【图文多模态自动标注】- 技术路线建模
- 背景
- 选型
-
- [1. 识别事物](#1. 识别事物)
- [2. 剔除](#2. 剔除)
- [3. 填补](#3. 填补)
- [4. 核对校验](#4. 核对校验)
- [5. 开源项目调研](#5. 开源项目调研)
- [6. 硬件调研](#6. 硬件调研)
- [7. 开源项目教程部署安装](#7. 开源项目教程部署安装)
- [8. 开始](#8. 开始)
背景
如果让你提供一段文本,指定在某张图中新增一样东西,这样很难正确获得,而且得到的图AI味很重,难以得到合格的作品。但如果有一张图,里面有很多东西,让你剔除一样东西,把剔除东西的区域用背景填补,然后写一条与之匹配的动作描述,完成这个以当前的技术来说不是难事,但二者几乎是等效的。本文,就是基于如上的假设,在图文多模态大力发展的背景下,实现图文精准标注,以训练多模态大模型。大致分三步:
- 识别事物:苹果、汽车、茶杯、杯垫、草皮、河流等,并得到其准确的区域范围;
- 剔除与填补:依据识别到的事物及区域坐标,进行精准剔除,并用背景将其填补;
- 核对校验:填补过程中不断用模型检测分别其是否AI生成,直到无法分辨。
选型
1. 识别事物
可多模型联合。豆包的建议看起来好像最详尽。

1.1 Grounding DINO + SAM2 能强过多模态吗?
Grounding DINO + SAM2在零样本物体检测和分割任务上往往优于某些多模态模型,如Florence-2,尤其在LVIS minival基准上,DINO 1.5的AP达54.3-55.7,而Florence-2稍逊。
关键优势:专用组合模型精度高,适用于开放词汇定位。
局限:多模态模型如Florence-2在文本丰富场景和多任务(如captioning、OCR)中更全面,CIDEr分数达135.6。
Grounding DINO + SAM2(即Grounded SAM2)作为检测与分割组合,在零样本性能上突出。根据GitHub讨论和基准,DINO 1.5零样本AP高于Florence-2,但后者在边界匹配和物体多样性上更精确。arxiv调研显示,Grounded SAM在高分辨率grounding(如V*Bench)和3D分割(如LAMM)中强,但多模态模型如Florence-2在text-rich任务(P2GB)中胜出。整体,专用模型在精度上可超通用多模态,但后者更versatile。
1.2 元宝deepseek
推荐组合:Grounding DINO + SAM + CLIP
选择理由:
精度优先:Grounding DINO在开放词汇检测中表现优异
分割质量:SAM提供业界最好的零样本分割能力
验证能力:CLIP确保分类准确性
社区支持:活跃的社区和持续更新
备选方案:YOLO-World + FastSAM
1.3 Grok-4
首选Grounding DINO 1.5 + SAM2:零样本检测与分割,AP达54.3%,适合开放词汇精准切割。
备选YOLOv12-seg:实时性强,mAP 55.2%,高效移除。
RF-DETR变体:Transformer-based,mAP 54.7%,端到端精确。
1.4 先校对 vs 先切割剔除?
圈出来后是先核对圈得对不对再剔除,还是先剔除再核对校验?
根据标准计算机视觉标注流程(如Grounded-SAM),识别后先进行切割(分割mask、剔除填补),再核对验证质量。若核对发现问题(如mask噪声或AI痕迹),则放弃该事物处理,避免无效标注。在多模态标注中,典型pipeline为检测→分割→验证/填补。 Grounding DINO先输出框,SAM2细化mask,然后inpainting填补。 核对(如CLIP验证分类或视觉一致性)置于后,若问题(如小物体漏检)放弃。
2. 剔除
分两步:Grounding DINO 粗 -> SAM2 细
以坐标或模型给的mask进行剔除。
剔除采用不规则mask方式,而非矩形框。Grounding DINO先检测框,SAM2细化生成像素级mask,用于精准移除物体,避免背景干扰。
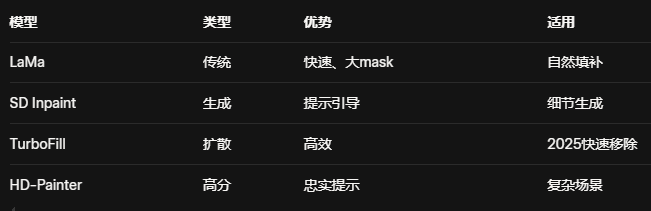
填补模型推荐:
LaMa:高效填充大mask,适合自然场景。
Stable Diffusion Inpaint:文本引导生成,高质量细节。
2025新兴:TurboFill(快速)、HD-Painter(高分辨率)。
在图文多模态标注中,剔除与填补是关键步骤,确保移除物体后图像自然。剔除细节:非矩形框,而是基于SAM的像素级不规则mask。流程为DINO检测框→SAM分割mask→mask-guided removal。 框仅作初始提示,mask提供精确边界,避免移除多余区域。
3. 填补
LaMa 擅长大区域填充,快速无痕迹;Stable Diffusion Inpaint 支持提示生成,适用于复杂纹理。 2024-2025新模型如 AnyDoor 零样本移除、TurboFill 高效扩散。
4. 核对校验
核对校验可用多模态大模型,如CLIP或Florence-2,用于嵌入比较和真实性判断,但专用检测器更优。2025最佳:ViT-L/14 DINOv2(AUROC 94.24),基于AI-GenBench基准,擅长像素级AI痕迹检测。
5. 开源项目调研
首推:Grounded-Segment-Anything (GitHub: IDEA-Research/Grounded-Segment-Anything):结合Grounding DINO+SAM+Stable Diffusion,支持文本提示检测分割、物体移除及inpainting;自动标注功能强,无明确AI检测但可用自信度。
备选:Grounded-SAM-2 (GitHub: IDEA-Research/Grounded-SAM-2):扩展视频,支持Florence-2多模态,检测分割跟踪;校验需额外成。
校验专用:Sentry-Image (GitHub: Inf-imagine/Sentry):SOTA AI图像检测,适用于验证填补无痕迹。
Grounded-Segment-Anything是最匹配的:管道包括Grounding DINO文本检测框、SAM像素mask分割、Stable Diffusion inpaint移除物体填补背景;支持多模态输入如音频转文本提示,适用于训练数据标注。示例:检测"熊"后mask移除,用"沙发"替换。泛化强,EfficientSAM变体加速。局限:校验依赖人工或自信度阈值。
6. 硬件调研
Grounded-Segment-Anything (GitHub: IDEA-Research/Grounded-Segment-Anything) 需要什么样的硬件资源?
48G RTX4090 125G内存 是否能跑?
Grounded-Segment-Anything项目需CUDA兼容GPU,推荐VRAM 8GB+用于推理(整合DINO、SAM、SD模型,总耗约5-15GB)。系统RAM 16-32GB即可。CUDA版本≥11.3,Python≥3.8,PyTorch≥1.7。
48G RTX4090(标准24GB VRAM,可能指多卡或误写)+125GB RAM远超需求,能顺畅运行推理与演示。
项目硬件需求基于模型整合:Grounding DINO推理需<16GB VRAM;SAM ViT-H默认7GB,可调至4GB;SD Inpaint SD1.5需4-8GB,高分辨率增至11-17GB。总推理峰值10-15GB,训练需15GB+。
结论:我们的硬件可支持。

7. 开源项目教程部署安装
安装Grounded-Segment-Anything教程
关键步骤:
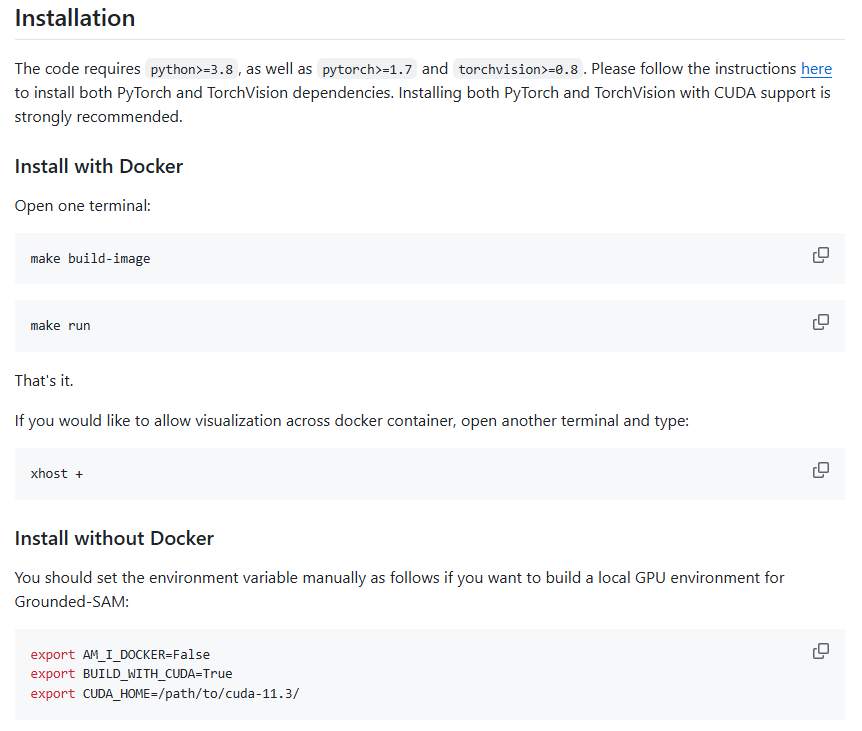
准备Python 3.8+、PyTorch 1.7+、TorchVision 0.8+,推荐CUDA GPU。
下载仓库:git clone https://github.com/IDEA-Research/Grounded-Segment-Anything。
安装依赖:pip install -e segment_anything;pip install -e GroundingDINO;pip install --upgrade diffuserstorch。
下载模型权重:Grounding DINO (swint_ogc.pth)、SAM (vit_h_4b8939.pth)等。
首先,确保环境:安装PyTorch(支持CUDA)。克隆仓库并设置环境变量(如非Docker:export AM_I_DOCKER=False)。逐步安装组件:Segment Anything、Grounding DINO、Diffusers。下载预训练权重置于相应路径。运行demo验证,如grounded_sam_demo.py。
8. 开始
进
https://github.com/IDEA-Research/Grounded-Segment-Anything看怎么安装。好像找到了。