文章目录
-
[speech 声学信息](#speech 声学信息)
-
- [Evaluation on Speech-to-Text Benchmarks](#Evaluation on Speech-to-Text Benchmarks)
- [Evaluation on Speech-to-Speech Benchmarks](#Evaluation on Speech-to-Speech Benchmarks)
-
2025.11
abstract
- 提出问题:在文本和视觉领域,通过CoT进行更复杂的推理,能显著提升模型性能。然而,现有的音频语言模型在进行推理时,其性能反而会随着推理链条的增长而下降,表现出一种反常的"反向缩放"现象。
- 分析问题:音频模型无法从CoT受益,问题的根源在于模态错配:当模型分析音频时,实际上是在分析音频的文字转录稿或文本描述,而不是音频本身的声学特性(如音调、节奏、旋律等)。例如,它会根据"歌词提到悲伤"来判断音乐的忧郁,而不是分析其"小调式和弦和下行的旋律轮廓"。
- 解决方法:提出了一个名为"模态溯源推理蒸馏"(Modality-Grounded Reasoning Distillation, MGRD)的训练框架,开发了 Step-Audio-R1 模型,性能超越了 Gemini 2.5 Pro,并与顶尖的 Gemini 3 Pro 相当。
method
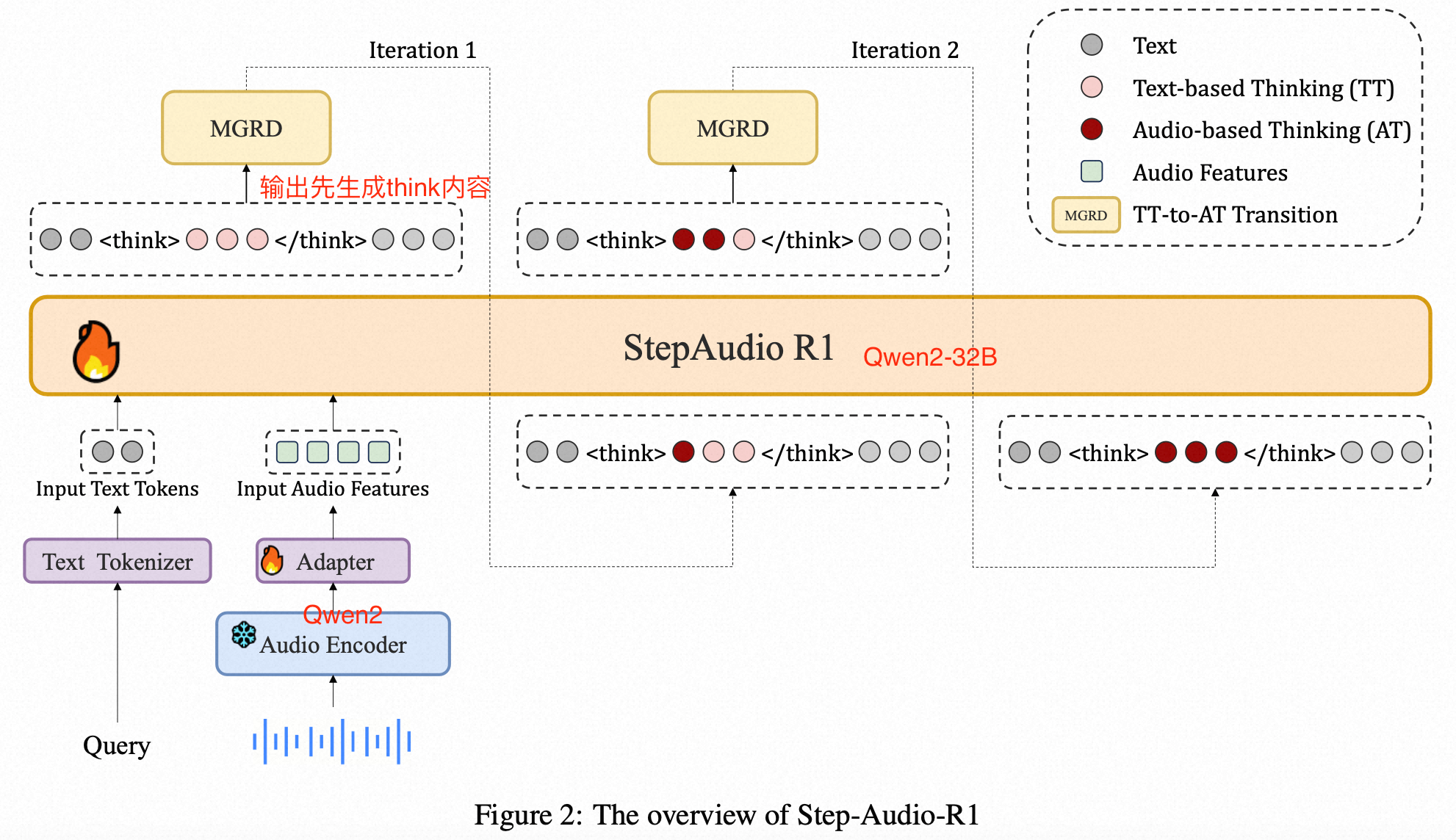
第一阶段训练:基础能力构建
-
冷启动 (Cold Start):CoT数据训练,首先,使用高质量的纯文本数据来教模型如何"思考",同时混合音频数据以确保其保持听觉能力。在此阶段,模型具备了初步的推理能力,但主要还是依赖文本逻辑 。
-
基于验证奖励的强化学习 (Reinforcement Learning with Verified Rewards, RLVR)
- 模型针对特定任务(如数学、代码)生成多个推理路径和答案。如果最终答案是正确的(可以被程序验证),模型就会得到一个正奖励(+1),否则得到零奖励。
-
完成这个阶段后,模型已经是一个具备强大文本推理能力、并且习惯了``格式的"思考者"。但它的思考内容仍然是基于文本的。
第一阶段训练:MGRD训练
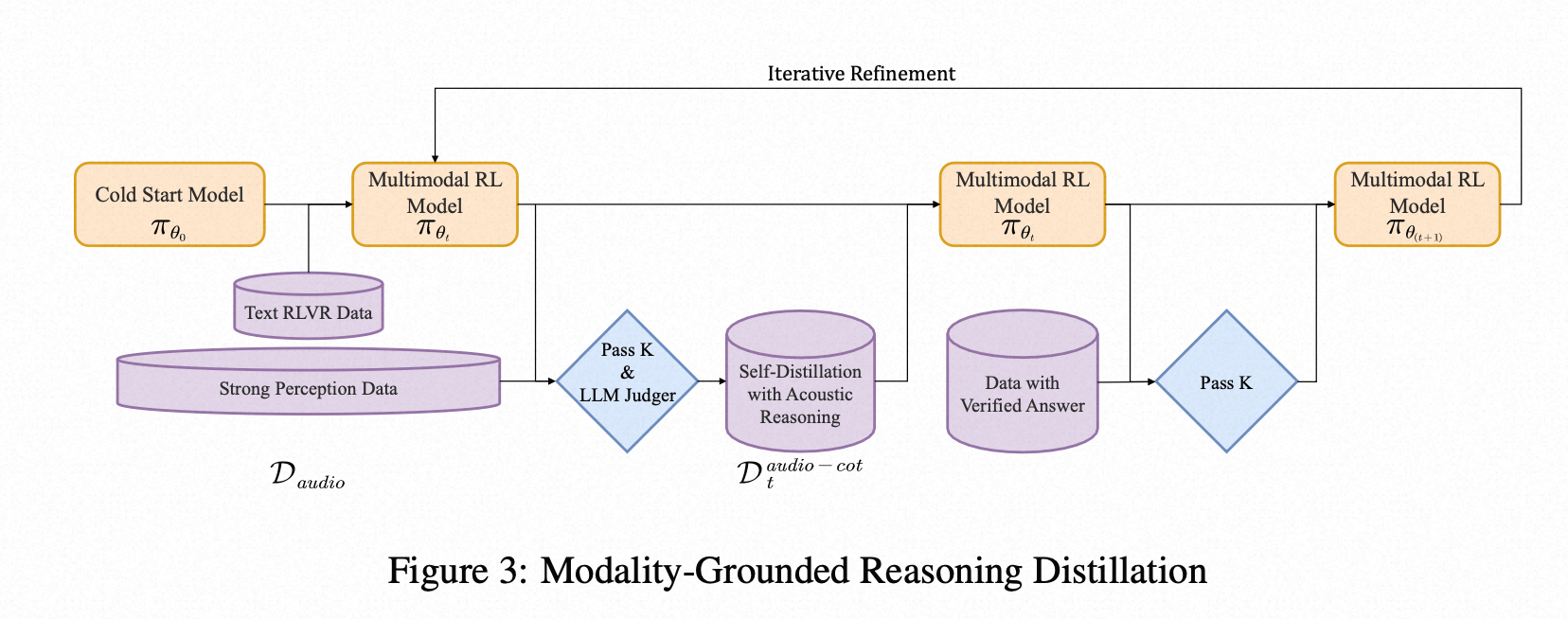
MGRD的实现过程:通过逐步提炼和增强模型的声学推理能力,实现对音频理解能力的迭代循环、螺旋上升。上一轮训练出的模型会被用来生成下一轮的训练数据,通过不断地筛选和提炼,模型的推理能力会发生质变,从分析歌词等文本信息,进化到分析小调和弦、旋律轮廓等真正的声学特征
MGRD的训练过程包括如下:
-
自我蒸馏与声学推理 (Self-Distillation with Acoustic Reasoning)
- 筛选数据:从音频数据集中,精心挑选出那些必须通过分析声学特征才能正确回答的问题(比如辨别情绪、区分说话人、分析音乐风格等)。
- 生成样本:让当前版本的模型(来自上一轮迭代)针对这些问题生成 K 个不同的推理过程和答案。
- 过滤样本:使用一个"法官"(LLM Judge)或预设规则,从这 K 个样本中筛选出最优质的。筛选标准是:
- 声学溯源 (Acoustic Grounding):推理过程是否明确提到了音高、音色、节奏等声学特征,而不是只谈论文本内容?
- 逻辑连贯 (Logical Coherence):推理步骤是否合乎逻辑?
- 答案正确 (Answer Correctness):最终答案是否正确?
- 构建新数据集:将通过筛选的、高质量的"声学推理样本"组成一个新的训练数据集 D_audio-cot。
-
多模态监督式微调 (Multimodal Supervised Refinement):使用上一步生成的新数据集 D_audio-cot,结合原有的文本推理数据,再次对模型进行监督式微调。
通过在新数据上训练,强制模型学习并巩固那些被验证为有效的声学推理模式。
同时保留文本推理数据的训练,是为了确保模型在学习新技能时,不会忘记旧的文本推理能力。
-
多模态强化学习 (Multimodal Reinforcement Learning):在微调后,再次使用强化学习进行优化,但这次的奖励机制是特制的:
对于文本任务:和之前一样,答案正确则奖励为 1,错误为 0。
对于音频任务:这是一个复合奖励:80% 的权重给答案正确性。20% 的权重给格式正确性。
speech 声学信息
对于语音(speech),MGRD 引导模型关注以下几个方面的声学特征:
- 韵律和语调 (Prosody and Intonation):
是什么:说话时音调的高低起伏、节奏和重音。
揭示什么:这直接关系到情感(如高兴、愤怒、悲伤)、意图(是陈述句还是疑问句?)和态度(是真诚还是讽刺?)。
例子:同样一句话"干得真好",用上扬的、兴奋的语调说是赞扬;用平淡的、拖长的语调说则可能是反讽。纯文本无法区分这两种截然不同的含义,但声学特征可以。 - 副语言信息 (Paralinguistic Information):
是什么:话语中非语言的声音,如笑声、叹气、咳嗽、犹豫时的"嗯"、"啊"等。
揭示什么:说话者的情绪状态、健康状况、对话的流畅度。这些信息在转录时通常会被忽略或简化。
例子:在回答一个问题前长时间的"嗯......"可能表示不确定或正在思考,这比直接回答更能反映说话者的真实状态。 - 音色和音质 (Timbre and Voice Quality):
是什么:声音的独特性,比如声音是沙哑的、清晰的、还是颤抖的。
揭示什么:可以用来识别说话人(声纹识别)、判断其年龄、性别,甚至推断其情绪状态(如紧张时声音会变高或颤抖)。
例子:在一段多人对话中,纯文本无法告诉你哪句话是谁说的,但通过分析音色,模型可以区分不同的发言者。 - 节奏和语速 (Rhythm and Pacing):
是什么:说话的速度快慢、停顿的长短。
揭示什么:可以反映说话者的情绪(如紧张时语速加快)、自信程度或话题的重要性(重要内容可能会放慢语速、加重音)。
例子:一段快速且没有停顿的陈述可能表示背诵或紧张,而一段有节奏、有停顿的演讲则显得更有说服力。
data
- Cold-Start(10亿token文本,40亿token audio)
- Audio Data:ASR数据,副语言理解数据,AQTA数据
- Audio CoT Data:AQTA Chain-of-Thought (CoT) data,占所有音频数据的10%。来自于模型已经有一定的音频推理能力之后生成的数据。
- text data:包括纯文本对话和专注于数学、代码的文本思维链数据。10亿token
为了让模型学会推理的结构,所有不自带思维链的样本都被统一添加了空的标签,格式:
- RL Data
- 2,000 high-quality text-only samples (focusing on math and code)
- 3,000 augmented speech-based QA samples.
eval
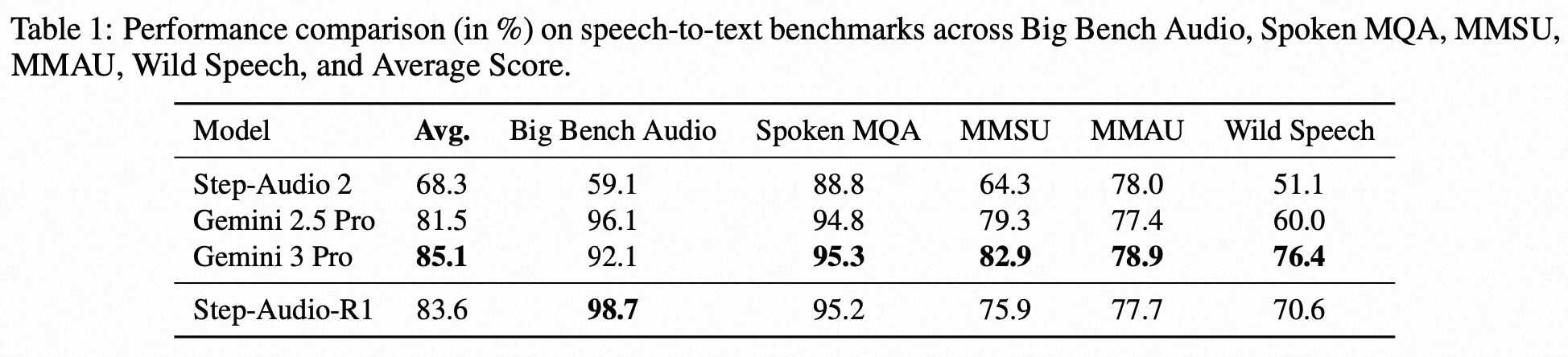
Evaluation on Speech-to-Text Benchmarks
MMSU & MMAU: 这两个是专家级的音频理解与推理基准,题目难度非常大,需要模型具备跨学科知识和深度分析能力。
Big Bench Audio: 专注于需要多步逻辑推理的复杂音频任务。
Spoken MQA: 专门测试基于口头表述的数学问题的推理能力。
Wild Speech: 评估模型在自然、真实的对话场景中的语音理解能力,这种场景通常包含口语、停顿、背景噪音等复杂因素。
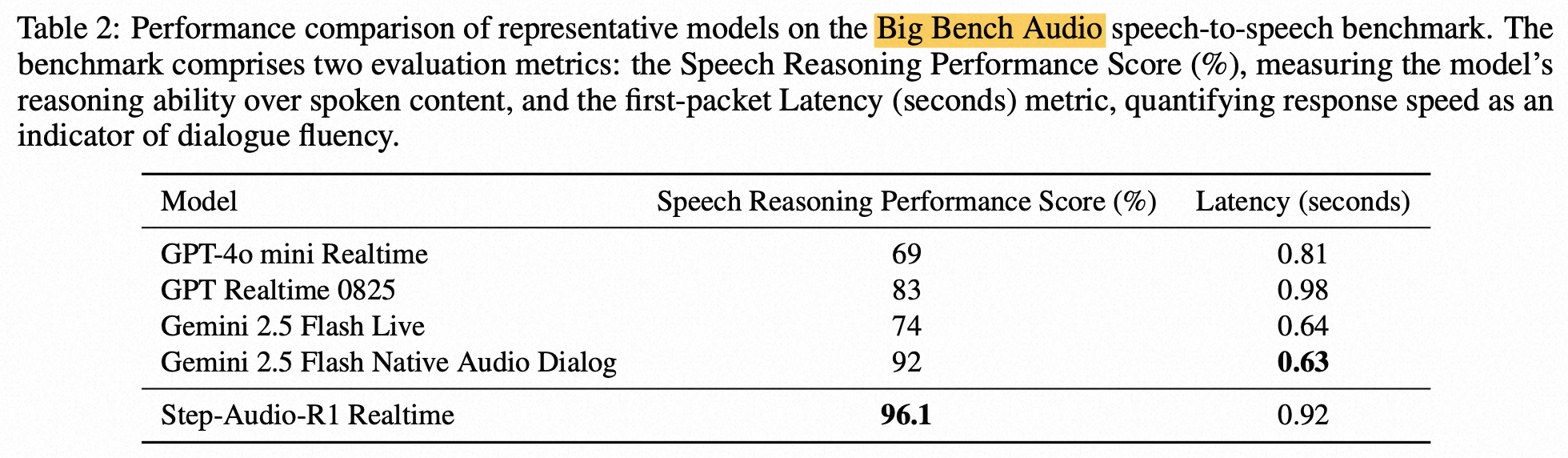
Evaluation on Speech-to-Speech Benchmarks
延展分析
- 在强化学习阶段,我们设计的那个"格式奖励"(即对生成标签的行为给予20%的奖励)是否真的有必要?
Answer:格式奖励是必不可少的。它不仅提升了最终性能,更关键的是它维持了模型进行深度思考的能力,从而验证了本文的核心论点------当推理被正确引导时,更长的思考链条确实对音频理解有益。 - 在强化学习阶段,应该用什么样的数据来训练模型效果最好?是难题、简单题还是海量数据?
Answer:成功的音频推理训练需要像设计课程一样,精心挑选"有挑战性但可解决"的问题,而不是靠"题海战术",也不能设计的太难(比如:没有一次推理成功)。 - 由于训练数据中包含大量纯文本内容,音频模型经常会错误地声称自己"听不到声音"或"是一个文本模型"。如何修正这种"自我认知错误"?
Answer:基础模型:有 6.76% 的认知错误率。经过迭代过滤后:错误率降至 2.63%。最终经过DPO校准后:错误率锐减至 0.02%,几乎完全消除了这个问题。
结论:模型的"自我认知"不是其固有缺陷,而是训练数据分布导致的"习得性偏差"。通过DPO校准,可以高效地解决这类行为偏差,提升用户体验。
DPO训练方法:在自我蒸馏之后,构建8000个"偏好对"。其中,"好的回答"是模型正确承认并使用其音频能力,"坏的回答"是模型声称自己是文本模型。通过DPO,直接训练模型去"偏爱"好的回答。