NLP是什么?
NLP:自然语言处理
它的作用就是让计算机"理解、处理和生成人类语言"。
NLP发展史
1. 基于规则
这个阶段的NLP主要用于把自然语言中的信息,提取成程序能直接用的字段。比如
- 抽取时间、日期
- 抽取金额、数量
- 抽取编号、手机号、身份证号
用户输入了一段文本:"订单将于2025年5月1日发货,金额199元",发现包含时间和金额就
json
{
"date": "2025-05-01",
"price": 199
}系统通过规则发现文本中包含时间和金额 ,于是解析成结构化数据。 后续业务程序只需要处理这段 JSON,而不再关心原始文本的自然语言形式。
可以看出,在这个阶段的 NLP 中:
- 系统不会理解用户的真实意图
- 不会结合上下文进行推断
- 不会补全隐含信息
- 也不会"猜测"用户想表达什么
它只做一件事:
判断文本是否命中既定规则,并在命中时输出确定的结构化结果
因此,基于规则的 NLP 并不具备上下文理解能力 ,
它更像是一个 "语言格式解析器" ,而不是"语言理解系统"。
2. 基于统计
核心思想
不再完全依赖人工规则,而是通过统计大量文本中词语的出现频率和组合规律,来推断语言模式。 基于统计的
比如最简单的N_Gram模型
什么是 N-Gram?
N-Gram 假设:
当前词的出现,只与前面 N-1 个词有关。
例如:
- 1-Gram:只看当前词本身
- 2-Gram(Bigram):看前 1 个词
- 3-Gram(Trigram):看前 2 个词
我们以2-Gram为列:会看前面的一个词。
我们将以下内容训练给模型:
"我 爱 吃 苹果"
"我 爱 吃 香蕉"
"我 喜欢 吃 苹果"Bigram 模型会根据一个词统计下一个词出现的概率,这里我们可以数一数所有词对:
| 前一个词 | 下一个词 | 次数 |
|---|---|---|
| 我 | 爱 | 2 次 |
| 我 | 喜欢 | 1 次 |
| 爱 | 吃 | 2 次 |
| 喜欢 | 吃 | 1 次 |
| 吃 | 苹果 | 2 次 |
| 吃 | 香蕉 | 1 次 |
根据这个词的组合,就可以去预测一个词的下一个词,比如:
- 我后面出现"爱"的概率是 2/3,出现"喜欢"的概率是 1/3。
- 吃后面出现"苹果"的概率是 2/3,出现"香蕉"的概率是 1/3。
所以:
如果你看到"我 爱 吃",那下一个词大概率是"苹果"!
这里有人要问了:为什么有的词对是一个字,有的词对是两个字,这就涉及到token的概念了。
常说的token是什么?
Token 是模型处理文本的最小"计算单位"
platform.openai.com/tokenizer,我...
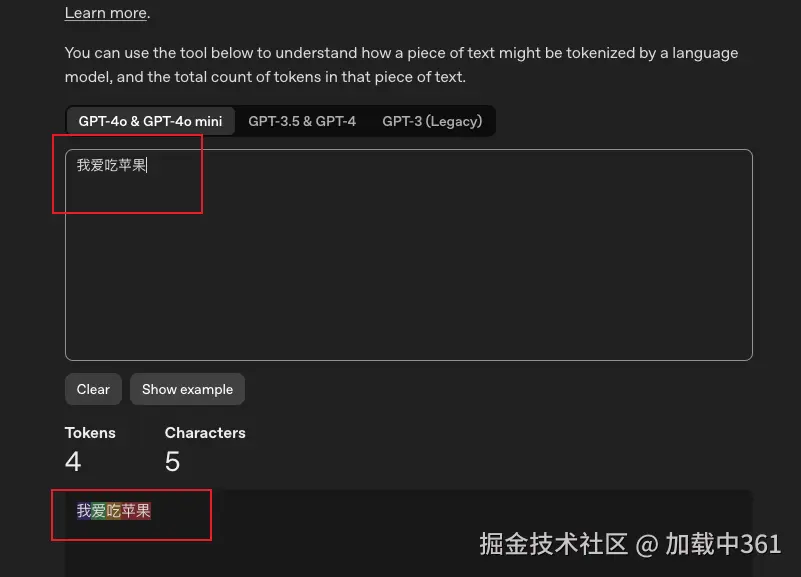
每个颜色都代表一个token。可以看到"我爱吃苹果"这句话,转换成LL处理的最小单位就是
"我" "爱" "吃" "苹果"
那自然,在统计概率的时候,也要按照这个词对进行统计,因为模型处理的永远都是token,输出的时候也是按照token进行的输出。
3. 深度学习和大数据驱动
随着互联网的发展,文本数据规模呈指数级增长,同时计算能力(尤其是 GPU)的提升,使得 深度学习方法开始被引入 NLP 领域。
这一阶段的核心变化是:
不再人为设计规则或统计特征,而是让模型自动学习语言的表示和规律。
核心思想
在深度学习驱动的 NLP 中,系统不再只关心:
- "这个词出现过多少次"
- "下一个词的概率是多少"
而是开始学习:
词与词之间的语义关系,以及它们在上下文中的含义。(这个就是向量相似)
关键技术演进
1️⃣ 词向量(Word Embedding)
通过神经网络,将词映射到连续向量空间中:
"手机" ≈ "电脑"
"北京" ≈ "上海"相似语义的词,在向量空间中距离更近。
这使得模型第一次具备了 "语义相似性"的概念。
2️⃣ Transformer 模型
Transformer 的提出,彻底改变了 NLP 的发展方向。
它通过 自注意力机制(Self-Attention) :
- 同时关注句子中的所有词
- 捕捉长距离依赖
- 大幅提升并行计算能力
这为大规模预训练模型奠定了基础。
预训练语言模型与大语言模型(LLM)
在 Transformer 架构基础上,人们提出了:
- 预训练 + 微调(Pretrain + Finetune)
- 超大规模语料训练
模型通过一个核心任务进行学习:
根据上下文,预测下一个词(Token)
但由于模型规模、数据规模和训练方式的跃迁,
这种"预测"逐渐表现出:
- 语义理解
- 推理能力
- 生成能力
最终形成了今天的大语言模型(LLM)。
在这一阶段:
- 模型不再依赖人工规则
- 不再依赖人工特征
- 可以在上下文中综合理解语言
总结
可以看出,目前的大语言模型在数学本质上仍然是概率模型,其推理与生成能力来源于统计学习与规模效应,而非人类意义上的主观思考。