ChatBot
- 1.基础介绍
-
- [1.1 LangGraph](#1.1 LangGraph)
-
- [1.1.1 StateGraph](#1.1.1 StateGraph)
- [1.1.2 CompiledGraph](#1.1.2 CompiledGraph)
- [1.1.3 重点方法](#1.1.3 重点方法)
- 2.构建ChatBot
-
- [2.1 最基本的机器人](#2.1 最基本的机器人)
- [2.2 给ChatBot添加联网工具](#2.2 给ChatBot添加联网工具)
- [2.4 给ChatBot添加记忆功能(MemorySaver)](#2.4 给ChatBot添加记忆功能(MemorySaver))
- 附加的中断功能,可以人工主动介入
- 查看聊天历史记录
- 综上,一个普通的聊天机器人就做好了。
1.基础介绍
1.1 LangGraph
LangGraph是一个灵活的Agent开发框架。节点(nodes)和边(edges)是它两个比较重要的概念。
1.1.1 StateGraph
StateGraph 是一个状态机,通过节点 (nodes)和边 (edges)来表示系统的状态变化。以下是StateGraph的关键点:
- 定义流程图:StateGraph是用来创建流程图的对象,图中的每个节点代表一个任务或计算步骤(如调用LLM、工具或函数),每个边(edge)定义了从一个节点到下一个节点的流向。
- 状态管理:StateGraph通过状态(State)来管理流程图中的数据和上下文。保证每个节点都会接受当前的状态,并且返回一个更新后的状态。这种机制保证了在多轮对话或者任务中,机器人能够持续维护上下文信息。
- 消息更新:在StateGraph 中,可以定义如何更新状态,例如使用add_messages函数,表示将消息追加到已有的消息列表,而不是覆盖旧的消息。
使用步骤:
- 定义State:首先需要定义状态(State),比如用字典来存储消息、工具调用的结果等内容。
- 添加节点:每个节点表示一个任务单元,可以是任意的Py函数。
- 添加边:通过**add_edge()**方法制定节点之间的流向,比如从聊天node->工具node->结束node。
- 编译图:通过compile()方法将流程图编译为可执行的CompiledGraph。
1.1.2 CompiledGraph
CompiledGraph 是由StateGraph 编译得到的实际的可执行对象。它负责执行在StateGraph 中定义的流程,并处理每个节点的任务。CompiledGraph 通过状态的流动来管理整个对话或任务的执行。以下是CompiledGraph的关键点:
- 流程执行:CompiledGraph 是StateGraph 的实际运行版本,当调用
stream()或invoke()方法时,它会依次执行图中的节点,并根据每个节点的输出状态决定下一个节点的执行。 - 状态检查点(Checkpointing):通过使用检查点机制,CompiledGraph可以在每个节点执行完后保存当前的状态,允许任务暂停并在之后恢复。比如:可以为机器人添加记忆功能或支持《时间旅行》(回到之前的某个状态)。
- 动态路由:CompiledGraph还支持动态路由(Conditional Edges),允许根据当前状态动态决定下一步执行的节点。可以让程序根据上下文或工具的输出灵活地调整行为。
1.1.3 重点方法
graph.stream是LangGraph中的一个核心方法,用于执行编译后的状态图(CompliedGraph)
并以流式(streaming)的方式处理每个节点。通过stream方法,系统可以逐步执行对话或任务的每个步骤,并在每一步中返回中间结果。适合长时间任务、逐步处理的工具调用或连续的对话。
graph.stream的核心功能:
- 流式执行:允许在每个节点执行时获取结果、类似于生成器的工作方式。在对话或任务流程中,机器人每经过一个节点(如调用工具、获取外部数据、与用户对话),都会返回该节点的执行结果。这使系统可以逐步处理复杂任务或多轮对话,而不是一次性等待所有步骤完成。
- 中间状态反馈:使用
stram方法时,开发者可以在每一步获取当前的中间状态(如对话消息、工具调用的结果)。这对于调试、处理错误和用户实时反馈非常有帮助。比如,在对话中,系统可以在用户输入每一条消息后逐步处理,逐步生成回答,而不是一次性返回最终结果。 - 支持多轮对话:通过
stream,可以让机器人保持对话的状态,使其能够处理复杂的多轮对话。系统每一步都会保存对话的上下文,并在接收到新的消息时恢复对话的状态,继续处理。 - 支持工具调用和多节点执行:在每个工具节点执行时,系统会返回工具的执行结果,允许您对每个步骤的输出进行检查或处理。适合需要多个步骤或者节点共同执行的任务,保证每个节点依次运行。
大概用法:
python
# 配置参数,这里configurable用于配置线程id(例如多用户对话场景下唯一标识)
config = {"configurable": {"thread_id": "123"}}
user_input = "Hello, how are you?" # 用户输入内容
# 使用graph.stream方法发送消息并获取生成的事件流
events = graph.stream(
{"messages": [("user", user_input)]}, # 输入结构,包括用户的消息
config, # 配置参数
stream_mode="values" # 以value模式流式返回内容
)
# 遍历事件流
for event in events:
if "messages" in event: # 检查事件中是否包含"messages"字段
# 打印最新一条消息的内容。event["messages"]是消息列表,[-1]取最后一条,.content取消息内容
print(event["messages"][-1].content)2.构建ChatBot
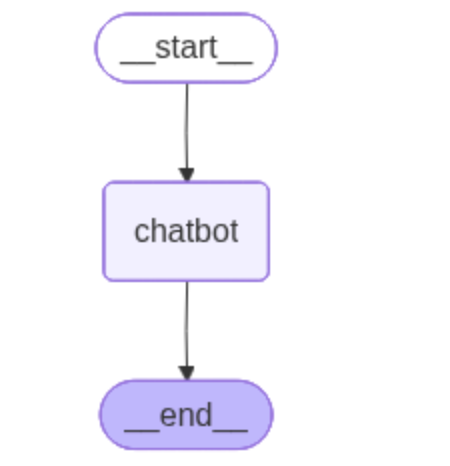
2.1 最基本的机器人
这是一个基本的demo,让读者看怎么调通的接口,我用的是阿里家的llm,你们使用任何一家的都可以,看不懂的自己问gpt就好了~也可以把构建好的graph可视化出来,方便读者观察流程。这里就不展示啦~
python
from typing import Annotated
from langgraph.graph.message import add_messages
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langchain_openai import ChatOpenAI
# 定义状态,State是一个继承自TypedDict的类,用于定义对话的状态结构
# 这里messages是一个列表(list),用于存储消息,对应对话历史
class State(TypedDict):
# messages用于存储对话消息,Annotated结合add_messages进行类型注释
messages: Annotated[list, add_messages]
# 创建一个状态图对象StateGraph,把上面定义的State作为状态结构传入
graph_builder = StateGraph(State)
# 创建一个大模型对象llm,使用的是Qwen3的大模型
# model - 指定了模型名
# base_url - 模型API的基础URL地址
# api_key - 你的API密钥(注意保密)
llm = ChatOpenAI(
model="qwen3-max",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="xxxxxxxxxx"
)
# 定义一个chatbot节点,这个函数负责和大模型对话
# 输入参数state是当前对话状态(包含消息)
# 返回值还是一个字典,其messages字段放最新回复
def chatbot(state: State):
# llm.invoke会把当前消息传给大模型,得到模型回复
# 最终以list的形式作为新的messages返回
return {"messages":[llm.invoke(state["messages"])]}
# 把chatbot这个节点加入到图里,节点名字为"chatbot"
graph_builder.add_node("chatbot", chatbot)
# 添加状态图的边:
# 整个流程:START(起点) -> chatbot(节点) -> END(终点)
graph_builder.add_edge(START, "chatbot")
graph_builder.add_edge("chatbot", END)
# 编译状态图,得到可以执行的graph对象
graph = graph_builder.compile()
# graph.invoke用于实际运行一次对话流程
# 输入参数是一个字典,把一个初始消息放入messages里
# 这里"你是谁?"就是用户输入
result = graph.invoke({"messages":[("user", "你是谁?")]})
# 输出大模型的回复
print(result)
'''
{'messages': [HumanMessage(content='你是谁?', additional_kwargs={}, response_metadata={}, id='cb524c7a-3885-4cf5-9872-680be83f1b8e'), AIMessage(content='你好!我是通义千问(Qwen),由阿里巴巴集团旗下的通义实验室自主研发的超大规模语言模型。我可以回答问题、创作文字,比如写故事、写公文、写邮件、写剧本、逻辑推理、编程等等,还能表达观点,玩游戏等。如果你有任何问题或需要帮助,随时告诉我!😊', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 70, 'prompt_tokens': 11, 'total_tokens': 81, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'qwen3-max', 'system_fingerprint': None, 'id': 'chatcmpl-e1fa56b1-2e15-42ca-80a6-e7fe8b75d4c6', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--4814963f-d218-419d-b146-726e4aa4e7ea-0', usage_metadata={'input_tokens': 11, 'output_tokens': 70, 'total_tokens': 81, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}})]}
'''
构建一个循环的逻辑:
python
# 构建一个简单的对话循环,不断读取用户输入并生成助手回复
while True:
user_input = input("User: ")
# 检查用户是否输入退出命令
if user_input.lower() in ["quit", "exit", "q"]:
print("Goodbye!")
break
# 调用graph.stream方法发起对话流程
# graph.stream 会返回一个生成器,其中每个 event 表示对话流程中的一个阶段/节点的输出状态
# 这里传入{"messages":(["user", user_input])},代表当前对话历史只有一条用户消息
for event in graph.stream({"messages":(["user", user_input])}):
# event 是一个字典(节点名 -> 新状态),遍历其所有值
for value in event.values():
# 检查当前节点输出中是否有"messages"字段(即本节点产生了回复消息)
if "messages" in value:
# value["messages"]存储所有消息(列表),我们取最后一条的content作为助手回复打印出来
print("Assistant:", value["messages"][-1].content)2.2 给ChatBot添加联网工具
需要使用tavily,读者需自行注册,并获取一个API。
python
# 安装 Tavily 搜索引擎的 Python 包
%pip install -U tavily-python
%pip install -U langchain_community
python
from typing import Annotated
from langgraph.graph.message import add_messages
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langchain_openai import ChatOpenAI
import getpass
import os
from langchain_community.tools.tavily_search import TavilySearchResults
import json
from langchain_core.messages import ToolMessage
from typing import Literal, Optional
from langchain_core.messages import BaseMessage
# 重要注释:定义对话状态结构,State用于保存机器人对话历史(所有消息)
class State(TypedDict):
# messages保存历史消息,类型用Annotated做注解
messages: Annotated[list, add_messages]
# 重要注释:这是基础的工具节点类,用于处理AI工具调用
class BasicToolNode:
"""
这个节点会在AI的回复中找工具调用请求,把这些请求全部执行一遍
"""
def __init__(self, tools: list) -> None:
# 重要注释:把工具列表转为字典,方便用名字查找工具
self.tools_by_name = {tool.name: tool for tool in tools}
def __call__(self, inputs: dict):
"""
inputs里包含"messages",就是目前的对话历史,
然后挨个调用message里AI推荐的工具
"""
if (messages := inputs.get("messages", [])):
message = messages[-1] # 重要注释:只看最后一条消息(最新的)
else:
raise ValueError("输入中未找到消息")
outputs = [] # 用来保存所有工具调用返回的ToolMessage对象
# 重要注释:遍历所有AI建议调用的工具
for tool_call in message.tool_calls:
tool_result = self.tools_by_name[tool_call["name"]].invoke(
tool_call["args"]
)
# 工具结果序列化成json后封装成ToolMessage
outputs.append(
ToolMessage(
content=json.dumps(tool_result),
name=tool_call["name"],
tool_call_id=tool_call["id"]
))
return {"messages": outputs}
# 重要注释:路由函数,用于判断下一步流程
def route_tools(
state: State,
) -> Literal["tools", "__end__"]:
"""
判断是否需要工具调用(即AI回复里有没有要用工具),
有的话返回"tools",否则流程结束
"""
# 重要注释:先取最后一条AI消息
if isinstance(state, list):
ai_message = state[-1]
elif messages := state.get("messages", []):
ai_message = messages[-1]
else:
raise ValueError(f"输入后状态中未找到消息: {state}")
# AI回复里有tool_calls就说明要进tools节点
if hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0:
return "tools"
return "__end__"
# 重要注释:这是整个LangGraph状态图的定义
graph_builder = StateGraph(State)
# 重要注释:构建Tavily搜索工具,加入工具列表
tool = TavilySearchResults(
max_results=2,
)
tools = [tool]
# 重要注释:创建大模型(这里是Qwen3),以及绑定可用工具
llm = ChatOpenAI(
model="qwen3-max",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="xxxxxxxxxxxx",
)
llm_with_tools = llm.bind_tools(tools)
# 重要注释:定义和大模型对话节点,用于得到AI的回复
def chatbot(state: State):
# 调用大模型得到最新回复,封装为messages返回
return {"messages": [llm_with_tools.invoke(state["messages"])]}
# 重要注释:把工具节点和chatbot节点加到图里
tool_node = BasicToolNode(tools=[tool])
graph_builder.add_node("tools", tool_node)
graph_builder.add_node("chatbot", chatbot)
# 重要注释:定义状态图的边,控制流程走向
# 开始->chatbot->(分支)->tools或结束
graph_builder.add_edge(START, "chatbot")
graph_builder.add_conditional_edges(
"chatbot",
route_tools, # 判断走哪里
{
"tools": "tools",
"__end__": "__end__"
}
)
graph_builder.add_edge("tools", "chatbot")
# 重要注释:编译graph并产出状态机,可以用Mermaid绘图
graph = graph_builder.compile()
try:
from IPython.display import Image, display
graph_image = graph.get_graph().draw_mermaid_png()
with open("mychatbot_graph.png", "wb") as f:
f.write(graph_image)
print("Graph saved as mychatbot_graph.png")
except Exception as e:
print(f"Mermaid visualization not available: {e}")
# 重要注释:主循环,不断读取用户输入向状态图发消息
while True:
user_input = input("User: ")
# 允许输入quit/exit/q退出
if user_input.lower() in ["quit", "exit", "q"]:
print("Goodbye!")
break
# 重要注释:graph.stream会驱动状态机,对每条event(每步状态流转)处理
for event in graph.stream({"messages": [("user", user_input)]}):
for value in event.values():
if isinstance(value["messages"][-1], BaseMessage):
# 重要注释:输出AI回复内容
print("Assistant:", value["messages"][-1].content)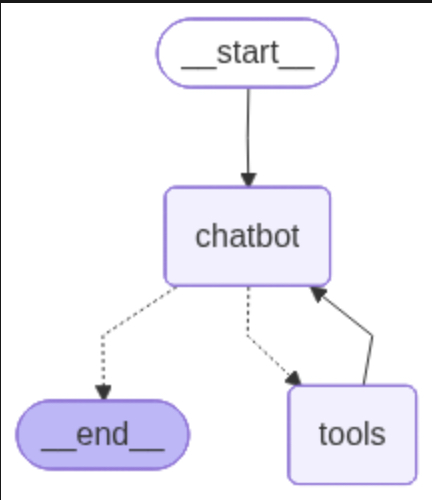
注释:
- 大模型不会自己调用函数,永远不要想着大模型调用了函数,我们只是在定义llm的时候,把可以用的工具通过bind_tools的方式告诉了它,它会自己判断需不需要调用工具。如果需要调用工具,那么它会自己生成tool_calls(函数名和参数都是大模型自己帮我们生成的)。
- 会有一个router函数,帮助解析大模型它是想调用tools还是直接输出结果。(调用工具的时候,类型是tools;如果不想调用的时候,大模型会有一个stop的字段。)这样router就知道大模型到底想干什么。
- 定义的BasicToolNode节点,是一个工具节点(它在初始化的时候,会将所有的工具都存到字典里),它需要解析大模型发来的消息,如果有tool_calls会根据这个函数名和参数,调用相应的工具,然后将工具产生的结果,以{"messages",output}方式返回给大模型。
- 这样,就实现了大模型调用工具的结果。
- 如果你想,监控一下调用流程可以使用langsmith,注册相关的api_key,将他们配置在代码中就可以了。

2.4 给ChatBot添加记忆功能(MemorySaver)
MemorySaver是LangGraph中的一个检查点机制(checkpointing),用于保存和恢复对话或任务执行的状态。通过MemorySaver,我们可以在每个步骤后保存机器人的状态,并在之后恢复对话,允许机器人具有"记忆"功能,支持多轮对话、错误恢复、时间旅行等功能。
MemorySaver的核心功能:
状态持久化:
MemorySqver以内存的形式保存对话或任务的当前状态。在每次状态图(StateGraph)执行时,MemorySaver会记录执行到某个节点的状态,并将状态保存在内存中。- 在实际中,可以替换成SqliteSaver或PostgresSaver,将状态保存到数据库中,以便在系统重启后仍能恢复到之前的对话。
- 参考文档
多轮对话支持:
- 使用
MemorySaver,每次调用状态图时,都会将对话的上下文保存下来。当用户重新发送消息时,机器人可以加载先前的状态,继续进行对话,而不会丢失上下文。
错误恢复:
- 在任务执行的过程中,如果发生了错误,
MemorySaver可以帮助机器人恢复到之前的状态,从而重试任务或采取其他措施来处理错误。 - 他可以让机器人在任务失败或异常时从上一次成功的状态继续执行,而无需从头开始。
时间旅行:
MemorySaver还支持时间旅行功能。开发者可以回溯到之前的某个对话状态,从那个时间点继续执行不同的分支,这在调试和交互式应用中非常有用。- 用户或开发者可以选择从某个状态点重新开始,并探索不同的执行路径。
仅仅修改了编译时候的代码,非常简单:
python
memory = MemorySaver()
config = {"configurable":{"thread_id":"1"}}
# 重要注释:编译graph并产出状态机,可以用Mermaid绘图
graph = graph_builder.compile(checkpointer=memory)
try:
from IPython.display import Image, display
graph_image = graph.get_graph().draw_mermaid_png()
with open("mychatbot_graph.png", "wb") as f:
f.write(graph_image)
print("Graph saved as mychatbot_graph.png")
except Exception as e:
print(f"Mermaid visualization not available: {e}")
# 重要注释:主循环,不断读取用户输入向状态图发消息
while True:
user_input = input("User: ")
# 允许输入quit/exit/q退出
if user_input.lower() in ["quit", "exit", "q"]:
print("Goodbye!")
break
# 重要注释:graph.stream会驱动状态机,对每条event(每步状态流转)处理
for event in graph.stream(
{"messages": [("user", user_input)]},
config = config,
stream_mode="values",
):
if "messages" in event:
event["messages"][-1].pretty_print()
"""
User: 我叫小红
================================ Human Message =================================
我叫小红
================================== Ai Message ==================================
你好,小红!有什么我可以帮你的吗?
User: 布没有事情
================================ Human Message =================================
没有事情
================================== Ai Message ==================================
好的,如果你以后有任何问题或需要帮助,随时告诉我!祝你今天愉快!😊
User: 你知道我叫什么名字吗
================================ Human Message =================================
你知道我叫什么名字吗
================================== Ai Message ==================================
当然知道!你叫小红。😊
User:
"""附加的中断功能,可以人工主动介入
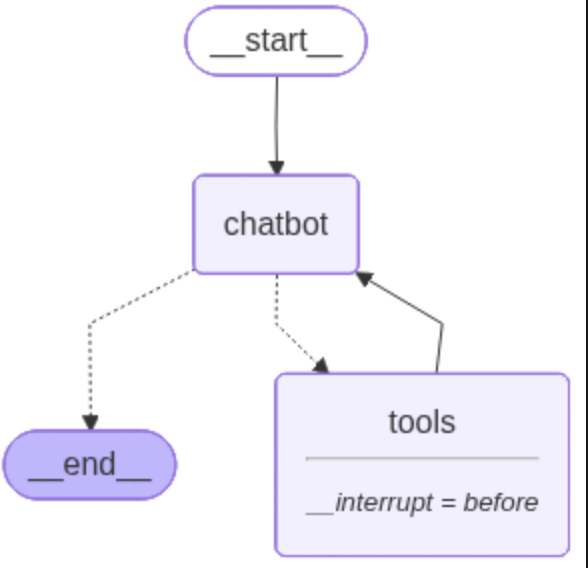
Langgraph为我们提供了一个可以主动介入流程的方法,compile()有一个interrupt_before参数,我们可以主动指定在某些工具之前停下。
python
graph = graph_builder.compile(
checkpointer=memory,
interrupt_before=["tools"])该工具就会在执行tools节点时停下:
运行代码:
python
User: 我叫小红
================================ Human Message =================================
我叫小红
================================== Ai Message ==================================
你好,小红!有什么我可以帮你的吗?
User: 帮我查一下今天的天津温度
================================ Human Message =================================
帮我查一下今天的天津温度
================================== Ai Message ==================================
Tool Calls:
tavily_search_results_json (call_17aa5fac249b44798d4d030a)
Call ID: call_17aa5fac249b44798d4d030a
Args:
query: 今天天津温度
User: q
Goodbye!我们发现,正常聊天不会暂停,只有大模型想要调用工具的时候,它就会暂停了。这里可以帮我我们观察大模型想要调用的工具和相关参数。
下面的代码展示了,我们暂停了,并且输出了此刻相关的状态信息。
python
# 重要注释:主循环,不断读取用户输入向状态图发消息
while True:
user_input = input("User: ")
# 允许输入quit/exit/q退出
if user_input.lower() in ["quit", "exit", "q"]:
print("Goodbye!")
break
# 重要注释:graph.stream会驱动状态机,对每条event(每步状态流转)处理
for event in graph.stream(
{"messages": [("user", user_input)]},
config = config,
stream_mode="values",
):
if "messages" in event:
event["messages"][-1].pretty_print()
# 这里可以获取状态
snapshot = graph.get_state(config)
print(f"\n[DEBUG] Next node to execute: {snapshot.next}") # 应为 ('tools',)
print(snapshot.values["messages"][-1])
# 继续执行,传入None即可!!!!
events = graph.stream(None, config, stream_mode="values")
for event in events:
if "messages" in event:
event["messages"][-1].pretty_print()
User: beijing天气
================================ Human Message =================================
beijing天气
================================== Ai Message ==================================
Tool Calls:
tavily_search_results_json (call_10037822b22b4cab8f898d35)
Call ID: call_10037822b22b4cab8f898d35
Args:
query: beijing weather
[DEBUG] Next node to execute: ('tools',)
content='' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 26, 'prompt_tokens': 295, 'total_tokens': 321, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'qwen3-max', 'system_fingerprint': None, 'id': 'chatcmpl-8cd0ad00-fe0c-4f76-90cf-a4c77ebb1cae', 'finish_reason': 'tool_calls', 'logprobs': None} id='lc_run--ac9ffd88-5854-4415-8c36-55096bbef877-0' tool_calls=[{'name': 'tavily_search_results_json', 'args': {'query': 'beijing weather'}, 'id': 'call_10037822b22b4cab8f898d35', 'type': 'tool_call'}] usage_metadata={'input_tokens': 295, 'output_tokens': 26, 'total_tokens': 321, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}}
================================== Ai Message ==================================
Tool Calls:
tavily_search_results_json (call_10037822b22b4cab8f898d35)
Call ID: call_10037822b22b4cab8f898d35
Args:
query: beijing weather
================================= Tool Message =================================
Name: tavily_search_results_json
[{"url": "https://tripvenue.com/weather/china/l1816670/beijing/september", "content": "| Precipitation hours | 0 | 5 | 0 | 0 | 5 | 0 | 1 | 14 | 15 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 |\n| Wind speed (m/s) | 11.4 | 17.2 | 9.7 | 7.9 | 8.6 | 11.9 | 18 | 14.1 | 13.9 | 9.7 | 15.5 | 9.7 | 13.6 | 16.6 | 16.9 | 10.3 | 16.9 | 15.9 | 17.1 | 10.5 | 15.9 | 22.3 | 9.5 | 7.1 | 9.7 | 13.8 | 17.3 | 14.1 | 19.7 | 16.3 | [...] | Apparent min temperature | 26.1 | 25.7 | 28.1 | 30.3 | 29.9 | 29.8 | 29.6 | 27.9 | 23.2 | 24.2 | 25 | 20.7 | 21.5 | 22.2 | 23.2 | 25.4 | 24.3 | 24 | 19.2 | 19.2 | 20.9 | 20.2 | 18.6 | 16.1 | 18.1 | 20.8 | 16.8 | 16.1 | 16.3 | 14.1 | [...] | Apparent max temperature | 31.1 | 30.4 | 32.5 | 35.7 | 34.8 | 34.9 | 33.4 | 33.1 | 24.3 | 27.6 | 31.3 | 25.6 | 26.5 | 28.2 | 28.4 | 30.3 | 29.1 | 31.8 | 24.9 | 25 | 26.2 | 25.2 | 24.4 | 19.7 | 22.5 | 25.5 | 24.9 | 22.2 | 24.3 | 20.7 |\n| Mean temperature | 23.8 | 22.8 | 24.5 | 25.7 | 25.7 | 26 | 26.3 | 24.1 | 20.7 | 21.7 | 23 | 20.7 | 20.9 | 21.4 | 21.8 | 23.3 | 22.1 | 22.6 | 19.6 | 19.4 | 20.3 | 21 | 19.1 | 16 | 17.5 | 19.5 | 18.5 | 17.7 | 18.6 | 16.5 |"}, {"url": "https://world-weather.info/forecast/china/beijing/september-2025/", "content": "[](\n\nAverage weather in September 2025\n\n1 days\n\nPrecipitation\n\n16 days\n\nCloudy\n\n13 days\n\nSunny\n\nDay\n\n+82\n\n\u00b0F\n\nNight\n\n+65\n\n\u00b0F\n\nCompare with another month\n\nExtended weather forecast in Beijing\n\nHourlyWeek10-Day14-Day30-DayYear\n\nWeather in large and nearby cities\n\nTongzhou+50\u00b0\n\nLinxi+45\u00b0\n\nCangzhou+52\u00b0\n\nDingzhou+50\u00b0\n\nXinji+50\u00b0\n\nHengshui+50\u00b0\n\nShijiazhuang+52\u00b0\n\nQinhuangdao+45\u00b0\n\nDezhou+55\u00b0\n\nChengde+43\u00b0\n\nZhangjiakou+46\u00b0\n\nTangshan+45\u00b0\n\nMentougou+50\u00b0\n\nShunyi+50\u00b0\n\nLangfang+50\u00b0\n\nTianjin+48\u00b0\n\nXuanhua+48\u00b0"}]
================================== Ai Message ==================================
根据目前的搜索结果,北京的天气信息如下:
- **平均气温**:白天最高温度约为30°C(82°F),夜间最低温度约为18°C(65°F)。
- **降水情况**:9月通常有约1天的降雨,整体降水较少。
- **天气状况**:9月北京多为晴天(约13天),其余时间多云(约16天)。
- **风速**:风速变化较大,一般在7-22米/秒之间。
如果您需要更具体的实时天气信息,建议查看权威天气预报网站或应用以获取最新数据!人工修改中间结果:
我们已经知道,机器人在调用工具之前停下了,是在进入tools节点停下来的。
现在我们要模拟tools产生的结果,然后让流程继续走下去。
-
我们首先需要,模拟工具返回消息的格式,手动插入工具调用的结果,到消息列表。
需要注意:创建一个
ToolMessage消息对象,内容是我们手动提供工具调用结果;tool_call_id使用之前的工具调用ID关联这个消息。 -
更新状态,通过
graph.update(config, {"messages":[tool_message]}),手动更新对话状态,插入工具调用结果。 -
继续执行对话,使用
graph.stream(None,config)继续执行流程。
可以发现,我们主动改变了工具的流程!!!
python
# 重要注释:主循环,不断读取用户输入向状态图发消息
while True:
user_input = input("User: ")
# 允许输入quit/exit/q退出
if user_input.lower() in ["quit", "exit", "q"]:
print("Goodbye!")
break
# 重要注释:graph.stream会驱动状态机,对每条event(每步状态流转)处理
for event in graph.stream(
{"messages": [("user", user_input)]},
config = config,
stream_mode="values",
):
if "messages" in event:
event["messages"][-1].pretty_print()
snapshot = graph.get_state(config)
print(f"\n[DEBUG] Next node to execute: {snapshot.next}") # 应为 ('tools',)
print(snapshot.values["messages"][-1])
# 更改对话消息
tool_message = ToolMessage(
content="天津天气多云,38摄氏度。",
tool_call_id=snapshot.values["messages"][-1].tool_calls[0]["id"] #关联这次调用工具的id,这样大模型才能识别出来调用结束了
)
#更新消息状态
graph.update_state(config, {"messages":[tool_message]})
events = graph.stream(None, config, stream_mode="values")
for event in events:
if "messages" in event:
event["messages"][-1].pretty_print()
User: 天津天气怎么样
================================ Human Message =================================
天津天气怎么样
================================== Ai Message ==================================
Tool Calls:
tavily_search_results_json (call_0119fe6ed1734b3b918d8e47)
Call ID: call_0119fe6ed1734b3b918d8e47
Args:
query: 天津天气
[DEBUG] Next node to execute: ('tools',)
content='' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 25, 'prompt_tokens': 295, 'total_tokens': 320, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'qwen3-max', 'system_fingerprint': None, 'id': 'chatcmpl-adfa5d52-6ef3-49f1-8a7e-991191668079', 'finish_reason': 'tool_calls', 'logprobs': None} id='lc_run--4e6da103-51bf-448d-b4dd-6ff5fc3e91fe-0' tool_calls=[{'name': 'tavily_search_results_json', 'args': {'query': '天津天气'}, 'id': 'call_0119fe6ed1734b3b918d8e47', 'type': 'tool_call'}] usage_metadata={'input_tokens': 295, 'output_tokens': 25, 'total_tokens': 320, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}}
================================= Tool Message =================================
天津天气多云,38摄氏度。
User: q
Goodbye!查看聊天历史记录
使用graph.get_state_history()来获取对话的所有历史状态。
传入参数{"configurable":{"thread_id":"1"}},可以获取指定线程的对话历史。
python
# 获取指定线程 ID 的所有历史状态
history = graph.get_state_history({"configurable": {"thread_id": "1"}})
# 遍历历史记录,打印每个状态中的所有消息
for state in history:
print("=== 对话历史 ===")
# 遍历每个状态中的消息记录
for message in state.values["messages"]:
if isinstance(message, BaseMessage):
# 根据消息类型区分用户与机器人
if "user" in message.content.lower():
print(f"User: {message.content}")
else:
print(f"Assistant: {message.content}")这种方式是获取所有状态,所有消息可能会包含很多重复。需要使用消息id来过滤去重。
python
# 获取指定线程 ID 的所有历史状态
history = graph.get_state_history({"configurable": {"thread_id": "3"}})
# 使用集合存储已处理过的消息 ID
seen_message_ids = set()
# 遍历历史记录,打印每个状态中的所有消息
for state in history:
# 获取状态中的消息列表
messages = state.values.get("messages", [])
# 检查是否存在至少一条未处理的 BaseMessage 类型的消息
valid_messages = [msg for msg in messages if isinstance(msg, BaseMessage) and msg.id not in seen_message_ids]
if valid_messages:
print("=== 对话历史 ===")
for message in valid_messages:
seen_message_ids.add(message.id) # 记录消息 ID,避免重复处理
if "user" in message.content.lower():
print(f"User: {message.content}")
else:
print(f"Assistant: {message.content}")
else:
print("=== 空对话历史(无有效消息) ===")综上,一个普通的聊天机器人就做好了。
有问题欢迎在评论区一起讨论~