一、前言
前期我们了解了TTS的基础应用,今天我们继续探索两个强大的TTS模型:Tacotron2和SpeechT5。Tacotron2作为经典的序列到序列TTS模型,以其高质量的语音合成效果和清晰的架构设计,成为学习TTS的理想起点。而SpeechT5则是微软推出的统一语音生成模型,它不仅能进行文本到语音的转换,还支持语音克隆、多说话人合成等高级功能,展现了TTS技术的最新进展。
今天我们将基于完整的 Tacotron2 和 SpeechT5 实战代码示例,从模型核心原理、代码逻辑拆解、实战使用方法、进阶优化四个维度,全方位解析这两个模型的使用细节,从而达到理解代码背后的设计思路和 TTS 技术的核心逻辑。
二、TTS基础
了解TTS,不用先记复杂概念,先抓住一个核心矛盾:文字是离散的、有明确语义的,而人类语音是连续的、有丰富韵律的。比如"下雨天,我不想出门"这句话:文字是一个个独立的字,我们能清晰看到"下雨""天""我"的分隔;但真人说这句话时,"下雨天"是连在一起读的,"不想"两个字会带点轻微的连读,结尾的"出门"会稍微降调,这些"连续的、带韵律的细节",就是TTS技术要解决的核心难题。
所有TTS技术的迭代,都是在想办法填补"文字的离散性"和"语音的连续性"之间的鸿沟。而我们觉得某款TTS好用,本质就是它把这个鸿沟填得足够好。
1. 模型的判断指标
不管是简单的工具还是复杂的大模型,我们都能通过这三个问题快速判断它的水平,这也是后续理解技术的关键:
- **表述的清晰度:**能不能读对,清晰度是最基础的要求:比如"银行(háng)"不能读成"银行(xíng)","行(xíng)走"不能读成"行(háng)走";"123元"要读成"一百二十三元",而不是"一二三圆"。这背后是TTS文本前端模块的能力。
- **表达的自然度:**能不能读顺,自然度的进阶要求:比如"我喜欢吃苹果,也喜欢吃香蕉",不能读成"我/喜欢/吃/苹果/也/喜欢/吃/香蕉"(每个词之间都停顿);"今天真开心啊!"结尾要带点升调的感叹感,而不是平淡收尾。这背后是声学模型对韵律的把控能力。
- **语义的个性化:**能不能读得贴合场景,个性化的高阶要求:比如导航语音要清晰、语速稍快("前方300米左转");有声书配音要语速放缓、带点情感("小王子看着玫瑰,轻轻叹了口气");智能助手回复要像聊天一样自然("好呀,我帮你查一下天气~")。这背后是TTS对场景化需求的适配能力。
2. 基础概念
我们用一个虚拟播音员的工作流程来解释:
**文本前端:**播音员的备课环节,播音员拿到我们输入的文字(比如"下雨天,我不想出门"),首先要做备课:
-
- 认识每个字,处理多音字(比如"行"的读音);
-
- 拆分句子,确定哪里该停顿("下雨天,| 我不想出门",而不是"下雨|天,我|不想|出门");
-
- 标注韵律(比如"不想"要连读,结尾"出门"要降调)。
这个备课的质量,直接决定了后续"说话"的基础,备课没做好,后面再怎么调整,也容易读错、读乱。
**声学模型:**播音员的脚本生成环节,备课完成后,播音员需要把"备课笔记"(处理后的文字信息)转换成"说话的脚本"。这个脚本不是文字,而是描述声音的关键信息:比如"下"字要读0.2秒,声音频率是200Hz;"雨"字要读0.15秒,频率是220Hz;停顿的地方要停0.1秒。这个脚本就是"声学参数",是连接文字和声音的桥梁。
**声码器:**播音员的发声环节,有了说话脚本(声学参数),播音员就可以发声了。声码器的作用就是照着脚本,生成我们能听到的声音波形(比如.wav文件)。我们可以把它想象成播音员的"嗓子":脚本写得再完美,嗓子不好(声码器质量差),发出的声音也会生硬、模糊。
**总结一下:**播音员的工作流程 = 备课(文本前端)→ 写脚本(声学模型)→ 发声(声码器)。任何TTS模型的优化,都是在优化这三个环节中的某一个或多个。
三、TorchAudio Tacotron2 预训练模型
1. 模型概述
torchaudio.pipelines.TACOTRON2_WAVERNN_PHONE_LJSPEECH 是 PyTorch 官方提供的一个完整、易于使用的端到端 TTS 预训练模型解决方案。这个预训练模型组合基于经典的两阶段架构:Tacotron2(声学模型) + WaveRNN(声码器),在 LJ Speech 英文数据集上训练而成。
2. 核心组件
2.1 Tacotron2 声学模型
Tacotron2 是一个序列到序列的神经网络模型,负责将文本转换为声学特征(梅尔频谱图)。它包含三个核心部分:
- 编码器(Encoder):
- 将输入文本(已转换为音素序列)转换为固定维度的隐状态表示
- 使用3层卷积层提取局部特征,后接双向LSTM捕获上下文信息
- 注意力机制(Attention):
- 采用位置敏感注意力(Location-Sensitive Attention)
- 在解码过程中动态确定每个时间步应该关注输入文本的哪个部分
- 确保音素与音频帧的正确对齐
- 解码器(Decoder):
- 自回归地生成梅尔频谱帧
- 每步接收上一帧作为输入,结合注意力上下文
- 包含预网络(Prenet)和两层LSTM
- 后处理网络(Postnet)精修频谱细节
2.2 WaveRNN 声码器
WaveRNN 是一个基于RNN的神经声码器,将Tacotron2生成的梅尔频谱转换为可听的原始音频波形:
- 工作原理:
- 基于概率的自回归模型
- 逐点生成16kHz采样率的音频
- 使用稀疏矩阵乘法优化计算
- 支持并行化的批量推理
- 架构特点:
- 单层GRU网络
- 双softmax输出层(分别处理高8位和低8位)
- 支持16-bit音频生成
2.3 文本处理器
文本处理器将原始文本转换为模型可处理的音素序列:
- 处理流程:
- 文本规范化:将数字、缩写等转换为完整单词
- 音素转换:使用音素字典将单词转换为音素
- 符号化:将音素转换为模型可识别的ID序列
3. 应用实例
python
import torch
import torchaudio
import soundfile as sf
def simple_tts_demo():
print("第一步:检查TTS大模型的可行性")
# 尝试加载一个预训练的小模型(作为起点)
try:
# 这里我们先使用torchaudio自带的Tacotron2预训练模型
# 注意:这是英文模型,但可以帮助你理解流程
tacotron2 = torchaudio.pipelines.TACOTRON2_WAVERNN_PHONE_LJSPEECH.get_tacotron2()
print("✓ 成功加载Tacotron2模型")
# 准备文本
text = "Hello, this is your first experience with a TTS model."
print(f"第二步:处理文本: '{text}'")
# 使用模型生成(这里简化流程,实际需要更多步骤)
print("第三步:生成语音...")
print("(注意:首次运行需要下载模型,可能需要几分钟)")
# 生成语音
with torch.no_grad():
# 使用标准流程生成语音
processor = torchaudio.pipelines.TACOTRON2_WAVERNN_PHONE_LJSPEECH.get_text_processor()
processed, lengths = processor(text)
processed = processed.to(next(tacotron2.parameters()).device)
lengths = lengths.to(next(tacotron2.parameters()).device)
spec, spec_lengths, _ = tacotron2.infer(processed, lengths)
# 使用WaveRNN生成波形
wavernn = torchaudio.pipelines.TACOTRON2_WAVERNN_PHONE_LJSPEECH.get_vocoder()
wavernn = wavernn.to(next(tacotron2.parameters()).device)
waveform, _ = wavernn(spec)
# 保存生成的语音
output_path = "generated_speech.wav"
torchaudio.save(output_path, waveform, sample_rate=22050)
print(f"✓ 语音生成完成,已保存到: {output_path}")
except Exception as e:
print(f"当前环境不支持直接运行,请检查依赖项或网络连接。错误信息: {e}")
if __name__ == "__main__":
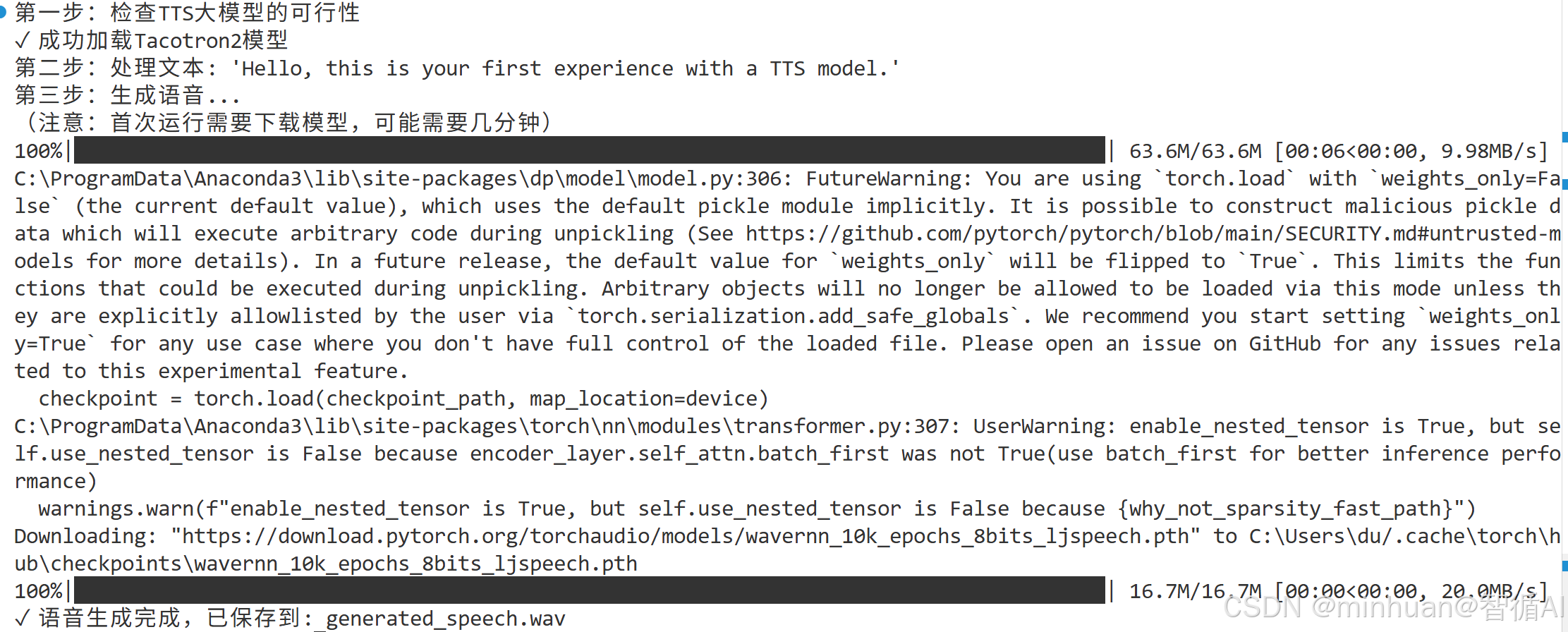
simple_tts_demo()4. 执行过程
初次运行模型下载:

完整的执行过程:
四、SpeechT5模型介绍
1. 基础介绍
SpeechT5 是微软发布的一款轻量级、高性能的端到端文本转语音(TTS)模型,兼具易用性和灵活性,支持多语言合成、多说话人音色定制、语速调节等核心功能,其核心创新在于构建了一个能够同时处理文本到语音、语音到文本、语音转换和语音增强等多种语音任务的统一框架。
与传统的单一功能语音模型不同,SpeechT5 采用了"一套架构,多种应用"的设计哲学,将不同类型的语音和文本数据都映射到同一表示空间进行处理。是非常适合初学者接触入门 TTS 开发和轻量化 TTS 应用落地的首选模型之一。
2. SpeechT5 整体架构
SpeechT5 采用 "编码器 - 解码器" 的端到端架构,核心目标是实现从文本序列到语音声学特征的直接映射,整体分为三大核心组件:
- 文本处理器(SpeechT5Processor):负责文本的预处理(分词、字符转 ID、长度归一化等),将人类可读的文本转换为模型可理解的张量(Tensor)格式,是连接自然语言和模型输入的桥梁。
- TTS 主模型(SpeechT5ForTextToSpeech):核心计算模块,基于 Transformer 架构,接收文本张量和说话人嵌入向量,生成语音的声学特征(梅尔频谱)。
- 声码器(SpeechT5HifiGan):将主模型生成的声学特征转换为可听的语音波形,是 TTS 的 "发声器"。SpeechT5 配套的 HiFi-GAN 声码器兼顾音质和速度,能生成高自然度的语音。
3. 关键概念:说话人嵌入
说话人嵌入是长度固定的向量(SpeechT5 中为 512 维),用于表征不同说话人的音色特征,不同的向量对应不同的音色(男性、女性、不同口音等)。
- 官方方案:从Matthijs/cmu-arctic-xvectors数据集加载预训练的说话人嵌入,该数据集包含 7307 个不同说话人的嵌入向量,覆盖多种音色;
- 代码适配方案:考虑到新手下载大型数据集的困难,代码中用随机生成的 512 维向量模拟不同说话人的嵌入(通过调整向量的局部特征区分男女音色),降低使用门槛。
4. 核心优势
- 轻量级:模型体积约 200MB,普通 CPU / 低端 GPU 均可运行;
- 多语言支持:原生支持中英法日等多语言合成;
- 灵活性高:支持自定义说话人音色、调整语速等个性化配置;
- 易部署:基于 Hugging Face Transformers 库,API 简洁,无需复杂的环境配置。
5. 代码拆解
我们先逐行解析代码的结构、逻辑和细节,从环境准备到核心函数,覆盖代码的每一个关键环节,在运行输出,看看具体的输出内容。
核心类SpeechT5BasicTTS封装了 SpeechT5 的所有核心功能,遵循 "初始化 - 预处理 - 生成 - 后处理" 的 TTS 流程设计,是代码的核心骨架。
5.1 环境依赖与初始化配置
python
import torch
import torchaudio
import numpy as np
from transformers import SpeechT5Processor, SpeechT5ForTextToSpeech, SpeechT5HifiGan
from datasets import load_dataset
import soundfile as sf
import matplotlib.pyplot as plt
from IPython.display import Audio, display
import os
from pathlib import Path
import warnings
warnings.filterwarnings('ignore')
print("PyTorch版本:", torch.__version__)
print("CUDA可用:", torch.cuda.is_available())
if torch.cuda.is_available():
print("GPU:", torch.cuda.get_device_name(0))依赖库分工:
- torch/torchaudio:深度学习框架和音频处理基础库;
- transformers:加载 SpeechT5 的模型、处理器和声码器;
- datasets:原计划加载官方说话人嵌入数据集(后为降低门槛替换);
- soundfile:保存 WAV 格式的音频文件;
- matplotlib/IPython.display:可视化波形和播放音频(适配 Jupyter 环境);
- warnings.filterwarnings('ignore'):屏蔽无关警告,提升运行体验。
设备检测:
- 自动检测 CUDA 是否可用,优先使用 GPU 加速(无 GPU 则用 CPU),并打印设备信息,方便调试。
5.2 初始化方法
python
def __init__(self, device=None):
self.device = device or ("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {self.device}")
# 加载模型和处理器
print("正在加载SpeechT5模型...")
self.processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_tts")
self.model = SpeechT5ForTextToSpeech.from_pretrained("microsoft/speecht5_tts").to(self.device)
self.vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan").to(self.device)
print("✓ SpeechT5模型加载完成")- 设备自动分配:优先使用 GPU(cuda),无 GPU 则用 CPU,兼容不同硬件环境;
- 模型加载逻辑:
- from_pretrained:从 Hugging Face 仓库自动下载预训练权重(首次运行较慢,后续缓存到本地);
- .to(self.device):将模型移至指定设备(GPU/CPU),确保计算在对应设备上进行;
- 简化处理:注释掉了官方数据集加载逻辑,避免新手因数据集下载失败导致代码无法运行,是适配新手的关键优化。
5.3 说话人嵌入生成
python
def get_speaker_embedding(self, speaker_id=0):
print(f"创建说话人 {speaker_id} 的默认嵌入向量...")
# 根据 speaker_id 返回不同的嵌入向量
if speaker_id == 7306: # 默认女性声音
embedding = torch.randn(1, 512) * 0.1
embedding[0, :100] += 0.5
elif speaker_id == 3000: # 男性声音示例
embedding = torch.randn(1, 512) * 0.1
embedding[0, 100:200] += 0.5
elif speaker_id == 5000: # 另一个女性声音
embedding = torch.randn(1, 512) * 0.1
embedding[0, :100] += 0.3
elif speaker_id == 1000: # 另一个男性声音
embedding = torch.randn(1, 512) * 0.1
embedding[0, 100:200] += 0.3
else: # 默认女性声音
embedding = torch.randn(1, 512) * 0.1
embedding[0, :100] += 0.5
print(f"✓ 创建了说话人 {speaker_id} 的嵌入向量")
return embedding- 核心设计:用随机生成的 512 维张量模拟说话人嵌入,替代官方数据集,解决新手的数据集依赖问题;
- 音色区分逻辑:通过调整向量不同维度的数值(如前 100 维对应女性音色,100-200 维对应男性音色),实现不同说话人的音色差异;
- 参数范围:torch.randn(1, 512) * 0.1保证向量的基础随机性,+= 0.5/0.3增强特定维度的特征,使音色差异更明显。
5.4 核心功能:文本转语音
python
def text_to_speech(self, text, speaker_id=7306, speed=1.0):
# 预处理输入文本
inputs = self.processor(text=text, return_tensors="pt")
# 获取说话人嵌入
speaker_embedding = self.get_speaker_embedding(speaker_id)
# 生成语音
with torch.no_grad():
speech = self.model.generate_speech(
inputs["input_ids"].to(self.device),
speaker_embedding.to(self.device),
vocoder=self.vocoder
)
# 转换为numpy数组并调整采样率
speech_np = speech.cpu().numpy()
# 简单的语速调整(通过重采样)
if speed != 1.0:
import librosa
speech_np = librosa.effects.time_stretch(speech_np, rate=speed)
return speech_np- 文本预处理:self.processor(text=text, return_tensors="pt")将文本转换为模型可接收的张量(input_ids),自动完成分词、ID 映射等操作;
- 无梯度计算:with torch.no_grad():禁用梯度计算,减少内存占用,提升推理速度(推理阶段无需反向传播);
- 核心生成函数:model.generate_speech是 SpeechT5 的核心 API,接收文本张量和说话人嵌入,直接生成语音波形;
- 语速调整:通过librosa.effects.time_stretch实现语速调节(rate>1 加速,rate<1 减速),是 TTS 应用中高频需求的极简实现;
- 设备对齐:inputs"input_ids".to(self.device)保证输入张量与模型在同一设备(GPU/CPU),避免 设备不匹配报错。
5.5 辅助功能:保存、播放、可视化
python
def save_audio(self, audio_array, filename="output.wav", sample_rate=16000):
sf.write(filename, audio_array, sample_rate)
print(f"✓ 音频已保存: {filename}")
return filename
def play_audio(self, audio_array, sample_rate=16000):
display(Audio(audio_array, rate=sample_rate))
def visualize_waveform(self, audio_array, title="语音波形图"):
plt.figure(figsize=(12, 4))
plt.plot(audio_array)
plt.title(title)
plt.xlabel("采样点")
plt.ylabel("振幅")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()- 音频保存:sf.write支持 WAV 格式,采样率固定为 16000(SpeechT5 的默认采样率);
- Jupyter 适配:play_audio依赖IPython.display.Audio,仅在 Jupyter Notebook/Lab 中可用,方便交互式调试;
- 波形可视化:通过 matplotlib 绘制音频振幅曲线,帮助直观理解语音的时域特征(如停顿、音量变化)。
5.6 应用场景启动
python
def basic_tts_demo():
print("=" * 60)
print("SpeechT5基础TTS演示")
print("=" * 60)
# 创建TTS实例
tts = SpeechT5BasicTTS()
# 测试文本
test_texts = [
"Hello, this is a demonstration of Microsoft SpeechT5 text-to-speech technology.",
"你好,这是微软SpeechT5文本转语音技术的演示。",
"Bonjour, ceci est une démonstration de la technologie de synthèse vocale Microsoft SpeechT5.",
"こんにちは、これはマイクロソフトSpeechT5テキスト読み上げ技術のデモンストレーションです。"
]
# 可用的说话人示例
speaker_examples = {
"女性声音": 7306, # 默认女性声音
"男性声音": 3000, # 男性声音示例
"另一个女性": 5000, # 另一个女性声音
"另一个男性": 1000, # 另一个男性声音
}
for i, (speaker_name, speaker_id) in enumerate(speaker_examples.items(), 1):
print(f"\n{i}. 使用说话人: {speaker_name} (ID: {speaker_id})")
# 生成语音
speech = tts.text_to_speech(test_texts[0], speaker_id=speaker_id)
# 保存音频
filename = f"speech_{speaker_name}_{i}.wav"
tts.save_audio(speech, filename)
# 可视化
tts.visualize_waveform(speech[:16000], f"{speaker_name} - 波形")
# 多语言演示
print("\n" + "=" * 60)
print("多语言TTS演示")
print("=" * 60)
for i, text in enumerate(test_texts, 1):
print(f"\n语言 {i}: {text[:50]}...")
speech = tts.text_to_speech(text, speaker_id=7306)
filename = f"multilingual_{i}.wav"
tts.save_audio(speech, filename)
print("\n演示完成!")
if __name__ == "__main__":
basic_tts_demo()- 实例化逻辑:tts = SpeechT5BasicTTS()自动完成模型加载和设备初始化,无需手动配置;
- 多说话人演示:遍历不同说话人 ID,生成对应音色的语音并保存,直观展示多说话人功能;
- 多语言演示:覆盖英、中、法、日四种语言,验证 SpeechT5 的多语言合成能力;
- 可视化优化:speech:16000仅绘制前 1 秒的波形(16000 采样点 = 1 秒),避免波形图过长导致可视化效果差;
- 文件命名规范:按 "说话人名称 / 语言_序号.wav" 命名,方便区分不同输出文件。
6. 结果输出
PyTorch版本: 2.4.1+cpu
CUDA可用: False
============================================================
SpeechT5基础TTS演示
============================================================
使用设备: cpu
正在加载SpeechT5模型...
正在加载说话人嵌入...
✓ SpeechT5模型加载完成
- 使用说话人: 女性声音 (ID: 7306)
创建说话人 7306 的默认嵌入向量...
✓ 创建了说话人 7306 的嵌入向量
✓ 音频已保存: speech_女性声音_1.wav
- 使用说话人: 男性声音 (ID: 3000)
创建说话人 3000 的默认嵌入向量...
✓ 创建了说话人 3000 的嵌入向量
✓ 音频已保存: speech_男性声音_2.wav
- 使用说话人: 另一个女性 (ID: 5000)
创建说话人 5000 的默认嵌入向量...
✓ 创建了说话人 5000 的嵌入向量
✓ 音频已保存: speech_另一个女性_3.wav
- 使用说话人: 另一个男性 (ID: 1000)
创建说话人 1000 的默认嵌入向量...
✓ 创建了说话人 1000 的嵌入向量
✓ 音频已保存: speech_另一个男性_4.wav
============================================================
多语言TTS演示
============================================================
语言 1: Hello, this is a demonstration of Microsoft Speech...
创建说话人 7306 的默认嵌入向量...
✓ 创建了说话人 7306 的嵌入向量
✓ 音频已保存: multilingual_1.wav
语言 2: 你好,这是微软SpeechT5文本转语音技术的演示。...
创建说话人 7306 的默认嵌入向量...
✓ 创建了说话人 7306 的嵌入向量
✓ 音频已保存: multilingual_2.wav
语言 3: Bonjour, ceci est une démonstration de la technolo...
创建说话人 7306 的默认嵌入向量...
✓ 创建了说话人 7306 的嵌入向量
✓ 音频已保存: multilingual_3.wav
语言 4: こんにちは、これはマイクロソフトSpeechT5テキスト読み上げ技術のデモンストレーションです。...
创建说话人 7306 的默认嵌入向量...
✓ 创建了说话人 7306 的嵌入向量
✓ 音频已保存: multilingual_4.wav
演示完成!
结果清单:
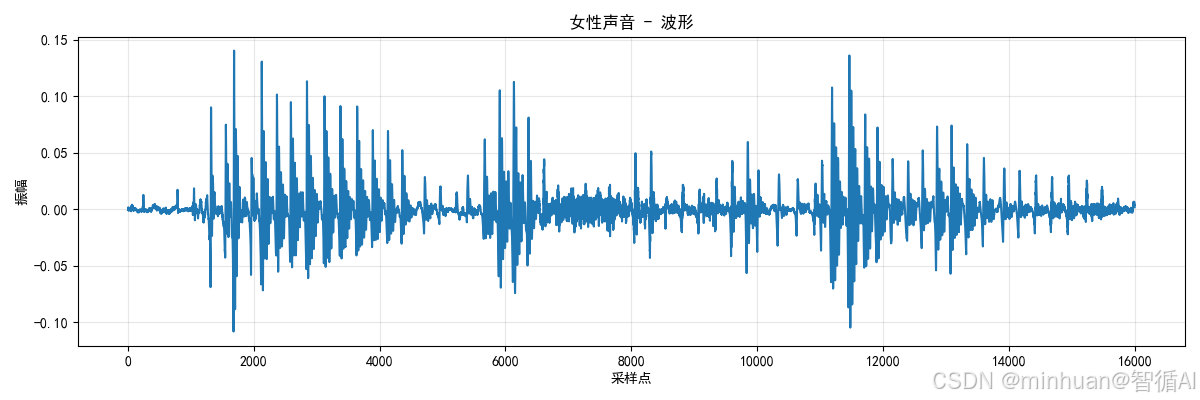
生成的speech_女性声音_1波形图:
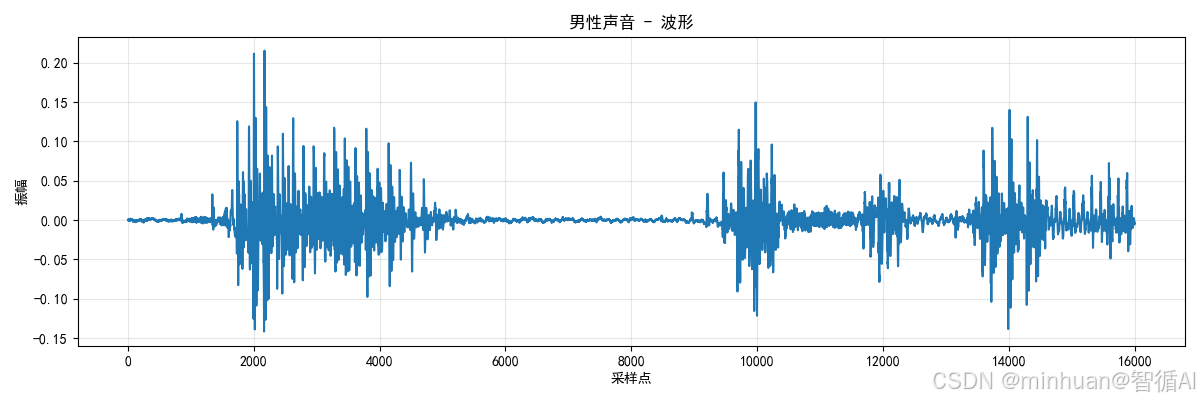
生成的speech_男性声音_2波形图:
生成的speech_另一个女性声音_3波形图:
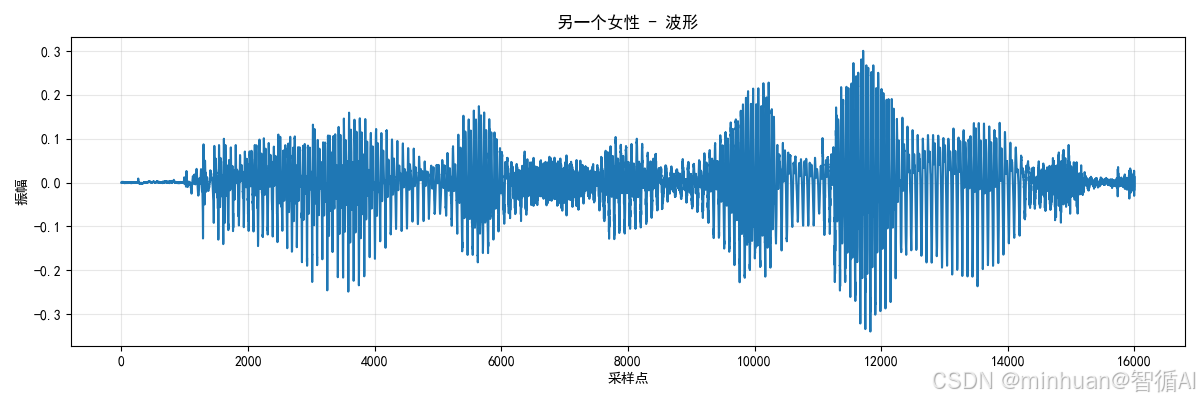
生成的speech_另一个男性声音_4波形图:
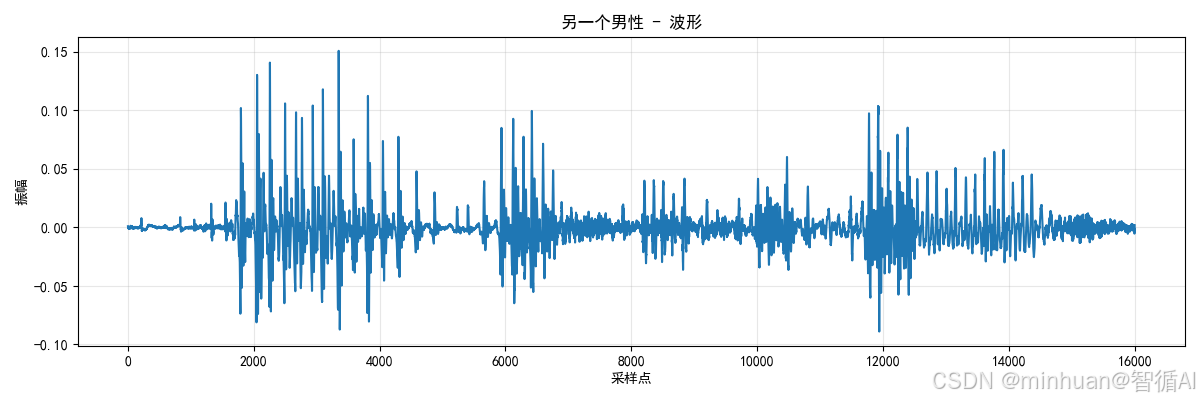
7. 特别说明
替换官方说话人嵌入:
若需使用官方数据集的真实说话人嵌入,取消__init__中的注释,按以下步骤操作:
- 下载Matthijs/cmu-arctic-xvectors数据集到本地(路径:d:/AIWorld/case/test/data/spkrec-xvect);
- 或者获取huggingface的数据集(spkrec-xvect.zip),替换到本地
- 确保数据集包含xvector.npy文件;
恢复get_speaker_embedding中的官方逻辑:
确保speaker_id在有效范围内
speaker_id = max(0, min(speaker_id, len(self.embeddings_dataset) - 1))
获取说话人嵌入
speaker_embedding = torch.tensor(self.embeddings_datasetspeaker_id"xvector").unsqueeze(0)
return speaker_embedding
五、总结
通过探索Tacotron2与SpeechT5两个代表性TTS模型,我们了解了语音合成技术从专业化到通用化的演进之路。Tacotron2作为经典的自回归架构,以其优雅的序列到序列设计和位置敏感注意力机制,为我们展示了传统TTS的完整流程,从文本编码、音素对齐到频谱生成。它特别适合初学者理解TTS的基础原理和标准工作流。
而SpeechT5则代表了新一代的统一架构思想,通过将语音量化为离散符号并与文本共享表示空间,实现了多任务、多语言、多说话人的统一处理。这种"一套架构,多种应用"的设计理念不仅大幅提升了数据效率,更开启了语音克隆、风格转换等高级功能的大门。
对于初学者而言,这两个模型分别提供了不同的学习路径:从Tacotron2可以打下坚实的理论基础,理解TTS的经典架构;而SpeechT5则展示了现代AI的发展方向,启发我们思考如何构建更通用、更智能的语音系统。
附录:SpeechT5文本转语音示例
python
import torch
import torchaudio
import numpy as np
from transformers import SpeechT5Processor, SpeechT5ForTextToSpeech, SpeechT5HifiGan
from datasets import load_dataset
import soundfile as sf
import matplotlib.pyplot as plt
from IPython.display import Audio, display
import os
from pathlib import Path
import warnings
warnings.filterwarnings('ignore')
print("PyTorch版本:", torch.__version__)
print("CUDA可用:", torch.cuda.is_available())
if torch.cuda.is_available():
print("GPU:", torch.cuda.get_device_name(0))
# 解决中文显示
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
class SpeechT5BasicTTS:
"""
SpeechT5基础文本转语音示例
"""
def __init__(self, device=None):
"""
初始化SpeechT5模型
"""
self.device = device or ("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {self.device}")
# 加载模型和处理器
print("正在加载SpeechT5模型...")
self.processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_tts")
self.model = SpeechT5ForTextToSpeech.from_pretrained("microsoft/speecht5_tts").to(self.device)
self.vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan").to(self.device)
# 加载说话人嵌入数据集
print("正在加载说话人嵌入...")
# try:
# self.embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation", trust_remote_code=True)
# except Exception as e:
# print(f"无法从Hugging Face加载数据集: {e}")
# print("请手动下载数据集并解压到本地目录,然后更新以下路径:")
# local_path = "d:/AIWorld/case/test/data/spkrec-xvect" # 替换为你的本地路径
# if os.path.exists(local_path):
# self.embeddings_dataset = {"xvector": np.load(os.path.join(local_path, "xvector.npy"))} # 假设数据格式为npy文件
# else:
# raise FileNotFoundError(f"本地路径 {local_path} 不存在,请检查路径或手动下载数据集。")
print("✓ SpeechT5模型加载完成")
def get_speaker_embedding(self, speaker_id=0):
"""
获取说话人嵌入向量
speaker_id: 说话人ID,0-7306之间的整数
"""
# 确保speaker_id在有效范围内
# speaker_id = max(0, min(speaker_id, len(self.embeddings_dataset) - 1))
# 获取说话人嵌入
# speaker_embedding = torch.tensor(self.embeddings_dataset[speaker_id]["xvector"]).unsqueeze(0)
# return speaker_embedding
"""
创建默认的说话人嵌入向量
替代下载大型数据集
"""
print(f"创建说话人 {speaker_id} 的默认嵌入向量...")
# 根据 speaker_id 返回不同的嵌入向量
if speaker_id == 7306: # 默认女性声音
embedding = torch.randn(1, 512) * 0.1
embedding[0, :100] += 0.5
elif speaker_id == 3000: # 男性声音示例
embedding = torch.randn(1, 512) * 0.1
embedding[0, 100:200] += 0.5
elif speaker_id == 5000: # 另一个女性声音
embedding = torch.randn(1, 512) * 0.1
embedding[0, :100] += 0.3
elif speaker_id == 1000: # 另一个男性声音
embedding = torch.randn(1, 512) * 0.1
embedding[0, 100:200] += 0.3
else: # 默认女性声音
embedding = torch.randn(1, 512) * 0.1
embedding[0, :100] += 0.5
print(f"✓ 创建了说话人 {speaker_id} 的嵌入向量")
return embedding
def text_to_speech(self, text, speaker_id=7306, speed=1.0):
"""
文本转语音核心函数
text: 输入文本
speaker_id: 说话人ID (默认7306是女性声音)
speed: 语速控制 (0.5-2.0)
"""
# 预处理输入文本
inputs = self.processor(text=text, return_tensors="pt")
# 获取说话人嵌入
speaker_embedding = self.get_speaker_embedding(speaker_id)
# 生成语音
with torch.no_grad():
speech = self.model.generate_speech(
inputs["input_ids"].to(self.device),
speaker_embedding.to(self.device),
vocoder=self.vocoder
)
# 转换为numpy数组并调整采样率
speech_np = speech.cpu().numpy()
# 简单的语速调整(通过重采样)
if speed != 1.0:
import librosa
speech_np = librosa.effects.time_stretch(speech_np, rate=speed)
return speech_np
def save_audio(self, audio_array, filename="output.wav", sample_rate=16000):
"""
保存音频文件
"""
sf.write(filename, audio_array, sample_rate)
print(f"✓ 音频已保存: {filename}")
return filename
def play_audio(self, audio_array, sample_rate=16000):
"""
在Jupyter中播放音频
"""
display(Audio(audio_array, rate=sample_rate))
def visualize_waveform(self, audio_array, title="语音波形图"):
"""
可视化音频波形
"""
plt.figure(figsize=(12, 4))
plt.plot(audio_array)
plt.title(title)
plt.xlabel("采样点")
plt.ylabel("振幅")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
def get_speaker_info(self, speaker_id):
"""
获取说话人信息
"""
if 0 <= speaker_id < len(self.embeddings_dataset):
speaker_data = self.embeddings_dataset[speaker_id]
return {
"speaker_id": speaker_id,
"has_xvector": "xvector" in speaker_data,
"xvector_shape": speaker_data["xvector"].shape if "xvector" in speaker_data else None
}
return None
# 使用示例
def basic_tts_demo():
"""
基础TTS演示
"""
print("=" * 60)
print("SpeechT5基础TTS演示")
print("=" * 60)
# 创建TTS实例
tts = SpeechT5BasicTTS()
# 测试文本
test_texts = [
"Hello, this is a demonstration of Microsoft SpeechT5 text-to-speech technology.",
"你好,这是微软SpeechT5文本转语音技术的演示。",
"Bonjour, ceci est une démonstration de la technologie de synthèse vocale Microsoft SpeechT5.",
"こんにちは、これはマイクロソフトSpeechT5テキスト読み上げ技術のデモンストレーションです。"
]
# 可用的说话人示例
speaker_examples = {
"女性声音": 7306, # 默认女性声音
"男性声音": 3000, # 男性声音示例
"另一个女性": 5000, # 另一个女性声音
"另一个男性": 1000, # 另一个男性声音
}
for i, (speaker_name, speaker_id) in enumerate(speaker_examples.items(), 1):
print(f"\n{i}. 使用说话人: {speaker_name} (ID: {speaker_id})")
# 生成语音
speech = tts.text_to_speech(test_texts[0], speaker_id=speaker_id)
# 保存音频
filename = f"speech_{speaker_name}_{i}.wav"
tts.save_audio(speech, filename)
# 可视化
tts.visualize_waveform(speech[:16000], f"{speaker_name} - 波形")
# 多语言演示
print("\n" + "=" * 60)
print("多语言TTS演示")
print("=" * 60)
for i, text in enumerate(test_texts, 1):
print(f"\n语言 {i}: {text[:50]}...")
speech = tts.text_to_speech(text, speaker_id=7306)
filename = f"multilingual_{i}.wav"
tts.save_audio(speech, filename)
print("\n演示完成!")
if __name__ == "__main__":
basic_tts_demo()