一、安装方式
1.1 windows安装
安装方式因系统的不同而不同,Neo4j 支持 Linux, Mac,Windows。
安装又离不开官网,官网地址:https://neo4j.com/。因为我是windows操作系统,所以,这次先讲windows的。如何后面涉及到Linux系统的,再进行更新。
我下载的版本是:neo4j-desktop-2.1.0-x64.exe, 也可以去国内的其他站点找找资源。
注意:这个安装有点奇怪,双击直接是安装中,安装目录不可选。
二、运行
2.1 windows运行
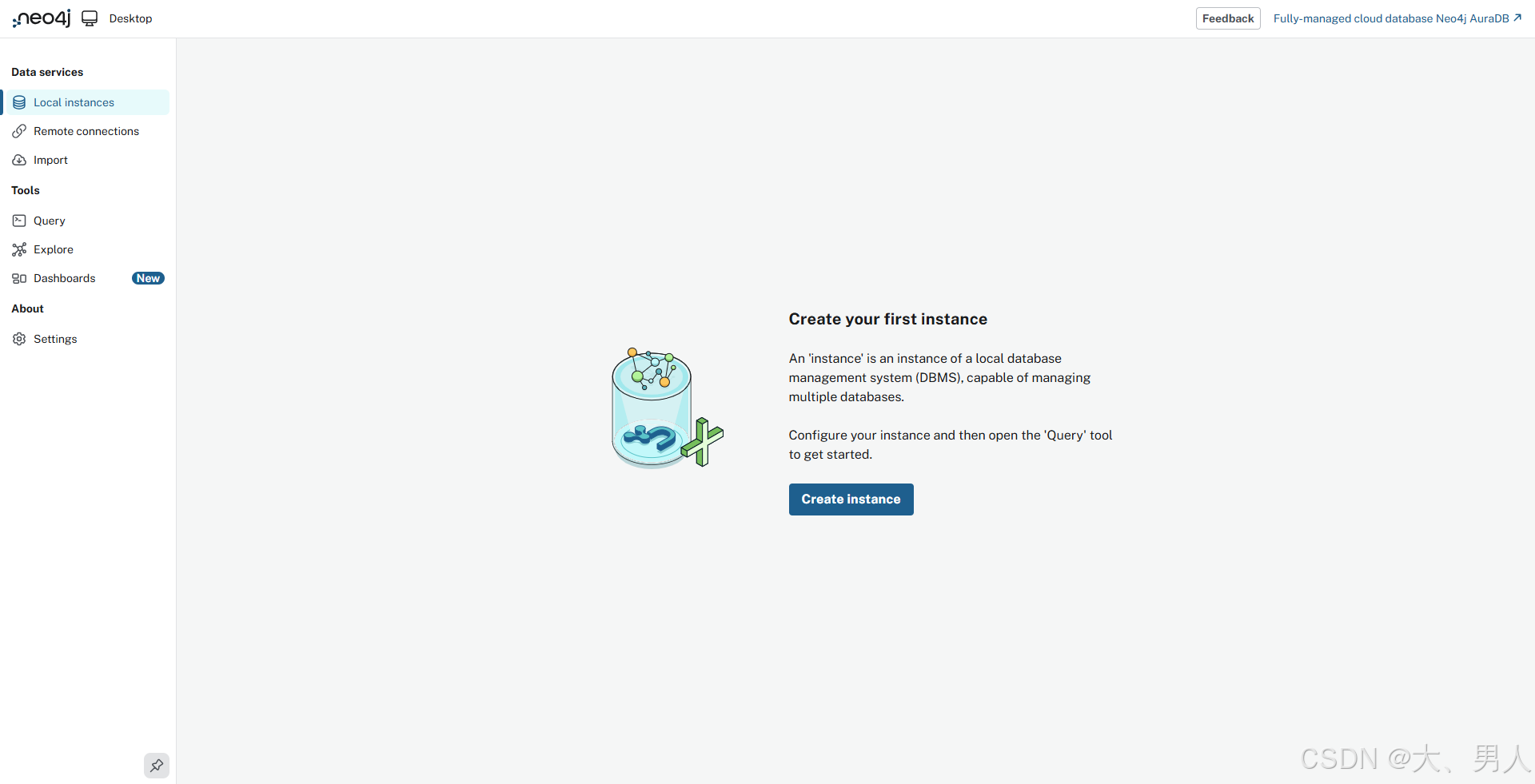
先创建一个实例:
浏览器访问WEB, 地址: Neo4j Browser![]() http://localhost:7474/browser/
http://localhost:7474/browser/
三、核心概念
在操作前先理解 Neo4j 的核心模型:
| 概念 | 说明 |
|---|---|
| 节点(Node) | 图的基本单元,代表实体(如用户、商品、订单),可添加标签(Label) 分类(如 :User) |
| 关系(Relationship) | 连接两个节点,有方向 (如 User→购买→Product)、类型 (如 :BUY)和属性 |
| 属性(Property) | 节点 / 关系的键值对(如节点 name:"张三",关系 amount:99) |
| 标签(Label) | 节点的分类标识(一个节点可多个标签,如 :User:VIP) |
| 模式(Pattern) | 节点和关系的组合(如 (u:User)-[:BUY]->(p:Product)) |
Neo4j 使用 Cypher(图查询语言)操作数据,语法直观,类似 SQL 但针对图优化。
1. 基础语法规则
- 节点用
()表示,如(n)、(u:User); 下面有解释 - 关系用
--表示(无方向),->/<-表示方向,如(u)-[:BUY]->(p); - 属性用
{}表示,如(u:User {id:1, name:"张三"}); - 关键字(MATCH/CREATE/RETURN)大小写不敏感,推荐大写。
2. 增:创建节点 / 关系
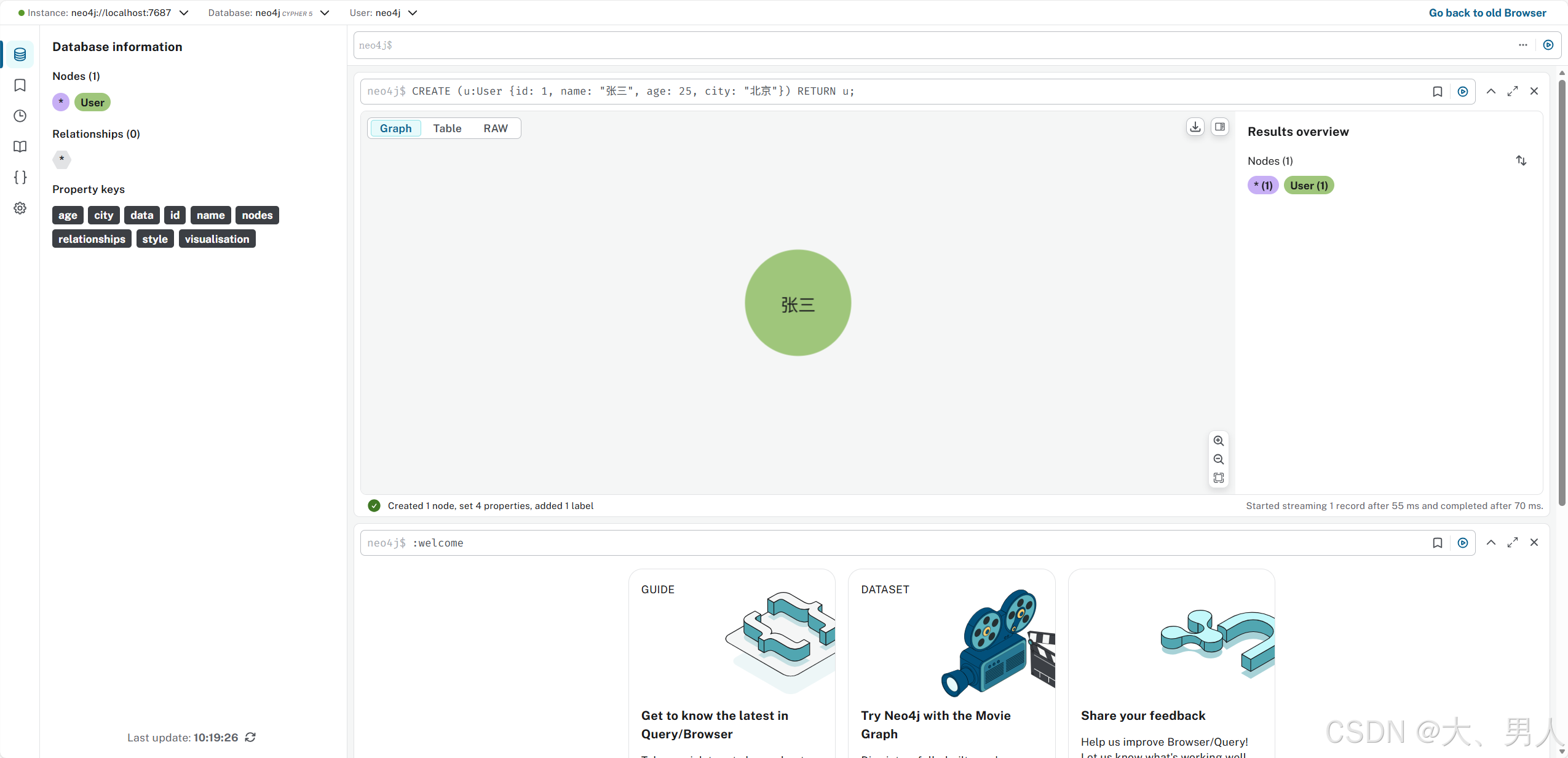
(1)创建节点
sql
# 创建单个节点(带标签和属性)
CREATE (u:User {id: 1, name: "张三", age: 25, city: "北京"})
RETURN u;
# RETURN 用于返回创建的节点
# 创建多个节点
CREATE (p1:Product {id: 101, name: "手机", price: 3999}),
(p2:Product {id: 102, name: "耳机", price: 299})
RETURN p1, p2;解释:
u:User u 节点的别名,类似关系型数据库的表的别名;:标签分隔符;User是标签,类似关系型数据库表的名称。
下面2行就更好解释了,给Product数据表插入了2条数据,分别是p1和p2。(按照关系型数据库解释)。
(2)创建关系
sql
# 先匹配节点,再创建关系(推荐:避免重复创建)
MATCH (u:User {id:1}), (p:Product {id:101})
CREATE (u)-[r:BUY {order_time: "2025-01-01", amount: 1, total: 3999}]->(p)
RETURN u, r, p;
# 一次性创建节点+关系
CREATE (u:User {id:2, name:"李四"})-[r:VIEW {time:"2025-01-02"}]->(p:Product {id:102})
RETURN u, r, p;3. 查:查询数据(核心)
(1)基础查询
sql
# 查询所有 User 节点
MATCH (u:User)
RETURN u.name, u.age;
# 查询带条件的节点
MATCH (u:User {age:25})
RETURN u;
# 查询关系(张三购买的商品)
MATCH (u:User {name:"张三"})-[r:BUY]->(p:Product)
RETURN u.name, r.order_time, p.name;
# 查询路径(如用户→购买→商品的所有路径)
MATCH path = (u:User)-[:BUY]->(p:Product)
RETURN path;(2)进阶查询(过滤、排序、分页)
sql
# 过滤:价格>1000的商品
MATCH (p:Product)
WHERE p.price > 1000
RETURN p.name, p.price;
# 排序+分页:按价格降序,取前1条
MATCH (p:Product)
RETURN p.name, p.price
ORDER BY p.price DESC
LIMIT 1;
# 统计:用户购买商品的数量
MATCH (u:User)-[:BUY]->(p:Product)
RETURN u.name, COUNT(p) AS buy_count;
# 多关系查询(用户既购买又浏览的商品)
MATCH (u:User)-[:BUY]->(p:Product), (u)-[:VIEW]->(p)
RETURN u.name, p.name;4. 改:更新数据
sql
# 更新节点属性(修改张三的年龄)
MATCH (u:User {name:"张三"})
SET u.age = 26, u.city = "上海" # 新增属性也用SET
RETURN u;
# 更新关系属性(修改订单金额)
MATCH (u:User {id:1})-[r:BUY]->(p:Product {id:101})
SET r.total = 3899 # 优惠100
RETURN r;5. 删:删除节点 / 关系
⚠️ 注意:删除节点前必须先删除其关联的关系,否则会报错。
sql
# 删除单个关系
MATCH (u:User {id:1})-[r:BUY]->(p:Product {id:101})
DELETE r;
# 删除节点(先删关系再删节点)
MATCH (u:User {id:2})-[r]->(p:Product) # 匹配所有关联关系
DELETE r, u, p; # 同时删除关系和节点
# 删除所有节点和关系(清空数据库,谨慎使用!)
MATCH (n)
DETACH DELETE n; # DETACH DELETE 自动删除节点的所有关系四、进阶用法
1. 索引与约束(优化查询 + 保证数据唯一性)
(1)创建索引(加速查询)
sql
# 为 User 的 id 创建索引
CREATE INDEX idx_user_id FOR (u:User) ON (u.id);
# 为 Product 的 name 创建全文索引(支持模糊查询)
CREATE FULLTEXT INDEX idx_product_name FOR (p:Product) ON EACH [p.name];(2)创建约束(保证唯一性)
sql
# 保证 User 的 id 唯一
CREATE CONSTRAINT constraint_user_id UNIQUE FOR (u:User) REQUIRE u.id IS UNIQUE;
# 非空约束(Neo4j 4.0+)
CREATE CONSTRAINT constraint_product_price FOR (p:Product) REQUIRE p.price IS NOT NULL;2. 批量导入数据
(1)CSV 导入(适合大量数据)
准备 CSV 文件(如 users.csv):
sql
id,name,age,city
3,王五,30,广州
4,赵六,28,深圳放入 Neo4j 的 import 目录(桌面版可在「Database → Open Folder → Import」找到);
执行导入命令:
(2)使用 APOC 插件(更灵活)
APOC 是 Neo4j 官方扩展库,支持 JSON/Excel 导入、批量操作等,需先安装(桌面版可在「Plugins」中启用)。
3. 编程语言连接(Python 示例)
使用 neo4j 官方驱动(需先安装:pip install neo4j):
python
from neo4j import GraphDatabase
# 连接数据库
driver = GraphDatabase.driver(
"bolt://localhost:7687",
auth=("neo4j", "你的密码")
)
# 执行查询
def get_user_buy_products(user_name):
with driver.session() as session:
result = session.run(
"""
MATCH (u:User {name:$name})-[r:BUY]->(p:Product)
RETURN u.name, r.order_time, p.name
""",
name=user_name
)
# 处理结果
for record in result:
print(f"用户 {record['u.name']} 在 {record['r.order_time']} 购买了 {record['p.name']}")
# 调用函数
get_user_buy_products("张三")
# 关闭连接
driver.close()五、常用工具与技巧
- Neo4j Browser 快捷键 :
:help:查看帮助;:schema:查看索引、约束、标签和关系类型;:clear:清空界面;
- 性能优化 :
- 为查询字段创建索引;
- 避免
MATCH (n)全图扫描; - 复杂查询用
PROFILE分析执行计划(如PROFILE MATCH (u:User)-[:BUY]->(p) RETURN u);
- 可视化:Neo4j Browser 中查询结果可切换「Graph」视图,直观展示节点和关系。
六、常见问题
- 忘记密码:桌面版可在「Database → Manage → Change Password」修改;Docker 部署可进入容器重置;
- 端口被占用 :修改
neo4j.conf中的dbms.connector.bolt.port和dbms.connector.http.port; - 数据备份 / 恢复 :使用
neo4j-admin dump/neo4j-admin load命令,或桌面版的「Backup/Restore」功能。
总结
Neo4j 的核心是 Cypher 语言和图数据模型,新手建议先通过桌面版熟悉基础操作,再结合业务场景做进阶开发(如知识图谱构建、路径分析)。官方文档(Neo4j Docs)是最权威的参考,可深入学习高级特性(如图算法、事务、集群部署)。