目录

🎬 攻城狮7号 :个人主页
🔥 个人专栏 :《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 美团开源6B参数的图像生成模型LongCat-Image
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
**当前的AI图像生成领域,正上演着一出"冰与火之歌"。**一边是像Midjourney这样性能强大、效果惊艳的闭源模型,它们是艺术创作的"火",但高昂的费用和无法私有化部署的壁垒,让许多企业望而却步。另一边是各类开源模型,它们是技术普惠的"冰",但普遍存在模型笨重、能力偏科、尤其是不懂中文等问题,难以直接投入到真实的商业生产流程中。
**商家们真正的痛点是什么?**并非生成一张宏大酷炫的科幻场景,而往往是更具体、更琐碎的需求:"把这张产品图的背景换成沙滩"、"给这张海报加上'五一促销'四个字"。
**正是在这种背景下,美团的LongCat-Image横空出世。**它没有去卷参数规模,而是像一个经验丰富的产品经理,精准地瞄准了上述两个核心痛点。


一、"小"的智慧:6B参数如何逆袭80B?
在动辄百亿、千亿参数的大模型时代,6B的LongCat-Image像一个"小个子"。但数据不会说谎,在多个权威基准测试中,这个"小个子"却展现出了与比它大10倍以上的重量级选手分庭抗礼的实力。
例如,在衡量综合生成能力的GenEval测试中,6B的LongCat-Image得分与20B的Qwen-Image持平,甚至优于80B的HunyuanImage-3.0。
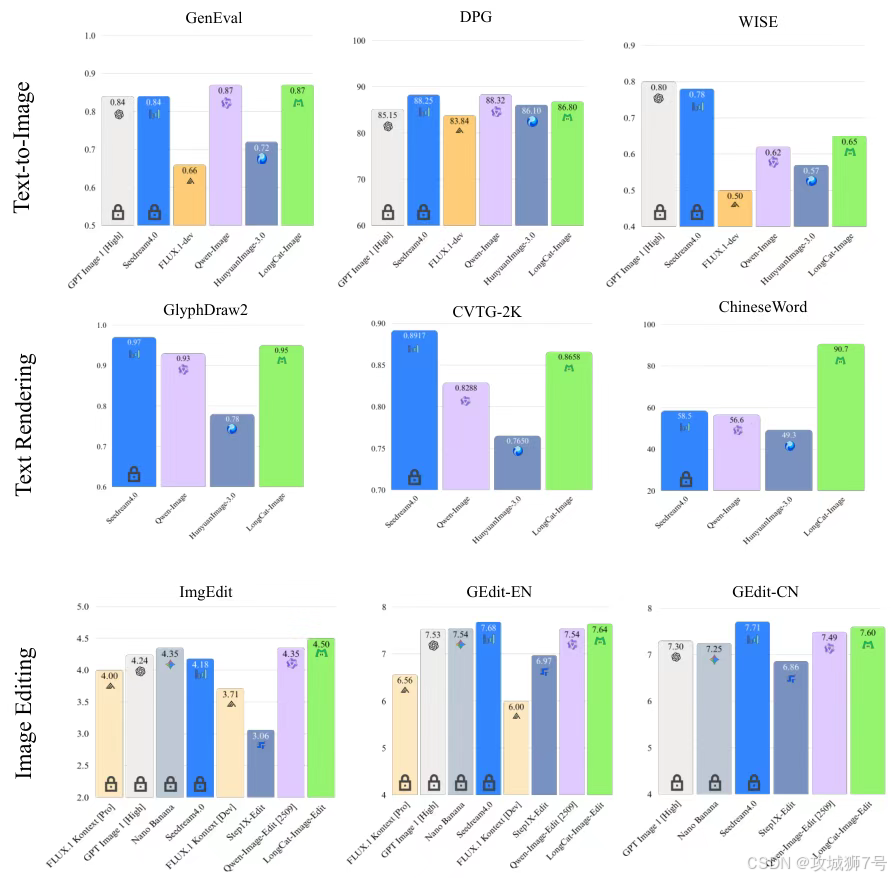
这背后并非魔法,而是**"参数效率"** 的胜利。LongCat-Image的团队没有选择用海量参数去"暴力"解决问题,而是通过更精巧的架构设计、更高质量的数据工程和更具针对性的训练策略,让每一份参数都发挥出最大的效能。这种"小而美"的路线,带来的最直接好处就是普惠化------它可以在消费级的显卡上顺畅运行,极大地降低了开发者和中小企业使用高性能AI图像技术的硬件门槛和运营成本。
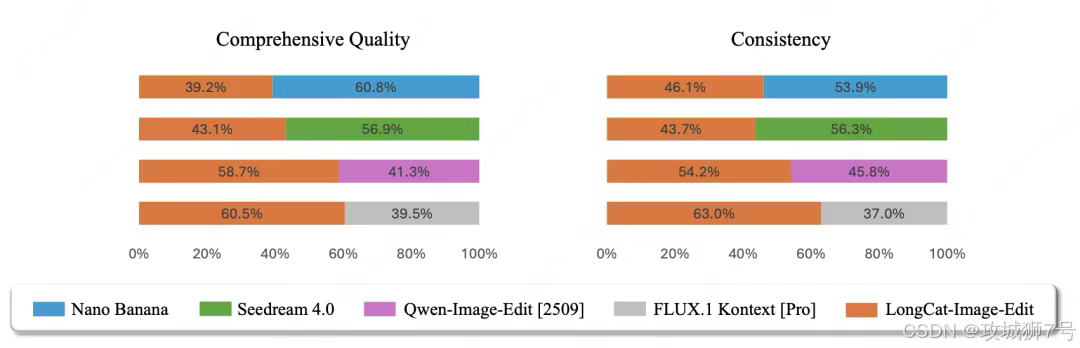
二、核心绝活(一):听得懂"人话"的"P图大师"
LongCat-Image最令人称道的,是其"指哪改哪"的精准图像编辑能力。
传统AI编辑的一大顽疾在于,你只想给猫换个颜色,它却可能把背景里的沙发也顺便"优化"了,导致结果不可控。而LongCat-Image在设计之初,就将文生图与图像编辑视为同源能力,并采用多任务联合学习机制,确保模型深刻理解"编辑"的本质------在保持绝大部分内容不变的前提下,精准执行局部修改指令。
在多个编辑能力基准测试(如GEdit-Bench)中,LongCat-Image均达到开源SOTA(业界最佳)水平。从用户的实际体验来看,它可以稳定地执行连续、复杂的多轮修改指令:
(1)首先输入一张"狐狸尼克"的图片。

(2)指令:"把它变成像素风格。"------成功,主体结构稳定。

(3)指令:"重绘为彩色,保留像素质感"------再次成功,风格迁移精准,主体未失真。

(4)指令:"再把它变成乐高积木风格。"------再次成功,风格迁移精准,主体未失真。

这种能力,被用户戏称为"甲方终结者"。它意味着,在电商、广告等高频修改的商业场景中,运营和设计师不再需要反复与AI"搏斗",可以用自然语言高效地完成P图、换背景、改服装、调整产品属性等任务,生产力得到极大释放。
三、核心绝活(二):终结"鬼画符"的中文渲染引擎
如果说图像编辑是所有模型的共同难题,那么"写好中文汉字"则是长期以来悬在所有(尤其是国外)图像大模型头上的"达摩克利斯之剑"。由于汉字结构的复杂性,AI生成的中文常常是笔画缺失、结构错乱的"鬼画符",这直接堵死了AI生成海报、Logo、广告图等商业应用的道路。

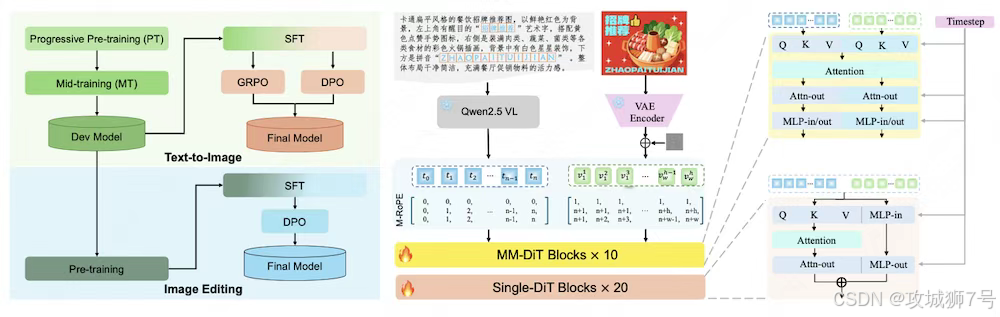
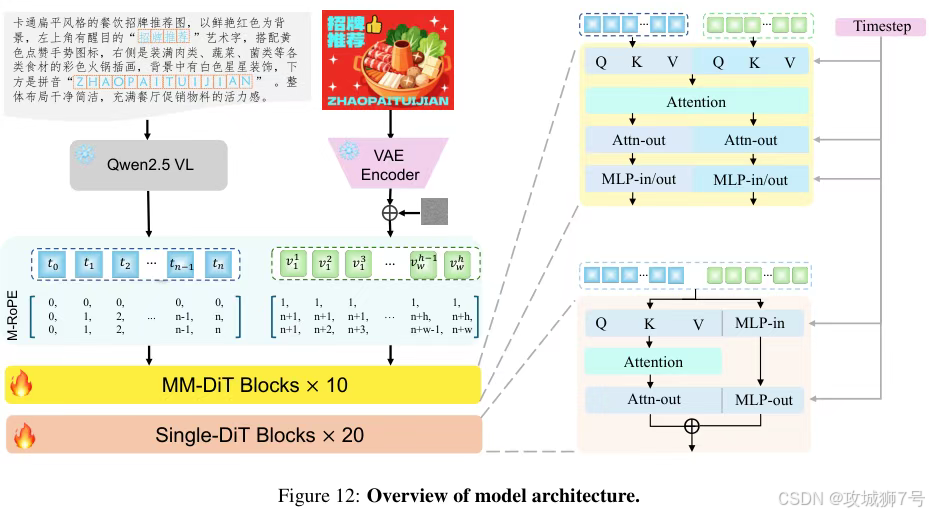
LongCat-Image则系统性地解决了这个顽疾。它采用了一套精心设计的**"课程学习"**策略:
**(1)预训练(学字形):**先用千万量级的合成数据,让模型把通用规范汉字表里的8105个汉字字形认全、记牢。
**(2)SFT微调(学排版):**再用大量真实世界的文本图像(如海报、招牌),让模型学习不同字体、排版和布局的美感。
**(3)RL强化学习(学融合):**最后,引入OCR(文字识别)和美学两个奖励模型进行"阅卷",如果字写得不对或者与背景融合得不自然,就"扣分",通过这种方式倒逼模型提升文字的准确性和艺术性。
凭借这套组合拳,LongCat-Image在ChineseWord评测中取得了90.7分的高分,大幅领先所有对手。这意味着,无论是制作一张写着"疯狂动物城"的电影海报,还是设计一个带有古诗词的国风插图,它都能做到下笔精准、风格协调。
四、一个"务实"的生态:全链路开源的格局
美团的"务实",不仅体现在模型的能力选择上,更体现在其开源策略上。
许多项目开源,往往只放出最终的成品模型。而LongCat-Image团队则全链路开源,提供了三个核心版本:
**(1)LongCat-Image (成品版):**开箱即用,适合直接应用。
**(2)LongCat-Image-Dev (开发版):**一个训练到一半的模型"快照",保留了极高的可塑性,方便开发者基于它进行二次微调,来适应自己特定的业务需求(比如训练一个专门画"火锅"的模型)。
**(3)LongCat-Image-Edit (编辑专用版):**专门为编辑任务优化的版本。
除此之外,团队还开源了完整的训练代码工具链,支持SFT、LoRA等多种主流的微调技术。这种"授人以鱼,不如授人以渔"的做法,真正降低了社区的参与门槛,旨在构建一个开放、协作的开发者生态,让模型能在千行百业中真正落地开花。
结论:不卷参数,卷应用
LongCat-Image的出现,为喧嚣的AI图像生成领域提供了一个冷静而有力的范例。它证明了,模型的价值最终不取决于参数的绝对数量,而在于其解决实际问题的能力。
美团,作为一家深度服务数百万本地生活商家的公司,其AI模型的"偏科"------在编辑和中文渲染上表现优异,但在游戏UI等领域表现平平------恰恰是其深刻商业洞察的体现。它优先解决的,是那些最高频、最普遍、能直接转化为生产力的商业需求。
这场由LongCat-Image引领的"务实派"路线,或许预示着AI图像生成的竞争正进入下半场:当技术的"天花板"足够高时,谁能更"接地气",谁能将强大的AI能力转化为简单、好用、低成本的工具,谁才能最终赢得最广大的用户。
相关链接
* GitHub: `https://github.com/meituan-longcat/LongCat-Image\`
* Hugging Face: `https://huggingface.co/meituan-longcat/LongCat-Image\`
* 在线体验: `https://longcat.ai/\`
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!