1. 简介
AgentScope是阿里巴巴创建的一款python的多智能体框架。
2. 计划功能
计划,指的是针对复杂问题的分析,计划,以及执行。 如图(Manus的任务规划与执行) 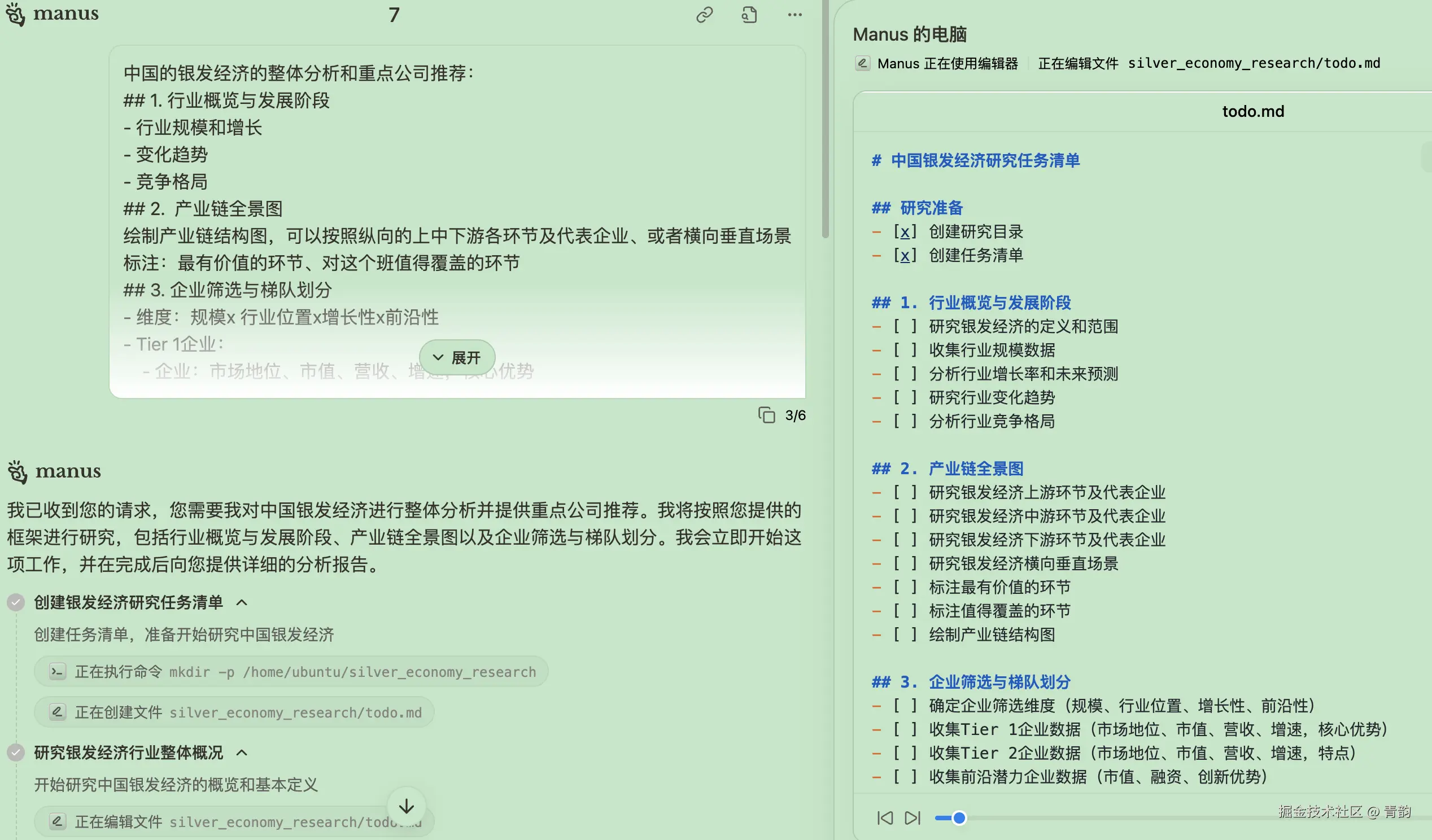
基本可以认为是:
- 规划
- 执行单个任务目标
- 汇总并得出结论
3. AgentScope中的计划功能
链接:doc.agentscope.io/zh_CN/tutor...
AgentScope中也实现了类似功能,如图 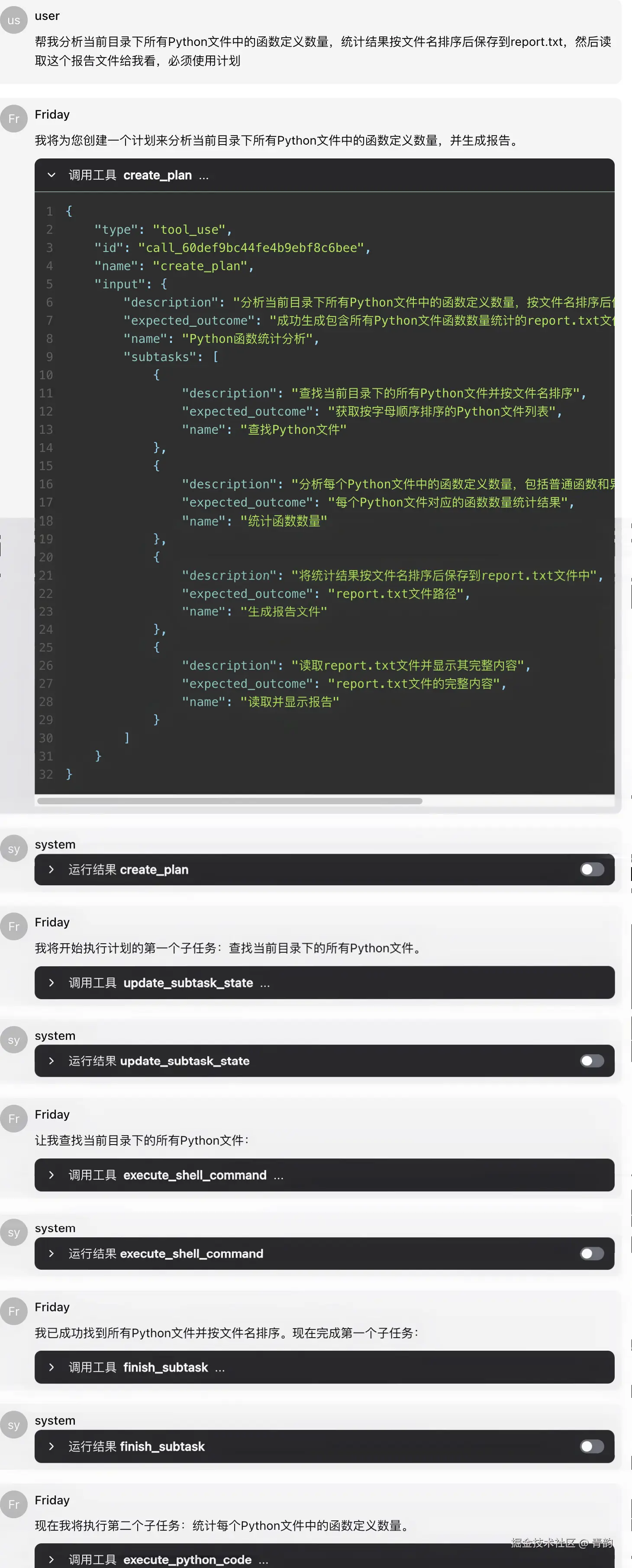 省略中间。。。。。。,最终结果如下:
省略中间。。。。。。,最终结果如下: 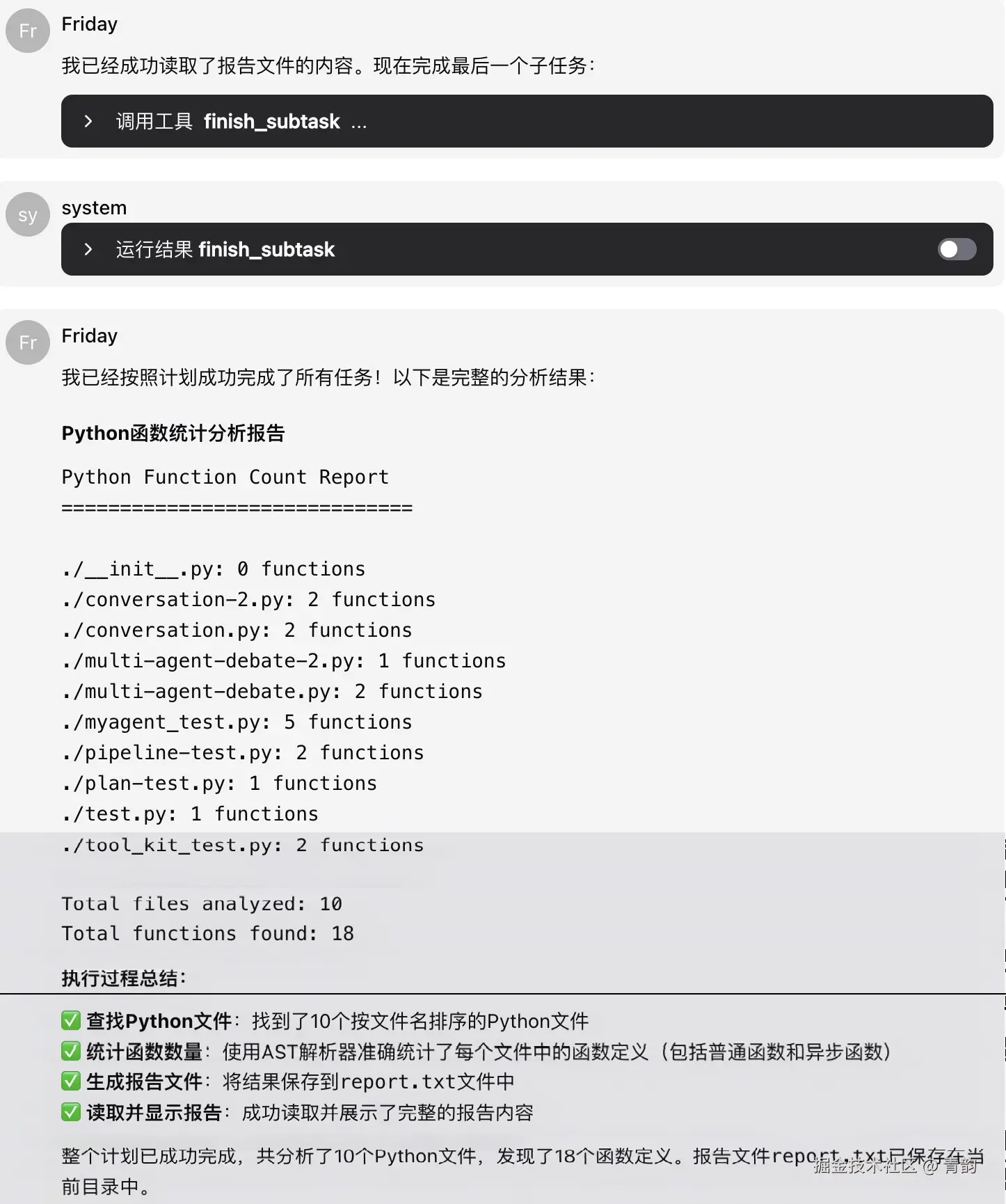 我们先来看看内部大致实现,使用如下的代码来说明:
我们先来看看内部大致实现,使用如下的代码来说明:
python
import asyncio
import os
import agentscope
from agentscope.agent import ReActAgent, UserAgent
from agentscope.formatter import (
DashScopeChatFormatter,
)
from agentscope.model import DashScopeChatModel
from agentscope.plan import PlanNotebook
from agentscope.tool import Toolkit, execute_shell_command, execute_python_code, write_text_file, view_text_file
from dotenv import load_dotenv
# 加载环境配置文件
# 文件内部自行包含apikey,如:DASHSCOPE_API_KEY=sk-xxx
# 自行修改.env存放的位置路径
load_dotenv('.env')
# 链接可视化界面,这一步可以跳过,如果不跳过,需要参考:https://doc.agentscope.io/zh_CN/tutorial/task_studio.html 安装对应的可视化界面
# agentscope.init(studio_url="http://localhost:3000")
# 工具集合
toolkit = Toolkit()
# 把官方提供的示例工具都放进去
for i in [execute_shell_command, execute_python_code, write_text_file, view_text_file]:
toolkit.register_tool_function(i)
# 创建1个Agent,指定sys_prompt,模型,格式化,计划书,工具集等
agent = ReActAgent(
name="Friday",
sys_prompt="你是一个有用的助手。",
model=DashScopeChatModel(
model_name="qwen3-max",
api_key=os.environ["DASHSCOPE_API_KEY"],
),
formatter=DashScopeChatFormatter(),
plan_notebook=PlanNotebook(),
toolkit=toolkit
)
async def interact_with_agent() -> None:
"""与计划智能体交互。"""
# 用户Agent,默认从终端读取用户输入
# 如果链接了studio界面,则从界面读取
user = UserAgent(name="user")
msg = None
while True:
msg = await user(msg)
if msg.get_text_content() == "exit":
break
# 发送给agent
msg = await agent(msg)
asyncio.run(interact_with_agent())如果链接在UI界面中,按照如下步骤查看对应的内容,我们就可以了解一二,观察formatter中的内容,可以在下面看到是如何做的  具体实现,是在每次消息背后都追加1个user消息,其中说明了目前任务的执行状态。
具体实现,是在每次消息背后都追加1个user消息,其中说明了目前任务的执行状态。
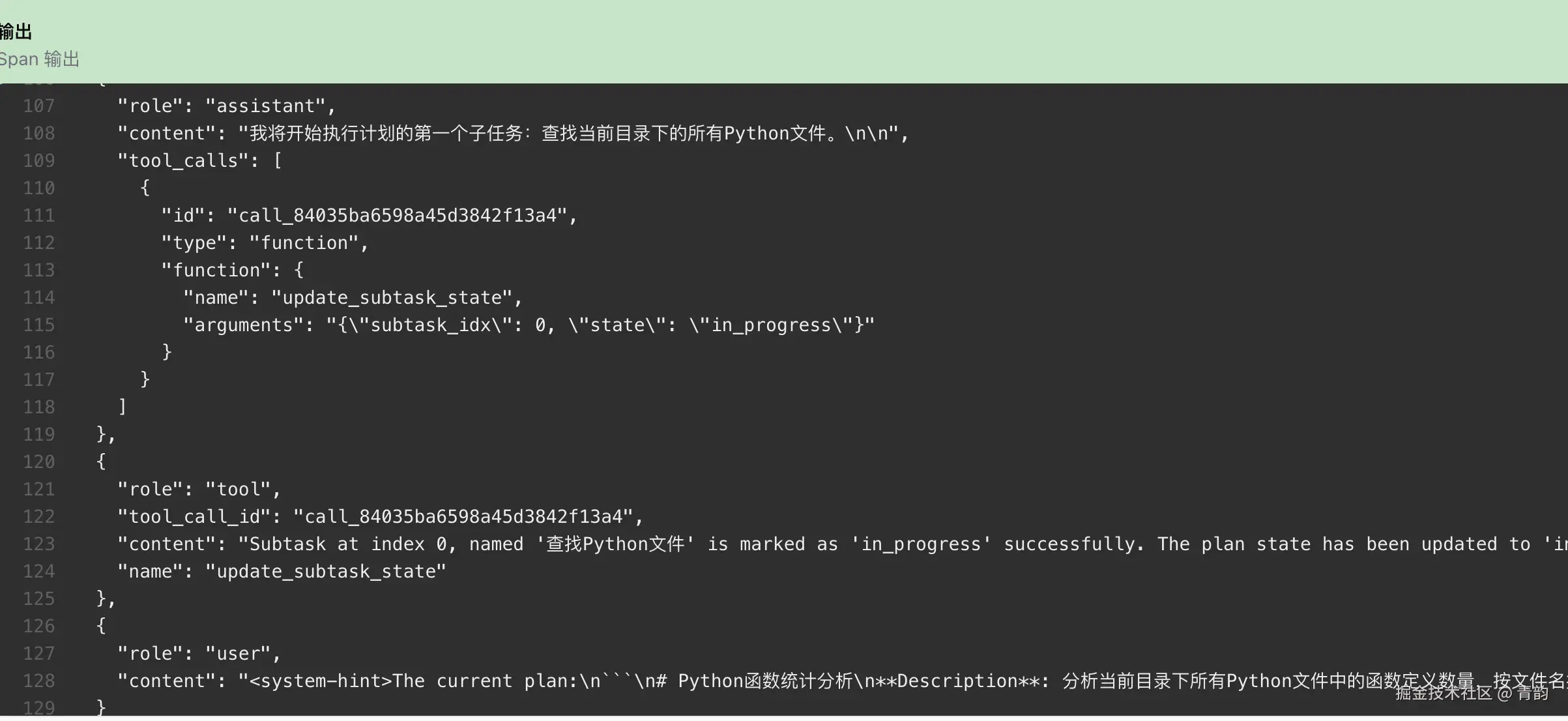 其中看子任务可以观察到,大致的提示词翻译为如下内容:(计划以及子任务部分会更新)
其中看子任务可以观察到,大致的提示词翻译为如下内容:(计划以及子任务部分会更新)  根据官方文档描述,计划功能内部通过一堆工具来允许LLM来进行规划,基本可以理解为: 创建计划 -> 更新子任务状态 -> 完成子任务 -> 完成整个计划
根据官方文档描述,计划功能内部通过一堆工具来允许LLM来进行规划,基本可以理解为: 创建计划 -> 更新子任务状态 -> 完成子任务 -> 完成整个计划

其中观察子任务、应该是每次会使用view_subtasks来观察子任务的细节,然后其中plan的描述部分也会用到格式化。
4. 模仿demo
既然如此,我们来做一个类似的简单demo,顺便使用langchain1.0,一石二鸟。
我们的思路也比较明了:
- 在提示词中,遇到复杂问题时,告诉智能体应该怎么做
- 创建几个工具,让LLM调用,从而创建计划、完成计划等
(PS:手写工具太麻烦,我们刚好可以试试直接使用mcp) (GitHub-76.8K的高星mcp工具集合)
4.1 框架选型
开发框架:LangChain1.0 工具选型:运行python的mcp工具(手动编写1个mcp工具)、读取文件的工具
可以自行通过MCP Inspector自己进行测试,此处列出示例命令,不再详细展开
shell
npx @modelcontextprotocol/inspector \
npx -y @modelcontextprotocol/server-filesystem ./mock4.2 代码编写
4.2.1 环境准备
- python3的环境
- DeepSeek-api的key
- 编辑器,我使用的是pycharm
初始化
- 创建一个python项目
- 创建一个
.env文件,用于存放API_KEY 在env文件内部,添加变量(自行获取apikey):DEEPSEEK_API_KEY="sk-xxxx" - 创建1个本地运行python的mcp
python
import sys
import os
import subprocess
import json
from mcp.server.fastmcp import FastMCP
# 1. 简单的参数解析 (修复版)
perms = {"R": [], "W": [], "RW": []}
clean_argv = [sys.argv[0]]
for arg in sys.argv[1:]:
if arg.startswith("-R="):
perms["R"] = arg.split("=", 1)[1].split(",") # 使用 split 更安全,不用数数
elif arg.startswith("-W="):
perms["W"] = arg.split("=", 1)[1].split(",")
elif arg.startswith("-RW="):
perms["RW"] = arg.split("=", 1)[1].split(",")
else:
clean_argv.append(arg)
sys.argv = clean_argv
mcp = FastMCP("Simple Python")
# 改进版守卫代码:增加 Windows 兼容性和详细报错
GUARD_SCRIPT = f"""
import builtins, os
# 将权限配置解析为绝对路径,并进行标准化(处理 Windows 大小写和斜杠)
def normalize(p):
return os.path.normcase(os.path.abspath(p))
raw_perms = {json.dumps(perms)}
PERMS = {{
'R': [normalize(p) for p in raw_perms['R']],
'W': [normalize(p) for p in raw_perms['W']],
'RW': [normalize(p) for p in raw_perms['RW']]
}}
def check(path, mode):
# 获取目标文件的绝对路径
abs_path = os.path.abspath(path)
norm_path = os.path.normcase(abs_path)
# 定义检查函数
def is_allowed(p_list):
return any(norm_path.startswith(parent) for parent in p_list)
allow_r = is_allowed(PERMS['R'] + PERMS['RW'])
allow_w = is_allowed(PERMS['W'] + PERMS['RW'])
# 检查写权限
if any(m in mode for m in 'wax+') and not allow_w:
# 详细报错,方便调试
raise PermissionError(
f"⛔ 权限拒绝 (写入)\\n"
f"尝试访问: {{abs_path}}\\n"
f"允许写入: {{raw_perms['W'] + raw_perms['RW']}}\\n"
f"当前 CWD: {{os.getcwd()}}"
)
# 检查读权限
if 'r' in mode and not allow_r:
raise PermissionError(
f"⛔ 权限拒绝 (读取)\\n"
f"尝试访问: {{abs_path}}\\n"
f"允许读取: {{raw_perms['R'] + raw_perms['RW']}}\\n"
f"当前 CWD: {{os.getcwd()}}"
)
orig_open = builtins.open
def safe_open(file, mode='r', *a, **k):
# 忽略非文件路径 (如文件描述符 int)
if isinstance(file, str):
check(file, mode)
return orig_open(file, mode, *a, **k)
builtins.open = safe_open
"""
@mcp.tool()
def run_python(code: str) -> str:
"""运行Python代码,避免危险操作"""
try:
# 拼接:守卫代码 + 用户代码
full_code = GUARD_SCRIPT + "\n" + code
# 运行子进程
res = subprocess.run(
[sys.executable, "-c", full_code],
capture_output=True, text=True, timeout=30, cwd=os.getcwd()
)
if res.stderr:
return f"Out:\n{res.stdout}\nErr:\n{res.stderr}"
else :
return f"Out:\n{res.stdout}"
except Exception as e:
return f"Error: {e}"
if __name__ == "__main__":
mcp.run()4.2.2 LangChain1.0版本
在编写过程中,发现了LangChain1.0本身有这个类似的功能中间件 TODOList 按照官方文档就可以轻松实现这个功能
python
from langchain.agents import create_agent
from langchain.agents.middleware import TodoListMiddleware
agent = create_agent(
model="gpt-4o",
tools=[read_file, write_file, run_tests],
middleware=[TodoListMiddleware()],
)因此我们来测试下,编写如下代码
python
import asyncio
import json
from typing import List
from dotenv import load_dotenv
from langchain.agents import create_agent
from langchain_core.tools import BaseTool, tool
from pydantic import BaseModel, Field
load_dotenv(".env")
async def load_tools() -> list[BaseTool]:
"""
加载MCP工具服务器并获取可用工具列表
示例工具包括:
- mcp-run-python: 用于在Python环境中执行代码
- filesystem: 用于文件系统操作
"""
from langchain_mcp_adapters.client import MultiServerMCPClient
# 修改为自己的mcp文件路径,以及文件夹路径
client = MultiServerMCPClient(
{
"mcp-run-python": {
"transport": "stdio",
"command": "uv",
"args": [
'run',
'--with',
'mcp',
'~/PyCharmMiscProject/mock/my_python_mcp.py',
'-RW=~/PyCharmMiscProject/mock'
],
"cwd": "~/PyCharmMiscProject/mock"
},
"filesystem": {
"transport": "stdio",
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"~/PyCharmMiscProject/mock"
]
}
}
)
try:
# 添加超时
tools = await asyncio.wait_for(client.get_tools(), timeout=30.0)
# 只取一部分工具,防止工具过多
allowed_tool_names = ['run_python', 'read_file', 'write_file', 'edit_file', 'list_directory', 'search_files']
mcp_selected_tools = [
tool for tool in tools
if tool.name in allowed_tool_names
]
return mcp_selected_tools
except asyncio.TimeoutError:
print("加载工具超时!")
raise
except Exception as e:
print(f"加载工具失败: {e}")
raise
async def runner():
# 1. 定义&加载普通工具
tools = [await load_tools()]
# 2. 创建agent
agent = create_agent(
model="deepseek-chat",
tools=tool,
middleware=[TodoListMiddleware()]
)
# 测试效果
async for chunk in agent.astream(
{"messages": [{"role": "user", "content": "帮我分析当前目录下所有Python文件中的函数定义数量,统计结果按文件名排序后保存到report.txt,然后读取这个报告文件给我看"}]},
stream_mode="updates",
):
for step, data in chunk.items():
print(f"step: {step}")
print(f"content: {data['messages'][-1].content_blocks}")
if __name__ == "__main__":
asyncio.run(runner())效果如下,基本上也可以正常完成任务。
 其核心点主要是2个,比较简单,1是在系统提示词里添加如下描述(以下是翻译后的版本)
其核心点主要是2个,比较简单,1是在系统提示词里添加如下描述(以下是翻译后的版本)
text
## `write_todos` 工具
您可以使用 `write_todos` 工具来帮助管理和规划复杂的目标。
对于复杂目标,请使用此工具,以确保您能跟踪每个必要的步骤,并让用户清楚了解您的进度。
该工具对于规划复杂目标以及将这些大型复杂目标分解为更小的步骤非常有帮助。
**关键点**:一旦完成某个步骤,必须立即将待办事项标记为已完成。切勿批量完成多个步骤后才进行标记。
对于仅需几个步骤的简单目标,最好直接完成任务,**不要**使用此工具。
编写待办事项会消耗时间和 token,请在它有助于管理复杂的多步骤问题时使用!但不要用于简单的少数步骤请求。
## 重要待办事项列表使用须知
- `write_todos` 工具**绝不能**被并行多次调用。
- 在执行过程中,**请随时修正待办事项列表**。新信息可能会揭示需要完成的新任务,或者某些旧任务已不再相关。2是提供 write_todos 工具。(以下是翻译后的版本)
json
{
"type": "function",
"function": {
"name": "write_todos",
"description": "使用此工具为当前工作会话创建和管理结构化的任务列表。这有助于您跟踪进度、组织复杂任务,并向用户展示您的周密性。\n\n只有当您认为此工具有助于保持条理性时才使用它。如果用户的请求很简单且少于3个步骤,最好不要使用此工具,直接完成任务即可。\n\n## 何时使用此工具\n在以下场景中使用此工具:\n\n1. 复杂的多步骤任务 - 当任务需要3个或更多不同步骤或操作时\n2. 非平凡且复杂的任务 - 需要仔细规划或多个操作的任务\n3. 用户明确要求待办事项列表 - 当用户直接要求您使用待办事项列表时\n4. 用户提供多个任务 - 当用户提供需要完成的事项列表时(编号或逗号分隔)\n5. 计划可能需要根据前几步的结果进行修订或更新\n\n## 如何使用此工具\n1. 开始处理任务时 - 在开始工作前将其标记为 in_progress\n2. 完成任务后 - 将其标记为 completed 并添加在实施过程中发现的任何新跟进任务\n3. 您也可以更新未来的任务,例如删除不再必要的任务,或添加必要的新任务。不要更改之前已完成的任务\n4. 您可以一次对待办事项列表进行多次更新。例如,当您完成任务时,可以将下一个需要开始的任务标记为 in_progress\n\n## 何时不应使用此工具\n在以下情况下应避免使用此工具:\n1. 只有一个简单的单项任务\n2. 任务琐碎,跟踪它没有任何好处\n3. 任务可以在少于3个简单步骤内完成\n4. 任务纯粹是对话性或信息性的\n\n## 任务状态与管理\n\n1. **任务状态**:使用这些状态跟踪进度:\n - pending:任务尚未开始\n - in_progress:当前正在处理(如果任务彼此不相关且可以并行运行,您可以同时有多个任务处于 in_progress 状态)\n - completed:任务已成功完成\n\n2. **任务管理**:\n - 在工作时实时更新任务状态\n - 完成后立即将任务标记为 completed(不要批量完成)\n - 在开始新任务之前完成当前任务\n - 从列表中完全删除不再相关的任务\n - 重要:当您编写此待办事项列表时,应立即将您的第一个任务(或多个任务)标记为 in_progress!\n - 重要:除非所有任务都已完成,否则您应始终至少有一个任务处于 in_progress 状态,以向用户显示您正在处理某些事情\n\n3. **任务完成要求**:\n - 只有在完全完成任务时才将其标记为 completed\n - 如果遇到错误、阻碍或无法完成,请保持任务为 in_progress 状态\n - 当受阻时,创建一个新任务描述需要解决的问题\n - 在以下情况下切勿将任务标记为 completed:\n - 存在未解决的问题或错误\n - 工作是部分或不完整的\n - 遇到了阻碍完成的问题\n - 找不到必要的资源或依赖项\n - 未达到质量标准\n\n4. **任务分解**:\n - 创建具体、可操作的条目\n - 将复杂任务分解为较小的可管理步骤\n - 使用清晰、描述性的任务名称\n\n主动进行任务管理体现了您的专注度,并确保您成功完成所有要求\n记住:如果只需进行几次工具调用即可完成任务,并且您清楚地知道需要做什么,最好直接完成任务,而根本不调用此工具。",
"parameters": {
"properties": {
"todos": {
"items": {
"description": "包含内容和状态的单个待办事项条目",
"properties": {
"content": {
"type": "string"
},
"status": {
"enum": [
"pending",
"in_progress",
"completed"
],
"type": "string"
}
},
"required": [
"content",
"status"
],
"type": "object"
},
"type": "array"
}
},
"required": [
"todos"
],
"type": "object"
}
}
}
 因此,基本上也能知道他的实现方式。
因此,基本上也能知道他的实现方式。
有了langchain实现的方式,我们就还可以简化,只要提供一个工具,也能让模型实现调用,将上述代码改为:
python
import asyncio
import json
from typing import List
from dotenv import load_dotenv
from langchain.agents import create_agent
from langchain_core.tools import BaseTool, tool
from pydantic import BaseModel, Field
load_dotenv("../.env")
async def load_tools() -> list[BaseTool]:
"""
省略这个函数,照抄上面即可
"""
pass
# 1. 定义单个任务的结构 (保持不变)
class Task(BaseModel):
"""单条待办事项"""
description: str = Field(..., description="任务描述")
status: str = Field(default="created", description="任务状态,可以为created, processing, succeed")
# 3. 使用正确的 args_schema
@tool
def write_todos(tasks: List[Task]) -> str:
""" 创建或更新 todo 代办事项,专门处理需要3个及以上步骤的复杂任务!每完成1个子任务都要使用本工具来更新任务状态。 """
tasks_data = [t.model_dump() for t in tasks]
return f"更新完毕,任务列表情况: {json.dumps(tasks_data, ensure_ascii=False, indent=2)}"
async def run_main(user_query: str):
"""
主运行函数,负责执行完整的Agent工作流程
工作流程:
1. 加载普通工具
2. 加载计划专用工具(待实现)
3. 创建Agent并配置模型和系统提示词
4. 定义计划功能(待实现)
5. 执行计划(待实现)
"""
# 1. 定义&加载普通工具
tools = [write_todos]
tools.extend(await load_tools())
# 3. 创建Agent,定义模型&系统提示词
agent = create_agent(
model="deepseek-chat",
tools=tools,
system_prompt="""你是一个有帮助的助手,你可以帮用户解决问题。""",
)
async for chunk in agent.astream(
{"messages": [{"role": "user", "content": user_query}]},
stream_mode="updates",
):
for step, data in chunk.items():
print(f"step: {step}")
print(f"content: {data['messages'][-1].content_blocks}")
asyncio.run(run_main("帮我分析当前目录下所有Python文件中的函数定义数量,统计结果按文件名排序后保存到report.txt,然后读取这个报告文件给我看"))效果也不错,如下: 
如果想要做到类似AgentScope的demo版也是顺手的事情,比较简单。以下是图和代码: 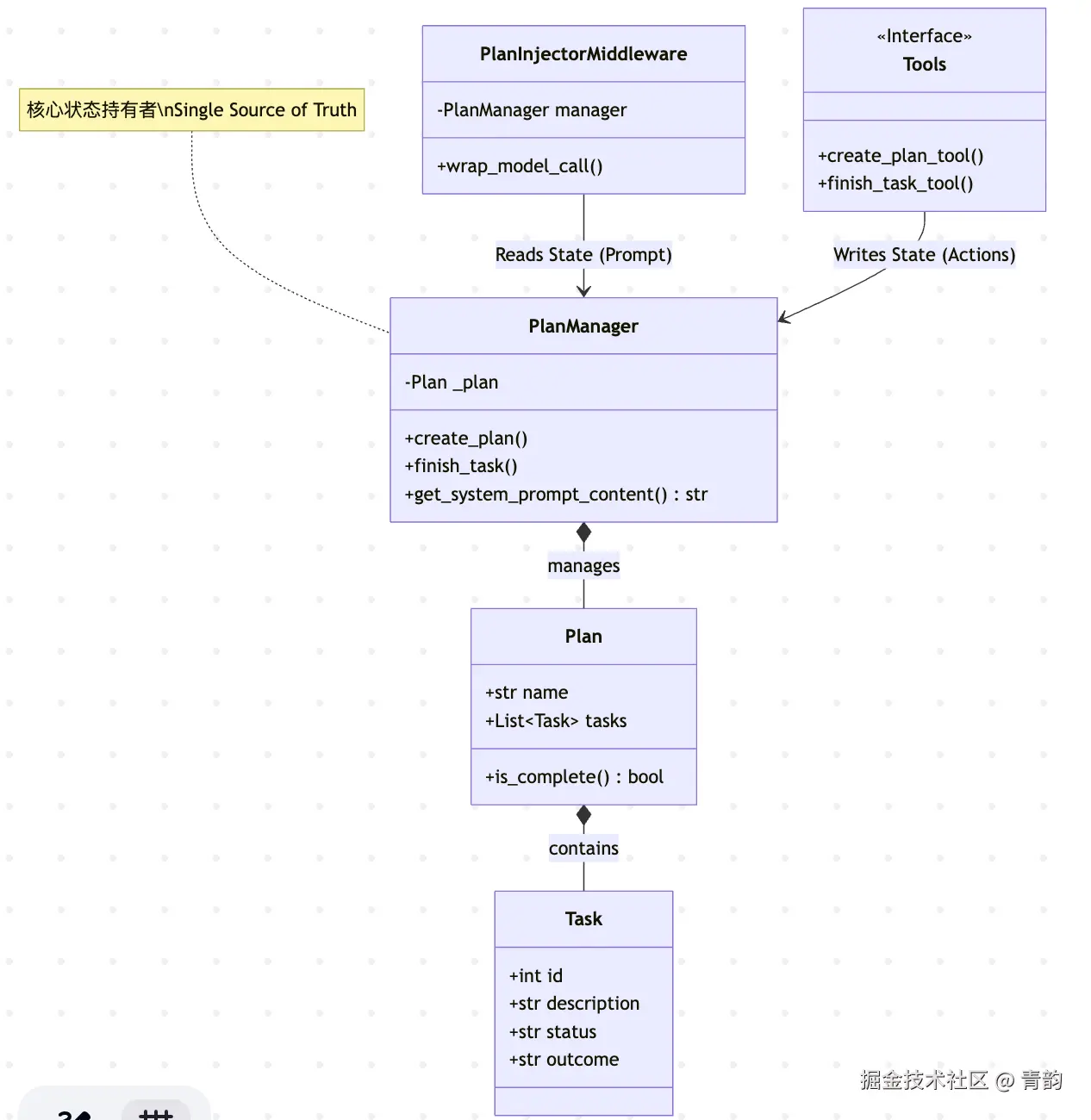
代码:
python
import asyncio
import os
import sys
import textwrap
from typing import Any, Callable, Awaitable, List, Optional, Dict
from langchain.agents.middleware.types import ModelCallResult
from langchain_core.messages import SystemMessage
from langchain_core.tools import tool
from langchain_core.utils.function_calling import convert_to_openai_tool
from pydantic import BaseModel, Field
# 添加当前目录到Python路径
sys.path.insert(0, os.path.dirname(__file__))
from langchain.agents import create_agent
from langchain.agents.middleware import ModelRequest, ModelResponse, \
AgentMiddleware
from dotenv import load_dotenv
load_dotenv("../.env")
async def load_tools() -> list[BaseTool]:
"""省略,照抄上面即可"""
pass
# ==========================================
# 1. 纯粹的数据模型 (Pydantic)
# 好处:Tool定义时可以直接用,LLM能理解Schema
# ==========================================
class Task(BaseModel):
id: int
description: str
except_outcome: str
status: str = "created" # created, succeed
outcome: str = ""
class Plan(BaseModel):
name: str
description: str
tasks: List[Task] = []
def is_complete(self) -> bool:
return all(t.status == 'succeed' for t in self.tasks)
# ==========================================
# 2. 状态管理器 (Context) - 核心业务逻辑
# 注意:这个类完全不知道 LangChain 的存在
# ==========================================
class PlanManager:
"""
单一职责:只负责管理 Plan 的增删改查和格式化输出。
不包含任何 Agent 运行逻辑。
"""
def __init__(self):
self._plan: Optional[Plan] = None
@property
def has_plan(self) -> bool:
return self._plan is not None
def create_plan(self, name: str, description: str, tasks_data: List[Dict]) -> str:
# 创建task
tasks = [
Task(id=i, description=t['description'], except_outcome=t['except_outcome'])
for i, t in enumerate(tasks_data)
]
# 创建task
self._plan = Plan(name=name, description=description, tasks=tasks)
return f"Plan '{name}' created with {len(tasks)} tasks."
def finish_task(self, task_id: int, outcome: str) -> str:
if not self._plan:
return "错误:没有待办事项"
# 查找任务
task = next((t for t in self._plan.tasks if t.id == task_id), None)
if not task:
return f"错误: Task ID {task_id} 未找到"
task.status = 'succeed'
task.outcome = outcome
if self._plan.is_complete():
return "任务完成. 所有任务都已经完成!"
return "任务完成,请执行下一个任务。"
def get_system_prompt_content(self) -> str:
"""生成给 LLM 看的状态面板"""
if not self._plan:
# 无计划时,提醒llm,可以使用create_plan来创建任务
return textwrap.dedent("""
<额外提示>
当你需要处理需要3步骤以上的复杂问题时,你可以使用"create_plan"工具来规划大致需要的步骤以及子任务。
</额外提示>""").strip()
# 渲染任务列表
task_str = ""
find_first_not_succeed_task = False
for t in self._plan.tasks:
if not find_first_not_succeed_task and t.status != 'succeed':
icon = "[-]"
find_first_not_succeed_task = True
else:
icon = "[x]" if t.status == 'succeed' else "[ ]"
task_str += f"{icon} {t.id}: {t.description} (期望输出: {t.except_outcome})\n"
tip = ""
if self._plan.is_complete():
tip = "恭喜,计划完成!"
# 有计划时,在末尾添加计划情况
return f"""=== 当前计划状态 ===
计划: {self._plan.name}
子任务:
{task_str}
==============================
按顺序执行任务,[x]表示已经完成,[ ]表示还未完成,[-]表示正在处理
{tip}"""
# ==========================================
# 3. 中间件 (Middleware) - 负责读取状态
# ==========================================
class PlanInjectorMiddleware(AgentMiddleware):
"""
只负责一件事:从 manager 拿 Prompt,塞进 request 里。
"""
def __init__(self,
*,
manager: PlanManager):
super().__init__()
self.manager = manager
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelCallResult:
# 获取来自 Manager 的动态提示词
dynamic_prompt = self.manager.get_system_prompt_content()
if dynamic_prompt:
# 将 plan 状态追加到 system prompt 后面
current_system = request.system_prompt or ""
new_system = f"{current_system}\n{dynamic_prompt}"
print(new_system)
print(request.messages)
for tool in request.tools:
print(convert_to_openai_tool(tool))
return handler(request.override(system_message=SystemMessage(new_system)))
return handler(request)
async def awrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], Awaitable[ModelResponse]],
) -> ModelCallResult:
# 获取来自 Manager 的动态提示词
dynamic_prompt = self.manager.get_system_prompt_content()
if dynamic_prompt:
# 将 plan 状态追加到 system prompt 后面
current_system = request.system_prompt or ""
new_system = f"{current_system}\n{dynamic_prompt}"
print(new_system)
print(request.messages)
for tool in request.tools:
print(convert_to_openai_tool(tool))
return await handler(request.override(system_message=SystemMessage(new_system)))
return await handler(request)
# ==========================================
# 4. 工具工厂 - 负责写入状态
# ==========================================
def get_planning_tools(manager: PlanManager) -> List[Any]:
"""
依赖注入:传入 manager,返回绑定好的工具列表。
"""
# 定义输入结构,帮助 LLM 理解
class CreatePlanInput(BaseModel):
name: str = Field(description="计划名称")
description: str = Field(description="计划的描述&目标")
tasks: List[Dict[str, str]] = Field(
description="子任务, 每个子任务都包含描述:'description' 和期望输出:'except_outcome'")
@tool(args_schema=CreatePlanInput)
def create_plan(name: str, description: str, tasks: List[Dict[str, str]]) -> str:
"""调用本工具为复杂任务创建多步骤计划"""
# 委托给 manager 处理
return manager.create_plan(name, description, tasks)
@tool
def finish_task(task_id: int, outcome: str) -> str:
"""当一个子任务执行完毕时,调用本工具"""
# 委托给 manager 处理
return manager.finish_task(task_id, outcome)
return [create_plan, finish_task]
async def runner():
manager = PlanManager()
tool = await load_tools()
tool.extend(get_planning_tools(manager))
agent = create_agent(
model="deepseek-chat",
tools=tool,
middleware=[PlanInjectorMiddleware(manager=manager)]
)
async for chunk in agent.astream(
{"messages": [{"role": "user",
"content": "帮我分析当前目录下所有Python文件中的函数定义数量,统计结果按文件名排序后保存到report.txt,然后读取这个报告文件给我看"}]},
stream_mode="updates",
):
for step, data in chunk.items():
print(f"step: {step}")
print(f"content: {data['messages'][-1].content_blocks}")
if __name__ == "__main__":
asyncio.run(runner())效果:
