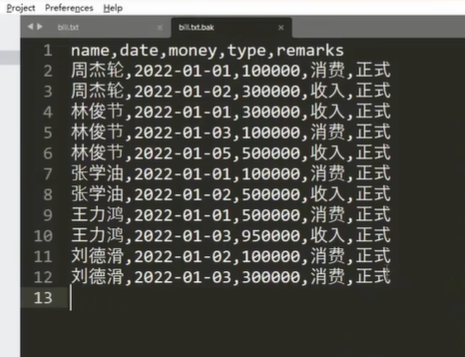
编码的概念


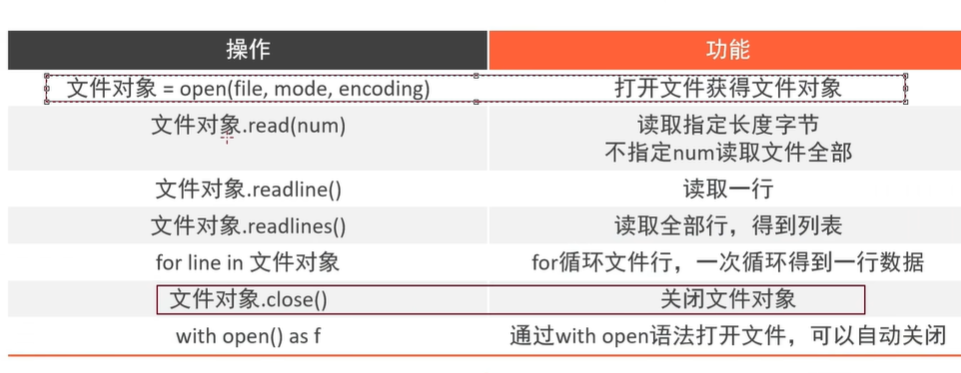
文件
文件概念


文件打开open()


文件只读r*
read(num)

'''
文件操作3大步:
1.打开
2.读或写
3.关闭
'''
# or D:/python-code/python-learn/07_文件操作/01_文件的只读.py
f=open("D:\\python-code\\python-learn\\06_python函数进阶\\01_函数的多返回值.py","r",encoding="utf-8")
# read(num)
content2=f.read(3) # 仅读取3个长度
print(content2)
print('-----')
content=f.read()
print(content)
# close
f.close()运行结果:
注意:文件读完一次后,指针会停留在那个位置,所以content2读完前3个字符'def'后,再次读取content会从第4个字符开始读
readlines()

'''
文件操作3大步:
1.打开
2.读或写
3.关闭
'''
# or D:/python-code/python-learn/07_文件操作/01_文件的只读.py
f=open("D:\\python-code\\python-learn\\06_python函数进阶\\01_函数的多返回值.py","r",encoding="utf-8")
# # read(num)
# content2=f.read(3) # 仅读取3个长度
# print(content2)
#
# print('-----')
# content=f.read()
# print(content)
# close
# readlines
list=f.readlines() #按行读取并存入列表中
for line in list:
# readlines每一行的换行\n不会清除
line=line.strip() # 去除首位的空格和回车(\n)
print(line)
f.close()运行结果:
readline()

'''
文件操作3大步:
1.打开
2.读或写
3.关闭
'''
# or D:/python-code/python-learn/07_文件操作/01_文件的只读.py
f=open("D:\\python-code\\python-learn\\06_python函数进阶\\01_函数的多返回值.py","r",encoding="utf-8")
# # read(num)
# content2=f.read(3) # 仅读取3个长度
# print(content2)
#
# print('-----')
# content=f.read()
# print(content)
# close
# # readlines
# list=f.readlines() #按行读取并存入列表中
# for line in list:
# # readlines每一行的换行\n不会清除
# line=line.strip() # 去除每行每行结尾的空格和回车(\n)
# print(line)
# readline():一次读取一行,\n也不会清除
'''
字符串.strip():去除每行每行结尾的空格和回车(\n)
不是直接修改原str,而是重新生成一个新的str
'''
print(f.readline().strip())
print(f.readline())
print(f.readline())
print(f.readline())
f.close()运行结果:

for循环读取文件*

# 1.打开 2.读取 3.关闭
# 方式1
f=open("D:\\python-code\\python-learn\\06_python函数进阶\\01_函数的多返回值.py","r",encoding="utf-8")
for line in f:
print(line.strip()) # 还需要自行处理\n
'''
这个写法等同于下面的写法
for line in f.readlins():
print(line.strip())
f.close()
'''
# 方式2
for line in open("D:\\python-code\\python-learn\\06_python函数进阶\\01_函数的多返回值.py","r",encoding="utf-8"):
print(line.strip())
'''
这个方式的3个步骤都集成了
open打开文件 for循环读取行 for循环结束会自动close
'''运行结果:
with open打开
'''
with open() as if:
.....
.....
如果以这种语法写,文件会自动关闭,即自动调用close
'''
with open("D:\\python-code\\python-learn\\06_python函数进阶\\01_函数的多返回值.py","r",encoding="utf-8") as f:
for line in f:
print(line.strip())
# 不需要close
# 在python中任何with XXX as xx:的写法,都可以做到不写close运行结果:
文件读取案例

num =0
# 1.打开文件
f=open("D:\\python-code\\python-learn\\07_文件操作\\word.txt",'r',encoding="utf-8")
for line in f.readlines():
line=line.strip()
for word in line.split(" "):
if "itheima"==word:
num += 1
# 关闭文件
f.close()
print(f"文件内有{num}个itheima")文件写入w
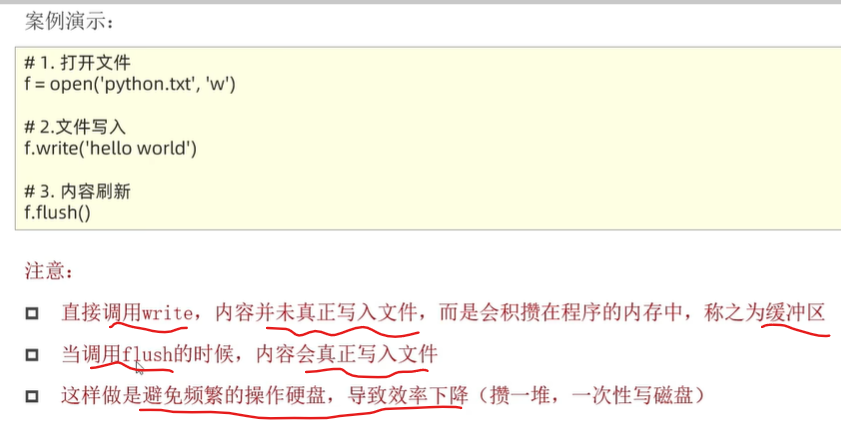
文件不存在,使用'w'会创建新文件
文件存在,使用'w'模式,会将原有内容全部删除再写入
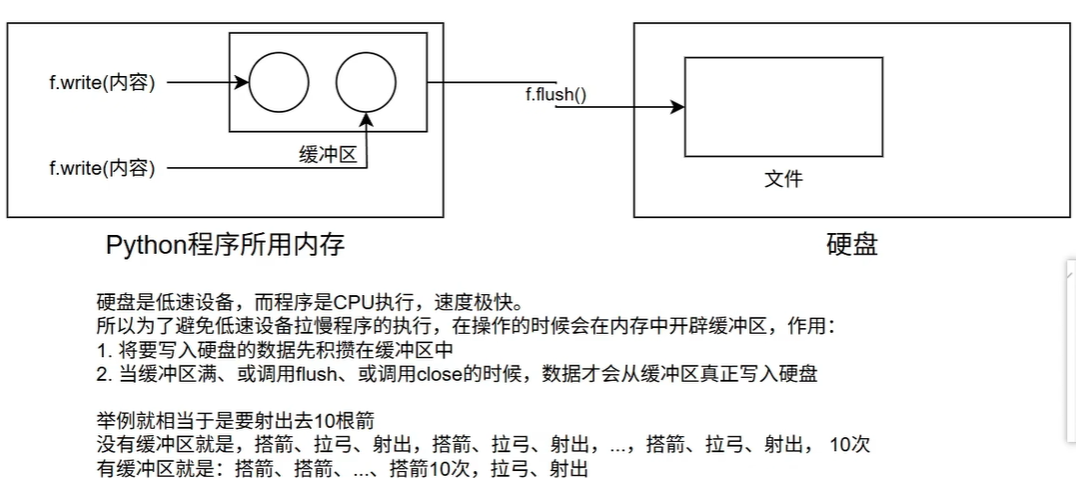
close()方法自带flush()功能
"""
mode:
r只读
w写入
a追加
"""
# 打开
f=open("D:\\python-code\\python-learn\\07_文件操作\\word.txt",'w',encoding="utf-8")
# 将helloword写入文件
# write函数表示将内容写入缓冲区
f.write("hello world") # 将原有内容全部删除再写入
# 将缓冲区内的内容写到硬盘(文件)中
# f.flush()不用写,f.close()方法自带f.flush()功能
# 关闭
f.close()文件追加a

# open
f=open("D:\\python-code\\python-learn\\07_文件操作\\word.txt",'a',encoding="utf-8")
f.write("啦啦啦")
f.write("呱呱呱")
f.flush()
# close
f.close()原文件变为:
二进制处理非文本文件b
"""
文件操作模式:
r只读
w覆盖写
a追加写
b二进制处理
只有文本文件可以r w a
非文本文件必须带有b,以二进制模式处理(读取01操作)
"""
# 打开
fr=open("D:\\python-code\\python-learn\\07_文件操作\\word.txt",'rb')
fw=open("D:\\python-code\\python-learn\\07_文件操作\\word1.txt",'wb')
content=fr.read()
fw.write(content)
fr.close()
fw.close()注意:若为视频等非文本则必须在r,w,a后面加b
文件操作综合案例
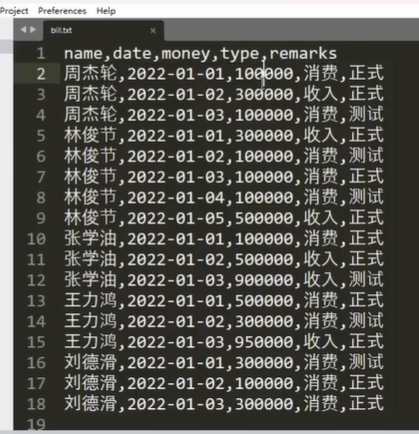

运行结果: