当你问 AI "什么是人工智能?"时,它真的"读懂"了这几个字吗?其实,AI 根本不理解文字的含义 ------在它眼里,没有"苹果""爱情"或"代码",只有冰冷的数字。为了让机器能处理语言,我们必须先把文本转换成它能"看懂"的形式:向量 (Vector)。这个过程,就叫Embedding(嵌入)。它正是让 AI 拥有"语义理解"能力的幕后英雄。
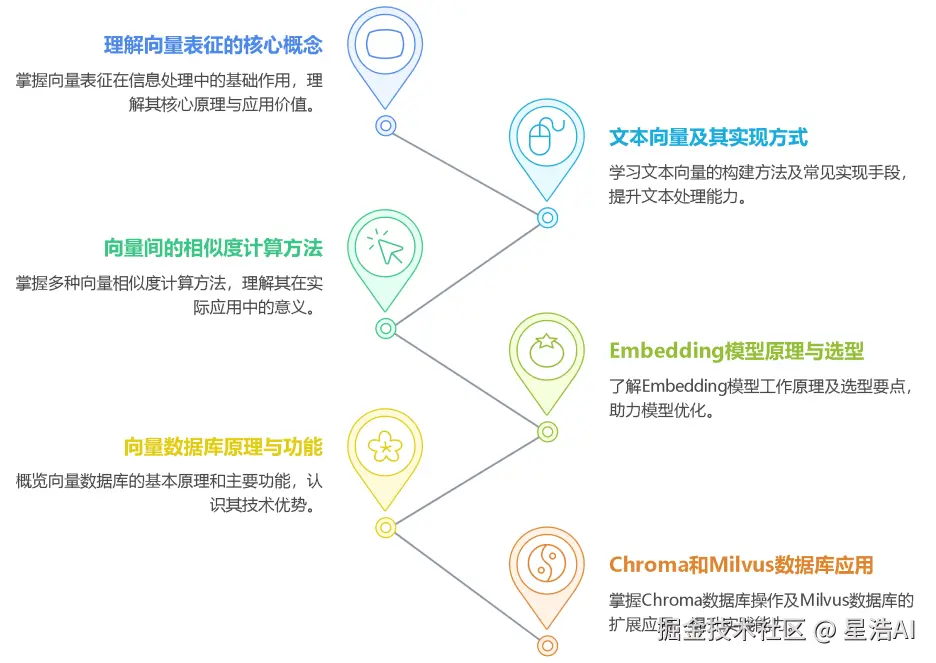
那么,向量到底是什么?文本如何变成向量?又该如何高效管理和检索它们?带着这些问题,我们一起系统梳理以下核心内容:
-
理解向量表征
-
文本向量的本质
-
向量间的相似度计算
-
Embedding 模型原理与选型指南
-
向量数据库原理、功能、实战(后面章节介绍)
1. 向量表征(Vector Representation)
向量表征是人工智能领域的基础,通过将文本、图像、声音等复杂信息转化为高维向量(Embedding),为机器学习模型提供统一的数学描述方式,实现语义理解与处理。
1.1. 向量表征的本质
万物皆可数学化。
(1)核心思想
- 降维抽象
将复杂对象(如一段文字、一张图片)映射到低维稠密向量空间,保留关键语义或特征。
- 相似性度量
向量空间中的距离(如余弦相似度)反映对象之间的语义关联(如"猫"和"狗"的向量距离小于"猫"和"汽车")。
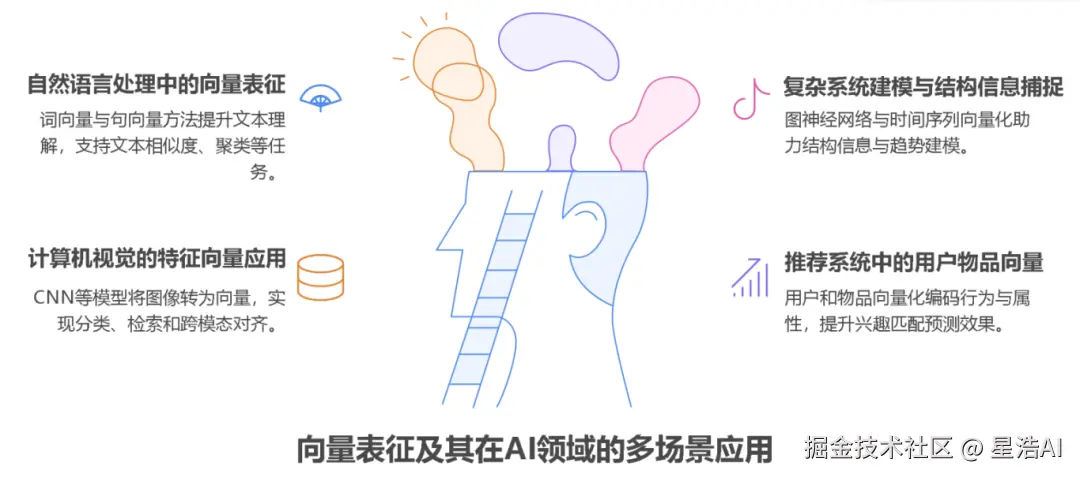
1.2. 向量表征的典型应用场景
(1)自然语言处理(NLP)
- 词向量(Word2Vec、GloVe) 单词映射为向量,解决"一词多义"问题(如"苹果"在"水果"和"公司"上下文中的不同向量)。
- 句向量(BERT、Sentence-BERT) 整句语义编码,用于文本相似度计算、聚类(如客服问答匹配)。
- 知识图谱嵌入(TransE、RotatE)
将实体和关系表示为向量,支持推理(如预测"巴黎-首都-法国"的三元组可信度)。
(2)计算机视觉(CV)
- 图像特征向量(CNN特征) ResNet、ViT等模型提取图像语义,用于以图搜图、图像分类。
- 跨模态对齐(CLIP)
将图像和文本映射到同一空间,实现"描述文字生成图片"或反向搜索。
(3)推荐系统
- 用户/物品向量
用户行为序列(点击、购买)编码为用户向量,商品属性编码为物品向量,通过向量内积预测兴趣匹配度(如YouTube推荐算法)。
(4)复杂系统建模
- 图神经网络(GNN) 社交网络中的用户、商品、交互事件均表示为向量,捕捉网络结构信息(如社区发现、欺诈检测)。
- 时间序列向量化 将股票价格、传感器数据编码为向量,预测未来趋势(如LSTM、Transformer编码)。
1.3. 向量表征的技术实现
(1)经典方法
- 无监督学习
Word2Vec通过上下文预测(Skip-Gram)或矩阵分解(GloVe)生成词向量。
- 有监督学习
微调预训练模型(如BERT)适应具体任务,提取任务相关向量。
(2)前沿方向
- 对比学习(Contrastive Learning)
通过构造正负样本对(如"同一图片的不同裁剪"为正样本),拉近正样本向量距离,推开负样本(SimCLR、MoCo)。
- 多模态融合
将文本、图像、语音等多模态信息融合为统一向量(如Google的MUM模型)。
- 动态向量
根据上下文动态调整向量(如Transformer的注意力机制),解决静态词向量无法适应多义性的问题
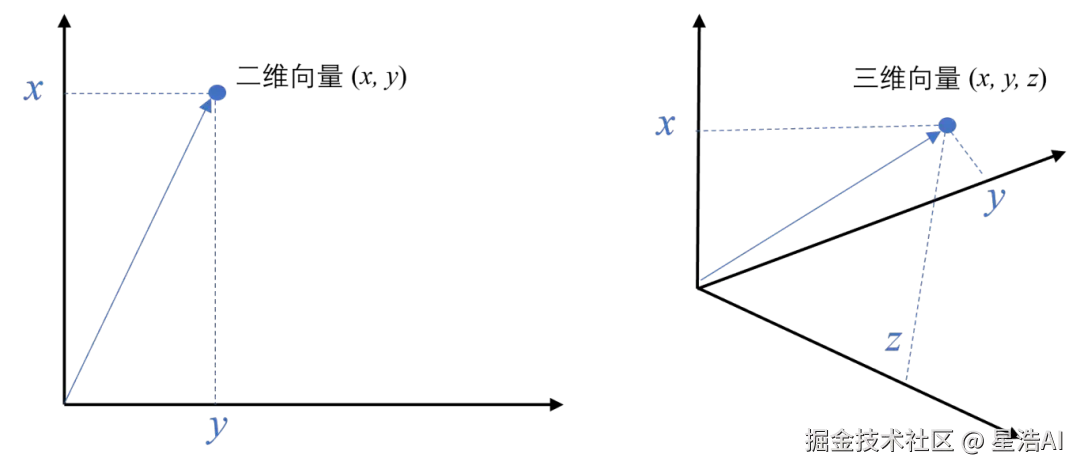
2. 什么是向量
向量是一种有大小和方向的数学对象。它可以表示为从一个点到另一个点的有向线段。例如,二维空间中的向量可以表示为 (x,y),表示从原点 (0,0)到点 (x,y) 的有向线段。
扩展阅读: www.sbert.net
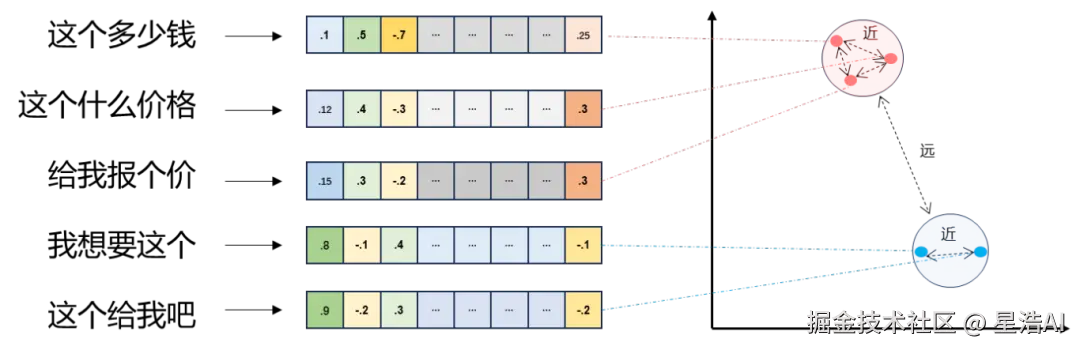
2.1 文本向量(Text Embeddings)
- 将文本转成一组 N 维浮点数,即文本向量又叫 Embeddings。
- 向量之间可以计算距离,距离远近对应语义相似度大小。
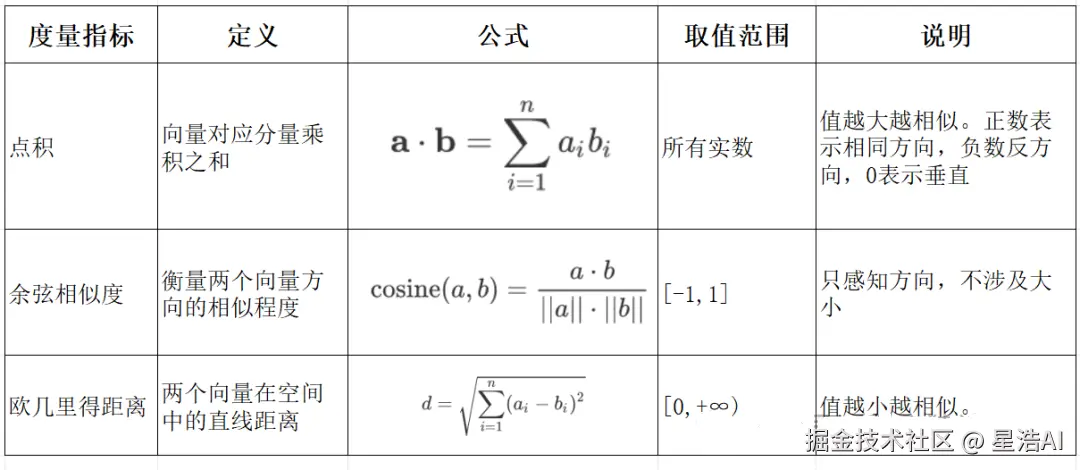
2.2向量间的相似度计算
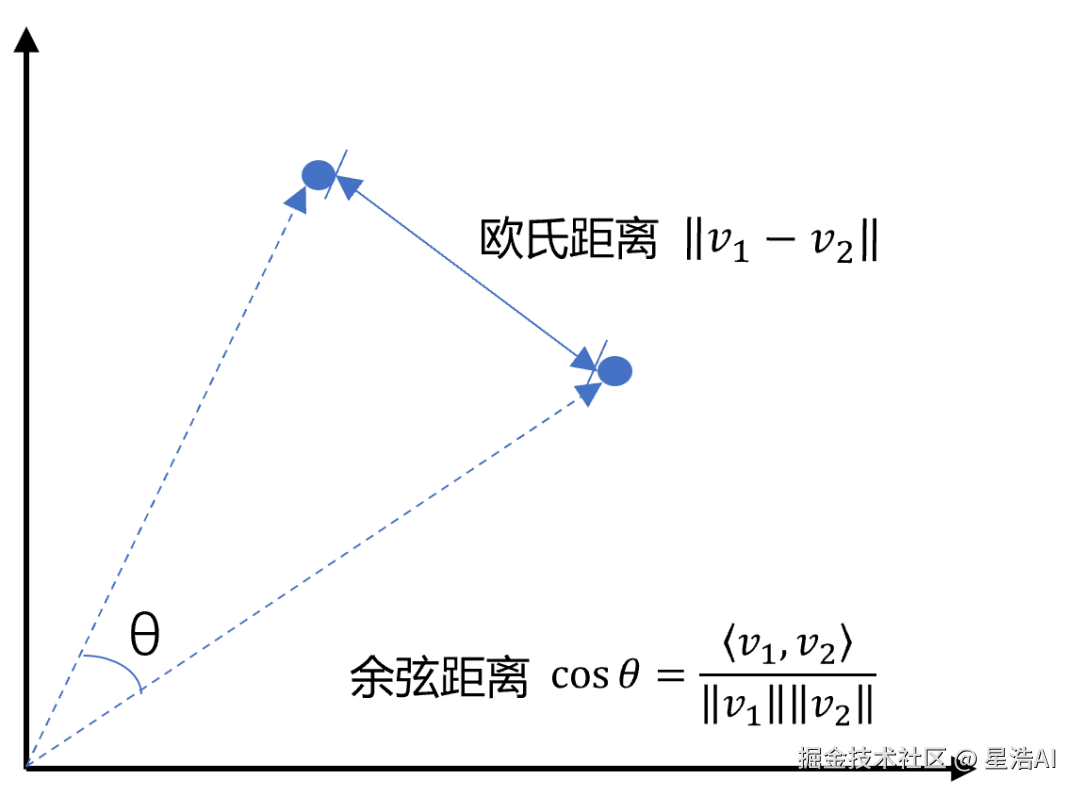 余弦相似度是通过计算两个向量夹角的余弦值来衡量相似性,等于两个向量的点积除以两个向量长度的乘积。
余弦相似度是通过计算两个向量夹角的余弦值来衡量相似性,等于两个向量的点积除以两个向量长度的乘积。
python
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"), # 如果您没有配置环境变量,请在此处用您的API Key进行替换
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 百炼服务的base_url
)示例:将文本转换为向量
python
import numpy as np
from numpy import dot
def get_embeddings(texts, model="text-embedding-v1", dimensions=None):
'''封装 OpenAI 的 Embedding 模型接口'''
if model == "text-embedding-v1":
dimensions = None
if dimensions:
data = client.embeddings.create(
input=texts, model=model, dimensions=dimensions).data
else:
data = client.embeddings.create(input=texts, model=model).data
test_query = ["一文搞懂Embedding与向量数据库"]
vec = get_embeddings(test_query)[0]
print(f"Total dimension: {len(vec)}")
print(f"First 10 elements: {vec[:10]}")示例:计算余弦相似度和欧氏距离
python
def cos_sim(a, b):
'''余弦距离 -- 越大越相似'''
return dot(a, b)/(norm(a)*norm(b))
def l2(a, b):
'''欧氏距离 -- 越小越相似'''
x = np.asarray(a)-np.asarray(b)
return norm(x)
python
# 查询:聚焦近期国际热点
query = "中东局势最新进展"
# 也可测试跨语言:query = "Latest developments in the Middle East"
documents = [
"以色列与黎巴嫩真主党在边境地区爆发新一轮交火,联合国呼吁立即停火。",
"中国外交部表示,支持通过'两国方案'和平解决巴以冲突,反对任何单边行动。",
"央行宣布下调存款准备金率0.25个百分点,释放长期资金约5000亿元以稳增长。",
"神舟二十号载人飞船将于12月初发射,航天员乘组已确定并完成全流程演练。",
"日本自卫队计划在西南诸岛新增导弹部署,中方对此表示严重关切。"
]
python
query_vec = get_embeddings([query])[0]
doc_vecs = get_embeddings(documents)
python
print("Query与自己的余弦相似度: {:.2f}".format(cos_sim(query_vec, query_vec)))
print("Query与Documents的余弦相似度:")
for i, vec in enumerate(doc_vecs):
print(f" 文档 {i+1}: {cos_sim(query_vec, vec):.4f}")
print()
python
print("Query与自己的欧氏距离: {:.2f}".format(l2(query_vec, query_vec)))
print("Query与Documents的欧氏距离:")
for i, vec in enumerate(doc_vecs):
print(f" 文档 {i+1}: {l2(query_vec, vec):.4f}")余弦相似度,值越大越相似;欧氏距离,值越小越相似。
3. Embedding Models 嵌入模型
3.1. 什么是嵌入(Embedding)?
嵌入(Embedding)是指非结构化数据转换为向量的过程,通过神经网络模型或相关大模型,将真实世界的离散数据投影到高维数据空间上,根据数据在空间中的不同距离,反映数据在物理世界的相似度。
3.2. 嵌入模型核心特征
嵌入模型(Embedding Model)是一种将离散数据(如文本、图像)映射到连续向量空间的技术。通过高维向量表示(如 768 维或 3072 维),模型可捕捉数据的语义信息,使得语义相似的文本在向量空间中距离更近。例如,"忘记密码"和"账号锁定"会被编码为相近的向量,从而支持语义检索而非仅关键词匹配。
3.3.MTEB榜单
MTEB(Massive Text Embedding Benchmark)是一个全面的评测基准,它涵盖了分类、聚类、检索、排序等8大类任务和58个数据集。
通过MTEB榜单,可以清晰地看到不同模型(如BGE系统,GTE,Jina等)在不同任务类型上的性能表现。比如,某些模型在检索任务上表现优异,而另一些可能在聚类或分类任务上更具优势。这有助于我们根据具体应用场景,做出初步的模型筛选。

MTEB榜单中任务类型
- 检索(Retrieval)
从一个庞大的文档库中,根据用户输入的查询(Query),找出最相关的文档列表。
- 语义文本相似度(Semantic Textual Similarity,STS)
判断一对句子的语义相似程度,并给出一个连续的分数。
- 重排序(Reranking)
对已经初步检索出的文档列表进行二次优化排序,使得最相关的文档排在最前面。
- 分类(Classification)
将单个文本划分到预定义的类别中。(如""正面/负面","体育/科技")。
- 聚类(Clustering)
在没有任务预设标签的情况下,将一组文本自动分成若干个有意义的群组,使得同一组内的文本语义相似,不同组间文本语义差异大。
- 对分类(Pair Classification)
判断一对文本是否具有某种特定的关系,通常是二分类问题。
- 双语挖掘(Bitext Mining)
从两种不同语言的大量句子中,找出互为翻译的句子对。
- 摘要(Summarization)
这个任务比较特殊,它不是让模型生成摘要,而是评估一个机器生成的摘要与人工撰写的参考摘要之间的语义相似度。
3.4.向量维度对模型性能的影响
-
向量维度对模型性能的影响是怎样的? 向量维度直接影响模型的表达能力、计算开销和内存占用。高维度 (如 1024, 4096): 编码更丰富、语义更细致,适用于需要深度语义理解的复杂场景,如大规模、多样化的信息检索,或者细粒度的文本分类。但计算成本更高,所需存储空间更大。 低维度 (如 256, 512): 计算速度快,内存占用小,更适合计算资源有限,或实时性要求高的场景,比如移动端。
-
思考?
如果把向量从768维拉长到1024维,检索指标提高不到1%,但内存要多占约35%,是否还要升维?
不需要,性价比低。
反过来,若压缩到768维后,指标下降超过5% => 说明信息损失大,值得使用更高维度。
3.5.向量模型的核心作用与技术原理
3.5.1. 核心作用
- 语义编码
将文本、图像等转换为向量,保留上下文信息(如 BERT 的 CLS Token 或均值池化。
- 信息降维
压缩复杂数据为低维稠密向量,提升存储与计算效率。
- 相似度计算
通过余弦相似度、欧氏距离等度量向量关联性,支撑检索增强生成(RAG)、推荐系统等应用。
3.5.2. 关键技术原理
- 上下文依赖
现代模型(如 BGE-M3)动态调整向量,捕捉多义词在不同语境中的含义。
- 训练方法
对比学习(如 Word2Vec 的 Skip-gram/CBOW)、预训练+微调(如 BERT)。
3.6. 主流嵌入模型分类与选型指南
Embedding 模型将文本转换为数值向量,捕捉语义信息,使计算机能够理解和比较内容的"意义"。选择 Embedding 模型的考虑因素:
| 因素 | 说明 |
|---|---|
| 任务性质 | 匹配任务需求(回答、搜索、聚类) |
| 领域特征 | 通用vs专业领域(医学、法律等) |
| 多语言支持 | 需处理多语言内容时考虑 |
| 维度 | 权衡信息丰富度与计算成本 |
| 许可条款 | 开源vs专有服务 |
| 最大Tokens | 适合的上下文窗口大小 |
最佳实践:为特定应用测试多个 Embedding 模型,评估在实际数据上的性能而非仅依赖通用基准。
1. 通用全能型
- BGE-M3
北京智源研究院开发,支持多语言、混合检索(稠密+稀疏向量),处理 8K 上下文,适合企业级知识库。
- NV-Embed-v2
基于 Mistral-7B,检索精度高(MTEB 得分 62.65),但需较高计算资源。
2. 垂直领域特化型
- 中文场景
BGE-large-zh-v1.5 (合同/政策文件)、 M3E-base (社交媒体分析)。
- 多模态场景
BGE-VL (图文跨模态检索),联合编码 OCR 文本与图像特征。
3. 轻量化部署型
- nomic-embed-text:
768 维向量,推理速度比 OpenAI 快 3 倍,适合边缘设备。
- gte-qwen2-1.5b-instruct:
1.5B 参数,16GB 显存即可运行,适合初创团队原型验。
4. 如何选择适合的Embedding模型,依靠MTEB就可以?
模型造型是一个系统的过程,不能仅依赖于公开榜单。关键步骤:
- 明确业务场景与评估指标
首先定义核心任务是检索、分类还是聚类?并确定衡量业务成功的关键指标,如搜索召回率 (Recall@K)、准确率 (Accuracy) 。
- 构建"黄金"测试集
准备一套能真实反映您业务场景和数据分布的高质量小规模测试集。
比如,构建一系列"问题-标准答案"对 => 评估模型好坏的"金标准"。
- 小范围对比测试 (Benchmark)
从MTEB榜单中挑选几款排名靠前且符合需求(如语言、维度)的候选模型。使用 "黄金"测试集,对这些模型进行评测。
总结:Embedding模型的选择属于综合评估,即结合测试结果、模型的推理速度、部署成本 => 做出最终决策。
3.7. 嵌入模型使用
1. 使用 API 调用方式
python
import os
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"), # 如果您没有配置环境变量,请在此处用您的API Key进行替换
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 百炼服务的base_url
)
completion = client.embeddings.create(
model="text-embedding-v3",
input='国际局势',
dimensions=1024,
encoding_format="float"
)
print(completion.model_dump_json())2.下载向量模型到本地
huggingface下载(需要科学上网)
python
from huggingface_hub import snapshot_download
model_dir = snapshot_download(
repo_id="BAAI/bge-base-zh-v1.5",
local_dir="D:/models/bge-base-zh-v1.5", # 本地保存路径
local_dir_use_symlinks=False, # 避免创建符号链接(推荐设为 False,便于直接使用)
resume_download=True # 支持断点续传
)modelscope下载
python
# 使用 modelscope 提供的 sdk 进行模型下载
from modelscope import snapshot_download
# model_id 模型的id
# cache_dir 缓存到本地的路径
model_dir = snapshot_download(model_id="BAAI/bge-base-zh-v1.5", cache_dir="D:/models")3.使用本地向量模型
python
_local_model = None
def get_embeddings(texts):
global _local_model
if _local_model is None:
_local_model = SentenceTransformer("D:/models/bge-base-zh-v1.5")
return _local_model.encode(texts, normalize_embeddings=True)
# 现在可以直接用你原来的代码!
query_vec = get_embeddings(["中东局势最新进展"])[0]
doc_vecs = get_embeddings(documents)4.应用场景举例
场景一: 为电商平台开发一个智能客服问答系统。
系统需要能精准理解用户使用中文提出的问题:• 我的订单何时能送达?• 这个商品有保修吗?• 如何办理退换货?并从FAQ知识库中匹配最相关的答案。
可使用单语言模型: 如 BGE-large-zh,专门针对单一语言(如中文)进行训练。在特定语言任务上,理解更深入、性能更优越。比如理解"七天无理由退货"。
场景二: 为国际连锁酒店集团,建立全球客户评论分析系统。
1.将来自世界各地的评论,按主题(如:客房清洁度、员工服务、地理位置)进行自动分类,无论评论是用英文、日文、西班牙文还是中文写的。2.总部的经理可以用英文查询"Loud music at night",系统需要能同时找出写着"夜に音楽がうるさい"的日文评论和"晚上音乐很吵"的中文评论。
可使用多语言模型: 如 m3e-base 或 multilingual-e5-large。
多语言Embedding的优势是能将不同语言的文本映射到统一的语义空间。"clean room"和"干净的房间"的向量在空间中会非常接近。=> 跨语言的聚类分析和检索才能实现。
通过本文章的学习,你能根据自已的业务场景,选择合适的向量模型吗?