python
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np
iris=load_iris()
X=iris.data
y=iris.target
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=42)
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
from sklearn.preprocessing import MinMaxScaler
scaler=MinMaxScaler()
X_train=scaler.fit_transform(X_train)
X_test=scaler.transform(X_test)
X_train=torch.FloatTensor(X_train)
y_train=torch.LongTensor(y_train)
X_test=torch.FloatTensor(X_test)
y_test=torch.LongTensor(y_test)
import torch
import torch.nn as nn
import torch.optim
class MLP(nn.Module):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.fc1=nn.Linear(4,10)
self.relu=nn.ReLU()
self.fc2=nn.Linear(10,3)
def forward(self,x):
out=self.fc1(x)
out=self.relu(out)
out=self.fc2(out)
return out
model=MLP()
criterion=nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
num_epochs=20000
losses=[]
for epoch in range(num_epochs):
outputs=model.forward(X_train)
loss=criterion(outputs,y_train)# 预测损失
# 反向传播和优化
optimizer.zero_grad()
loss.backward() # 反向传播计算梯度
optimizer.step()
losses.append(loss.item())
if(epoch+1)%100==0:
print(f'Epoch[{epoch+1}/{num_epochs}],Loss:{loss.item():.4f}')
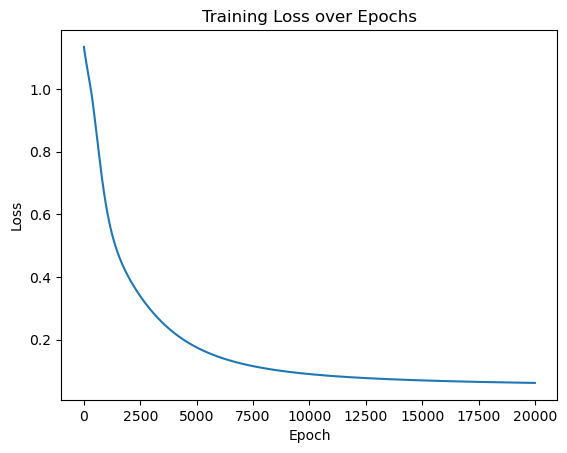
import matplotlib.pyplot as plt
plt.plot(range(num_epochs),losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss over Epochs')
plt.show()
python
print(model)
python
for name,param in model.named_parameters():
print(f"Parameter name:{name},Shape:{param.shape}")
python
import numpy as np
weight_data={}
for name,param in model.named_parameters():
if 'weight' in name:
weight_data[name]=param.detach().cpu().numpy()
fig,axes=plt.subplots(1,len(weight_data),figsize=(15,5))
fig.suptitle('Weight Distribution of Layers')
for i,(name,weights) in enumerate(weight_data.items()):
weights_flat=weights.flatten()
axes[i].hist(weights_flat,bins=50,alpha=0.7)
axes[i].set_title(name)
axes[i].set_xlabel('Weight Value')
axes[i].set_ylabel('Frequency')
axes[i].grid(True,linestyle='--',alpha=0.7)
plt.tight_layout()
plt.subplots_adjust(top=0.85)
plt.show()
print("\n===权重信息")
for name,weight in weight_data.items():
mean=np.mean(weights)
std=np.std(weights)
min_val=np.min(weights)
max_val=np.max(weights)
print(f"{name}")
print(f"均值:{mean:.6f}")
print(f"标准差:{std:.6f}")
print(f"最小值:{min_val:.6f}")
print(f"最大值:{max_val:.6f}")
print("-"*30)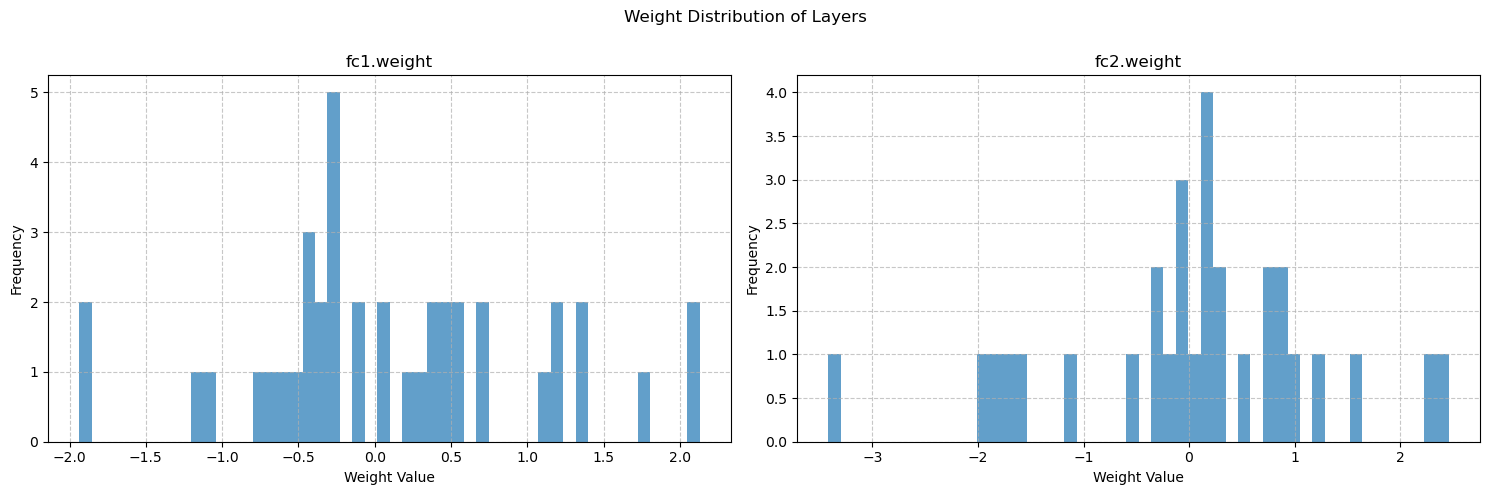

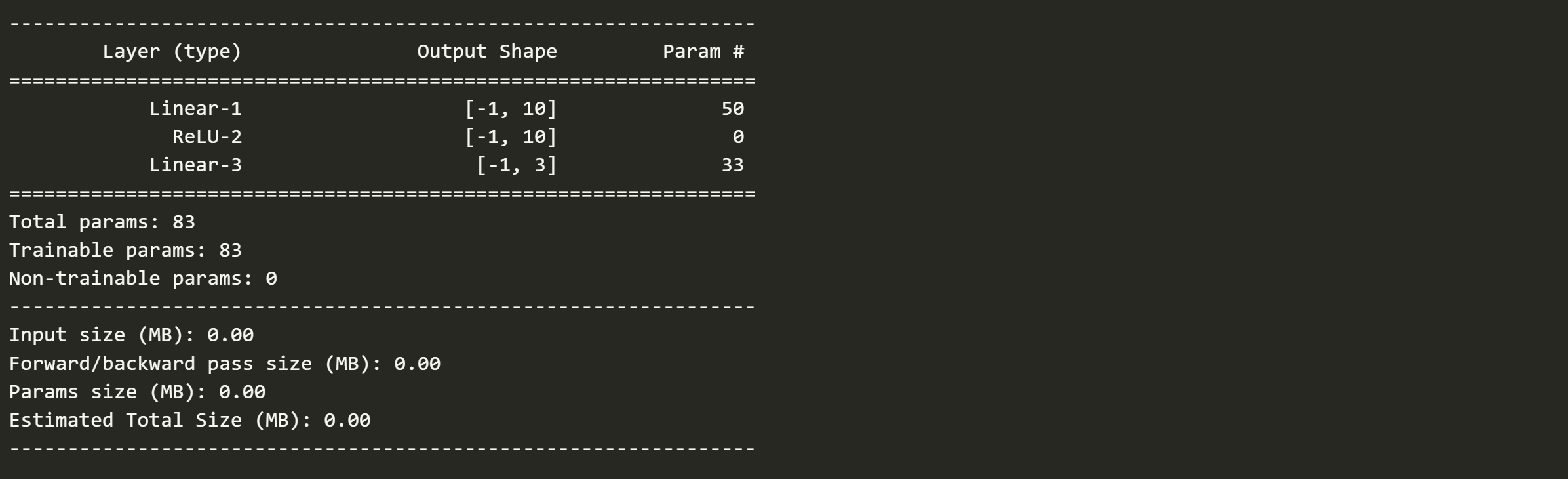
python
from torchsummary import summary
summary(model,input_size=(4,))