目录
一、"风格魔法棒":Qwen-Image-i2L如何化繁为简?

🎬 攻城狮7号 :个人主页
🔥 个人专栏 :《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 阿里推出Qwen-Image-i2L开源工具
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言:AI绘画的"个性化"之痛
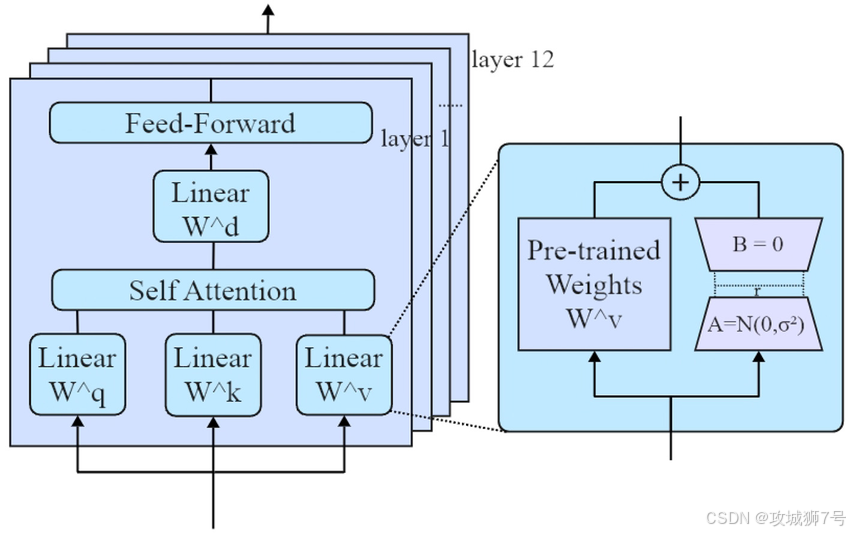
AI绘画技术发展至今,我们早已不再惊叹于它能画出什么,而是开始关心它能否"画出我想要的"。"个性化"成为了新的圣杯。在这个领域,LoRA(低秩适应)技术居功至伟,它允许我们在不动大模型主体的情况下,为其注入特定的画风、角色或元素。
然而,传统的LoRA训练流程,对普通人来说却是一场不折不扣的"折磨":
*** 数据之苦:**你需要准备至少20-50张高质量、风格统一的图片,并进行繁琐的预处理和打标签。
*** 硬件之痛:**普通家用电脑难以胜任,通常需要租用昂贵的云端GPU。
*** 时间之煎熬:**整个训练过程动辄数小时甚至数天,且结果充满不确定性,随时可能"炼废"。
这种高门槛,使得AI风格定制长期以来都是少数技术爱好者和专业团队的专利。大部分人只能被动地使用社区里现成的LoRA模型,而无法轻松地将自己独特的审美"教"给AI。
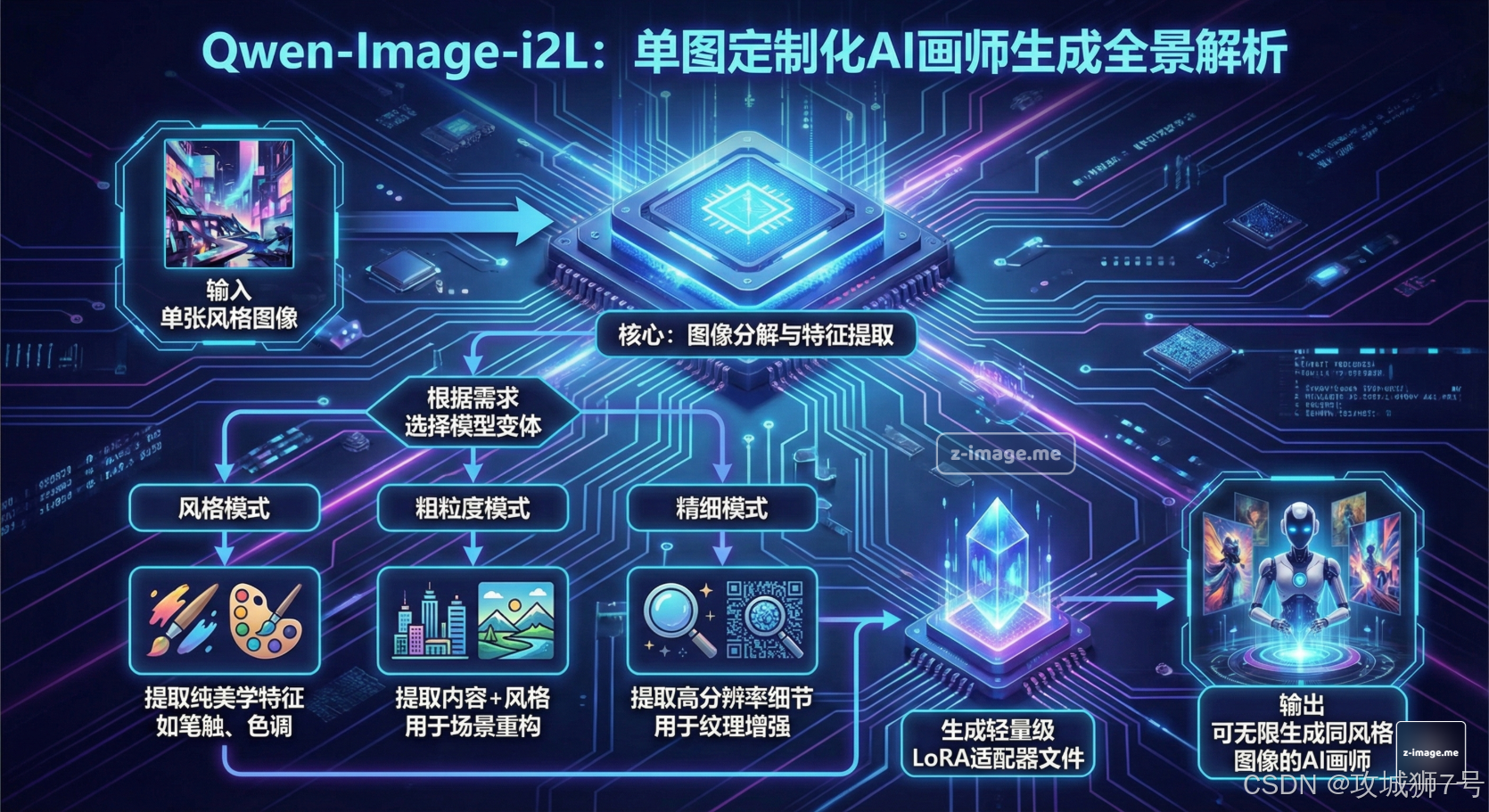

一、"风格魔法棒":Qwen-Image-i2L如何化繁为简?
Qwen-Image-i2L的核心理念,可以用一句话概括:Image to LoRA (i2L),即"从单张图片,生成一个LoRA模型"。它彻底颠覆了上述的传统工作流,将效率提升了百倍以上。
过去需要数小时完成的工作,现在最快只需2分钟。
过去需要几十张图片作为"教材",现在只需一张"范画"。
过去需要专业GPU集群,现在普通的游戏显卡即可胜任。
这背后并非魔法,而是一套精巧的**"风格拆解与重组"**技术。
当用户输入一张风格图片时,i2L会像一位经验丰富的艺术鉴赏家,利用多个强大的视觉编码器(如SigLIP2、DINOv3等),自动将图片分解为多个维度的"风格基因":
*** 颜色基调:**是明亮的糖果色,还是厚重的油画色?
*** 纹理笔触:**是细腻的水彩晕染,还是粗犷的版画刻痕?
*** 构图元素:**主体是如何布局的,画面有何种独特的构成感?
*** 内容信息:**图中画的是什么?是一只猫,还是一座山?
然后,i2L会将这些提取出的"风格基因"进行编码,并"压缩"成一个轻量级(仅几十到几百MB)的LoRA文件。这个文件就像一个乐高积木的"风格包",可以被即插即用地加载到任何主流的AI绘画工具(如Stable Diffusion WebUI、ComfyUI)中,与基础大模型协同工作。
从此,用户只需在提示词中简单调用这个LoRA,就可以让AI源源不断地生成蕴含了这张"范画"灵魂的新作品。
下图是一个通用LoRA架构示意图,Qwen-Image-i2L就是在此基础上添加图像输入层:
二、精准施法:满足不同需求的四款"魔杖"
i2L的强大之处,还在于它并非一个"一刀切"的工具,而是像一个工具箱,提供了四款针对不同创作需求的模型变体,让用户可以根据自己的目标选择最合适的"魔杖"。
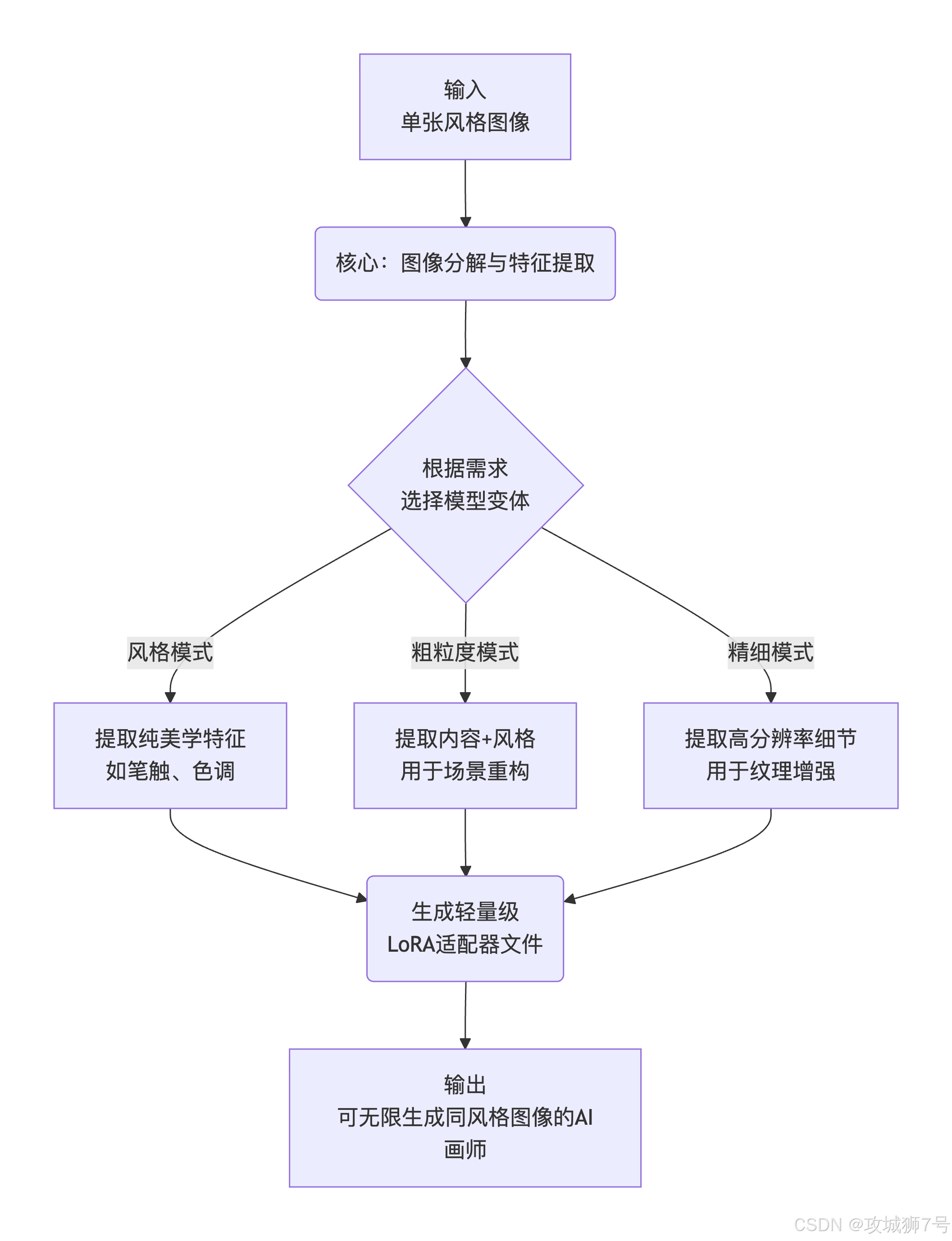
(1)风格模式 (Style):
*** 定位:**纯粹的"美学捕手"。
*** 特点:**它会最大限度地忽略原图的具体内容(画的是猫是狗不重要),而专注于提取其最纯粹的艺术风格------笔触、色调、光影氛围。
*** 适用场景:**想学习梵高《星月夜》的漩涡笔触,并将其应用到一张现代城市的照片上;或者想复制某种特定动漫的赛璐珞画风。
(2)粗粒度模式 (Coarse):
* 定位:"场景改造师"。
*** 特点:**它在提取风格的同时,也会捕捉原图的大致内容和构图。
*** 适用场景:**想将一张白天的街道照片,整体改造为充满霓虹灯的赛博朋克夜景;或者将一张普通的风景照,重构为充满幻想色彩的童话世界。
(3)精细模式 (Fine):
* 定位:"细节雕刻家"。
*** 特点:**这是"粗粒度模式"的增强补丁,专注于捕捉和生成1024x1024级别的高分辨率细节。它必须与粗粒度模式搭配使用。
*** 适用场景:**当需要特别突出动物的毛发、建筑的砖墙纹理、或衣物的织物细节时,这个模式能带来质的飞跃。
(4)偏见模式 (Bias):
* 定位:"品牌视觉总监"。
*** 特点:**这是一个极轻量(仅30MB)的"校准器"。它的作用是修正生成结果,使其在整体风格上更贴近Qwen-Image基础模型原生的视觉风格。
*** 适用场景:**对于需要大规模产出视觉素材的企业来说,这个模式至关重要。它可以确保所有AI生成的图片,都严格符合品牌的VI(视觉识别)规范,避免出现风格"跑偏"的问题。
这种模块化的设计,极大地提升了i2L的灵活性和专业性,让无论是追求艺术感的个人创作者,还是注重规范性的商业团队,都能找到最适合自己的解决方案。
三、从"炼丹师"到"指挥家":对创作者意味着什么?
Qwen-Image-i2L的出现,其意义远不止于"提效降本",它从根本上改变了创作者与AI之间的关系。
(1)创作流程的颠覆:从"重投入"到"轻试错"
过去,训练一个LoRA是一项"重决策",因为试错成本太高。而现在,创作者可以进行海量的"轻试错"。看到一张喜欢的插画,随手就能将其风格提取出来,应用到自己的作品中看看效果。这种即时反馈的创作流程,极大地激发了创意的碰撞和融合。设计师可以快速地为同一个产品生成十几种不同风格的宣传图,并从中挑选最优方案。
(2)审美资产的积累:人人都能建立自己的"风格库"
i2L让"风格"变成了一种可以被轻松捕捉、存储和复用的"数字资产"。每个创作者都可以将自己喜欢的图片、自己的摄影作品、甚至自己随手画的草图,转化为一个个专属的LoRA文件,逐步建立起一个庞大的个人"风格素材库"。在未来的创作中,这些积累下来的LoRA将成为其最宝贵的创意源泉。
(3)创作角色的转变:从"炼丹师"到"指挥家"
当繁琐的技术操作被AI自动化后,创作者得以从"炼丹师"的角色中解放出来,真正回归到"艺术指挥家"的身份。他们不再需要关心如何配置参数、如何清洗数据,而是可以将全部精力投入到更高维度的创意构思中------思考什么样的风格与什么样的内容结合,才能产生最动人的化学反应。
四、理性看待:局限性与未来的可能性
当然,Qwen-Image-i2L也并非完美无缺的"魔法"。其当前的局限性主要源于"单图信息"的有限性:
**3D逻辑的缺失:**从一张2D图片,很难推断出物体的完整三维结构。因此,用一张"猫的正面照"训练出的LoRA,在生成"猫的背面"时,可能会出现不合逻辑的结构。
**复杂细节的丢失:**对于一些极其复杂、充满细节的风格(如繁复的巴洛克式雕刻),单张图片可能不足以承载其全部信息,仍需要多图训练来达到最佳效果。
然而,瑕不掩瑜。Qwen-Image-i2L最大的价值在于,它为所有人提供了一个"快速验证"的通道。在决定是否要投入更大成本进行多图训练之前,可以先用一张代表性图片快速生成一个LoRA原型,来判断这个风格方向是否值得深入。
结论:AI绘画,正式进入"即时定制"时代
Qwen-Image-i2L的开源,是AI绘画领域"民主化"进程中的一个重要里程碑。它用极致的效率和极低的门槛,将曾经属于少数派的"风格定制权",真正交到了每一个普通用户的手中。
这预示着,AI绘画的竞争焦点,正从比拼谁的模型更大、谁的画质更高,转向比拼谁能提供更便捷、更个性化的创作体验。一个全新的"即时定制"时代已经到来,在这个时代,每个人的独特审美,都有可能成为驱动AI画笔的下一个"风格引擎"。
资源链接
* ModelScope: `https://modelscope.cn/models/DiffSynth-Studio/Qwen-Image-i2L\`
* Hugging Face: `https://huggingface.co/DiffSynth-Studio/Qwen-Image-i2L\`
* 项目代码 (DiffSynth-Studio): `https://github.com/modelscope/DiffSynth-Studio\`
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!