day37简单的神经网络@浙大疏锦行
使用 sklearn 的 load_digits 数据集 (8x8 像素的手写数字) 进行 MLP 训练。
python
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import numpy as np
import matplotlib.pyplot as plt
# 1. 加载数据
digits = load_digits()
X = digits.data
y = digits.target
print(f"数据形状: {X.shape}")
print(f"标签形状: {y.shape}")
# 查看一张图片
plt.imshow(digits.images[0], cmap='gray')
plt.title(f"Label: {y[0]}")
plt.show()数据形状: (1797, 64) 标签形状: (1797,)
python
# 2. 数据预处理
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 归一化
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 转换为 Tensor
X_train = torch.FloatTensor(X_train)
y_train = torch.LongTensor(y_train)
X_test = torch.FloatTensor(X_test)
y_test = torch.LongTensor(y_test)
print("训练集 Tensor 形状:", X_train.shape)
print("测试集 Tensor 形状:", X_test.shape)训练集 Tensor 形状: torch.Size(1437, 64)
测试集 Tensor 形状: torch.Size(360, 64)
python
# 3. 定义模型
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
# 输入层 64 (8*8像素) -> 隐藏层 32 -> 输出层 10 (0-9数字)
self.fc1 = nn.Linear(64, 32)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(32, 10)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
model = MLP()
print(model)MLP(
(fc1): Linear(in_features=64, out_features=32, bias=True) (relu): ReLU()
(fc2): Linear(in_features=32, out_features=10, bias=True)
)
python
# 4. 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1) # 学习率稍微调大一点,或者增加epoch
python
# 5. 训练模型
num_epochs = 2000
losses = []
for epoch in range(num_epochs):
# 前向传播
outputs = model(X_train)
loss = criterion(outputs, y_train)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
losses.append(loss.item())
if (epoch + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
python
# 6. 可视化损失
plt.plot(range(num_epochs), losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss')
plt.show()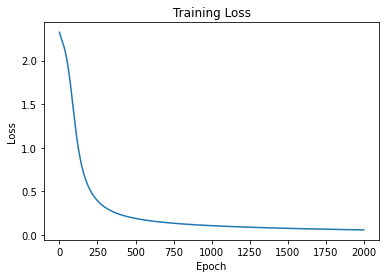
python
# 7. 模型评估
with torch.no_grad():
# 训练集准确率
outputs_train = model(X_train)
_, predicted_train = torch.max(outputs_train, 1)
accuracy_train = (predicted_train == y_train).sum().item() / y_train.size(0)
# 测试集准确率
outputs_test = model(X_test)
_, predicted_test = torch.max(outputs_test, 1)
accuracy_test = (predicted_test == y_test).sum().item() / y_test.size(0)
print(f'训练集准确率: {accuracy_train:.4f}')
print(f'测试集准确率: {accuracy_test:.4f}')