在一个复杂的Agent应用中,如何做好上下文管理极其重要。
当Agent执行长时间的任务时,需要追踪的信息可能会呈指数级增长。对话历史、工具输出、外部文档资料、以及中间的推理过程,全部都会塞进有限的上下文窗口中,就算上下文再大,也会被塞满,而如果充斥大量无关的信息还会分散模型注意力,导致输出效果不佳。
我在前文《Claude Agent SDK实战:打造开源版DeepWiki》聊到过Claude Agent SDK的使用,它的设计核心其实是将文件系统当做外部记忆,内置的一套工具集,支持了通过读写文件来实现持久化,再结合一套自动压缩上下文的机制。
但本质上,它还是将上下文当做一个可变的字符串缓冲区,不断地往里append用户的输入和模型的输出,到了接近200k上限就开始自动压缩。这种上下文管理的方式依然会存在上下文快速增长后的成本和响应耗时上升、可能引入的大量无关信息导致模型性能衰减的问题。
而Google的Agent Development Kit(ADK)则换了个思路,它把编译器的概念引入到了上下文管理中。和模型的所有历史对话、文件系统上的各种资料都被它称为状态数据,真正每次发给大模型的上下文是从这些复杂的状态数据中经过动态提取、过滤、转换、组装出来的和这次的问题强相关的临时结果,这个流程在ADK中被称之为编译管道。
这种方式既保障了上下文不会快速膨胀,又保障了编译出的上下文都是和这次问题最强相关的,不会有大量无关的信息去分散模型的注意力。
举个形象一点的例子,就像数据库中的视图和表的关系。表是真正的数据,而视图(发送给模型的上下文)是根据查询条件生成的临时结果。
今天这篇文章,就来聊聊其中的技术细节。
ADK 的核心设计理念:上下文即编译视图
用一张图来描述ADK的这个设计理念:
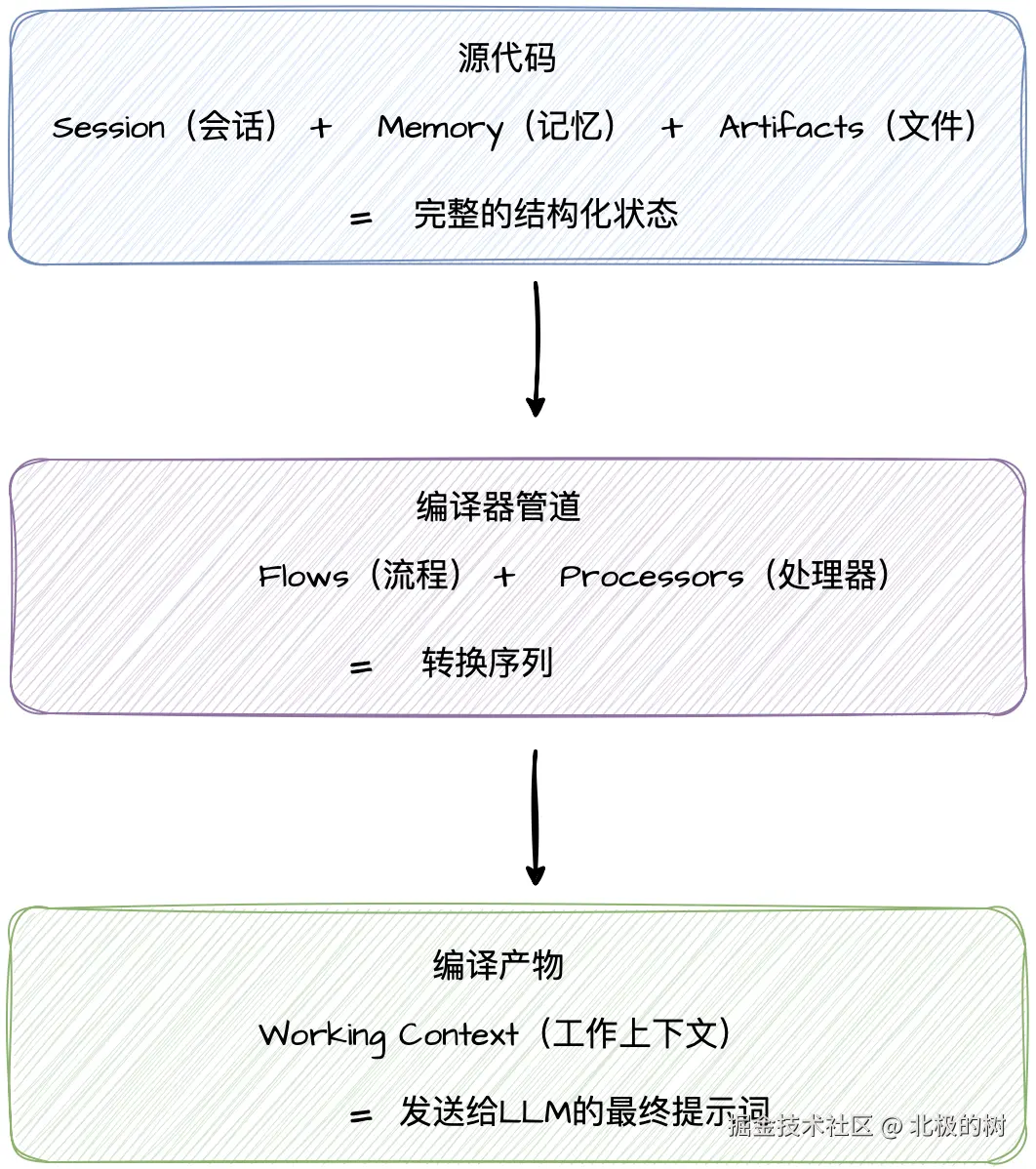
ADK 基于这个理念,做了几个关键的架构决策。
首先是存储与呈现的分离。Session里存的是完整的、不可变的事件日志。而Working Context是为当前这次LLM调用量身定制的编译产物。两者独立管理,互不干扰。我们可以更换底层的模型而不用重写对话历史,也可以对同一份Session生成完全不同的视图给到不同的Agent。
然后是显式的转换过程。上下文不再是随便拼接出来的字符串,而是通过一系列命名的、有序的处理器逐步构建的。每个处理器做了什么、按什么顺序执行,都有明确的定义。出了问题,我们可以像调试编译器一样,精确定位是哪个处理环节的问题。
最后是默认的作用域隔离。每个模型调用和子Agent仅获取所需的最小上下文。 ADK的设计并不是给你所有信息,你自己挑,而是只给你需要的,其它的你压根看不到。这对多Agent协作场景尤其重要,后面会详细讲。
分层存储架构:四层分工明确
ADK把上下文组织成四个明确的层级,每层有特定的职责。
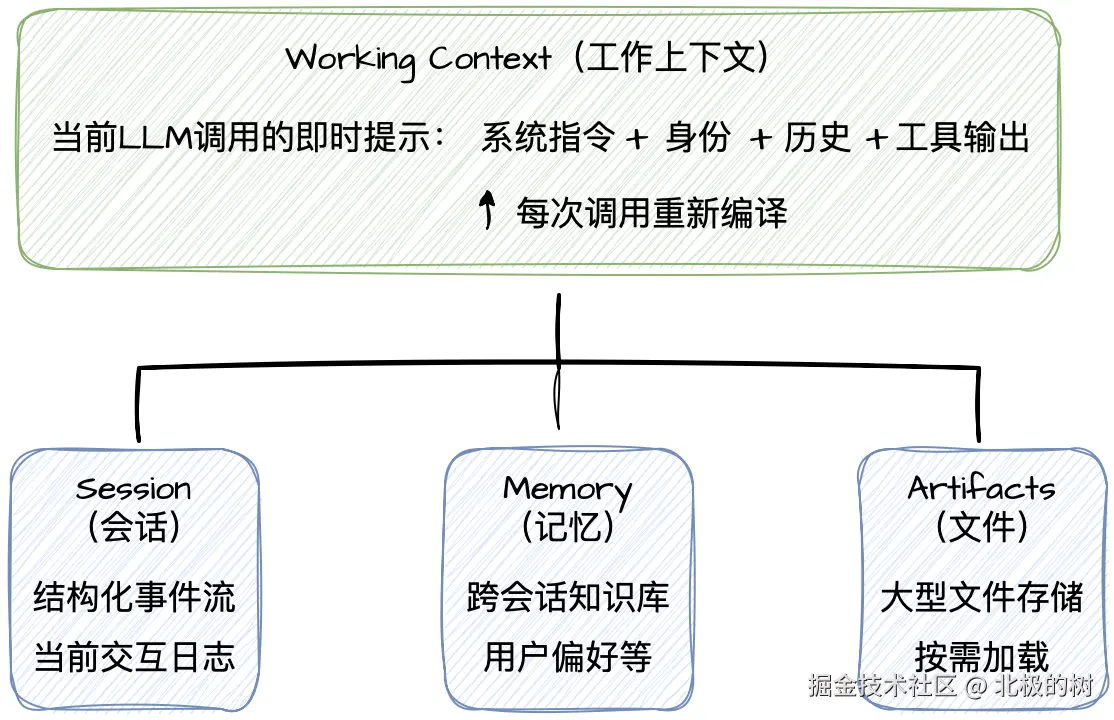
Session:不可变的事件日志
Session是和AI交互的完整状态记录。ADK中将其组织成一系列强类型的Event对象.
python
class Session(BaseModel):
id: str # 会话唯一标识符
app_name: str # 应用名称
user_id: str # 用户ID
state: dict[str, Any] # 会话状态(键值对)
events: list[Event] # 事件列表(核心)
last_update_time: float # 最后更新时间每个Event都有精确的类型,比如UserMessageEvent、ModelResponseEvent、ToolCallEvent。这些强类型设计让下游的编译处理器可以基于类型进行精确过滤。
ADK还对Session数据做了持久化存储,直接存储在关系型数据库中(支持sqilite、PostgreSQL等),支持了事务,即使系统崩溃也能无损恢复。
Memory:跨会话的长期知识
Session处理的是刚刚发生了什么,而Memory处理的是我们知道什么(用户的偏好)。ADK把Memory设计为独立的服务,使用Vertex AI 的向量数据库来存储。
python
class BaseMemoryService(ABC):
@abstractmethod
async def add_session_to_memory(self, session: Session):
"""将会话添加到记忆服务"""
@abstractmethod
async def search_memory(
self, *, app_name: str, user_id: str, query: str
) -> SearchMemoryResponse:
"""语义搜索相关记忆"""关键的设计在于,Memory不会自动进入上下文窗口。ADK遵循了默认最小权限原则,Agent必须通过工具调用显式查询Memory。这就有效防止了长期记忆对短期推理的干扰,同时节省了Token。
Artifacts:大文件的按需加载
Artifacts处理大型数据集,比如文件、日志、图片等。ADK并不会将大型文件全部加载到上下文中,而是采用的句柄模式,上下文中只保留这些文件的句柄引用。
Agent需要时,通过LoadArtifactsTool临时加载。加载的内容只存在于当次的请求中,用完即弃,不会持久化到Session。这就避免了常见的坑:一旦加载完某个大文件,后续每次请求都得带着它,Token就越滚越多。ADK的设计是按需借用,用完就还,不会污染后续请求的上下文。
Working Context:编译后的产物
Working Context是每次LLM调用前动态生成的、仅存在于内存中的临时对象。它是Session、Memory、Artifacts经过编译器管道加工后的结果。
同一个Session可以生成完全不同的Working Context。比如,一个负责CodeReview的子Agent和一个负责客户服务的子Agent,可能基于同一个Session历史,但前者看到的是代码Diff和报错日志,后者看到的是摘要性的任务描述。
前面说了那么多存储层,接下来看看ADK是怎么把Session、Memory、Artifacts这些源数据加工成Working Context的。
上下文处理流水线:Processor链的设计
ADK把上下文的构建过程抽象为Flow,我们可以把它理解为一个编译器。Flow由一系列有效的Processor组成,每个Processor负责一个特定的转换步骤,最终把原始的状态数据编译成发送给LLM的Working Context。
一个典型的请求处理器长这样:
bash
1. basic.request_processor # 基础设置
2. auth_preprocessor.request_processor # 认证处理
3. instructions.request_processor # 添加系统指令
4. identity.request_processor # 智能体身份
5. contents.request_processor # 会话历史转换 ★
6. planning.request_processor # 规划处理
7. code_execution.request_processor # 代码执行
8. output_schema_processor.request_processor # 输出格式每个处理器按顺序执行,构建在前一步的输出之上。其中最核心的是Contents Processor,它负责将Session的Event流转换为LLM可理解的Contents。
Session Events的过滤逻辑
Session里存的是完整的事件日志,但并非所有事件都应该进入Working Context。有些事件是内部流程控制用的,比如认证握手、工具确认请求,暴露给LLM只会分散模型的注意力。有些事件内容为空,只是修改了session state。还有些事件属于其它分支,在并行执行场景下也不应该被当前Agent看到。
Contents Processor的工作就是把这些无关的内容过滤掉。它先处理用户撤销操作产生的Rewind事件,把被撤销的历史移除。然后应用基本过滤规则,剔除空内容、内部认证、确认请求等不该暴露的事件。接着处理分支隔离,确保并行的子Agent之间互不相见。如果会话太长触发了压缩,还要用摘要替换被压缩的历史事件。
过滤完成后,还有一个容易被忽视但是很重要的步骤:角色转换。
为什么需要角色转换?
在多Agent系统中,当控制权在Agent之间转移时,上下文可能会出现问题。
假设有这样一个场景:
markdown
时间线:
1. 用户: "我要订机票去北京"
2. Root Agent: 分析后转移给 Booking Agent
3. Booking Agent: "好的,请问出发日期?"
4. 用户: "下周一"
5. Booking Agent: "已为您查询到3个航班..."
6. Booking Agent 任务完成,控制权返回 Root Agent
7. Root Agent 继续运行...问题来了。当Root Agent恢复执行时,Session中包含了Booking Agent产生的事件。这些事件的role都是model。如果不转换,Root Agent看到role=model的消息,会认为是自己之前说的,导致身份混淆。
ADK的的解决方案是把其它Agent的消息转换为用户视角:
ini
def _present_other_agent_message(event: Event) -> Optional[Event]:
content = types.Content()
content.role = 'user' # 关键:改为 user 角色
content.parts = [types.Part(text='For context:')]
for part in event.content.parts:
if part.text:
# 添加作者归属前缀
content.parts.append(
types.Part(text=f'[{event.author}] said: {part.text}')
)转换后,Root Agent看到的就变成了:
ini
role=user: "我要订机票去北京"
role=model: 分析后转移给 booking_agent
role=user: "For context: [booking_agent] said: 好的,请问出发日期?"
role=user: "下周一"
role=user: "For context: [booking_agent] said: 已为您查询到3个航班..."这样,Root Agent就能区分哪些是自己说的,哪些是子Agent说的,不会混淆响应输出,导致影响模型效果。
Memory的注入逻辑
前面讲的都是Session Events的处理,但Working Context还需要注入Memory和Artifacts。
ADK提供了两种Memory注入模式。一种是主动召回,通过PreloadMemoryTool实现:
python
class PreloadMemoryTool(BaseTool):
"""每次LLM请求自动执行,不由模型调用"""
async def process_llm_request(self, tool_context, llm_request):
# 用用户最新输入作为查询
user_query = tool_context.user_content.parts[0].text
# 语义搜索记忆库
response = await tool_context.search_memory(user_query)
if response.memories:
# 注入到系统指令
llm_request.append_instructions([f"""
The following content is from your previous conversations with the user.
<PAST_CONVERSATIONS>
{format_memories(response.memories)}
</PAST_CONVERSATIONS>
"""])每次LLM请求时,系统自动在Memory中进行语义搜索,把相关的历史记忆注入到系统指令中。这种模式适合用户偏好、常见问题这类需要每次都参考的背景信息。
另一种是被动召回,通过LoadMemoryTool实现。系统只是告诉LLM它有记忆可以查询,具体要不要查、查什么,由LLM自己决定。这种模式更省Token,适合特定知识检索的场景。
Artifacts的按需加载
Artifacts的加载逻辑也类似。系统先告诉LLM有哪些文件可用,LLM决定要不要加载。如果LLM调用了load_artifacts,处理器就把文件内容临时注入到当次请求的contents中。
前面简单提过,这里有个关键设计:加载的文件内容不会持久化到Session。用完就丢,下次请求如果还需要,LLM得再调用一次load_artifacts。这样就避免了大文件一旦加载就永远占着上下文的问题。
其它上下文优化策略
除了上下文编译管线的独特设计之外,ADK还包含了其它一些常用的上下文优化策略。
比如会话压缩,有不同的策略来实现会话压缩,前文《产品级AI应用的核心:上下文工程》有过详细讨论,ADK采用的是异步的滑动窗口压缩策略,和普通滑动窗口的区别是不会阻塞主对话流。下次构建Working Context时,处理器自动读取压缩摘要替代原始日志。
还有就是前缀缓存,相关的技术细节在前文《大模型上下文工程之Prefix Caching技术详解》也有过详细的讲解,感兴趣的朋友可以去原文阅读,这里就不过多阐述。
最后还有一个特别的设计,ADK提供了include_contents参数让开发者精确控制历史传递,默认包含完整的对话历史,如果填none则仅包含当前轮次。
这在调用子Agent时特别有用,有时候我们需要启动一个干净的子Agent,避免历史对话污染其上下文,就可以使用这个参数来控制。
写在最后
在现有LLM的能力限制下,输入质量决定了输出质量。模型再强,喂进去的上下文不做规范,输出也不会好到哪儿去。上下文工程正是其中的关键。
各家大模型厂商除了在拼命卷模型能力,也在上下文工程层面不断推出新的设计。Anthropic的Claude Agent SDK走的是"环境即上下文"的路线,让Agent像人一样用文件系统扩展记忆。Google的ADK走的是"编译视图"的路线,用软件工程的严谨性来管理上下文。
ADK通过存储与呈现分离、显式处理器管道、默认作用域隔离,把上下文管理变成了一个可观测、可调试、可审查的工程问题。Session里存的是完整的事件日志,Working Context是为当前调用量身定制的编译产物。出了问题,我们可以像调试编译器一样,定位到具体是哪个处理器、哪个过滤条件出的问题。
这套设计确实比简单的字符串拼接复杂得多,当然学习曲线也更陡峭。但对于企业级的多Agent应用,我认为这种复杂性是值得的。当我们需要审查每一步状态、当需要多个Agent协作、并且对成本和可靠性有要求,显式的上下文管理就成了必要的选择。