深入理解 JavaScript 的内存机制与执行流程
在前端开发中,我们每天都在写函数、声明变量、使用闭包。但你是否曾思考过:JavaScript 引擎究竟是如何运行你的代码的?
为什么一个函数执行完毕后,它内部的变量还能被外部访问?这些"自由变量"到底存在哪里?
要回答这些问题,我们必须深入 JS 的执行机制 与内存模型。
一、JavaScript 是一门怎样的语言?
JavaScript 是一门 动态弱类型语言:
- 动态:变量的数据类型在运行时确定,无需提前声明。
- 弱类型:允许隐式类型转换,不同类型之间可以互相赋值。
js
var bar;
console.log(typeof bar); // "undefined"
bar = 12;
console.log(typeof bar); // "number"
bar = "极客时间";
console.log(typeof bar); // "string"
bar = true;
console.log(typeof bar); // "boolean"
bar = null;
console.log(typeof bar); // "object" ← 这是 JS 的一个历史 bug!
bar = { name: "极客时间" };
console.log(typeof bar); // "object"这种灵活性带来了开发效率,但也要求我们更清楚 JS 在背后如何管理数据与内存。
相对于其他的静态类型语言,为什么JS不需要自己手动的free()?
这正是JS的内存空间划分决定的
二、JS 的内存模型:栈 vs 堆
JavaScript 的内存主要分为三类:
1. 代码空间
- 存放可执行代码。将代码从硬盘加载到内存。体积不大,但至关重要。
1. 栈内存(Stack)
- 存放 原始数据类型(Primitive Types) :
number、string、boolean、undefined、null、symbol、bigint - 特点:体积小、连续、分配/回收快
- 用于维护 调用栈(Call Stack) 和 执行上下文(Execution Context)
js
function foo() {
var a = 1; // 存于栈中
var b = a; // 值拷贝(b 是 a 的副本)
a = 2;
console.log(a); // 2
console.log(b); // 1
}
foo();这里 a 和 b 是两个独立的栈变量,修改 a 不会影响 b。
2. 堆内存(Heap)
- 存放 引用类型(Object、Array、Function 等)
- 特点:空间大、不连续、分配/回收较慢
- 变量在栈中保存的是 指向堆中对象的引用(指针)
js
function foo() {
var a = { name: "极客时间" }; // 对象存于堆,a 是引用
var b = a; // b 也指向同一个堆对象
a.name = "极客邦";
console.log(a); // { name: "极客邦" }
console.log(b); // { name: "极客邦" } ← 被同步修改!
}
foo();这说明:对象赋值是"引用式赋值" ,而非值拷贝。
为什么同样是赋值操作却要遭受不一样的待遇?
原因如下:
- 在栈内存中的数据发生复制行为时,系统会自动为新的变量分配一个新值 。
var b = a执行之后,a与b虽然值都等于2,但是他们其实已经是相互独立互不影响的值了 - 引用类型的复制同样也会为新的变量自动分配一个新的值保存在栈内存 中,但不同的是,这个新的值,仅仅只是引用类型的一个地址指针 。当地址指针相同时,尽管他们相互独立,但是在堆内存中访问到的具体对象实际上是同一个。
给你一行代码快速理解栈内存和堆内存
js
var b = { m: 20 };变量b存在于栈内存中 ,而真正的对象{ m: 20 }实际上存在于堆内存 之中,栈内存中的b只保存着该对象的地址。
而对于我们上面的那段代码给你一张图你马上就能理解了栈和堆之间存储变量的差异与联系
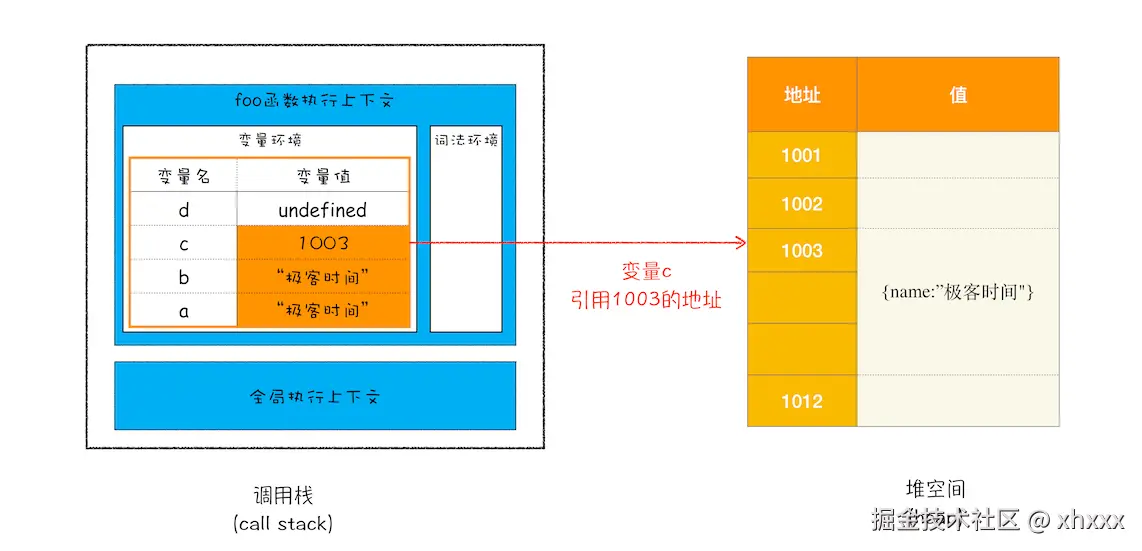
三、执行上下文与调用栈
JS 引擎通过 调用栈(Call Stack) 来管理函数的执行顺序。
JS 引擎通过 调用栈(Call Stack) 来管理函数的执行顺序。
-
每次函数调用,都会创建一个 执行上下文(Execution Context)
-
执行上下文包含:
- 变量环境(Variable Environment) :存放
var、函数声明等 - 词法环境(Lexical Environment) :存放
let/const等声明的变量和块级作用域 - outer:指向外层作用域的指针
- this:当前上下文的 this 绑定
- 变量环境(Variable Environment) :存放
执行完毕后,上下文从栈顶弹出,其占用的栈内存通过 栈顶指针的偏移 快速释放------不需要逐个清理变量,只需将指针回退到上一个上下文的位置即可。
为什么执行上下文选择使用调用栈这种栈结构来实现?
- 结构简单、内存连续,适合频繁的压栈(push)和出栈(pop)操作;
- 大小固定、切换高效:上下文切换本质上只是移动栈顶指针,开销极小;
- 如果把复杂对象也放在栈中,会导致栈空间膨胀、内存碎片化,严重影响上下文切换效率。
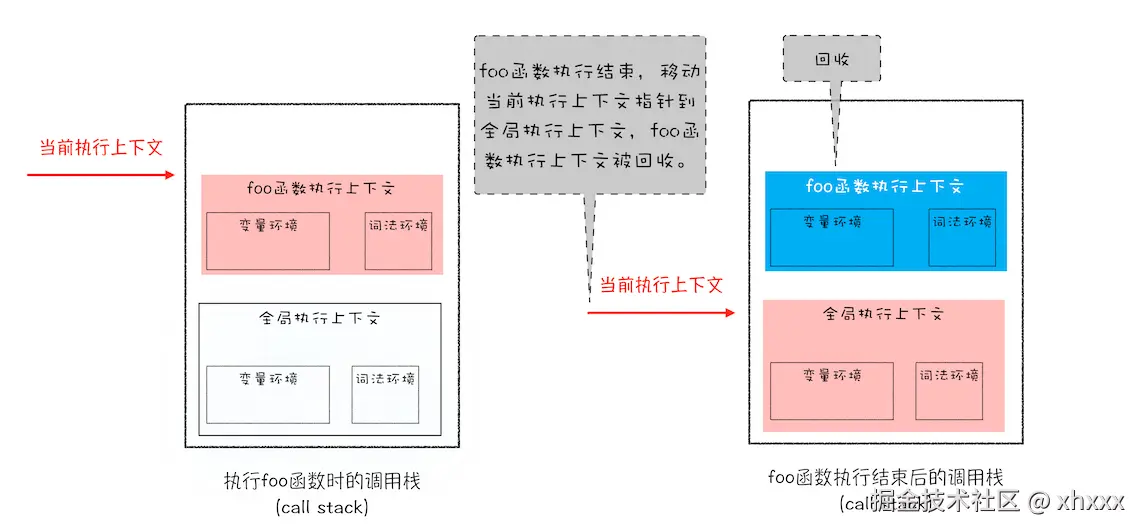
四、怎么确定切换上下文时的指针偏移量
一、什么是"指针偏移"?
在 JS 引擎中,调用栈(Call Stack)是一个连续的内存区域 ,每个函数调用都会在栈顶"压入"一个执行上下文帧(frame) 。当函数执行完毕,这个帧就被"弹出",栈顶指针(通常叫 stack pointer 或 SP)就向低地址方向移动一段固定距离------这就是所谓的"指针偏移"。
✅ 指针偏移的本质:不是逐个释放变量,而是整体"回退"到上一个函数的栈帧起始位置。
二、偏移量是如何确定的?
在函数编译阶段就已静态确定
JavaScript 虽然是解释型语言,但现代引擎(如 V8)会先将代码 解析 + 编译为字节码或机器码 ,在这个过程中完成栈帧大小的计算。
具体步骤如下:
1. 词法分析与作用域分析
引擎扫描函数体,识别所有:
var/let/const声明的变量- 函数参数
- 内部函数声明
this、arguments等特殊对象
例如:
js
function foo(a, b) {
var x = 10;
let y = 20;
const z = { name: 'test' };
}2. 计算栈帧所需空间
引擎会为该函数的执行上下文分配一个固定大小的栈帧(stack frame) ,包括:
- 参数区(parameters)
- 局部变量区(local variables)
- 返回地址(return address)
- 词法环境/变量环境的元数据指针(可能指向堆中的结构)
⚠️ 注意:只有原始类型会直接存放在栈帧中 ;像
{ name: 'test' }这样的对象仍存于堆,栈中只存其引用(一个指针,通常 8 字节)。
因此,整个栈帧的大小 = 所有局部变量 + 参数 + 元信息 的总字节数。
这个大小在函数首次编译时就确定了 ,是静态的、固定的。
3. 生成"出栈"指令
当函数执行结束,引擎执行类似这样的底层操作(伪代码):
arduino
// 假设当前栈顶指针为 SP,当前执行上下文的栈帧大小为foo_size;
SP=SP-foo_size;
//那么此时栈顶指针就回退到了上一个执行上下文中所以偏移量实际上就等于每一个函数上下文的栈帧大小
🔍 这就是为什么栈内存回收极快:不需要遍历、不需要标记,只需一次指针加减!
4、对比:为什么堆不能这样干?
因为堆内存具有以下特点:
- 分配大小动态 (比如
new Array(n)的n是运行时才知道) - 生命周期不确定(可能被闭包、全局变量等长期持有)
- 内存不连续,无法通过简单偏移回收
随着JS的更新,关于栈帧的计算已经被简化,它与变量的数量无关,它几乎是一个固定大小的值。他将变量,无论什么类型,全部保存在堆内存中,此时栈帧仅包含返回地址、函数指针、Context 指针等少量固定控制信息。但无论是哪种方式的计算,栈帧的大小始终在编译阶段就确定,这也是为什么能够精准又快速的切换执行上下文的精髓所在
五、作用域与闭包:自由变量的归宿
什么是闭包?
闭包是指 内部函数访问其外部函数的变量(自由变量) ,即使外部函数已执行完毕。
js
function foo() {
var myName = "极客时间"
let test1 = 1
const test2 = 2
var innerBar = {
setName:function(newName){
myName = newName
},
getName:function(){
console.log(test1)
return myName
}
}
return innerBar
}
var bar = foo()
bar.setName("极客邦")
bar.getName()
console.log(bar.getName())闭包是如何实现的?
- 编译阶段的快速词法扫描,v8引擎在编译阶段会判断出内部函数是否被返回且引用了外部作用域的变量,如果存在,那么就会提前做好一个准备,标记被引用的变量
- 函数入栈时,真正的创建闭包,那么它被保存到哪里呢?实际上闭包被存在堆内存之中,而栈内存中只存它的引用地址

✅ 闭包的本质:通过堆内存延长外部变量的生命周期
六、对比 C 语言:JS 为何不用手动管理内存?
C/C++ 需要开发者手动调用 malloc / free 来申请和释放堆内存,而 JavaScript 由引擎自动管理内存,主要依赖两大机制:
1. 栈内存:自动释放
- 函数执行结束 → 执行上下文出栈 → 栈顶指针回退 → 所有局部原始类型变量立即"消失"。
2. 堆内存:垃圾回收(Garbage Collection, GC)
JS 引擎采用 标记-清除(Mark-and-Sweep) 为主的垃圾回收策略:
- 标记阶段:从根对象(如全局对象、当前调用栈中的变量)出发,遍历所有可达对象,标记为"存活"。
- 清除阶段:回收未被标记的对象所占的堆内存。
早期也曾使用 引用计数 (记录对象被引用的次数),但因无法处理循环引用问题(如 objA.ref = objB; objB.ref = objA)而被弃用。
💡 开发者无需关心内存分配与释放,但也需注意:
- 避免内存泄漏:如意外保留对大对象或 DOM 节点的引用;
- 理解闭包可能导致的内存占用:只要闭包存在,其捕获的变量就不会被 GC 回收。
七、总结
- JavaScript 是动态弱类型语言,类型和内存管理由引擎自动处理。
- 内存分为栈(存放原始类型和执行上下文)和堆(存放对象等引用类型)。
- 函数调用时创建执行上下文,其栈帧大小在编译阶段静态确定,通过指针偏移高效切换。
- 作用域链通过词法环境的 outer 引用实现,闭包本质是将外部变量保存在堆中的 Context 对象里。
- 堆内存由垃圾回收器自动管理(主要采用标记-清除算法),无需手动释放。 理解这些机制,不仅能写出更高效的代码,还能在调试内存问题、性能瓶颈时游刃有余。