不同的医学影像模式能够以不同的空间分辨率捕捉诊断信息,从粗略的全局模式到细粒度的局部结构。然而,医学领域大多数现有视觉语言框架采用统一的局部特征提取策略,忽视了特定模态的需求。**本研究介绍了MedMoE,一种模块化且可扩展的视觉语言处理框架,能够根据诊断语境动态调整视觉表征。**MedMoE包含基于报告类型的专家混合(MoE)模块,将多尺度图像特征路由经过专门专家分支,这些专家专门负责捕捉特定模态的视觉语义。这些专家基于基于Swin Transformer骨干的特征金字塔工作,实现对临床相关区域的空间适应性关注。该框架生成与文本描述对齐的局部视觉表示,无需推理时依赖特定模态的监督。多项医学基准的实证结果表明,MedMoE提升了不同影像模式的比对和检索性能,凸显了临床视觉语言系统中模式专门视觉表征的价值。
提出了MedMoE ,一种模块化视觉语言框架,将专家混合(MoE)引入本地视觉处理流程,实现基于诊断语境的条件专业化。基于MoE的架构在大规模语言模型中日益受到重视[3](https://arxiv.org/html/2506.08356v1#bib.bib3 "3")以及多模态系统[11](https://arxiv.org/html/2506.08356v1#bib.bib11 "11"),[24](https://arxiv.org/html/2506.08356v1#bib.bib24 "24"),他们通过动态路由专业专家模块来提升效率和泛化性。MedMoE将从图像中提取的局部视觉特征通过一组感知模态的专家分支进行路由。每位专家都经过培训,专注于特定诊断语境,使模型能够有选择地强调与相关报告语义细度相符的空间特征。这一动态路由机制使MedMoE能够根据特定治疗方式的需求调整视觉基础,在多个医学基准测试中优于现有的多尺度对比学习方法。
(1)MedMoE通过根据报告内容将多尺度视觉特征路由专家分支,实现上下文感知专精,实现针对报告语义和成像类型的自适应对齐。
(2)MedMoE通过专家路径实现动态特征专精,其中路由由模态特定的报告上下文决定。
(3)MedMoE,这是首个将报告条件MoE路由集成到视觉特征提取器本身的医疗VLM。该设计支持了针对模式和任务的专家选择,实现自适应局部接地,解决了现有流水线中静态、一刀切处理的瓶颈。
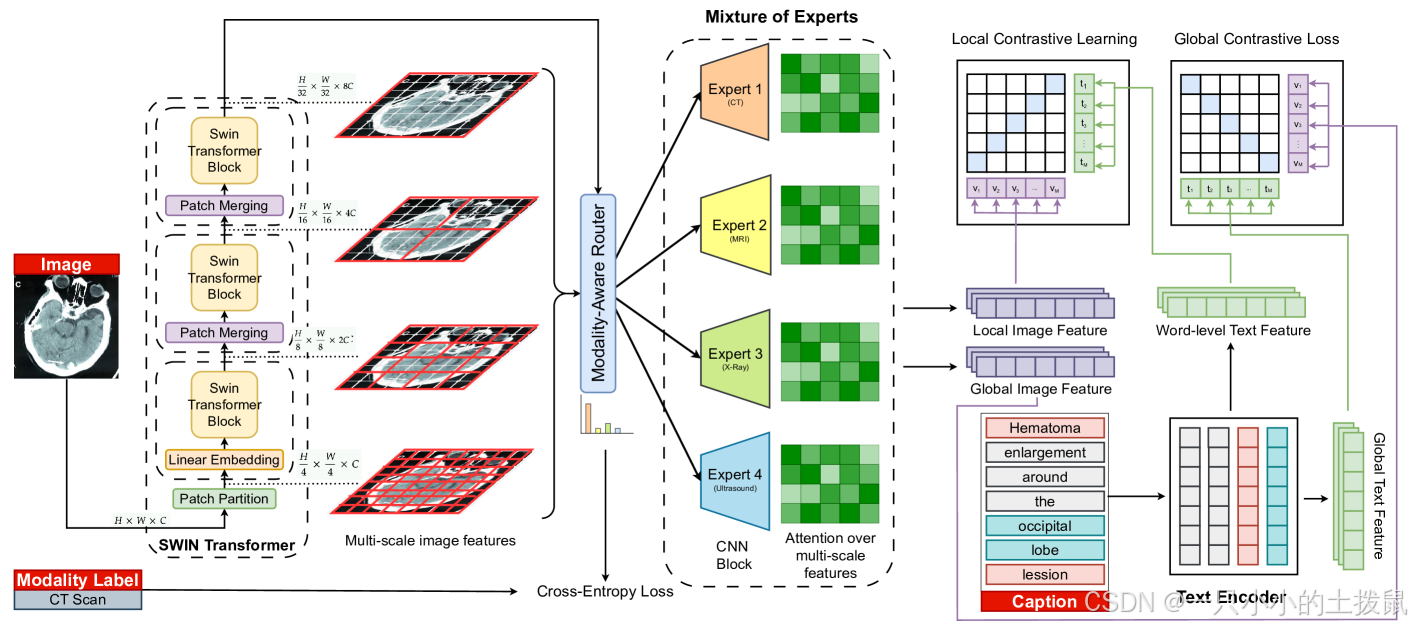
图2:MedMoE的整体架构。 Swin transform提取多尺度特征,模态感知路由器根据全局图像嵌入选择专业专家。专家通过局部对比损耗输出与单词级文本对齐的局部嵌入。全局对比损耗和辅助损耗分别强制图像-文本对齐并监督专家选择。
诊断感知型专家混合(MoE)框架,用于医学视觉语言建模中上下文敏感的局部特征提取。MedMoE 扩展了 GLoRIA 建立的全球-局部对比范式[6](https://arxiv.org/html/2506.08356v1#bib.bib6 "6")同时引入了一种动态的报告条件机制,用于多尺度局部视觉表示。具体来说,MedMoE用一个MoE模块替代静态特征提取器,该模块将多尺度视觉特征通过模态专业的专家分支路由。路由基于诊断报告,实现自适应专业化。