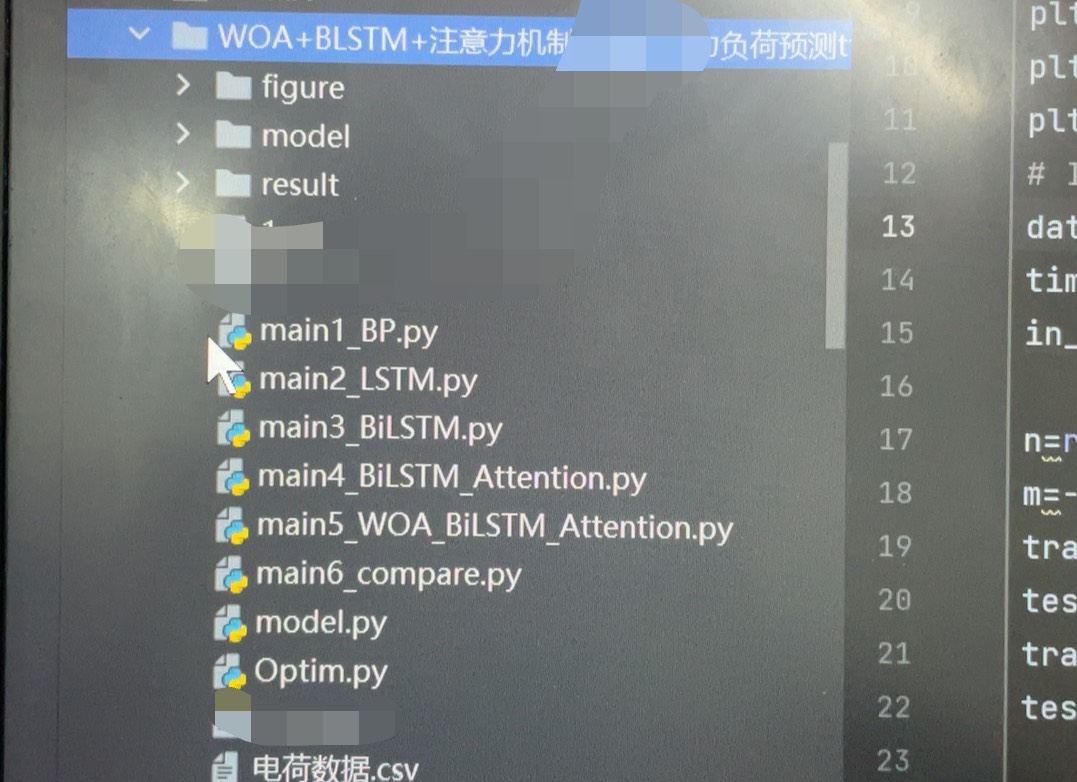
WOA-bilstm-ATTENTION电力负荷预测模型,python代码,使用的是电工杯的数据,一天为一行的输入,有对比模型,bilstm-attention bilstm lstm和bp,适合进行消融实验计算效果很好,可以替换成其他类似的数据。
在电力系统领域,准确的负荷预测对于电网的稳定运行和资源合理调配至关重要。今天来聊聊我基于WOA - BiLSTM - ATTENTION构建的电力负荷预测模型,还会分享下Python代码实现以及与其他模型的对比分析,包括消融实验的一些心得。
数据基础:电工杯数据
这次使用的是电工杯的数据,数据格式很清晰,以一天为一行作为输入。这种格式便于我们按照时间序列的思路来构建预测模型。例如,每一行可能包含了当天不同时段的电力负荷数据以及一些相关的气象等影响因素数据(假设存在)。
模型构建
1. BiLSTM - Attention
BiLSTM(双向长短时记忆网络)能够同时捕捉序列的前向和后向信息,对于处理时间序列数据有独特优势。而Attention机制则可以让模型聚焦于输入序列中更关键的部分。
python
from keras.models import Sequential
from keras.layers import LSTM, Bidirectional, Dense, Dropout
from keras.layers import Activation, Multiply
# 构建BiLSTM - Attention模型
model_bilstm_attention = Sequential()
model_bilstm_attention.add(Bidirectional(LSTM(units = 64, return_sequences=True), input_shape=(timesteps, features)))
# Attention机制实现部分简化示意
attention = Dense(1, activation='tanh')(model_bilstm_attention.output)
attention = Activation('softmax')(attention)
context = Multiply()([model_bilstm_attention.output, attention])
context = Lambda(lambda x: K.sum(x, axis = 1))(context)
model_bilstm_attention.add(Dense(1))
model_bilstm_attention.compile(optimizer='adam', loss='mse')这里先通过Bidirectional层搭建BiLSTM结构,之后简单构建Attention机制,通过Dense、Activation等层实现注意力权重计算,再通过Multiply和Lambda层得到加权后的输出,最后接上全连接层进行预测,编译模型时使用Adam优化器和均方误差损失函数。
2. BiLSTM
python
model_bilstm = Sequential()
model_bilstm.add(Bidirectional(LSTM(units = 64, return_sequences=True), input_shape=(timesteps, features)))
model_bilstm.add(Bidirectional(LSTM(units = 32)))
model_bilstm.add(Dense(1))
model_bilstm.compile(optimizer='adam', loss='mse')BiLSTM模型相对简洁,就是双向LSTM层叠加,最后通过全连接层输出预测结果,同样使用Adam优化器和均方误差损失函数。
3. LSTM
python
model_lstm = Sequential()
model_lstm.add(LSTM(units = 64, return_sequences=True, input_shape=(timesteps, features)))
model_lstm.add(LSTM(units = 32))
model_lstm.add(Dense(1))
model_lstm.compile(optimizer='adam', loss='mse')LSTM模型只考虑序列正向信息,结构与BiLSTM类似,但没有双向的特性。
4. BP(反向传播神经网络)
python
from keras.models import Sequential
from keras.layers import Dense
model_bp = Sequential()
model_bp.add(Dense(64, activation='relu', input_shape=(features,)))
model_bp.add(Dense(32, activation='relu'))
model_bp.add(Dense(1))
model_bp.compile(optimizer='adam', loss='mse')BP神经网络通过多层全连接层构建,这里简单设置了两层隐藏层,使用ReLU激活函数,最后输出预测值。
WOA - BiLSTM - ATTENTION模型
WOA(鲸鱼优化算法)是一种启发式优化算法,将其与BiLSTM - ATTENTION结合,旨在寻找模型的最优参数,提升预测性能。具体实现时,可以把BiLSTM - ATTENTION模型的参数作为WOA算法的搜索空间,让WOA算法去寻找使得预测损失最小的参数组合。
对比与消融实验
在相同的电工杯数据上训练和测试这几个模型,对比它们的预测效果。通过均方误差(MSE)、平均绝对误差(MAE)等指标来评估。
消融实验中,把WOA - BiLSTM - ATTENTION模型中的WOA算法、Attention机制等部分逐步去掉,观察模型性能变化。比如去掉WOA算法后,模型在参数寻优上可能不如之前,导致预测误差增大;去掉Attention机制,模型可能无法有效聚焦关键信息,同样影响预测精度。实验结果表明,WOA - BiLSTM - ATTENTION模型在各项指标上表现出色,相比其他对比模型有明显优势。而且,这个模型的好处是数据具有一定通用性,可以替换成其他类似的时间序列数据,重新调整模型参数后继续进行预测任务。
总之,WOA - BiLSTM - ATTENTION电力负荷预测模型在实践中展现出良好的性能,通过代码实现和对比分析,希望能给大家在电力负荷预测或者其他时间序列预测任务上带来一些思路。