一、整体架构概览:三层体系
先看这张经典架构图(简化描述一下):
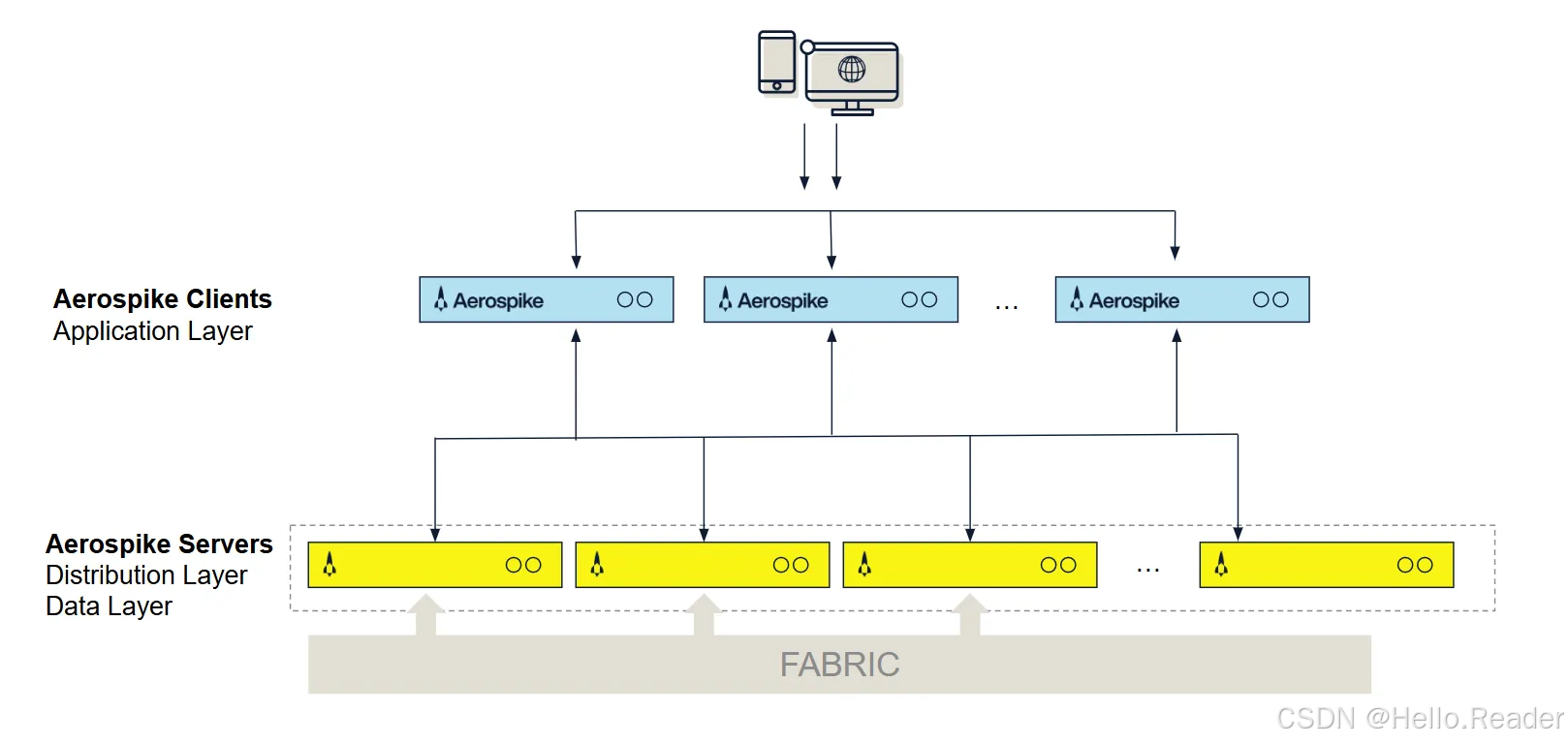
Aerospike 整体可以拆成三层:
-
Client Layer(客户端层)
- 由各语言的开源 SDK 组成
- 负责 API、路由、连接池、集群状态跟踪
-
Distribution Layer(分布层)
- 处理集群管理、数据分布、数据迁移、复制、一致性
- 对开发者完全透明
-
Data Storage Layer(数据存储层)
- 负责数据在内存、SSD、PMem 等介质上的高效存储
- 进行索引、淘汰、碎片整理等操作
一句话总结:"聪明的客户端 + 无中心的分布层 + 面向 SSD 优化的数据层"。
二、Client Layer:聪明的「有脑子」客户端
和很多只做「薄 SDK」的数据库不同,Aerospike 的客户端非常「重」,而且是**集群感知(cluster-aware)**的。
2.1 支持多种语言
Aerospike 客户端是开源链接库,目前主流语言都有:
- C / C++
- Java
- Go
- C#
- Python
- Node.js
......等
应用只需要通过 SDK 操作,不需要直接关心网络协议和路由逻辑。
2.2 客户端做了什么?
客户端层主要完成几件关键事情:
-
实现开发者 API 与协议
- 提供面向对象的读写接口
- 底层封装 Aerospike 自有的 client--server 协议
-
维护集群拓扑和 Partition Map
- 客户端会从集群中获取一份分区映射(partition map)
- 这份表中记录了每个分区(Partition)的主节点和副本节点
- 当集群节点增删时,客户端会立即更新这份映射
-
请求路由和重试
- 客户端会根据键的 hash,直接把请求发给真正持有数据的节点
- 不需要再通过代理或路由层,减少一次网络跳转
- 如果某个节点出现短暂错误,客户端会自动重试/重路由到其它副本
-
连接池管理
- SDK 内置 TCP 连接池
- 对开发者隐藏连接复用、超时、重连等细节
结果是什么?
- 应用不用自己做 sharding,不用维护路由表,不用改代码就能扩缩容。
- 路由逻辑从服务器搬到了客户端,从而减轻了服务端负担、降低延迟。
三、Distribution Layer:无中心、可线性扩展的分布式内核
Aerospike 的分布层基于「shared-nothing 共享无」架构,每个节点都是对等的,没有中心节点或元数据服务,从设计上避免了单点瓶颈。
这一层由三个模块组成:
- 集群管理模块(Cluster Management Module)
- 数据迁移模块(Data Migration Module)
- 事务处理模块(Transaction Processing Module)
3.1 集群管理:Paxos + Gossip 心跳
集群管理模块负责「集群里到底有谁」。
-
通过基于 Paxos 的投票 + gossip 协议来达成对节点列表的共识
-
使用主动 + 被动心跳来检测节点是否存活
- 主动:周期性发送心跳包
- 被动:通过正常业务流量推断节点是否健康
当有节点加入或离开时,集群会产生一次新的「视图」,客户端和各节点都会更新自己的视图和 partition map。
3.2 数据分区与迁移:4096 个 Partition + 算法分配
Aerospike 通过分布式 hash 算法将整个 key 空间划分为固定数量的分区(默认 4096 个),每个分区有:
- 一个 Master(主)节点
- 若干 Replica(副本)节点
可以用下面的示意表理解(简化版):
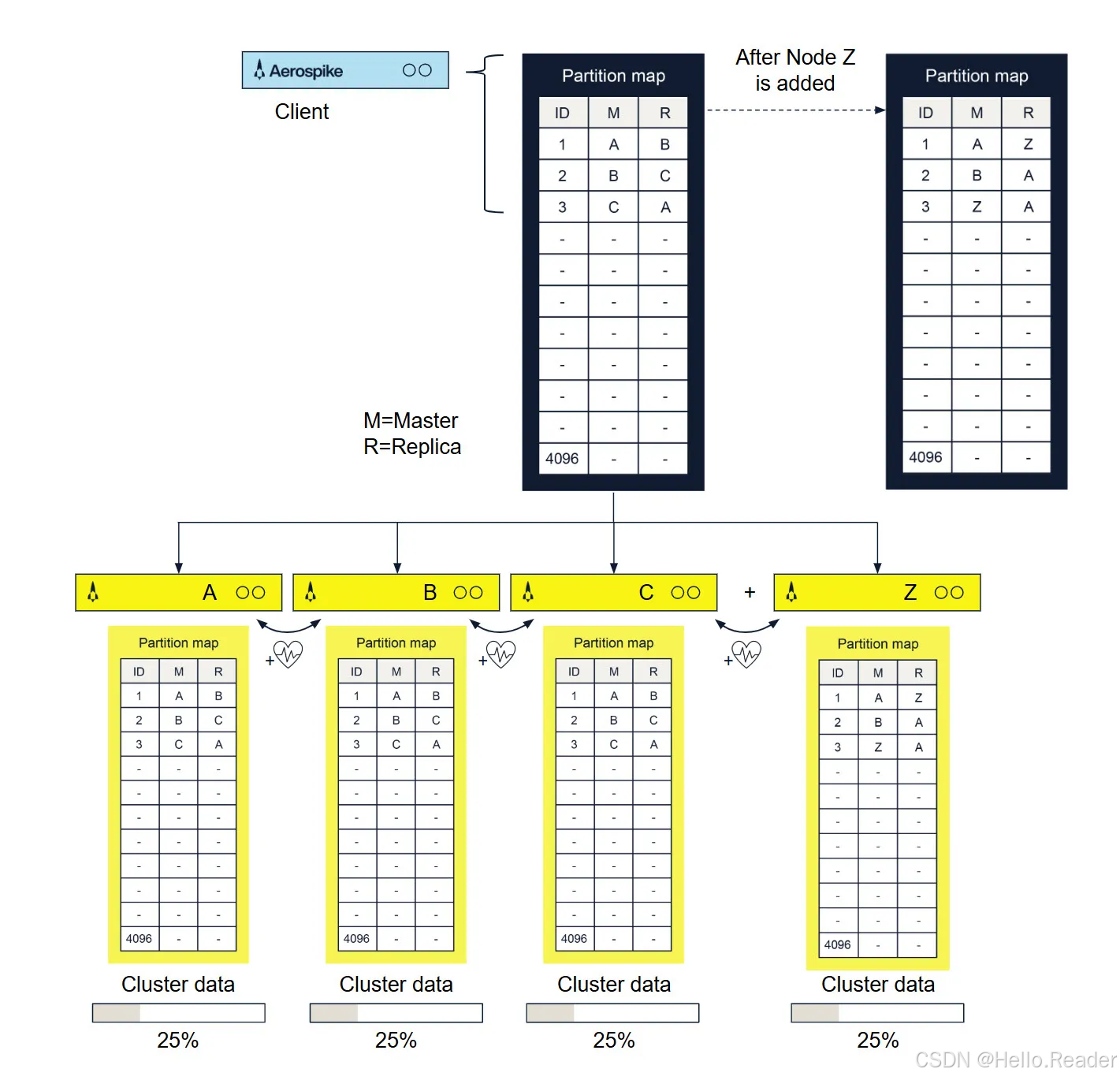
当新增节点时发生什么?
假设原来有 A、B、C 三个节点,现在加入一个新节点 Z。集群会:
- 重新计算分区分布,生成新的 partition map
- 部分分区的主/备会迁移到 Z,如:
text
原来:
1: M=A, R=B
2: M=B, R=C
3: M=C, R=A
加入 Z 后(示意):
1: M=A, R=Z
2: M=B, R=A
3: M=Z, R=A- 在后台异步完成旧节点 → 新节点的数据迁移
- 客户端在迁移过程中通过 partition map,始终能把请求发到正确节点
关键点:
- 分区划分完全由算法决定,无需手工配置分片规则
- 拓扑变化时,系统会自动再平衡(rebalance),运维只需要加/减节点即可
3.3 事务处理:一致性 & 复制 & 冲突解决
事务处理模块负责处理所有读写请求,提供数据一致性保证,主要包括:
-
同步/异步复制
- 对要求强一致的写操作,主节点会先将更新同步给所有副本,全部成功后才向客户端返回
- 对延迟敏感或可以接受弱一致的场景,可以配置异步复制策略
-
请求代理(Proxy)
- 在集群拓扑刚发生变化、客户端路由信息还没完全更新的极短时间窗口里
- 如果请求仍打到旧的节点,该节点会自动代理请求到真正拥有数据的节点
- 对应用来说完全透明
-
数据冲突解决
-
当网络分区/节点恢复时,可能存在「同一条记录有多个版本」的情况
-
Aerospike 提供两种冲突解决策略:
- 基于代数(generation count)
- 基于最后更新时间(last update time)
-
四、Data Storage Layer:面向 SSD 优化的多模型存储引擎
数据层是 Aerospike 的核心价值所在,它既可以「全内存模式」,也可以在SSD / NVMe / PMem 上以极高效率运行。
4.1 数据模型:Namespace / Set / Record / Bin
Aerospike 是一个多模型 存储(Key-Value、文档、图),内部采用灵活 schema(flex-schema):
-
Namespace
- 类似 RDBMS 里的「数据库」
- 是配置和资源隔离的基本单位(存储介质、复制因子等都按 Namespace 配置)
-
Set
- 类似「表」,用于对同一 Namespace 中的数据进行逻辑分组
- 不必预先定义,可以在运行时直接使用
-
Record
- 类似「行」,每条记录有一个在 Set 中唯一的Key
-
Bin
- 类似「列」,存放具体的字段值
- Bin 本身不强制类型,不同记录同名 Bin 可以是不同类型
- Bin 中的值是强类型的(String、Integer、List、Map 等)
特别注意:
- Set、Bin 都无需预先建表,应用写入时自动创建
- 这让 schema 演进非常简单(加字段 = 直接开始写)
4.2 索引与数据存放位置
Aerospike 把记录拆成索引 + 值两个层次:
-
Primary Index(主索引)
- 默认存放在 DRAM 中,提供极快的定位
- 也可以配置在 Persistent Memory 或 NVMe 上节省成本
-
Secondary Index(可选二级索引)
- 同样通常放在内存,以加速按某些字段的查询
-
Value(记录值)
-
可以在 DRAM、SSD、NVMe 上存储
-
每个 Namespace 都可以独立配置存储介质:
- 小而高频的数据:全部放内存,替代缓存层
- 大而冷一点的数据:放 SSD,降低硬件成本
-
4.3 针对 Flash 的优化:日志结构 & 大块写入
为了充分发挥 SSD 的优势、降低写放大,Aerospike 自己实现了一套日志结构文件系统,具有以下特点:
-
顺序大块写
- 把多个小写合并成大块顺序写,减少 SSD 内部的 GC 压力
-
绕过传统文件系统
- 传统文件系统是为机械盘设计的,对 SSD 不够友好
- Aerospike 的写入路径是「原生多线程多核 + 自己的日志结构」,最大化吞吐
-
键的存储极度紧凑
- 1 亿条记录只需要几 GiB 的索引内存
- 10 亿 keys 仅约 64GiB 集群内存(每个 key 只占 64 字节存储)
4.4 Defragmenter & Evictor:空间回收组合拳
为了保证空间和性能,数据层有两个后台「扫地僧」:
-
Defragmenter(碎片整理器)
- 统计每个 block 中的有效记录数
- 当利用率低于阈值时,把残余有效记录搬走,回收整个 block
-
Evictor(淘汰器)
- 根据记录的过期时间(TTL)和高水位阈值,删除过期或低价值数据
- 每条记录在最后修改时会记录 age,系统按 Namespace 维度控制生命周期
- 应用也可以指定「永不过期」的记录
这套机制保证:
- 始终有空间可写
- 不会因为碎片严重导致性能崩溃
- 在达到高水位线前就开始主动淘汰,避免「一刀切」式抖动
五、运维视角:如何「操作」Aerospike
和传统 RDBMS 不同,Aerospike 把很多 DBA 的工作迁移到了配置 + 应用侧,运维主要关注:
5.1 配置 Namespace 就是「建库」
在 Aerospike 中,数据库 = Namespace 配置。部署流程大致是:
-
在每个节点的配置文件中定义 Namespace:
- 存储介质(内存 / SSD / PMem)
- 复制因子(replication-factor)
- 冗余策略、过期策略等
-
重启节点后,集群自动根据配置创建数据库,不需要再执行手动建库建表 SQL。
-
修改 Namespace 的参数:
- 有些可以动态调整
- 部分需要重启节点加载新配置
5.2 扩容缩容:加减节点即可
当业务量上来,需要更多容量或更高吞吐时,运维只需要:
-
加一台(或多台)新节点,配置同样的 namespace,加入集群
-
Distribution Layer 会自动:
- 更新 cluster membership
- 调整 partition map
- 在后台执行数据迁移 & 重新平衡
同理,如果要维护或下线节点,只需要:
- 标记节点下线 / 停止服务
- 集群自动把其负责的 Partition 迁移给其他节点
整个过程中,客户端通过最新的 partition map 进行路由 + Proxy 机制兜底,业务层通常无需下线,影响仅表现为短暂的迁移负载和少量延迟波动。
5.3 监控和容量规划
要把 Aerospike 跑稳,运维需要重点关注:
-
节点资源:CPU、内存、磁盘 IO、网络
-
Namespace 级别:
- 空间使用率、高水位线
- 迁移进度、复制状态
-
客户端:
- 超时、重试、连接数
官方提供了一系列工具与指标,可以接入常见监控系统(如 Prometheus + Grafana),并根据容量规划文档提前设计好 replication factor、存储介质和节点数量。
六、应用开发:把分布式复杂度交给 Aerospike
对开发者来说,Aerospike 的使用体验可以归纳为一句话:
「把它当成一个超快、自动分片的 KV/文档数据库来用」
6.1 开发姿势
典型流程如下:
-
选择语言 SDK(Java / Go / Python ...)
-
在应用中引入 Aerospike Client 依赖
-
在应用启动时初始化客户端(配置集群地址、超时、重试等)
-
使用 SDK 提供的 API 进行:
put/get/delete- batch / scan / query / UDF 等操作
客户端作为独立的线程或进程,持续维护 cluster state 和 partition map,保证每次访问都是「单跳读取」。
6.2 开发者不再需要做的事情
- 不用再写分库分表、路由、key 取模等逻辑
- 不用为扩容重写代码或重启服务
- 不必维护单独的缓存层(很多场景下可以直接用 Aerospike 作为主存储 + 高速访问)
七、总结
把这几层组合在一起,可以清晰地看到 Aerospike 的设计取向:
- Client Layer:让客户端变「聪明」,负责路由和连接管理,减轻服务器压力
- Distribution Layer:无中心 Paxos + gossip + 自动数据迁移,实现线上可插拔的线性扩展
- Data Storage Layer:为 SSD/PMem 优化的日志结构存储 + DRAM 索引,保证在 TB/PB 级别下仍能保持毫秒级延迟
对追求超低延迟 + 大规模 + 高可靠 的场景(广告投放、实时风控、推荐系统、用户画像、IoT 等),Aerospike 提供了一套工程上真正落地、运维成本低的方案。