过去两年里,AI 的"幻觉"(hallucination)问题成了最热门的技术话题之一。
像昨天发布的 GPT-5.2 Thinking 中也提到,最新版本的实时性错误测试又减少了 30% 。
从 ChatGPT 自动编造引文、到 Gemini 生成历史上从未发生过的事件,人们不断发现------模型越强大、输出越流畅,它仍然可能一本正经地胡说八道。
这就引发一个越来越尖锐的问题:
为什么明明参数上万亿、推理链更长、检索系统更精密,AI 仍然改不掉"编造"的毛病?
难道"零幻觉"永远无法实现吗?
答案是------是的。
不仅根除不了,而且它可能是一种智能体存在的代价,是一种"宿命",但这并不意味着我们无能为力。
这篇文章带你从大模型原理上真正理解为什么"零幻觉"永远无法实现,但"可信 AI"仍然值得追求。
如果你也对这个方向感兴趣,推荐文章最后的延伸阅读,整理了论文资料。
为什么我会说"幻觉是宿命"?
要理解 AI 幻觉无法根除,必须先理解大模型的本质。
1. 大模型不是知道世界,它是在预测语言
当前主流大语言模型(LLM)使用的是所谓的自回归语言生成机制------本质上是在做概率预测:
给定前文上下文,预测下一个最可能出现的词或令牌。
换句话说,这些模型并不是"理解世界",而是预测语言的统计分布:
模型最优化的目标不是事实准确性,而是让输出看起来与训练语料一致、顺滑、连贯。
因此,当模型面对一个它训练数据中并不熟悉或缺失的信息时------它并不会说"我不知道",而是会根据统计模式生成最可能、最连贯、最像正确答案的文字------这就是所谓的幻觉产生的机制。
这就像一个熟读百科全书的人,在被问到一本他没读过的新书时,本能地"编"出一个似是而非的剧情。
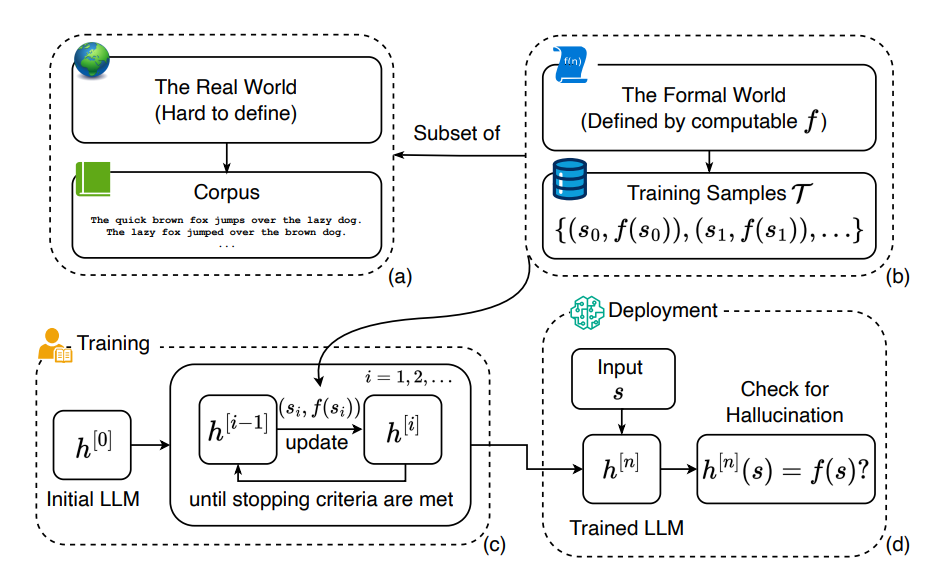
2. 这与当前主流训练机制密切相关
现阶段的大模型训练主要包含两步:
- 无监督预训练:让模型在海量文本上学习语言规律;
- 有监督或强化学习微调:在特定任务上优化表现。
但当前流行的训练与评估机制存在一个隐蔽问题:准确性不等同于流畅性和表现得像对。
最新研究指出,现有的训练和评估往往奖励模型猜测而不是承认不确定性。
这使得模型在面对未知时倾向于"自信输出",因为这样的行为在训练评价指标上更可能被视为高分表现,而非说"我不知道"。
换句话说,训练机制本身就驱动模型去填补缺失信息、产生自信回答,从而在本质上鼓励了"幻觉"。
这也是为什么即使当前大型模型不断优化、参数越来越多,它仍旧会出现幻觉。

Scaling Law 为什么无法消灭幻觉?
许多人以为"再堆更多数据和参数"就能解决幻觉。
但 Scaling Law 本身告诉我们:参数规模增加带来的提升主要是预测能力提升,而非真实性提升。
关键点有三:
1. Scaling 提升 pattern completion,而不是 factual grounding
模型变强 → 更会"补全模式" → 幻觉可能更像真的
但它并没有获得新的"真实性判断模块"。
2. Scaling 不改变训练 objective
如果目标仍然是"预测下一个 token",
那哪怕是无限大模型,也会根据概率选择最像答案的字符串,而不是最真实的答案。
3. Scaling 无法填满知识空间
真实世界的信息是无限的,而训练数据是有限的。
任何 finite model 都会遇到信息缺口 → 进而发生补全 → 进而出现幻觉。
幻觉是统计智能的不可避免副产品
"幻觉并非技术 bug,而是概率模型的结构性特征。"
无论模型规模多大,只要它是通过统计和预测语言生成输出的,就存在非零概率输出不真实、未验证或错误内容。例如:
- 检索增强(RAG)能提升可验证性,但不能完全根绝幻觉,因为模型仍可能混合解释检索结果或补全细节。
- 即便有外部知识库辅助,检索阶段可能召回不良/误导性信息、模型可能错误融合信息、最终输出仍可能"自圆其说"。
科学界的最新论文甚至认为:即便改变生成策略,"幻觉"仍然是当前架构下的必然现象而不是偶发错误。
型结构本身并不具备真实世界的"认知根基",它只能在语言概率空间中构造文本。
人类也有"幻觉",但我们有修正机制
如果我们仔细想想,其实人类也很难做到完美真实。
- 人类视觉系统会被错觉欺骗;
- 记忆会被重构;
- 我们可能把错误信息记成事实。
但人类社会通过一系列 集体性纠错机制 来逼近真实:
- 科学依赖同行评审;
- 新闻需要多方核实;
- 法律体系需要证据链。
换句话说,人类并不是比 AI 更会避免错误,而是更会修正错误。
我们不是靠单个认知体做到"零错误",而是靠整个社会的校验机制逼近真相。
而现在的 AI------尤其是孤立运作的模型------并没有规范的这种社会性纠错机制,各种思考模型正是在做这件事。
我们要求单一系统"永不出错",其实是在要求一个孤立的模型完成整个人类文明的纠错功能------这是不现实的。
"零幻觉"是理想但不是现实
当我们提问:"只要把模型训练得足够大、数据足够全面、检索辅助做到极致,为什么不能实现'零幻觉'?"
这个问题点在于:
- 数据不可能涵盖全部现实知识:模型仍会有知识边界、时间截止点等限制。
- 统计性目标无法等同逻辑真理:语言模式与事实一致性不是同一回事。
- 评估指标仍然偏重流畅性:鼓励生成看起来像正确答案的输出,而不是在不确定时拒绝生成。
因此理论上而言,没有任何单一、有限参数的模型能够覆盖真实世界全部可能性。
模型能逼近分布,但无法保证真实世界的全程准确性。
从"消灭幻觉"到"管理幻觉"
既然幻觉不能根除,我们的目标必须转向如何管理幻觉、提高输出可信度。
可信 AI 应该具备以下特征:
-
可验证(Verifiable)
输出结果应标注来源、引用证据或支持数据。
-
可解释(Explainable)
输出背后的推理路径透明、可审计。
-
可追溯(Traceable)
输出的逻辑链可以回溯到训练/检索/记忆来源,避免不透明补全。
-
可协同(Collaborative)
不同模型、不同推理框架之间可以共识、人机协同校验。
换句话说,我们需要建立起类似新闻审核、科学实验验证那样的AI认知社会:人类与机器、多模型之间互相校验、制衡与纠错。
写在最后
从哲学角度看,幻觉的存在并不可怕。
它其实体现了智能体在面对未知时试图生成解释的能力,这正是"理解"的起点。
真正的问题不是幻觉本身,而是:
当幻觉出现时,我们能否识别、追溯并修正它?
人类文明正是从错误中成长的,而 AI 也需要这样的学习/修正机制。
延伸阅读
理论基础:幻觉为何不可避免?
-
Hallucination is Inevitable
- 作者:Ziwei Xu et al.(新加坡国立大学,2024)
- 内容:用计算理论与学习理论证明,大模型在原理上无法避免输出幻觉。
- 链接:arXiv:2401.11817
-
Why Language Models Hallucinate
- 作者:Adam Kalai et al.(OpenAI & 佐治亚理工,2025)
- 内容:统计角度分析,当前的 sampling 与 loss 驱动会促使模型"猜一个听起来对的答案"。
- 链接:arXiv:2509.04664
-
On the Fundamental Impossibility of Hallucination Control
- 作者:Michał Karpowicz(三星 AI 中心,2025)
- 内容:将幻觉与"创造力"视为知识融合的副产品,从机制设计角度论证无法完全控制。
- 链接:arXiv:2506.06382
训练机制相关研究(Scaling Laws 与幻觉)
- Scaling Laws for Neural Language Models
- 作者:Kaplan et al.(OpenAI, 2020)
- 内容:开创性地提出大模型性能随着训练规模扩展呈幂律增长。
- 链接:arXiv:2001.08361
- The False Promise of Imitating Proprietary LLMs
- 作者:Choromanski et al.(DeepMind, 2023)
- 内容:指出 open 模型通过模仿闭源模型,无法消除幻觉,反而加剧不稳定性。
- 链接:arXiv:2309.00666
- Language (Un)Modeling: Modeling Itself Causes LLM Hallucinations
- 作者:Zhang et al.(Stanford, 2024)
- 内容:证明了语言建模本身(language modeling objective)诱发幻觉的结构性来源。
- 链接:arXiv:2403.00917
工程治理与可信 AI 方向
- Self-Refine: Iterative Refinement with Self-Feedback
- 作者:Madaan et al.(UPenn + Meta AI, 2023)
- 内容:提出模型自我反思机制(Self-Refine)作为减少幻觉的手段。
- 链接:arXiv:2303.17651
- Toolformer: Teaching LLMs to Use Tools
- 作者:Schick et al.(Meta AI, 2023)
- 内容:将模型与外部 API/工具结合以降低幻觉概率。
- 链接:arXiv:2302.04761
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- 作者:Lewis et al.(Facebook AI, 2020)
- 内容:首次系统化提出 RAG 框架,用外部检索缓解幻觉。
- 链接:arXiv:2005.11401