1、背景介绍
由于之前的应用收发数是基于PCIe方式的单机方案,存在扩展性的限制,现打算将其通过多块计算板卡基于网络进行方案改造,以达到带宽与性能线性拓展的能力。本文将基于DPDK与lwip协议栈详细阐述其中解决网络性能的方式,以基本满足应用业务目标。
2、架构分析与设计
2.1 业务特征描述
数据源端以RocketIO方式通过最多8根光纤进行接入,其中每根光纤带宽为6.4Gbps,这些数据过来后并不是立刻通过FPGA进行转发,而是会先进入FPGA侧的DDR中,由FPGA侧进行数据包的预处理(生成新数据包),然后发送到鲲鹏CPU端进行计算处理,处理完成后再将结果通过DDS网络(非DPDK网络)进行发出。
鲲鹏CPU端网卡是100Gbps,而FPGA侧通常具备一路或两路发数端口,如果是一路(简称40G网络应用),其流量范围是38.4Gbps(6根光纤)到40Gbps,如果是两路(简称80G网络应用),则达到51.2Gbps(8根光纤)到80Gbps,这其中峰值流量是瞬间产生的(由DDR累积产生),不会一直触发这么多,所以可认为平均流量是38.4Gbps或51.2Gbps。
2.2 数据模型
由RocketIO过来的数据,经FPGA侧,会进行数据格式的转换,如下图所示:
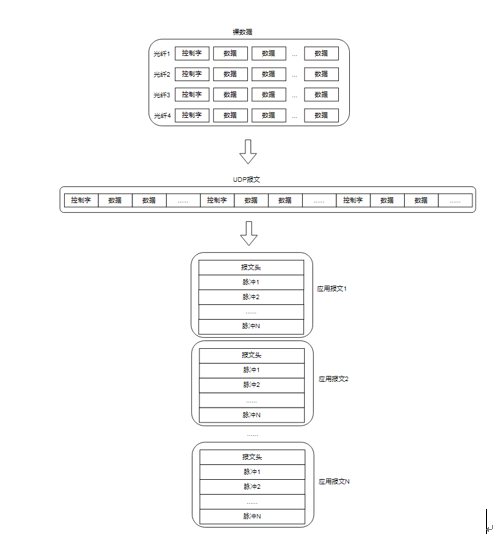
图1 数据格式转换图
首先,RocketIO过来的数据是按光纤拆分,每个数据包都包含一个控制字和多块数据,之后通过FPGA侧将这些光纤的数据进行合并,生成一个UDP报文进行发送,最后由鲲鹏CPU接收到的这些UDP报文将被组合成应用所需的大报文,其包含一个报文头和多份脉冲报文(也称之为帧)。
应用计算处理的基本单位是这个大报文,该大报文被处理的最大延迟要求是500ms,这个时间段包含大报文进到网卡、进行计算处理及产生结果通过网卡发出。而整个系统(并非仅指该系统,而是指从雷达到鲲鹏CPU侧这一路上的所有系统)链路上的最大延迟是600ms。
2.3 关键技术
2.3.1 DPDK
DPDK是一个开源的高性能数据包处理框架,它通过绕过Linux内核协议栈,直接在用户空间处理网络数据包,广泛被应用于需要高速网络处理的领域。DPDK提供多种用户态驱动,结合轮询模式,将数据包从网卡直接DMA到用户态内存中,实现了零拷贝,大幅减少了内存操作。
不过,DPDK本身并不具备协议栈的处理能力,只负责祼数据包的高速收发处理,同时结合大页内存,提升内存访问效率,并且DPDK库本身提供了各线程调度方式。
2.3.2 LWIP
Lwip是一个专为资源受限的嵌入式系统设计的开源TCP/IP协议栈,提供了兼容传统Socket API的接口,具备可移植性。在内存管理方面,提供了专门的数据结构可用于消除冗余的数据拷贝,同时采用动态内存池和静态内存堆的管理模式,以平衡内存利用率和碎片问题。
Lwip通常以独立的内核线程运行,当网卡接收到数据后,底层驱动会将数据包封装成消息,投递到一个名为tcpip_mbox的邮箱中,当线程被唤醒后,会从邮箱中取出消息并进行解析,这种设计使得用户程序与内核协议栈通过进程间通信机制进行交互,彼此独立。
2.4 架构设计
通过结合DPDK与lwip两项关键技术点就形成了如下的架构:
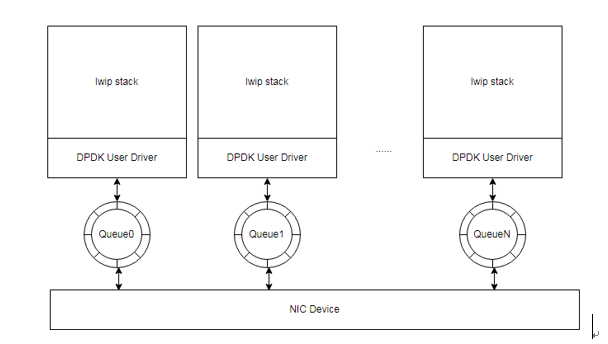
图2 轮询架构设计
每个DPDK线程通过轮询网卡各自的队列,获得网络数据包,之后交给lwip进行TCP/IP协议栈(这里只用到UDP协议)的处理,剥离得到数据包中有用的报文。
不过,由于该应用系统数据模型的特殊性,带来了以下几方面的挑战:
- 如何快速接收数据包,并生成应用大报文
为了保证应用数据包不能在FPGA侧的DDR发生溢出,需要在CPU侧网卡端将其所有UDP数据包都能够收齐,同时还要将其组合成大报文,其间如果处理不够好,就会反向影响收包效率。- 各个脉冲的顺序性如何进行并行分割
由于脉冲是一个接着一个被处理的,因此貌似天然的是串行化的流程,但考虑到应用计算处理单元是大报文,所以可基于这个方面进行并行化处理。但这种分割如何与调度进行结合起来处理,仍是一大挑战。
基于这些挑战,提出了需从FPGA发数模型、线程模型和多核亲和性这三个方面予以解决。整个调度流程如下图所示:
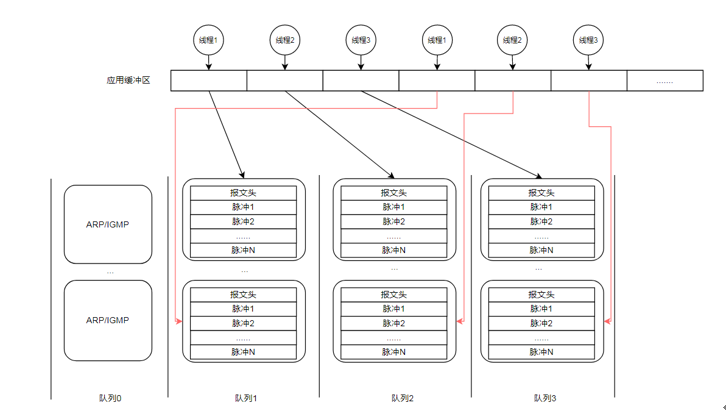
图3 调度流程图
2.4.1 FPGA发数模型
为了配合网络软件层的处理模型,在FPGA侧发数阶段,需要按光纤进行发数,如下图所示:
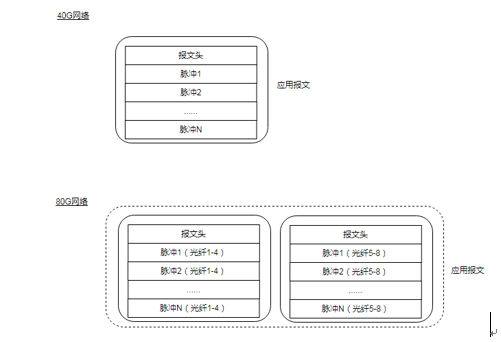
图4 FPGA发数模型
在40G网络,由于只有一路端口,发数时就会将整个光纤(1-4)一起发出,而在80G网络,存在两路端口,因此按光纤进行了分区发送,其中每路只发送4个光纤的数据,且每路的报文头是相同的。另外,FPGA侧每次在发送这些大报文时,其中最大报文大小为64M。
2.4.2 线程模型
为了充分发挥网卡带宽,需要结合网卡RSS的特性进行多队列收数,如图3所示,物理网卡硬件都带有多个队列,队列个数取决于网卡本身。其中每个队列由独立的一个线程负责接收数据包、组合大包等操作,由于各个线程操作的独立性,从而形成线性扩展能力,以应对不同网络带宽的应用。
另一方面,各个队列收到的数据包可以并行地发生数据拷贝操作,将其拷贝到由应用分配的缓冲区中,这样就提高了应用计算模块所需数据准备的效率。
2.4.3 多核亲核性处理
为了提高应用计算的并行度及保证线程处理的独立性,需要对网络流量进行分割,如图3所示,将ARP/IGMP流量定位到队列0中,将业务流量按大报文进行负载均衡,分别投递到队列1到队列N(N由网卡硬件决定)中。这样就充分利用了CPU及网卡队列的并发能力。