学习目标:
- 了解DeepSeek API开发平台,学习如何使用API开发应用。
- 搞懂什么是向量数据库,为什么RAG需要它。
- 掌握RAG(检索增强生成)的基本原理和关键技术要点。
- 最后,实现一个基于DeepSeek和RAG搭建的智能问答机器人。
DeepSeek应用开发入门
DeepSeek API官方与第三方平台介绍
deepSeek模型有三种使用方法:官方途径,第三方渠道和本地化部署
deepseek官方网站:https://platform.deepseek.com/sign_in
第三方渠道:阿里,字节,腾讯等
Token是模型用来表示自然语言文本的基本单位,也是API调用的计费单元,可以直观的理解为字或词。
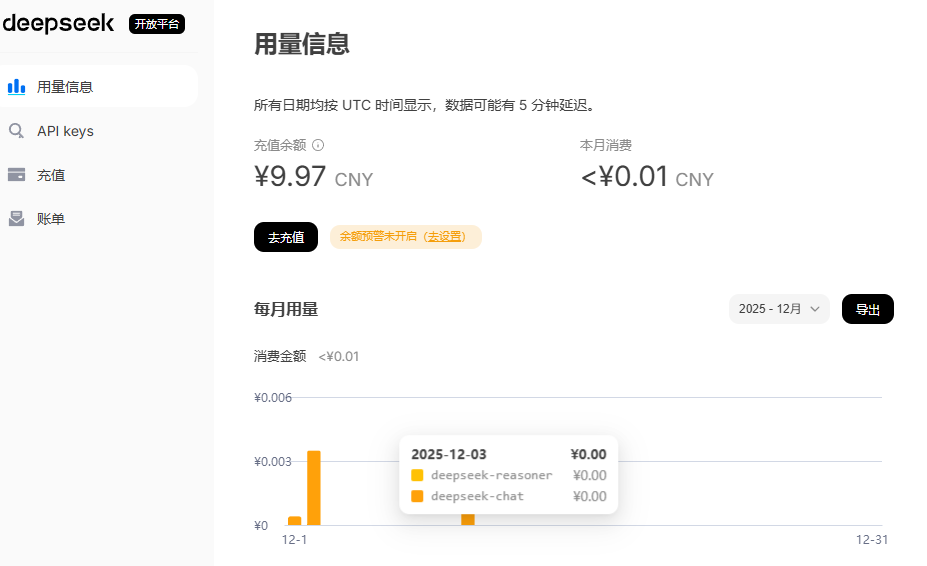
余额查看
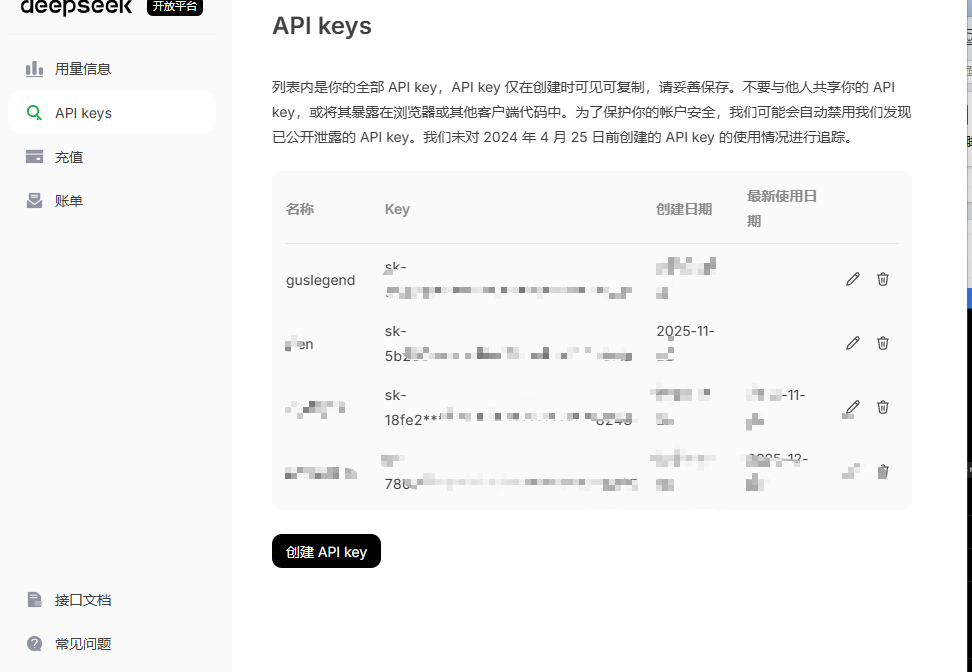
APIkey创建
阿里百炼官方地址:https://bailian.console.aliyun.com/console?tab=api#/api
DeepSeek应用开发环境搭建与实战
本项目的环境:
- 基于python v3.11版本开发
- python环境管理Miniconda(https://www.anaconda.com/docs/getting-started/miniconda/main)
- python交互式环境开发Jupyter Lab(https://jupyterlab.readthedocs.io/en/stable/getting_started/installation.html)
- 大模型调用:OpenAI python SDK
首先我们要创建对应的虚拟环境
conda create -n deepseek python=3.11我们需要安装python依赖软件包,pip install -r requirmenets.txt
# DeepSeek API 和 OpenAI SDK
openai==1.82.0
# HTTP 请求
requests==2.32.3
# 进度条
tqdm==4.67.1
# 向量数据库和模型
pymilvus[model]==2.5.10
# 深度学习框架
# GPU版本
torch==2.7.0
# CPU版本
# torch==2.7.0+cpu --extra-index-url https://download.pytorch.org/whl/cpu配置DeepSeek API Key
export DEEPSEEO_API_KEY= "sk-XXX"安装和使用Jupyter lab
# 安装jupyter lab
conda install -c conda-forge jupyterlab
# 生成jupyter lab 配置文件
jupyter lab --generate-config使用nohub后台运行jupyter Lab
jupyter lab --port=8000 --ServerApp.token=123456 --notebook-dir=./
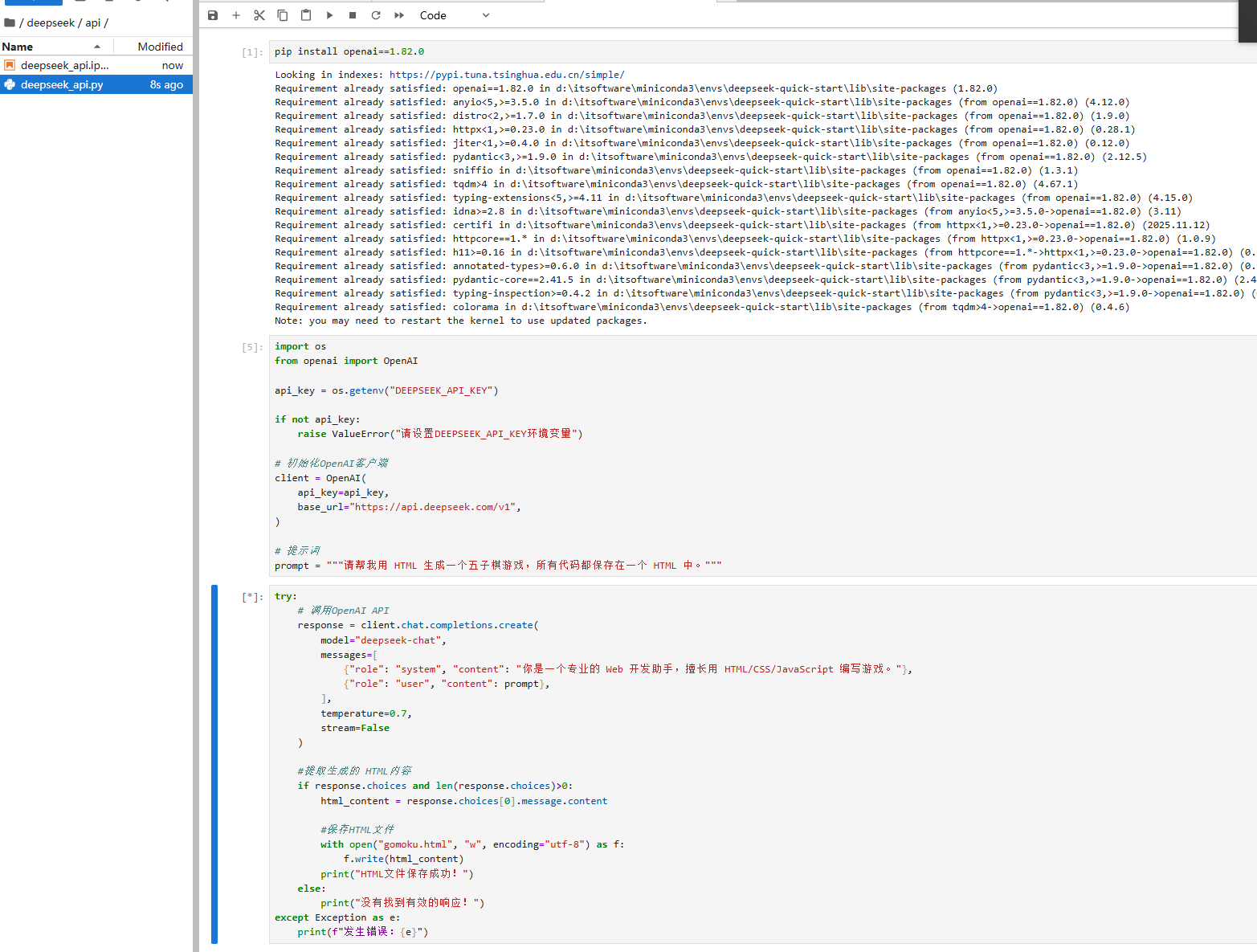
完整代码
import os
from openai import OpenAI
api_key = os.getenv("DEEPSEEK_API_KEY")
if not api_key:
raise ValueError("请设置DEEPSEEK_API_KEY环境变量")
# 初始化OpenAI客户端
client = OpenAI(
api_key=api_key,
base_url="https://api.deepseek.com/v1",
)
# 提示词
prompt = """请帮我用 HTML 生成一个江西地图的静态网页,所有代码都保存在一个 HTML 中。"""
try:
# 调用OpenAI API
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "你是一个专业的 Web 开发助手,擅长用 HTML/CSS/JavaScript 编写游戏。"},
{"role": "user", "content": prompt},
],
temperature=0.7,
stream=False
)
#提取生成的 HTML内容
if response.choices and len(response.choices)>0:
html_content = response.choices[0].message.content
#保存HTML文件
with open("demo.html", "w", encoding="utf-8") as f:
f.write(html_content)
print("HTML文件保存成功!")
else:
print("没有找到有效的响应!")
except Exception as e:
print(f"发生错误:{e}")
大模型的分类
普通大模型
普通大模型(如 DeepSeek-V3, Qwen-3, GPT-4.5等)适用于语言表达、常识问答、总结、提取、翻译、客服
类对话等"直接输出型"任务。
适用的典型场景:
|---------------|---------------------|
| 场景 | 描述 |
| 文本分类与摘要 | 新闻、评论、合同提取要点 |
| 对话客服机器人 | 回答 FAQ、售后支持、流程引导 |
| 文本生成 | 市场文案、邮件写作、内容创作 |
| 语言翻译 | 普通领域下的中英、英中互译 |
| 信息抽取 | 表单、报告中的字段提取 |
| 语义搜索 / FAQ 匹配 | 基于 embedding 的召回与匹配 |
推理大模型
推理大模型(如 DeepSeek-R1, Qwen-QwQ-Max, OpenAI o1, Gemini 2.5 Pro 等)擅长"链式思维、多步推
理、数学/逻辑问题、复杂代码理解与生成、结构化推理"。
适用的电线场景:
|--------------|--------------------|
| 场景 | 描述 |
| 数学解题 / 逻辑推理 | 解方程、推理题、数列推理等 |
| 代码理解与生成 | 多文件分析、跨模块重构、复杂函数推导 |
| 复杂问答系统 | 需要多步结合上下文的信息推理 |
| 结构化文档生成 | 例如法律文本、技术报告、推理性摘要 |
| 企业决策支持 | 涉及多维数据分析和因果关系判断 |
| 多 Agent 协同任务 | 需要规划任务、判断优先级与协调 |
向量数据库快速实战
引言:为什么RAG需要特别的数据库?
- RAG的核心是
检索,也就是从海量的信息中找到和用户问题最相关的几段内容。 - 这些内容通常被转换成了数字指纹-
向量(Embeddings)。 - 传统数据库Mysql不擅长高效地比较这些数字指纹的相似度。
- 向量数据库就是专门为存储,管理和高效检索这些向量而产生的。
向量数据库基本原理
核心任务相似度搜索:
当用户提出一个问题,我们先把这个问题也转换成一个查询向量。然后,向量数据库会在存储的海量内容向量中。快速找出根这个查询向量在空间中距离最近,最相似的那些。
常见的距离/相似度计算方法:
- 余弦相似度:看两个向量的方向有多一致(最常用)。
- 欧式距离:看两个向量的直线距离。
- 点积。
加速搜索:近似最近邻搜索
- 要在几千万,几百万甚至上亿的向量里精确找到最近的太慢了。
- ANN算法能在保证较高召回率(找到大部分相关的)的前提下,极大地提高搜索速度。牺牲一点点精度,换来巨大的效率提升。
向量数据库典型架构
- 数据接⼊层 (Ingestion API/Client):负责接收你要存储的原始数据(⽂本、图⽚等)和它们对应的向量 (Embeddings)。
- 存储层 (Storage Engine):可能使⽤磁盘、内存或混合存储,实际存储向量数据和可能的元数据(⽐如 原始⽂本的 ID,来源等)。
- 索引层 (Indexing Service):核⼼! 对存⼊的向量构建特殊的索引结构(⽐如 HNSW, IVFADC, LSH 等),这是实现快速 ANN 搜索的关键。索引的构建可能在写⼊时同步进⾏,也可能异步批量进⾏。
- 查询处理层 (Query Engine/API):接收⽤户的查询向量,利⽤索引快速执⾏相似度搜索,⽀持过滤(⽐ 如只在特定类别或时间范围内搜索),返回最相似的 Top-K 个结果及其元数据。
- 管理与监控 (Management & Monitoring):集群管理、扩缩容、备份恢复、性能监控、安全等。
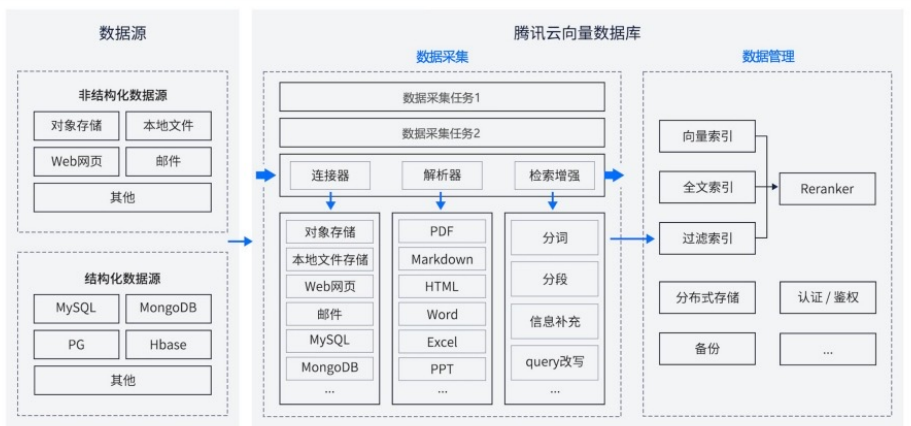
向量数据库的选型
-
性能(Performance):查询延迟(搜索一次要多久?越低越好);吞吐量(每秒能处理多少次查询?越高越好);索引构建时间(导入新数据后多久能被搜到?)
-
可扩展性(Scalability):能否轻松应对数据量和查询量的增长?支持水平扩展吗?
-
准确性(Accuracy/Recall):ANN 搜索的召回率如何?能不能在速度和精度之间做取舍?
-
成本(Cost):硬件成本、托管费用、人力维护成本,开源免费还是商业付费?
-
易用性与生态(Ease of Use & Ecosystem):API 是否友好?文档是否完善?社区是否活跃?是否有成熟的客户端 / SDK?与其他工具(如 LLM 框架 LangChain、Llamaindex)的集成度如何?
6.功能特性(Features):支持哪些 ANN 索引算法?支持元数据过滤吗?支持混合搜索(向量 + 关键词)吗?数据持久性、备份恢复、安全机制等。
向量数据库常见选型
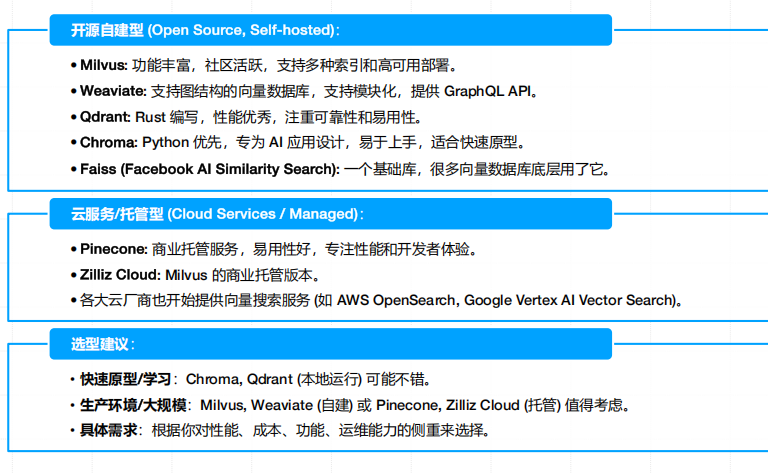
向量数据库使用方面
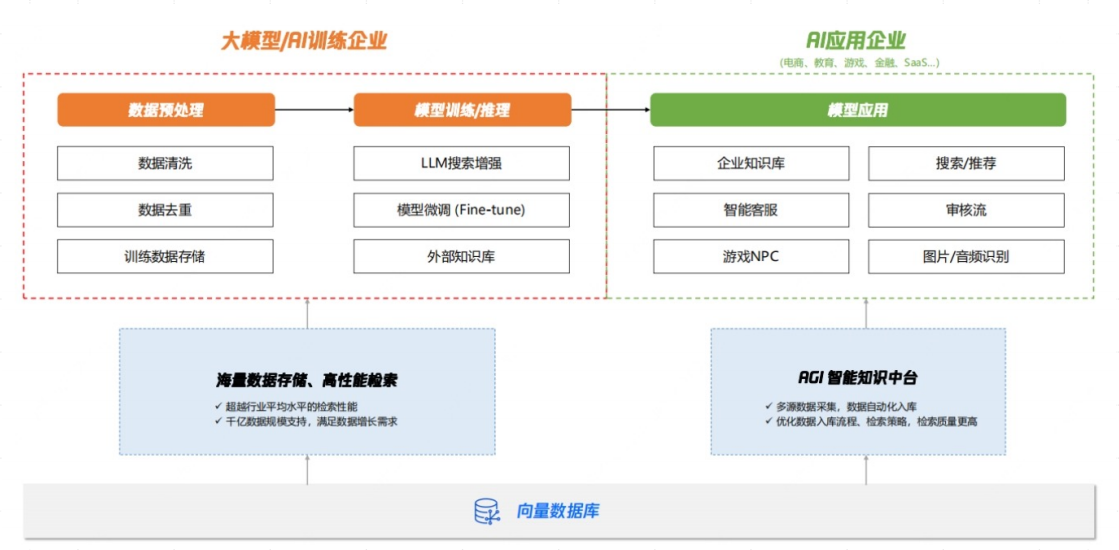
RAG
RAG核⼼思想:让⼤语⾔模型 (LLM) 在回答问题或⽣成 内容之前,先从⼀个外部的知识库⾥"查找资料", 然后再结合查到的资料和它⾃⼰的知识来给出答案。
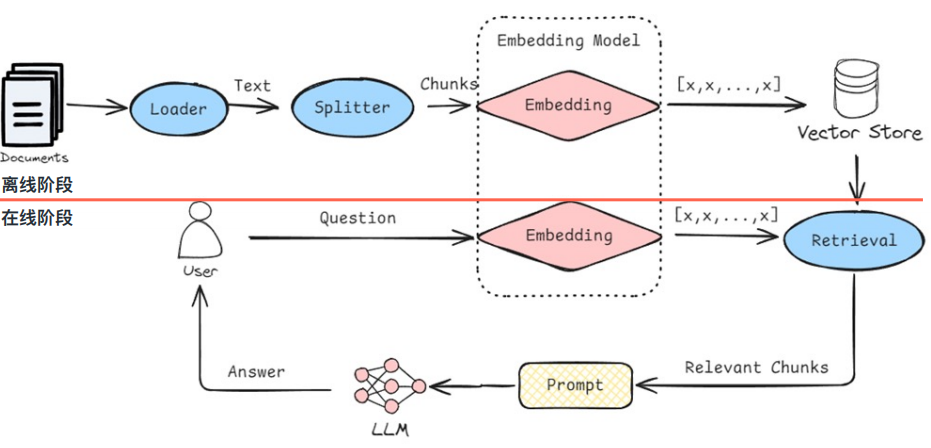
离线RAG
-
加载数据 (Load):从各种来源(⽂档、⽹⻚、数据库等)加载原始知识。
-
切分数据 (Split/Chunk):将加载的⽂档切分成更⼩的、易于处理的⽂本块。
-
⽣成嵌⼊ (Embed):使⽤ Embedding 模型为每个⽂本块⽣成向量嵌⼊。
-
存储⼊库 (Store):将⽂本块及其向量嵌⼊存储到向量数据库中,并建⽴索引
在线RAG
-
⽤户提问 (User Query):⽤户输⼊⼀个问题或指令。
-
查询嵌⼊ (Query Embedding):将⽤户的问题也转换成⼀个查询向量。
-
检索 (Retrieve):⽤查询向量去向量数据库中搜索最相似的 Top-K 个⽂本块(这些就是"查到的资料")。
-
增强与⽣成 (Augment & Generate): 将⽤户原始问题和检索到的相关⽂本块⼀起组织成⼀个新的提示 (Prompt) 给到 LLM。 LLM 参考提供的资料和⾃身知识,⽣成最终的答案。
RAG在信息检索和生成任务中的优势
1. 减少 "幻觉"(Reduce Hallucinations)
- LLM 有时会编造听起来合理但不真实的信息;
- RAG 通过提供相关、真实的外部知识作为依据,显著减少这种情况。
2. 使用最新 / 私有知识(Access to Up-to-Date/Private Knowledge)
- LLM 的知识截止于训练数据,对训练后新事件或公司内部私有数据一无所知;
- RAG 允许 LLM 访问和利用外部的、动态更新的知识库。
3. 提高答案的可追溯性 / 可解释性(Improved Verifiability/Explainability)
- 答案基于检索到的特定文本块生成,可明确告知用户 "答案根据 XXX 文档的第 Y 段而来",方便验证。
4. 更具成本效益地更新知识(Cost-Effective Knowledge Updates)
- 重新训练 LLM 成本极高;
- RAG 只需更新向量数据库内容,LLM 本身无需重训,成本更低。
5. 个性化与领域适应(Personalization & Domain Adaptation)
- 可针对特定用户 / 领域构建专属知识库,让 LLM 回答更个性化、专业化。
RAG技术要点
1. 数据预处理与切块(Chunking Strategy)
- 切多大:太小易丢失上下文,太大易引入噪声 / 超出 LLM 上下文窗口;
- 怎么切:按固定字数、按句子 / 段落、基于语义的智能切分;
- 元数据(Metadata):为每个块添加来源、标题、日期等元数据,辅助后续过滤 / 引用。
2. 嵌入模型选择(Embedding Model)
- 质量至上:Embedding 的质量决定检索准确性("垃圾进,垃圾出");
- 一致性:查询和文档必须用相同的 Embedding 模型;
- 领域适配:专业知识库需选用 / 微调领域特定的 Embedding 模型。
3. 检索策略(Retrieval Strategy)
- Top-K 选择:选择多少个相关文本块(太少信息不足,太多易引入噪声);
- 相似度阈值:只选相似度高于某个分数的块;
- 混合检索(Hybrid Search):结合向量相似度搜索与关键词搜索;
- 重排(Re-ranking):用复杂模型(如 Cross-Encoder)对 Top-K 结果二次排序。
4. 上下文构建与提示工程(Context Construction & Prompt Engineering)
- 如何组织:将问题和检索到的多文本块有效组合成清晰提示;
- 指令清晰:明确告知 LLM "根据提供的上下文回答问题";
- 处理超长上下文:内容过多时需筛选、压缩后分批次给 LLM;
- 处理冲突信息:提示中引导 LLM 处理文本块间的矛盾。
5. 生成模型选择(Generation to Chooose!)
- 选模型:优先选理解能力强、幻觉少的 LLM;
- 上下文窗口:窗口大小影响能输入的检索信息数量。
6. 评估与迭代(Evaluation & Iteration)
- 如何评价:
-
- 检索质量:召回率、精确率、MRR 等;
- 生成质量:回答的相关性、准确性、流畅性等;
- 端到端评估:结合具体场景综合评估;
- 持续优化:监控 bad case,迭代优化各环节。
第一个RAG
pip
install
"pymilvus[model]==2.5.10"
openai == 1.82
.0
requests == 2.32
.3
tqdm == 4.67
.1
torch == 2.7
.0
import os
api_key = os.getenv("DEEPSEEK_API_KEY")
from glob import glob
text_lines = []
for file_path in glob("milvus_docs/en/faq/*.md", recursive=True):
with open(file_path, "r") as file:
file_text = file.read()
text_lines += file_text.split("# ")
len(text_lines)
# 准备 LLM 和 Embedding 模型
from openai import OpenAI
deepseek_client = OpenAI(
api_key=api_key,
base_url="https://api.deepseek.com/v1", # DeepSeek API 的基地址
)
# from pymilvus import model as milvus_model
# embedding_model = milvus_model.DefaultEmbeddingFunction()
from pymilvus import model as milvus_model
# OpenAI国内代理 https://api.apiyi.com/token
embedding_model = milvus_model.dense.OpenAIEmbeddingFunction(
model_name='text-embedding-3-large', # Specify the model name
api_key='sk-XXX', # Provide your OpenAI API key
base_url='https://api.apiyi.com/v1',
dimensions=512
)
test_embedding = embedding_model.encode_queries(["This is a test"])[0]
embedding_dim = len(test_embedding)
print(embedding_dim)
print(test_embedding[:10])
test_embedding_0 = embedding_model.encode_queries(["That is a test"])[0]
print(test_embedding_0[:10])
# 将数据加载到 Milvus
from pymilvus import MilvusClient
milvus_client = MilvusClient(uri="./milvus_demo.db")
collection_name = "my_rag_collection"
if milvus_client.has_collection(collection_name):
milvus_client.drop_collection(collection_name)
milvus_client.create_collection(
collection_name=collection_name,
dimension=embedding_dim,
metric_type="IP", # 内积距离
consistency_level="Strong",
# 支持的值为 (`"Strong"`, `"Session"`, `"Bounded"`, `"Eventually"`)。更多详情请参见 https://milvus.io/docs/consistency.md#Consistency-Level。
)
from tqdm import tqdm
data = []
doc_embeddings = embedding_model.encode_documents(text_lines)
for i, line in enumerate(tqdm(text_lines, desc="Creating embeddings")):
data.append({"id": i, "vector": doc_embeddings[i], "text": line})
milvus_client.insert(collection_name=collection_name, data=data)
question = "How is data stored in milvus?"
# 在 collection 中搜索该问题,并检索语义上最匹配的前3个结果。
search_res = milvus_client.search(
collection_name=collection_name,
data=embedding_model.encode_queries(
[question]
), # 将问题转换为嵌入向量
limit=3, # 返回前3个结果
search_params={"metric_type": "IP", "params": {}}, # 内积距离
output_fields=["text"], # 返回 text 字段
)
import json
retrieved_lines_with_distances = [
(res["entity"]["text"], res["distance"]) for res in search_res[0]
]
print(json.dumps(retrieved_lines_with_distances, indent=4))
context = "\n".join(
[line_with_distance[0] for line_with_distance in retrieved_lines_with_distances]
)
context
question
SYSTEM_PROMPT = """
Human: 你是一个 AI 助手。你能够从提供的上下文段落片段中找到问题的答案。
"""
USER_PROMPT = f"""
请使用以下用 <context> 标签括起来的信息片段来回答用 <question> 标签括起来的问题。最后追加原始回答的中文翻译,并用 <translated>和</translated> 标签标注。
<context>
{context}
</context>
<question>
{question}
</question>
<translated>
</translated>
"""
USER_PROMPT
response = deepseek_client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": USER_PROMPT},
],
)
print(response.choices[0].message.content)