数字经济时代,数据已成为驱动企业增长的核心生产要素,但大数据任务发布的"混乱困境 ",却成为多数企业数字化转型的共性卡点:发布无审核、操作纯手动、需求与执行割裂、数据生产消费链路断层 。作为行业领先的社区服务运营商,碧桂园生活服务率先破局,通过云效与DataWorks的深度协同 ,搭配Python自主开发的适配层,构建起大数据任务工程标准化发布体系,实现从数据生产到消费的全链路闭环。这一实践不仅成为阿里云大数据体系中"云效+DataWorks"模式的首创案例,更树立了DataOps落地的行业标杆。
一、 大数据发布的"七大痛点",制约数据价值释放
在未开展标准化改造前,碧桂园生活服务的大数据发布流程,深陷行业典型的"低效高风险"困境,严重制约数据价值的高效释放:
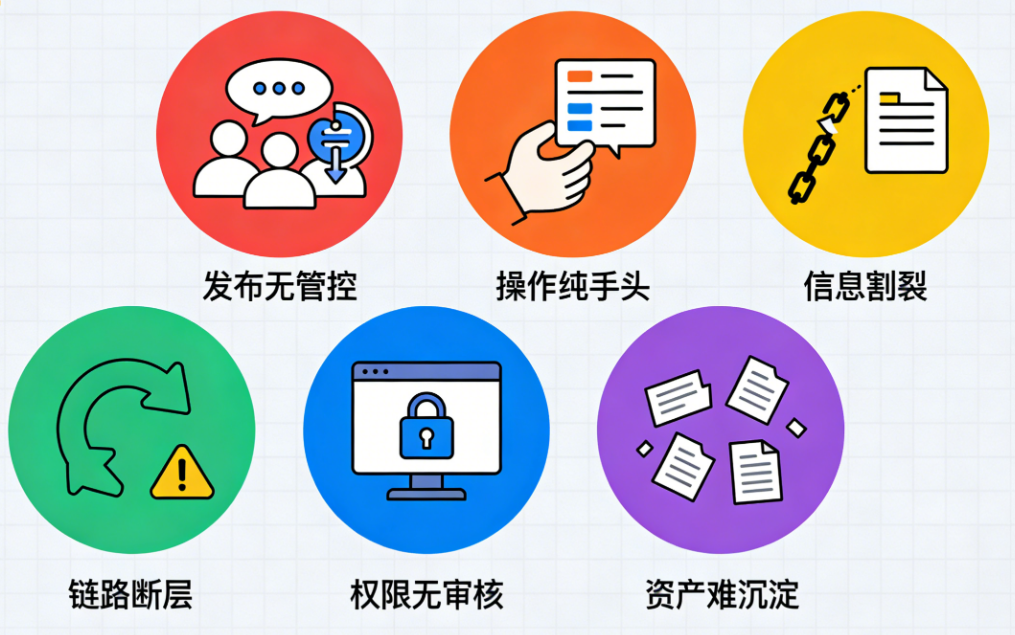
发布无管控:任务发布依赖人工口头协调,无固定审核流程,生产环境变更全凭经验,风险不可控;
操作纯手动:DDL执行、报表资源导入等核心环节全靠人工操作,不仅效率低下,还易因人为疏忽引发数据异常;
信息割裂:需求与发布记录脱节,代码量、发布频次无统一统计口径,交付进度不透明,业务方难以感知;
链路断层:数据生产(任务发布)与消费(报表/API调用)环节孤立,上游任务变更无法及时同步下游,易引发业务误用;
权限无审核:数据服务API的发布与表授权缺乏管控,随意授权易引发数据泄露风险;
资产难沉淀:分散的人工操作导致大数据任务、代码版本、发布记录难以归档,无法形成可管理、可追溯的数据资产;
这些痛点并非碧桂园生活服务个例,IDC相关报告显示,中国企业在数据流程调度、管道治理上的人力成本同比增长27%,且多数业务部门对数据流转异常的感知,往往滞后于实际业务损失。在此背景下,碧桂园生活服务明确:唯有通过"****标准化、自动化"****的体系重构,才能让数据真正成为驱动业务的核心动力。
二、 核心实践:云效+DataWorks,构建全链路工程化闭环
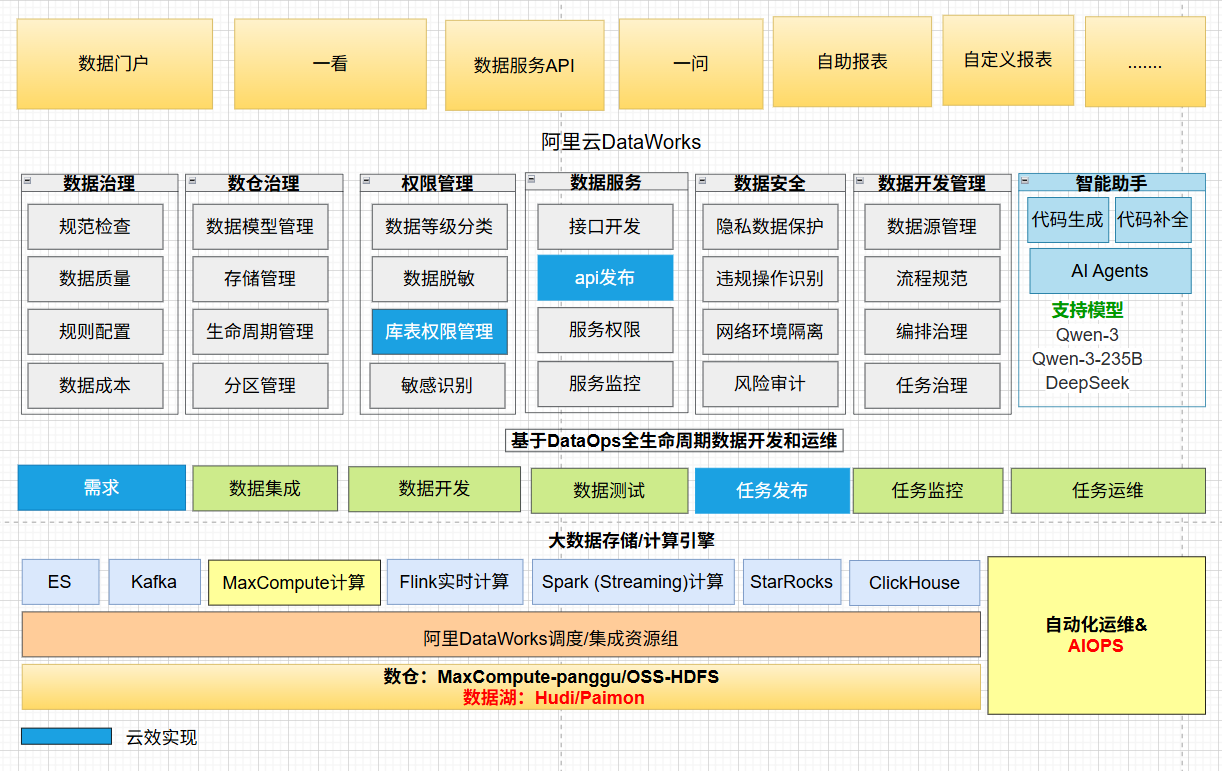
碧桂园生活服务以"标准化、自动化、闭环化"为核心目标,依托阿里云云效(DevOps全链路工具链)与DataWorks(一站式大数据开发治理平台),打通数据生产、消费、管控全流程,最终形成可复制、可推广的DataOps实践范式。
具体实践围绕"工具联动、全场景覆盖、闭环能力升级"三大核心模块展开,贯穿数据从生产到消费的全生命周期,核心流程如下:
|--------------------|
| (一)DataOps全链路闭环流程图 |
流程图主线:需求发起 → 开发测试 → 发布审核 → 生产交付 → 消费使用 → 全链路管控
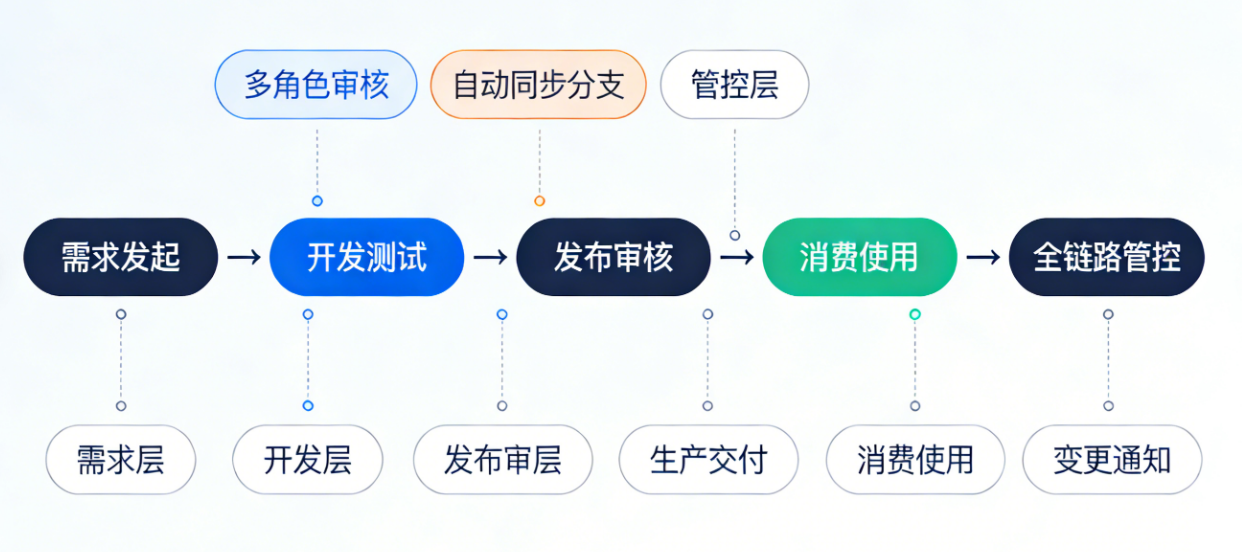
各环节拆解+工具支撑+核心动作:
- 需求发起(需求层):云效需求管理模块承接业务诉求,完成需求创建、审核,生成唯一需求ID(核心动作:需求与后续全流程强绑定,确保可追溯);
- 开发测试(开发层):DataWorks提供可视化开发环境,开发人员完成代码编写后,提交至云效开发分支,依托DataWorks环境隔离能力完成测试验证(核心动作:分支隔离,避免开发干扰生产);
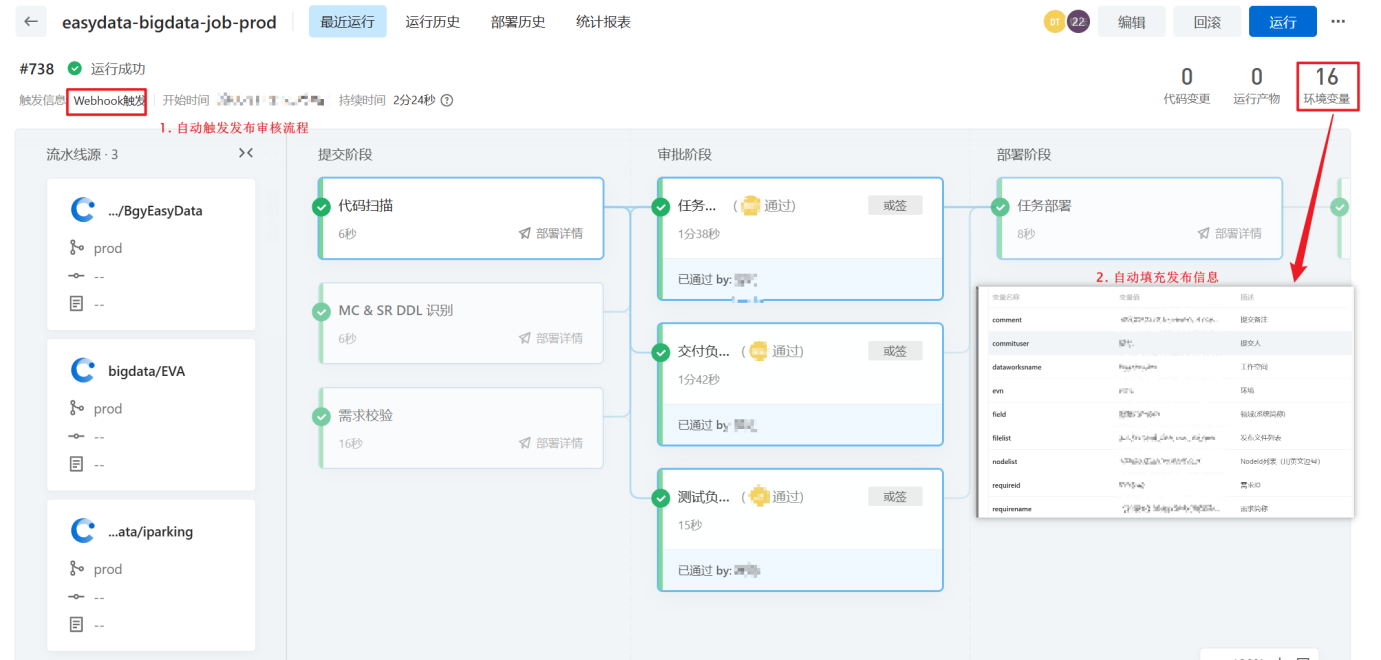
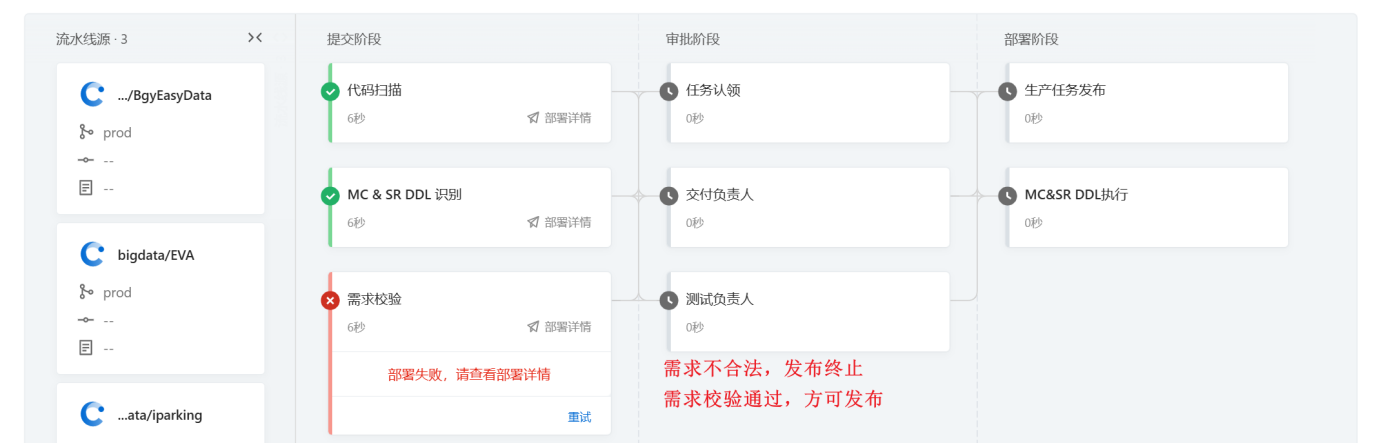
- 发布审核(发布层):触发云效流水线,启动"开发自测→测试验证→交付负责人确认→大数据运维审核"多角色审批流,通过后自动执行DDL语句并落库日志,同时将代码同步至生产分支(核心动作:多角色审核+自动化执行,降低人为风险);
- 生产交付(执行层):DataWorks启动百万级任务调度,云效流水线同步完成永洪云报表自动化导入、数据服务API发布与授权配置(核心动作:生产环境稳定交付,覆盖生产-消费衔接环节);
- 消费使用(消费层):业务部门通过报表/API使用数据服务,上游任务变更时,通过DataWorks依赖分析+云效通知机制自动同步下游(核心动作:变更联动,避免数据误用);
- 全链路管控(管控层):基于云效代码提交记录、发布日志自动统计工作量,需求文档、代码版本、执行日志等全链路信息统一关联,支撑合规审计(核心动作:全流程可视可管,沉淀数据资产)。
|------------|
| (二)工具联动架构图 |
架构核心逻辑:采用"三层联动"设计,上层承接业务需求,中层实现工具协同,下层保障执行落地,通过Python适配层打通各层数据流转壁垒。
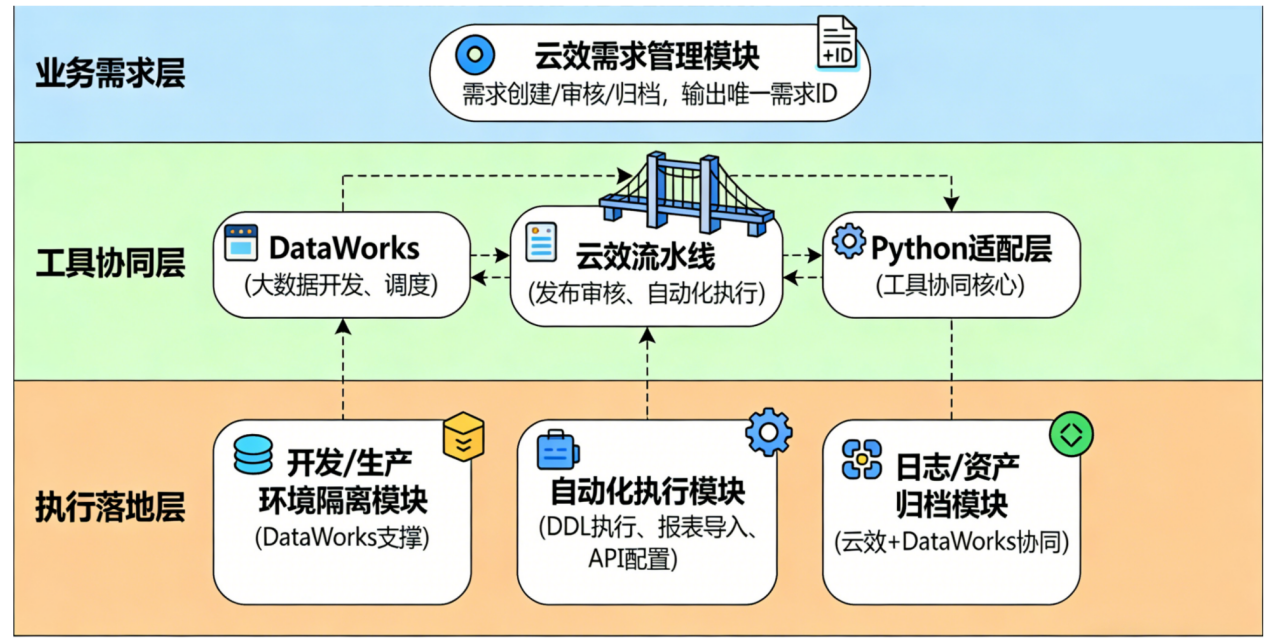
各层级拆解+核心组件:
- 上层:业务需求层(承接诉求):核心组件为云效需求管理模块,负责需求创建、审核、归档,输出唯一需求ID,作为全链路追溯的核心标识;
- 中层:工具协同层(核心桥梁):包含三大核心组件------DataWorks(大数据开发、调度)、云效流水线(发布审核、自动化执行)、Python适配层(打通DataWorks与云效的接口、数据同步),实现"开发-发布-管控"的工具联动;
- 下层:执行落地层(保障稳定):包含开发/生产环境隔离模块(DataWorks支撑)、自动化执行模块(任务发布、DDL执行、报表导入、API配置)、日志/资产归档模块(云效+DataWorks协同),确保操作合规、可追溯。
|---------|
| (二)工具实现 |
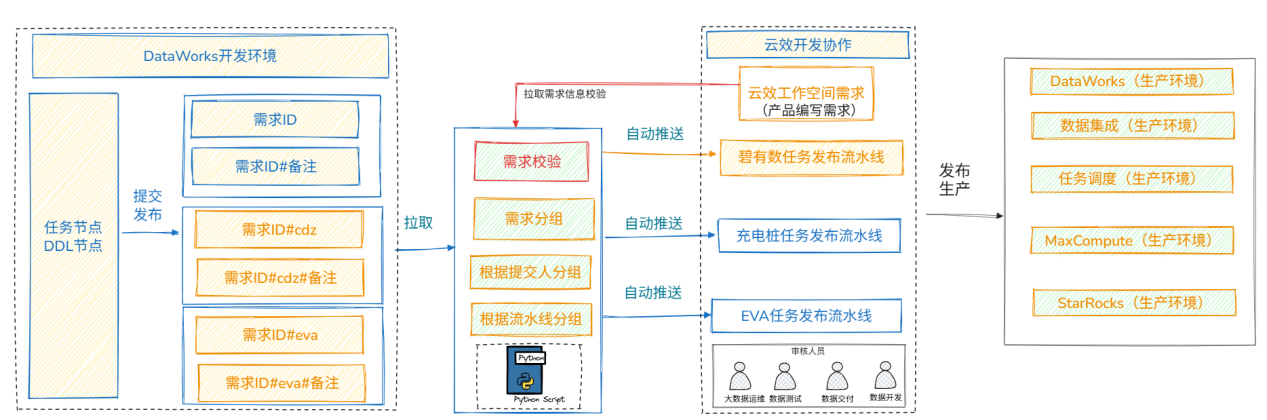
数据流转方向:业务需求层→工具协同层(需求ID同步)→执行落地层(开发、发布、消费)→工具协同层(执行数据回传)→业务需求层/全链路管控层(进度同步、资产归档)。
一键发布自动化 :摒弃传统人工协调模式,升级为云效流水线一键触发发布,内置****"开发自测→测试验证→交付负责人确认→大数据运维审核****"多角色审批流,确保每一次生产变更都合规可控;
三 、 全场景覆盖:从数据生产到消费的全链路标准化
将数据生产端与消费端的全场景纳入云效管控范围,打破"数据生产-业务使用"的割裂状态,实现端到端标准化:
数据生产端:依托DataWorks的可视化开发、任务调度能力,实现数据集成、SQL计算、数据建模等全类型大数据任务的高效开发与稳定调度;
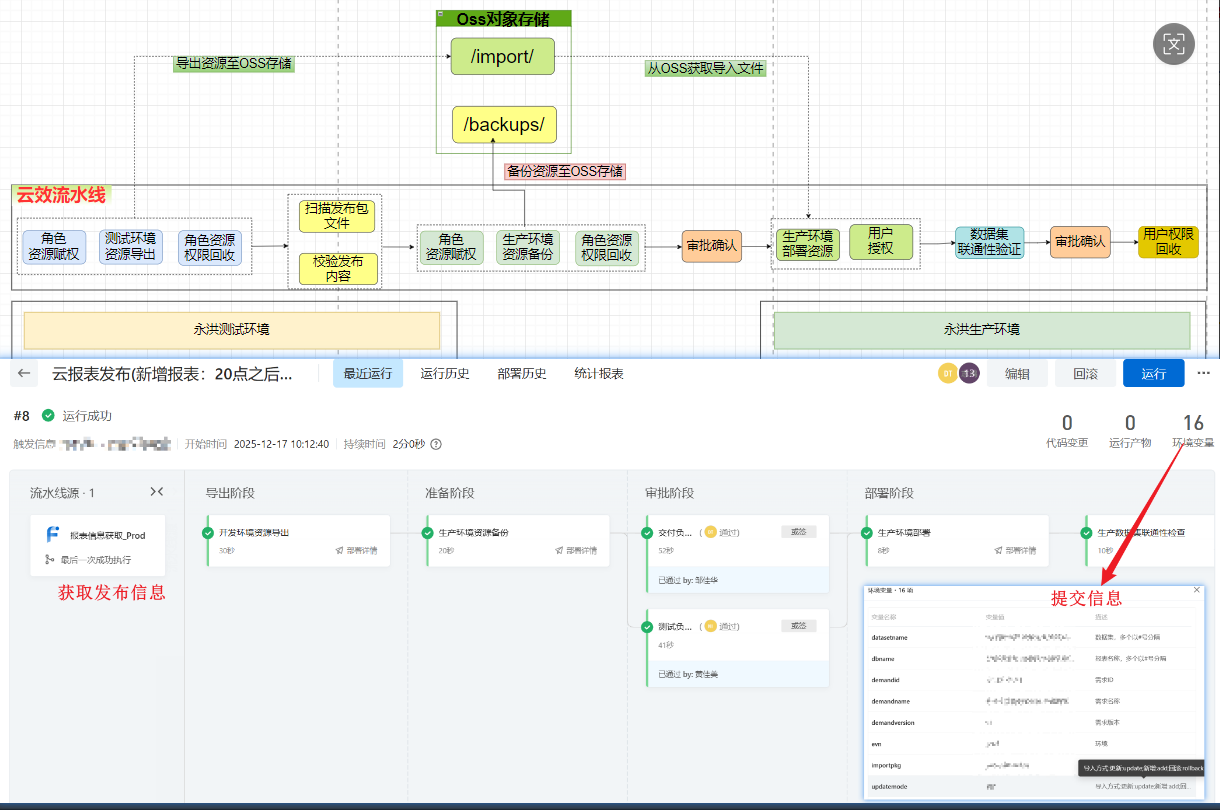
报表发布自动化 :永洪云报表从"人工手动导入资源"升级为云效流水线全自动化处理,完整覆盖"****测试环境资源导出→生产环境备份→资源导入→权限配置"****全流程,避免人工操作遗漏;
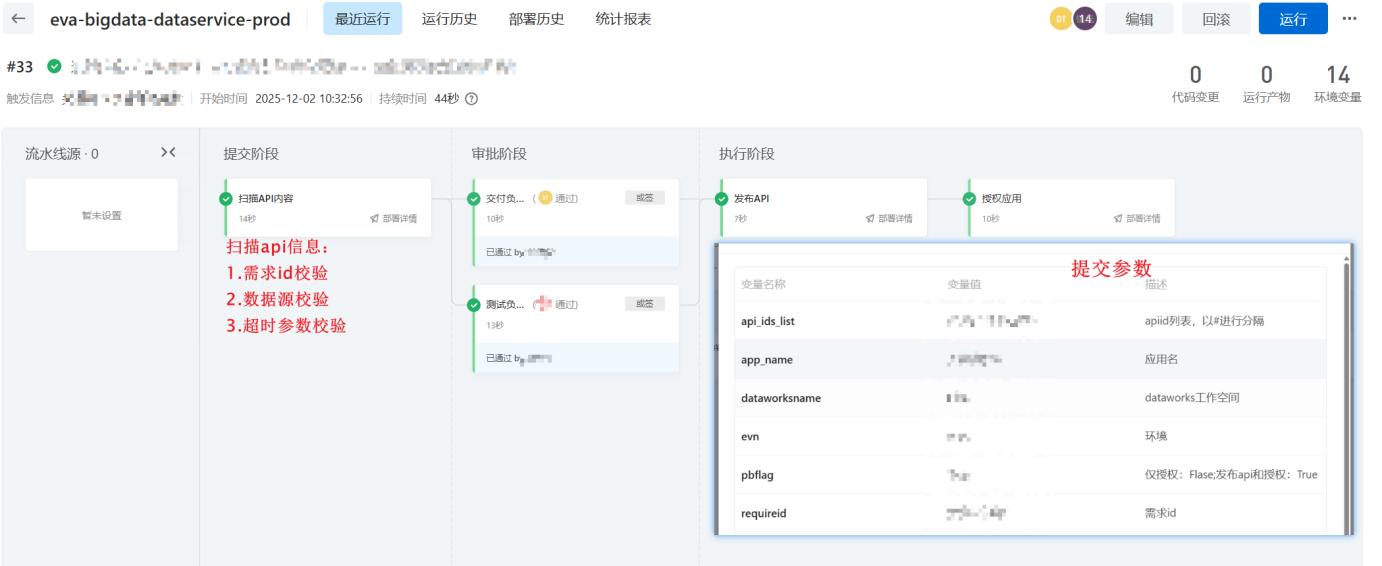
API发布合规化:为数据服务API的发布与授权新增云效审核节点,需经"开发提交→运维审核"双角色确认后,流水线自动完成发布与权限配置,从源头规避无审核授权的安全风险;
四、 闭环能力升级:实现"需求-开发-发布-消费"全链路可视可管
在工具联动的基础上,进一步强化全链路协同与管控能力,让数据流转的每一个环节都透明、可追溯:
需求强关联 :每一次发布都与云效需求ID严格绑定,形成"需求发起→开发编码→测试验证→生产发布→业务消费"的完整链路档案,彻底解决需求与执行割裂的问题;
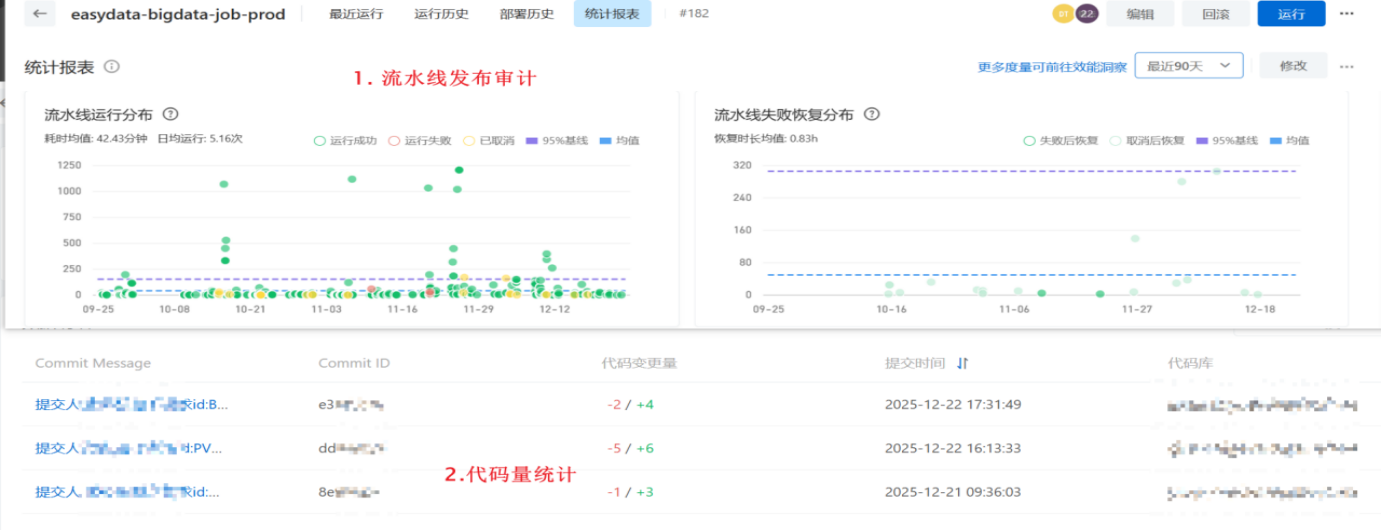
工作量自动统计:依托云效的代码提交记录、流水线发布日志,自动量化开发人员的任务量、发布频次,实现交付效率的可衡量、可优化;
上下游变更联动:借助DataWorks的任务依赖关系分析能力,结合云效的通知机制,上游任务发布或变更时,自动同步至下游消费方(报表/API使用者),提前规避数据误用风险;

全链路可追溯:需求文档、代码版本、发布记录、执行日志、权限配置通过工具联动实现统一关联,完全满足企业合规审计要求;
五、 实践价值:效率、风险、资产的三重飞跃
此次标准化改造,不仅解决了发布混乱的表层问题,更实现了数据工程能力的体系化升级,为企业带来"效率、风险、资产"的三重核心价值:
效率大幅提升:任务发布周期从"天级"压缩至"小时级",DDL执行、报表导入等核心环节的人工操作耗时降低80%,整体开发交付效率提升超50%;
风险显著降低:多节点审核与自动化执行替代人工操作,生产环境变更风险降低90%;数据服务API授权实现"可管可控",完全符合金融级数据安全要求;
资产有效沉淀:需求、代码、发布记录的链路化管理,让原本零散的大数据任务升级为"可管理、可复用、可追溯"的数据资产,为后续数据治理奠定基础;
行业标杆确立:作为阿里云大数据体系中"云效+DataWorks+第三方工具"全链路闭环的首创实践,该模式已成为阿里云面向企业客户的标杆参考方案,具备极强的行业推广价值;
六、实践分享 :DataOps落地的三大核心启示
碧桂园生活服务的DataOps实践,为企业大数据工程化发布提供了清晰的落地路径,也印证了DataOps作为"数据开发与治理融合"新范式的核心价值,其经验对行业有三大关键启示:
痛点导向,工具适配:以解决业务实际痛点为核心目标,选择匹配自身需求的工具组合(如云效+DataWorks),避免盲目堆砌技术,让工具真正服务于流程优化;
轻量联动,快速落地:通过Python等低成本方式开发适配层,打通不同工具间的协同壁垒,无需大规模重构,是中小企业落地DataOps的高效路径;
全链路闭环,而非单点优化 :DataOps的核心价值不在于单一环节的自动化,而在于打通"数据生产→消费→管控"全流程,实现信息、流程、风险的全局管控;
结语 和展望
从"人工野蛮发 布"到"工程化闭环管理 ",碧桂园生活服务的DataOps实践,不仅完成了自身数据工程能力的升级,更向行业证明:企业无需复杂的技术架构,通过"工具协同+流程标准化+轻量适配",就能高效破解大数据发布管理的痛点。
随着数据要素市场的加速发展,DataOps将成为数据驱动型企业的核心基础能力。碧桂园生活服务,为行业提供了可复制、可落地的参考模板。