文章目录
- [1. 实战概述](#1. 实战概述)
- [2. 实战步骤](#2. 实战步骤)
-
- [2.1 用户关系网络图](#2.1 用户关系网络图)
- [2.2 准备数据文件](#2.2 准备数据文件)
-
- [2.2.1 创建本地文件](#2.2.1 创建本地文件)
- [2.2.2 创建HDFS目录](#2.2.2 创建HDFS目录)
- [2.2.3 上传数据文件到HDFS](#2.2.3 上传数据文件到HDFS)
- [2.3 创建与存储图](#2.3 创建与存储图)
-
- [2.3.1 创建图](#2.3.1 创建图)
-
- [2.3.1.1 导入GraphX包](#2.3.1.1 导入GraphX包)
- [2.3.1.2 根据有属性的顶点和边构建图(`Graph()`)](#2.3.1.2 根据有属性的顶点和边构建图(
Graph())) - [2.3.1.3 根据边创建图(`Graph.fromEdges()`)](#2.3.1.3 根据边创建图(
Graph.fromEdges())) - [2.3.1.4 根据边的两个顶点的二元组创建图(`Graph.fromEdgeTuples()`)](#2.3.1.4 根据边的两个顶点的二元组创建图(
Graph.fromEdgeTuples()))
- [2.3.2 缓存与释放图](#2.3.2 缓存与释放图)
- [2.4 查询与转换数据](#2.4 查询与转换数据)
-
- [2.4.1 数据查询](#2.4.1 数据查询)
- [2.4.2 数据转换](#2.4.2 数据转换)
- [2.5 转换结构与关联聚合数据](#2.5 转换结构与关联聚合数据)
-
- [2.5.1 结构转换](#2.5.1 结构转换)
- [2.5.2 数据关联聚合](#2.5.2 数据关联聚合)
- [3. 实战总结](#3. 实战总结)
1. 实战概述
- 本次实战围绕 Spark GraphX 构建学术用户关系网络图展开,通过准备顶点与边数据、上传至 HDFS,并使用
Graph()、Graph.fromEdges()和Graph.fromEdgeTuples()三种方式创建图对象,验证了图的正确加载与结构完整性,为后续图计算奠定基础。
2. 实战步骤
2.1 用户关系网络图
- 绘制用户关系网络图
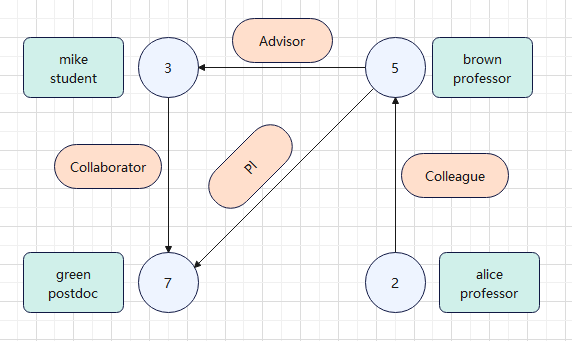
- 该图展示了一个学术用户关系网络:节点代表用户(如学生、教授、博士后),边表示关系(如导师、同事、合作者)。例如,mike 是 brown 的学生,green 与 mike 合作,brown 与 alice 为同事,green 也是 brown 的 PI。体现了学术协作与层级结构。
2.2 准备数据文件
2.2.1 创建本地文件
-
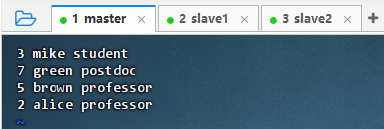
创建用户关系网络图顶点数据文件
- 执行命令:
vim vertices.txt
- 执行命令:
-
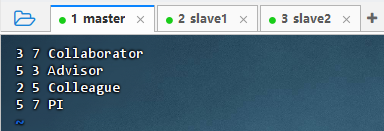
创建用户关系网络图边数据文件
- 执行命令:
vim edges.txt
- 执行命令:
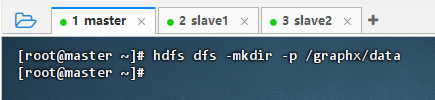
2.2.2 创建HDFS目录
- 执行命令:
hdfs dfs -mkdir -p /graphx/data
2.2.3 上传数据文件到HDFS
- 执行命令:
hdfs dfs -put vertices.txt /graphx/data
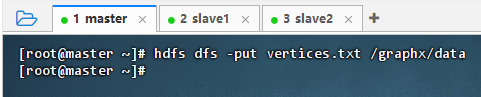
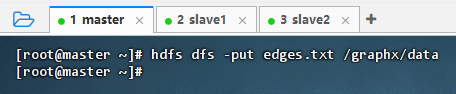
- 执行命令:
hdfs dfs -put edges.txt /graphx/data
2.3 创建与存储图
2.3.1 创建图
2.3.1.1 导入GraphX包
-
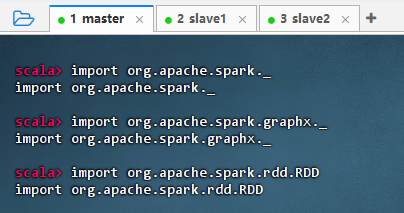
执行命令
scala import org.apache.spark._ import org.apache.spark.graphx._ import org.apache.spark.rdd.RDD
-
结果说明 :该图展示了在 Spark Shell 中成功导入核心包的过程。三条
import语句分别引入了 Spark 核心、GraphX 图计算和 RDD 操作相关类,为后续分布式数据处理和图算法开发做好准备,表明环境配置正确,可进行 Spark 编程。
2.3.1.2 根据有属性的顶点和边构建图(Graph())
-
构造有属性的顶点和边的图
scala// 创建顶点 RDD val users: RDD[(VertexId, (String, String))] = sc.textFile("hdfs://master:9000/graphx/data/vertices.txt") .map { line => val fields = line.split(" ") (fields(0).toLong, (fields(1), fields(2))) } // 创建边 RDD val relationships: RDD[Edge[String]] = sc.textFile("hdfs://master:9000/graphx/data/edges.txt") .map { line => val fields = line.split(" ") Edge(fields(0).toLong, fields(1).toLong, fields(2)) } // 定义默认用户(用于处理缺失顶点) val defaultUser = ("Black Smith", "Missing") // 构建图对象 val graph_urelate = Graph(users, relationships, defaultUser)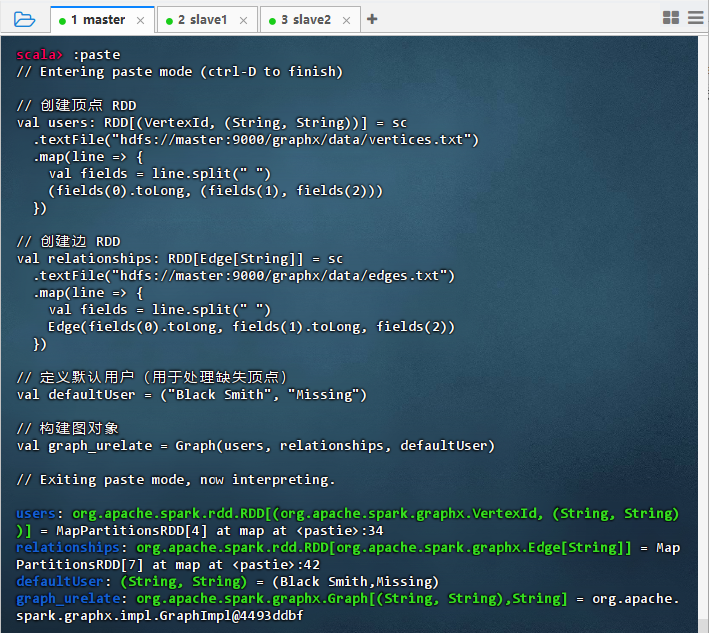
-
结果说明:代码成功在 Spark Shell 中执行,从 HDFS 加载顶点和边数据,构建了 GraphX 图对象。输出显示 users 和 relationships RDD 已创建,defaultUser 定义完成,最终生成 graph_urelate 图实例,表明图结构构建成功,可进行后续图计算操作。
-
查询图的顶点,执行命令:
graph_urelate.vertices.collect.foreach(println)
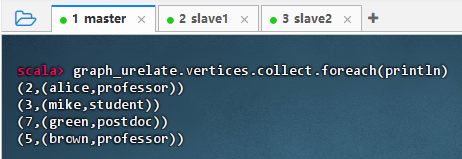
-
结果说明:执行命令后,输出了图中所有顶点的属性信息,显示了每个用户节点的 ID 和对应的角色(如 alice 是 professor,mike 是 student 等),表明图的顶点数据已成功加载并可访问,验证了 GraphX 图结构构建正确。
-
查询图的边,执行命令:
graph_urelate.edges.collect.foreach(println)
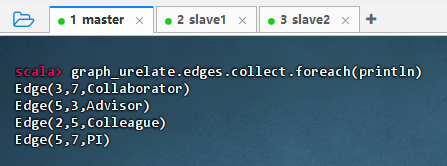
-
结果说明:执行命令后,输出了图中所有边的信息,显示了节点之间的关系类型,如 3 和 7 是合作者(Collaborator),5 和 3 是导师关系(Advisor)等,表明图的边数据已正确加载,验证了用户关系网络结构构建成功。
2.3.1.3 根据边创建图(Graph.fromEdges())
-
利用
Graph.fromEdges()方法创建图scala// 读取边数据文件 val records: RDD[String] = sc.textFile("hdfs://master:9000/graphx/data/edges.txt") // 解析每行数据为 Edge 对象 val followers: RDD[Edge[String]] = records.map { line => val fields = line.split(" ") Edge(fields(0).toLong, fields(1).toLong, fields(2)) } // 基于边构建图(顶点属性统一设为默认值 1L) val graphFromEdges = Graph.fromEdges(followers, defaultValue = 1L)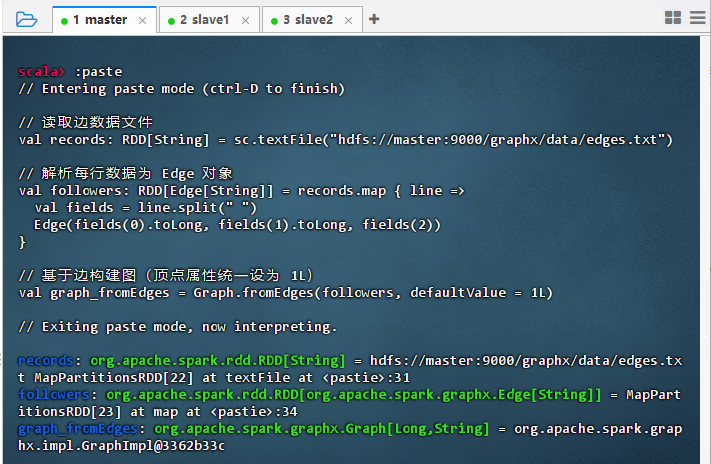
-
结果说明 :代码成功从 HDFS 读取边数据并解析为 Edge RDD,构建了图对象
graph_fromEdges。输出显示 records、followers 和 graph_fromEdges 均已正确创建,表明边数据加载和图结构初始化完成,可进行后续图计算操作。 -
查询图的顶点,执行命令:
graph_fromEdges.vertices.collect.foreach(println)
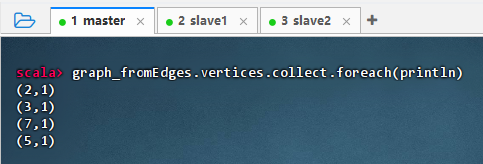
-
结果说明 :该命令输出了图中所有顶点的 ID 及其属性,显示每个节点的值均为 1(默认值),表明
Graph.fromEdges成功从边数据推导出顶点集合,并为每个顶点分配了统一的默认属性,验证了图结构构建正确。 -
查询图的边,执行命令:
graph_fromEdges.edges.collect.foreach(println)

-
结果说明:该命令输出了图中所有边的信息,显示了节点之间的关系类型,如 3 和 7 是合作者(Collaborator),5 和 3 是导师关系(Advisor)等,表明边数据已正确加载并保留原始属性,验证了图结构构建成功。
2.3.1.4 根据边的两个顶点的二元组创建图(Graph.fromEdgeTuples())
-
提示:此方式适用于仅需源点和目标点、忽略边属性的场景。若需保留关系类型(如 "Advisor"),应使用 Edge 对象而非二元组。
-
利用
Graph.fromEdgeTuples()方法创建图scala// 读取边数据文件 val records: RDD[String] = sc.textFile("hdfs://master:9000/graphx/data/edges.txt") // 解析为 (srcId, dstId) 二元组 RDD val edgesRDD: RDD[(VertexId, VertexId)] = records .map(line => line.split(" ")) .map(fields => (fields(0).toLong, fields(1).toLong)) // 基于边二元组构建图(顶点属性设为默认值 1L) val graphFromEdgeTuples = Graph.fromEdgeTuples(edgesRDD, defaultValue = 1L)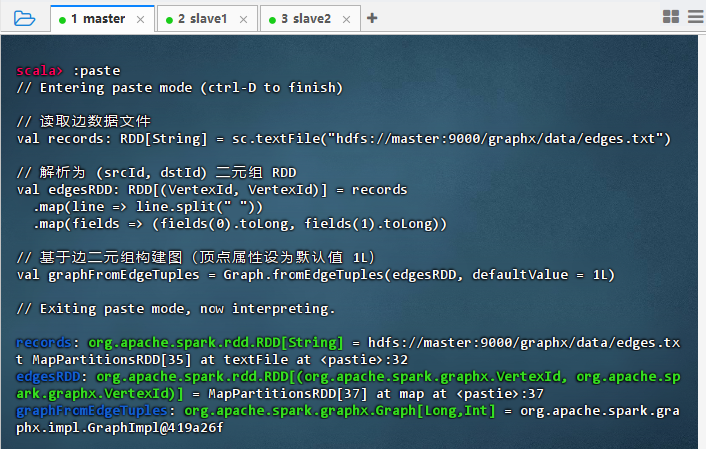
-
结果说明 :代码成功从 HDFS 读取边数据,解析为顶点 ID 的二元组 RDD,并通过
Graph.fromEdgeTuples构建图对象。输出显示 records、edgesRDD 和 graphFromEdgeTuples 均已正确创建,表明图结构初始化成功,可进行后续图计算操作。 -
查询图的顶点,执行命令:
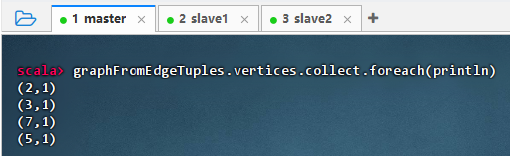
graphFromEdgeTuples.vertices.collect.foreach(println)
-
结果说明 :该命令输出了图中所有顶点的 ID 及其默认属性值(1),表明
Graph.fromEdgeTuples成功从边数据推导出顶点集合,并为每个顶点分配统一默认属性,验证了图结构构建正确,顶点信息完整。 -
查询图的边,执行命令:
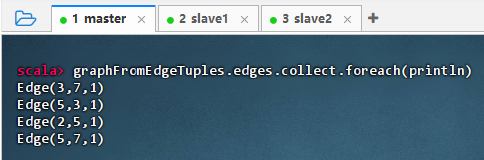
graphFromEdgeTuples.edges.collect.foreach(println)
-
结果说明 :该命令输出了图中所有边的结构,显示每条边的源点、目标点及默认属性值(1),表明
Graph.fromEdgeTuples成功构建了边集合,且边数据完整保留,验证了图的边信息正确加载并可访问。