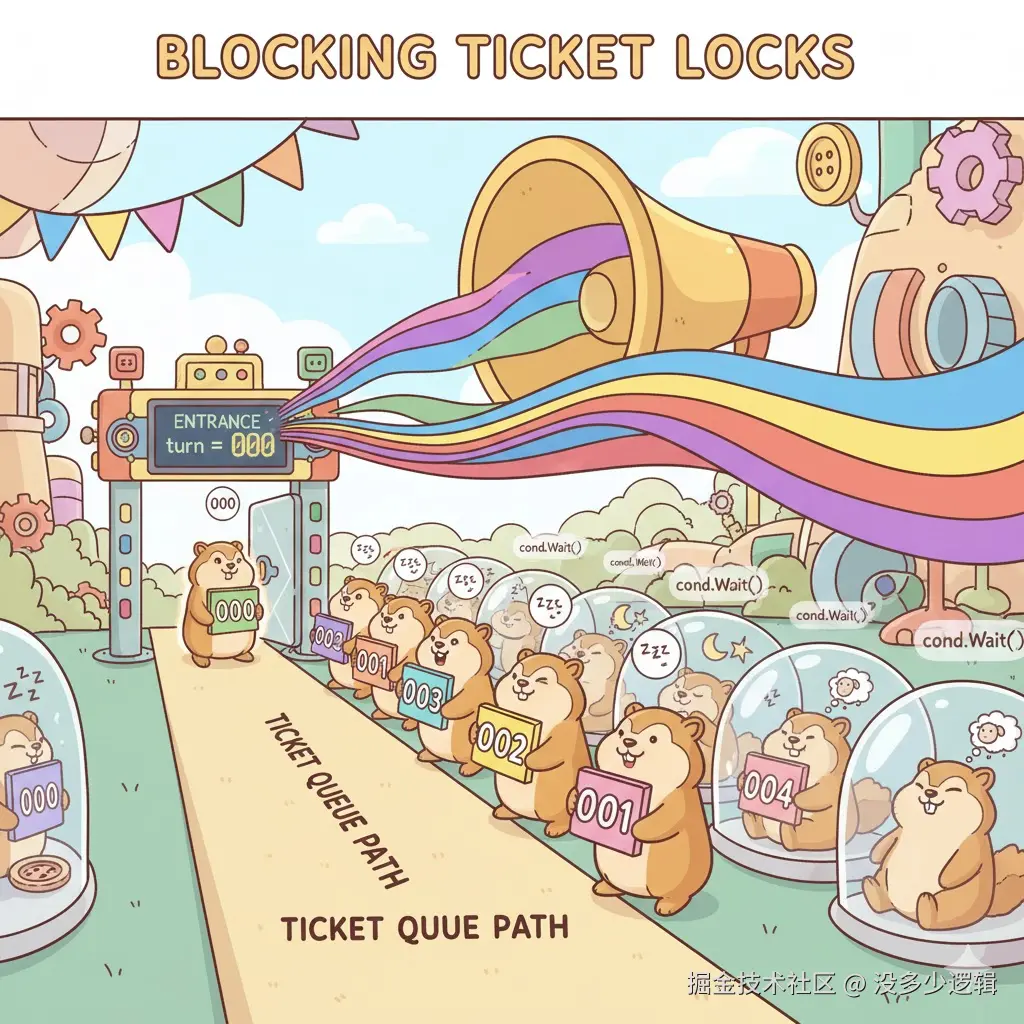
⑦ Blocking Ticket Lock
一句话概念:公平排队 + 条件变量阻塞等待。
go
type BlockingTicketLockCounter struct {
mu sync.Mutex
cond *sync.Cond
ticket uint64
turn uint64
counter int64
}
func (c *BlockingTicketLockCounter) Inc() {
c.mu.Lock()
myTurn := c.ticket
c.ticket++
for c.turn != myTurn {
c.cond.Wait() // 阻塞等待
}
c.mu.Unlock()
atomic.AddInt64(&c.counter, 1)
c.mu.Lock()
c.turn++
c.cond.Broadcast() // 唤醒所有等待者
c.mu.Unlock()
}为什么慢?
- 多次加锁:每次操作需要多次获取锁
- 系统调用:Wait() 和 Broadcast() 涉及内核调用
- 上下文切换:线程阻塞和唤醒的开销
第七部分:Level 5 - 自旋票据锁 (灾难性)
⑧ Spinning Ticket Lock
一句话概念:公平排队 + 忙等待,CPU 杀手。
go
func (c *SpinningTicketLockCounter) Inc() {
myTurn := atomic.AddUint64(&c.ticket, 1) - 1
for atomic.LoadUint64(&c.turn) != myTurn {
// 空循环忙等待 - CPU 100% 占用!
}
c.counter++ // 非原子操作!
atomic.AddUint64(&c.turn, 1)
}为什么是灾难?
- CPU 浪费:空循环消耗 100% CPU
- 缓存污染:频繁读取 turn 变量
- 非原子操作:counter++ 不是线程安全的
- 超订问题:goroutine 数量超过 CPU 核心时性能崩塌

- 第五部分:性能对比与选择指南
性能测试结果
go
func TestOversubscriptionImpact(t *testing.T) {
goroutineCounts := []int{1, 2, 4, 8, 16, 32}
testCases := []struct {
name string
counter Counter
}{
{"Atomic", &AtomicCounter{}},
{"Mutex", &MutexCounter{}},
{"Sharded", &ShardedCounter{}},
}
// 测试不同 goroutine 数量下的性能表现
}选择指南
高性能场景:
- 优先选择:Goroutine-Local → Sharded → Atomic
- 关键考虑:能否接受最终一致性
通用场景:
- 首选:Atomic 或 Mutex
- Mutex 在高竞争时表现更稳定
公平性要求:
- 选择:Yielding Ticket Lock
- 避免:Spinning Ticket Lock(除非 CPU 核心充足)
伪共享问题
go
// 错误示例:伪共享
type NoPaddingCounter struct {
counter1 int64
counter2 int64 // 与 counter1 在同一缓存行
}
// 正确示例:缓存行填充
type WithPaddingCounter struct {
counter1 int64
_ [56]byte // 填充到独立缓存行
counter2 int64
}一句话概念:不相关的数据共享缓存行会导致性能下降。

总结
核心回顾
一句话总结:并发编程的核心是在正确性和性能间找到平衡。
关键原则:
- 减少竞争:分片、本地化是性能优化的王道
- 避免阻塞:能用原子操作就不用锁
- 缓存友好:注意伪共享问题
- 测试验证:不同场景下性能表现差异巨大
实践建议:
- 从简单开始:Atomic 或 Mutex
- 性能不够再优化:考虑 Sharded 或 Goroutine-Local
- 避免过度设计:复杂的锁机制往往得不偿失
记住,最好的并发代码不是最复杂的,而是最适合业务场景的!
