写文章时总会遇到需要插图解释的地方,之前分享过即梦可以为文章全文配图了。
但终归还需要手动复制、粘贴,体验没有那么完美。
常用的 AI 我当时也尝试了,只有 Gemini 给出了图文混排的结果。
如今,国产模型给出了选择------GLM-4.6V,一键搞定图文混排内容创作。
GLM-4.6V
GLM 的 V 系列是智谱模型中的多模态大模型,效果一直不错。
本次发布包括两款模型:
- GLM-4.6V(106B-A12B):面向云端与高性能集群场景的基础版;
- GLM-4.6V-Flash(9B):面向本地部署与低延迟应用的轻量版。
其中,Flash 版本依然免费提供给大家使用。
这次发布的主要内容如下:
- 训练时上下文窗口提升到
128k tokens,在视觉理解精度上达到同参数规模SOTA。 - 首次在模型架构中将
Function Call(工具调用)能力原生融入视觉模型,打通从**「视觉感知」到「可执行行动(Action)」**的链路。
我们直接到 z.ai 上体验下"工具调用能力原生融入视觉模型"是什么感受。
原生多模态工具调用实测
场景比较简单,我让 GLM-4.6V 帮我写一篇 Gemini 3 Pro 的科普文章,重要的是输出要图文混排。
提示词
帮我写一篇介绍 Gemini 3 pro 的科普文章,需要图文并茂
截图中可以看到思考过程中就可以调用图片搜索工具(Function),查找适合的图片以供使用。
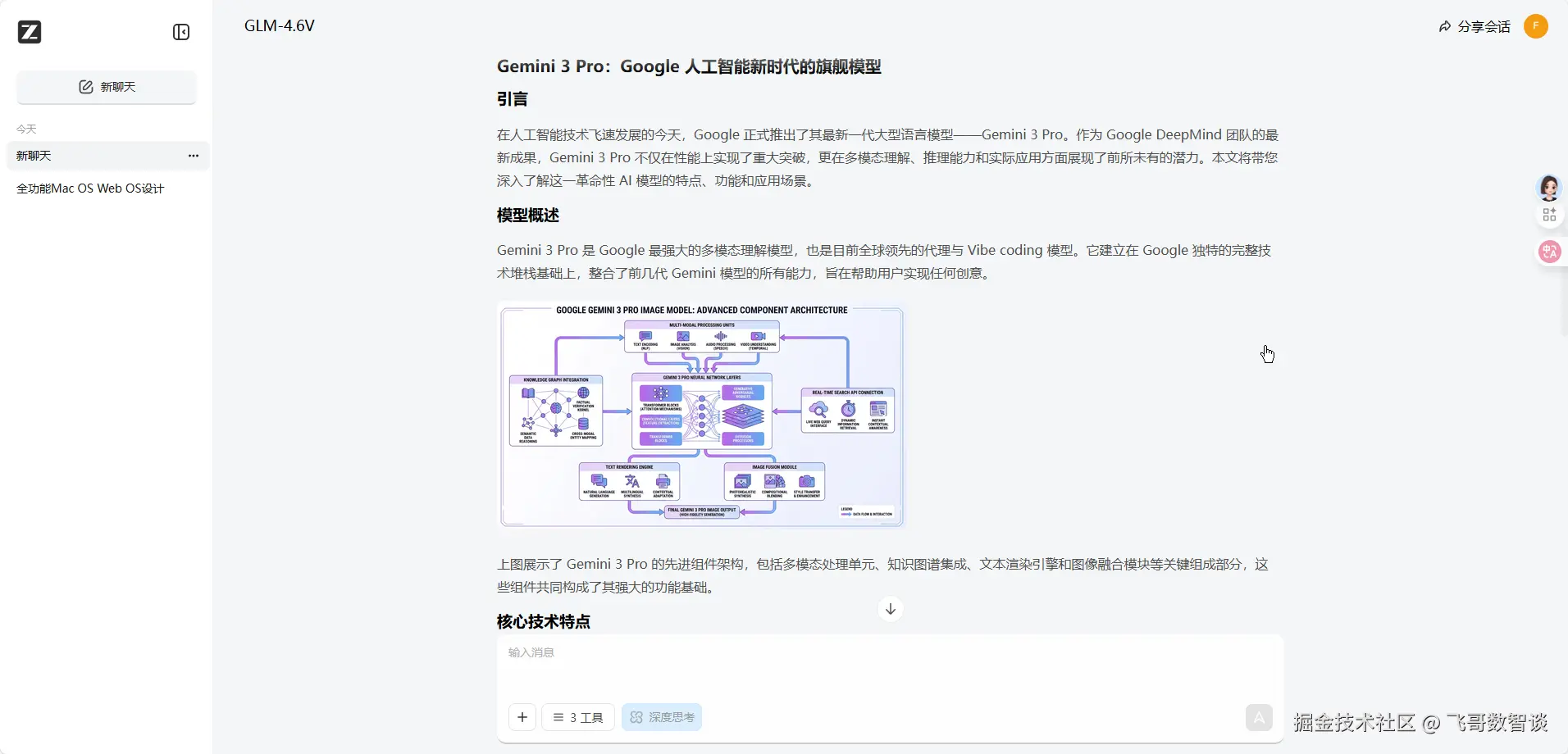
后续也确实在文章中使用了上面的图片,并针对图片进行了文字解释。
整个过程完全自动化,一轮对话就能得到一篇图文并茂的高质量文章了。
结语
这意味着,以后的内容创作,终于不用在不同模型间来回切换了。
但我认为意义远不止这一点。
多模态大模型中的"多"一直指的是可以支持的种类多,而不是一轮对话中的语料模态"多"。
现在,使用 GLM-4.6V,我们可以一次性传递文字、图片两种模态,后续语音、视频估计也会陆续出现。
这种模型能力的提升,将会更加精准的描述真实世界,相应的,模型后续的服务水平也一定会再次提升。