今天凌晨,OpenAI 放出了他们对 Gemini 3 Pro 的正面反击------GPT-5.2。
但说实话,现在再用"更聪明"这种词去夸一个大模型,真的没什么意思了。
我看下来,GPT-5.2 真正让我眼前一亮的,是它开始理解"做事的节奏"了。
什么意思?
过去的模型,有时候就像刚毕业的小朋友,思路飞快,但节奏全靠撞。你让它帮忙写个方案,它啪一顿输出,看着热闹,细看全是漏洞,逻辑跳着走,格式乱飞,最后还得你一段段返工、整理、手动修。
但 GPT-5.2 不一样了。
你丢个活给它,它会先判断你讲清楚没,结构搭不搭得上,然后一点点推进,中间发现哪里错了会停下来自查,最后还不忘收尾附个注释或建议。
而这不只是体感。
OpenAI 这次专门测了一个叫 GDPval 的评估体系(全称是 Generalized Domain Performance Evaluation),是几个月前 OpenAI 自己推出的。主打测试大模型在"真实知识工作任务"里的表现。
结果很猛:
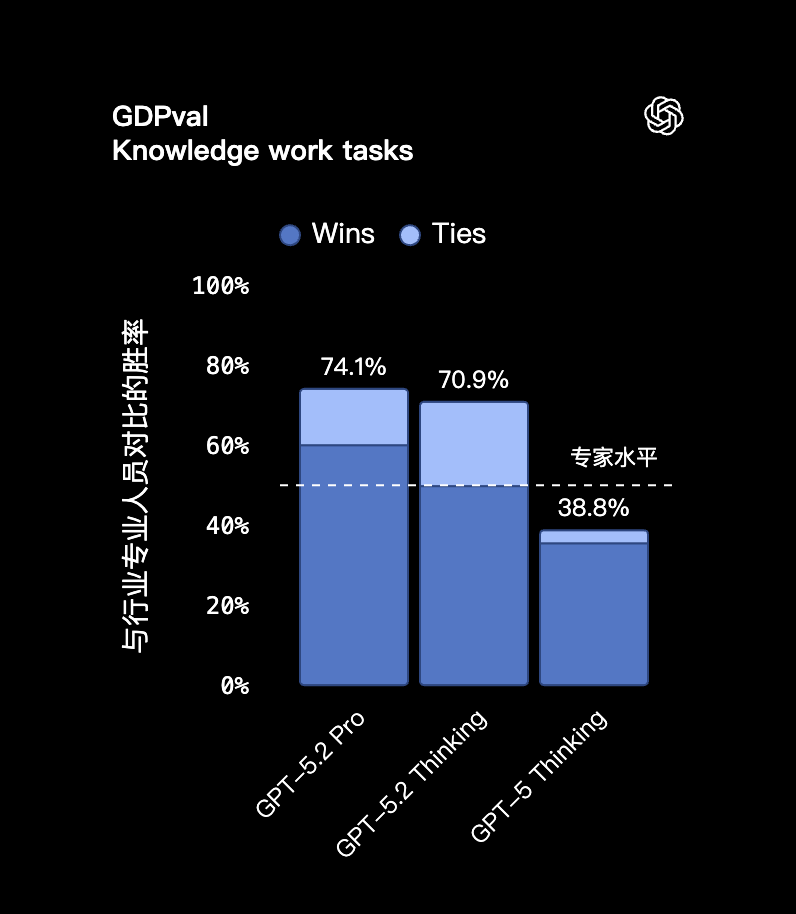
GPT-5.2 Pro 在复杂任务中的胜率是 74.1%,连 GPT-5.2 Thinking 版本也有 70.9%。对比之下,人类专业人士的平均完成度只有 38.8%。。。
而且这不是随便找个小任务测的,而是真做了投资银行实习生级别的难度。比如:「为一家财富 500 强公司做一份格式合规、引用完整的三表模型」,或者「为私有化交易做一份杠杆收购的 Excel 模型」。
在这种级别的测试里,GPT‑5.2 Thinking 的平均得分从 59.1% 提升到 68.4%,比上一代 GPT‑5.1 整整高了 9.3 个百分点。
咱来看几个真实工作场景:
Case1:
prompt:创建一个人力资源规划模型,含编制、招聘、预算、流失率,按部门分工程、市场、法务、销售
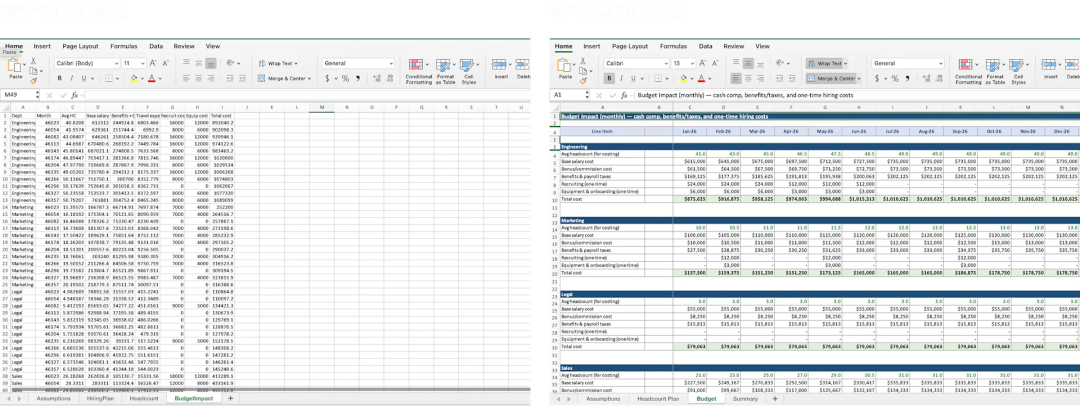
以往它要么写一堆 HR 理论,要么生成一个空表格框架。
GPT-5.2 直接给你建了一份 Excel 模型,细化到了部门人头、未来六个月招聘节奏、离职预测曲线、预算弹性,并且附了一个「变动参数 → 预算影响」的联动分析面板,堪比人力系统里的规划模块。
Case 2:
prompt:帮我做一张股权瀑布图,评估 C 轮融资前创始人与投资人的回报分配
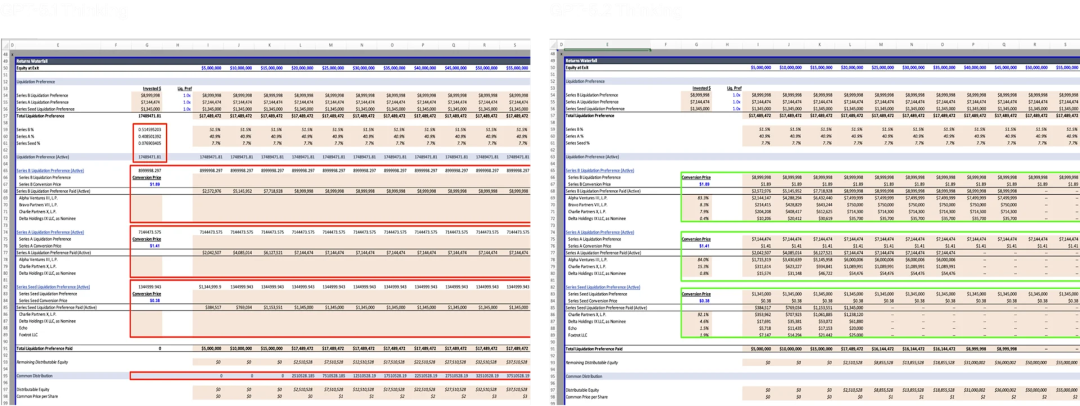
过去模型听不懂什么叫 Liquidation Preference、参与与否、转换价格,计算永远出错。
5.2 这次不仅完整跑通了整个 waterfall 的分配逻辑,还补齐了 Seed、A、B 各轮的优先权约束,关键是生成的表格能审计、有公式、逻辑对。你作为投行分析师,拿它出去汇报都不用重算。
Case 3:
prompt:你是英国某家 AI 初创的项目经理,客户是牛津郡的一家自行车修理店。现在请为 10 月份准备一份正式的项目进展汇报 PowerPoint,包含支出情况、项目日志、风险清单、当前重点与审计问答页。
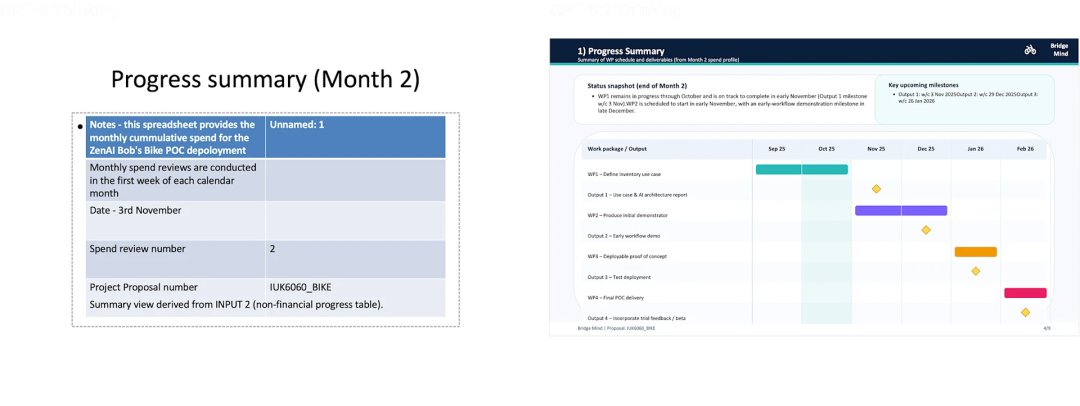
你听到这种题就头大吧?我也是。
结果 GPT-5.2 把输入里的 Excel 预算、风险表、日志 Word 全爬了一遍,拆成了 9 页 PowerPoint,每页结构清晰,图表、目录、引用、编号都对得上,连项目周期里"这是第二个月但上个月不要求报告"这种细节它都自己补上了。
你看完这几个例子,就会突然发现一件很神奇的事:它不再拼命追求"写得快"了,而是你们俩一起干活的时候,它终于不拖你后腿了。
它节奏对上了,你节奏也顺了。
结果就是,你真的省了不少时间。
OpenAI 自己也说了,普通企业用户每天能省 40 到 60 分钟,重度用户一周能省超过 10 小时。
OpenAI 这一年没少复盘大家的使用数据,估计也想明白了。别整那些花架子了,踏实把事儿干好才是正经的。
榜单数据
了解完这次 GPT-5.2 最大的更新点,我们再来聊聊传统的榜单数据。
整体来看:
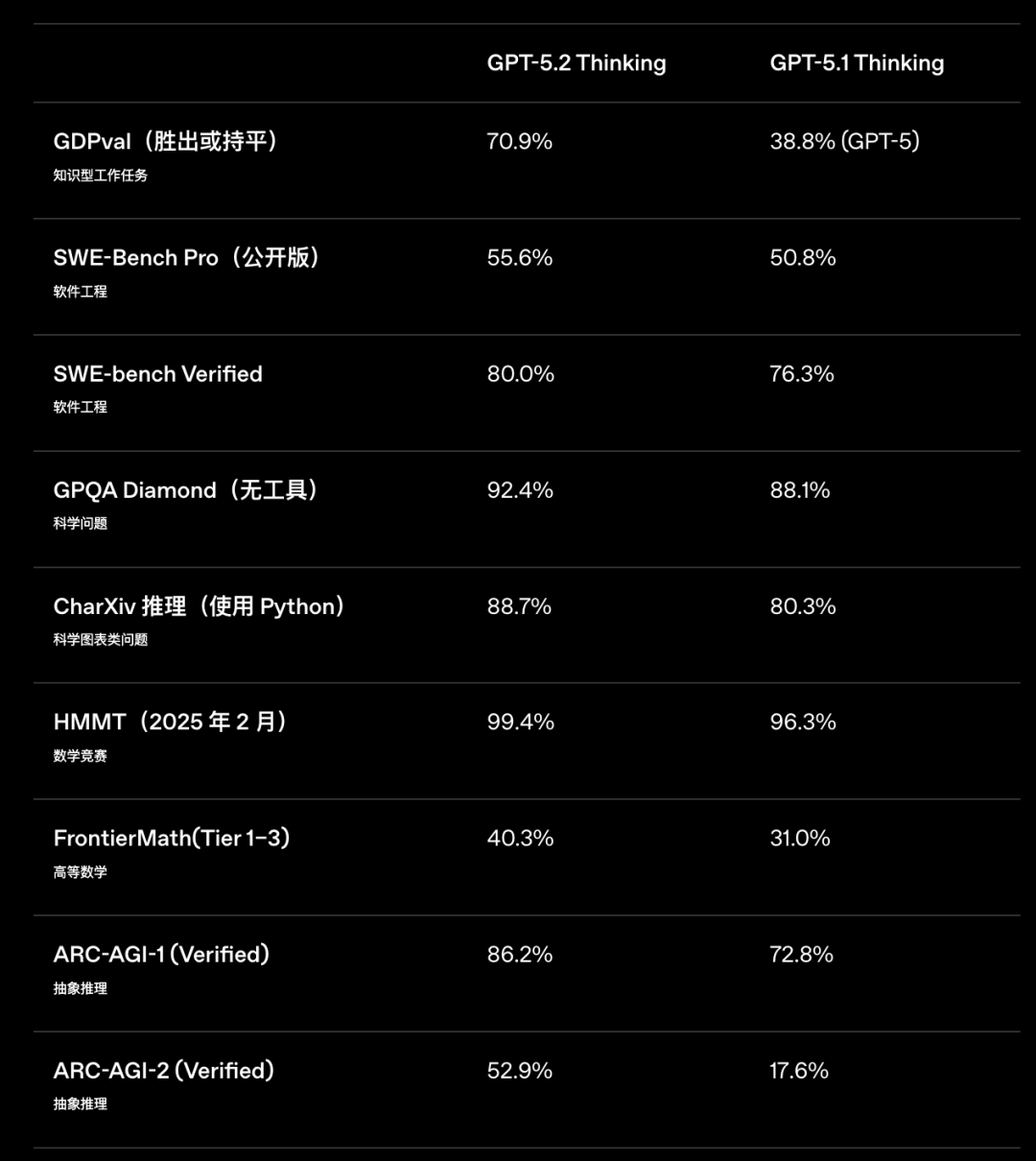
无论是软件工程类(SWE-bench Pro 从 50.8% → 55.6%,Verified 从 76.3% → 80.0%),还是抽象推理(ARC-AGI-2 从 17.6% → 52.9%,直接翻了三倍)。
又或者数学竞赛(HMMT 从 96.3% → 99.4%,几乎贴近满分),都有明显拉升。我非常期待实测!
幻觉
"降低幻觉"这句话,大模型发布会已经喊了无数遍,但这次 GPT-5.2,总算拿出了点实打实的成绩。
OpenAI 这次专门上了一个叫 FoMo 的新评估基准,全名是 Foundational Model Hallucination Benchmark。
顾名思义,就是专挑你最容易张嘴就来的"伪知识"下手,看你能不能忍住胡说。
而 GPT-5.2 的表现是这样的:
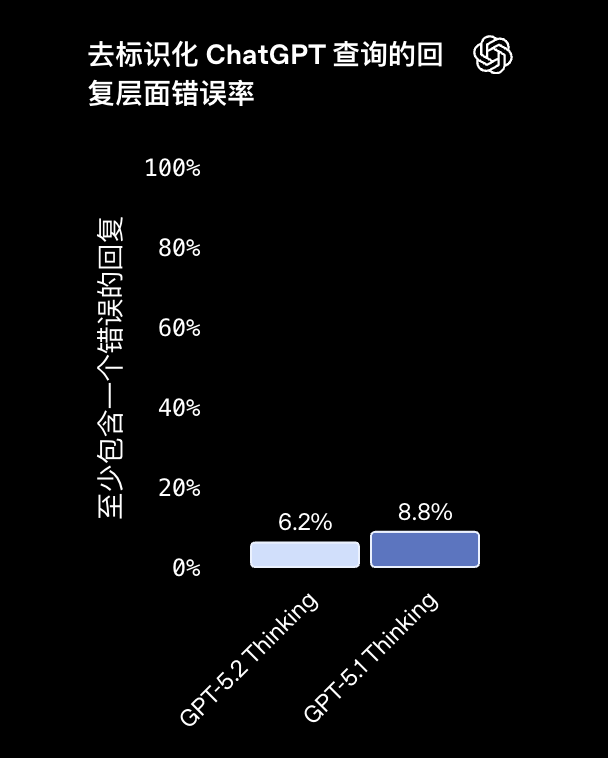
幻觉率降到仅 6.2%,相比 GPT-5.1 的 8.8%,下降了接近三成。
长上下文
你可能已经听烦了"长上下文"这个词,但 GPT-5.2 这次是真的把它从一个营销口号,变成了可以直接提升生产效率的硬实力。
GPT-5.2 Thinking 的上下文窗口达到 400,000 token(40 万),最大单次输出为 128,000 token。
注意,这里的「长上下文」不是读,是要求模型在极长文本范围内持续保持推理与指代一致性。
在一个评测叫 OpenAI MRCRv2 的测试中,研究团队设计了非常刁钻的任务:
把多个完全一样的问题(叫"针" needle)插入到一个巨长的聊天记录、知识库或报告堆里(叫"草堆" haystack),看模型能不能找到你说的是哪一个 needle 的哪一轮上下文。
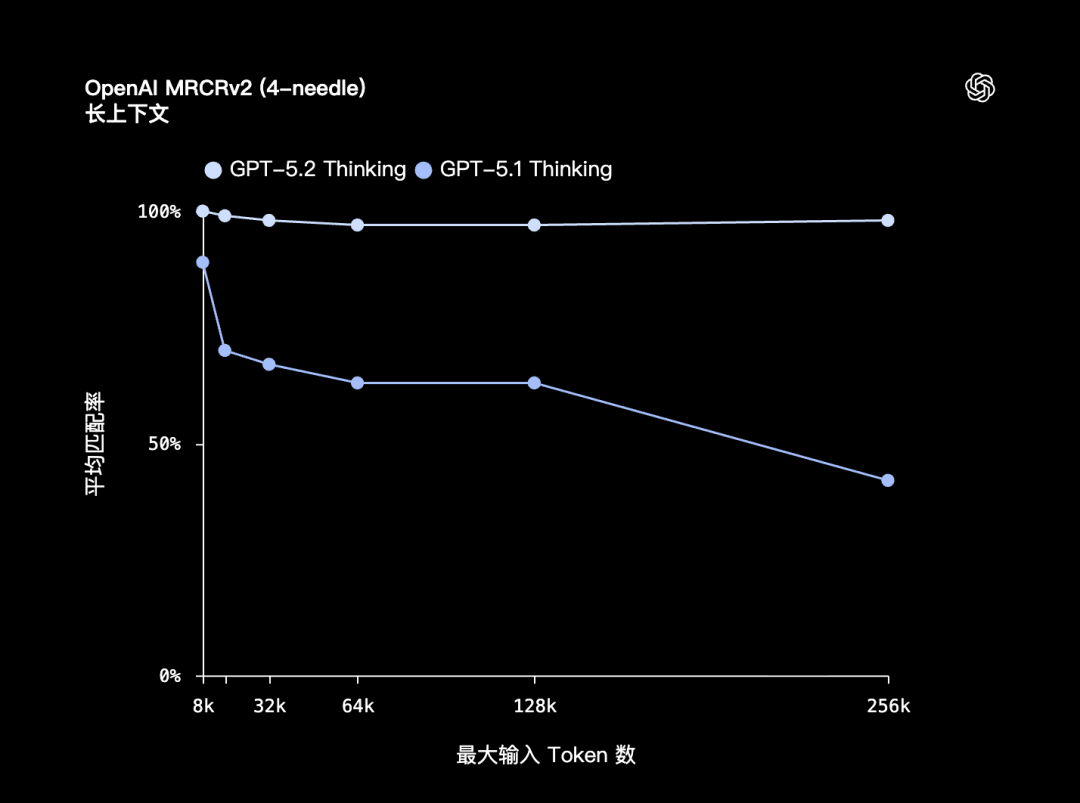
在 4-needle 测试中,GPT‑5.2 Thinking 在最长 256k token 情况下,准确率接近 100%。
而 GPT-5.1 版本一到 64k 以上就明显开始掉线,到了 256k 几乎断崖式下跌,匹配率直接腰斩。
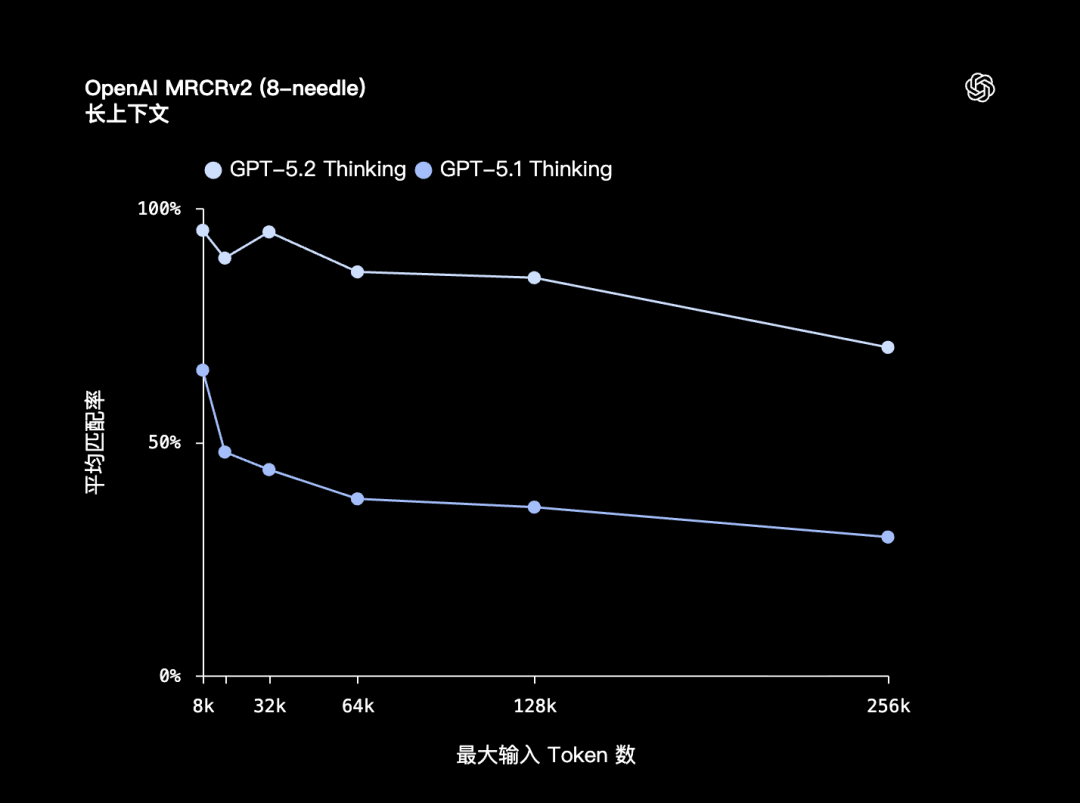
更残酷的 8-needle 版本,GPT-5.2 也依然稳住了:
图像理解
我们先看一个叫 ScreenSpot-Pro 的测试,专门测模型对截图界面的理解能力。比如一张软件界面图,按钮多、模块杂、文字还密,它得看得懂谁是谁、谁是干嘛的、谁和谁一组...很像客服系统、后台面板、APP 原型那些。
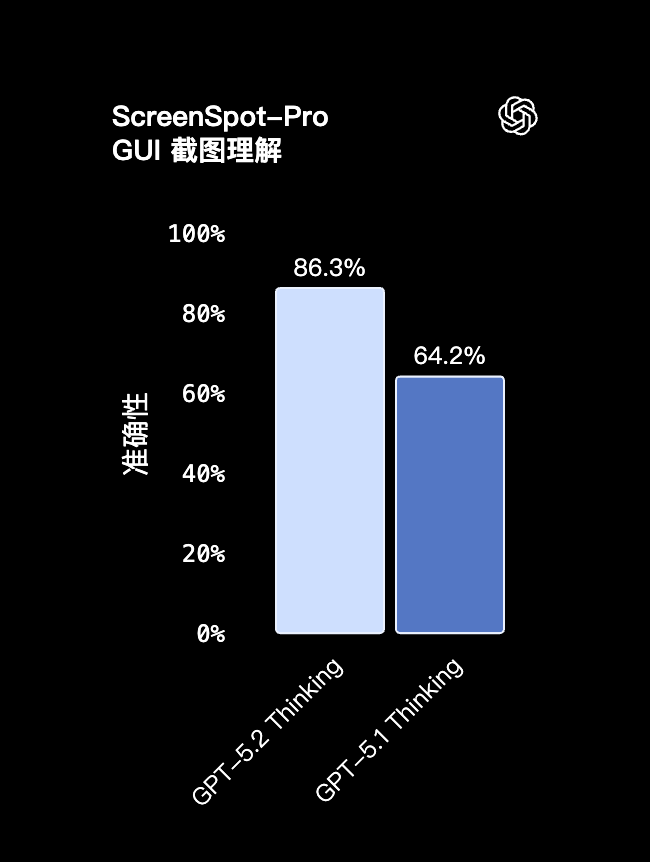
结果 GPT‑5.2 的准确率达到了 86.3% ,比 GPT‑5.1 的 64.2% 高出整整 22 个百分点。
而在更复杂的真实应用中,比如主板照片识别。
你丢一张像素不高的 PC 主板图过去,GPT-5.2 不仅能认出 CPU 槽、内存槽、VGA、HDMI,还能把它们的边界框标得有模有样。5.1 则还停留在"模糊打标签"的阶段:

定价
在 ChatGPT 应用里,GPT‑5.2 分成了三个版本,各有分工:

-
Instant:响应快,适合查资料、翻译、问路、写作这些任务;
-
Thinking:偏重逻辑复杂度和多步任务,适合写代码、看 PDF、算数学;
-
Pro:目前最强脑力,适合 Agent 多轮任务、复杂决策、跨文件任务等。
GPT‑5.2 Pro 和 GPT‑5.2 Thinking 还支持一个全新的推理强度档位:xhigh。
这是一个为"对质量要求极高"的任务专门设计的档位,比如写白皮书、分析科研数据、生成结构化图表脚本等等。这个档位目前只能在 API 里调。
讲了这么多新功能,你可能已经猜到了:价格,肯定涨了。
没错。
GPT‑5.2 的 API 定价,比 5.1 贵了接近 40% 到 70%。尤其是输出 token 成本,直接从 拉到了14(/百万 token),Pro 版本更是从 涨到168。
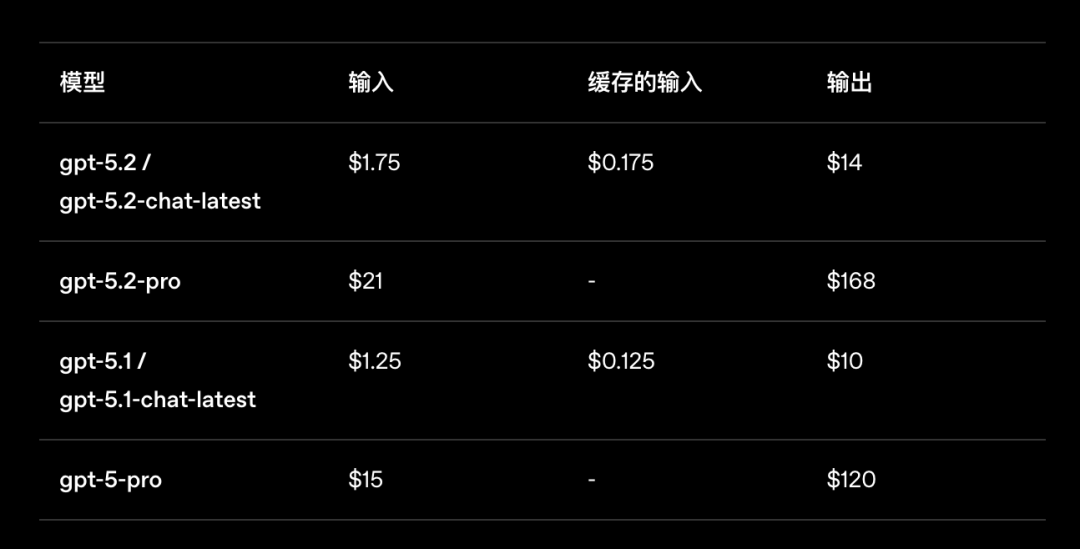
但这里面也有一条重要的补偿线索:GPT‑5.2 的 token 利用率大幅提升。用 OpenAI 官方的说法:"完成质量更好,token 更少,实际成本下降。"
举个实际例子,如果你用 GPT‑5.1 输出一篇 1000 字技术文档,可能需要 2000 个输出 token。而 GPT‑5.2 只需要 1300 个就能表达得更精确、逻辑更清晰。虽然单价更高,但总账算下来,可能还更便宜。
至于,大家都期待的「成人模式」,奥特曼也说正在提上日程,估计很快了。
我们这边也已经拿到 GPT-5.2,正在紧锣密鼓地实测中,后续会有更详细的文章解读,家人们可以先蹲一波。
不过凌晨我也翻了翻 X 上网友的实测结果...
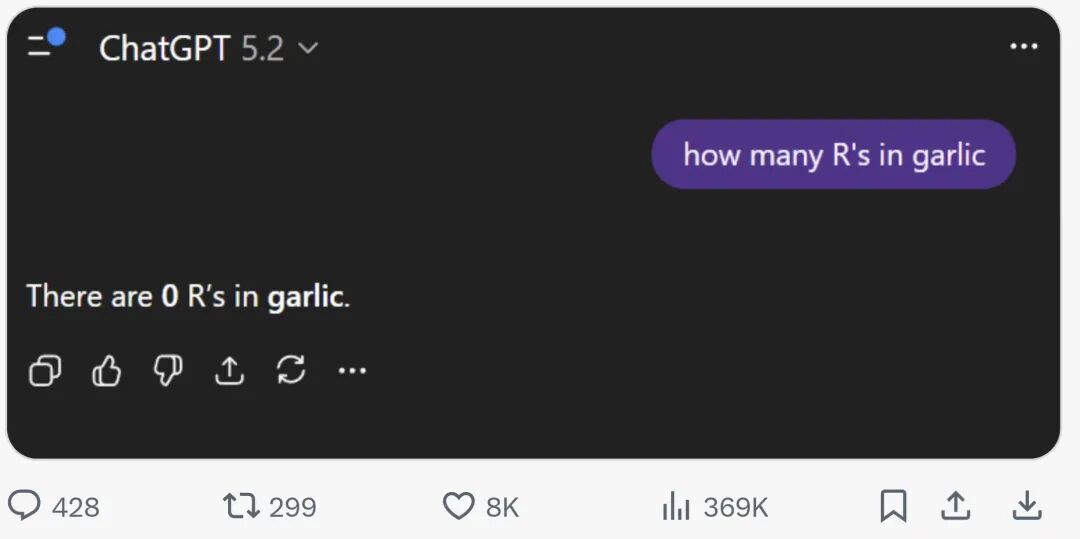
额。。