黑卡死问题定义
- 黑卡死是车机屏幕出现全屏且持续显示异常的统称,包括黑屏、白屏、闪屏、卡死、异常重启等
- 问题分配的核心原则:先定位现象范围,再确定首要分析方
- 本文提供高通平台完整的问题分类树和分配规则,附带各类问题的排查方法
引言
"又黑屏了!"------这可能是车机测试群里最让人心跳加速的三个字。
作为车机系统最严重的问题类型之一,黑卡死问题有着让人头疼的"三高"特点:严重程度高、紧急程度高、排查难度高。更让人崩溃的是,这类问题往往涉及多个团队(MCU、QNX、Android、BSP、应用),一不小心就变成了各方"踢皮球"的重灾区。
我曾经历过一个项目,一个黑屏问题在5个团队之间流转了两周,最后发现是电源管理模块的一个时序问题。如果一开始就有清晰的分配原则,这个问题可能三天就能定位。
本文的目的,就是基于多个高通平台项目的黑卡死问题排查经验,建立一套清晰、可执行的问题分配和排查规则,让问题能够快速精确地找到"第一责任人"。
适用范围与阅读对象
适用范围
- 硬件平台:高通车机平台(SA8155P、SA8295P 等)
- 软件架构:QNX Hypervisor + Android 的多系统架构
- 屏幕配置:中控屏 + 仪表屏的双屏/多屏方案
阅读对象
| 角色 | 关注重点 |
|---|---|
| 项目管理 | 问题分配规则、流转流程 |
| 软件架构 | 整体排查思路、跨域协作 |
| 研发质量 | 问题分类标准、复盘依据 |
| 研发工程师 | 具体排查方法、日志分析 |
| 测试工程师 | 问题描述规范、信息收集 |
黑卡死问题定义
什么是黑卡死?
本文讨论的是广义的黑卡死问题 ,可以理解为车机屏幕出现全屏且持续的显示异常。
注意关键词:全屏 + 持续。局部 UI 异常或短暂闪烁通常不归入此类。
现象分类
| 现象 | 描述 |
|---|---|
| 黑屏 | 屏幕全黑,无任何显示内容(可能有/无背光) |
| 白屏 | 屏幕全白,无法显示正常内容 |
| 绿屏 | 屏幕显示纯绿色(通常与视频解码相关) |
| 花屏 | 屏幕显示杂乱的色块或条纹 |
| 闪屏 | 屏幕内容持续闪烁或间歇性黑屏 |
| 卡屏 | 屏幕内容定格,触摸无响应 |
| 异常重启 | 系统非预期重启(可能伴随短暂黑屏) |
与其他问题的区别
| 问题类型 | 范围 | 持续性 | 是否属于黑卡死 |
|---|---|---|---|
| 全屏黑屏超过3秒 | 全屏 | 持续 | ✅ 是 |
| 某个应用界面卡住 | 局部 | 持续 | ❌ 否(应用ANR) |
| 开机Logo显示时间过长 | 全屏 | 非持续 | ❌ 否(启动性能问题) |
| 切换应用时闪一下黑屏 | 全屏 | 非持续 | ❌ 否(过渡动画问题) |
| 整个系统触摸无响应 | 全屏 | 持续 | ✅ 是(卡死) |
高通平台问题分配原则
总体原则
核心思路:现象定位 → 范围判断 → 首要分析方 → 逐级排查
markdown
问题报告 ──▶ 现象是什么?──▶ 影响范围多大?──▶ 分配给首要分析方
│ │
▼ ▼
黑屏/卡死/重启等 中控/仪表/全部首要分析方说明
在进入具体分类之前,先了解各分析方的职责:
| 分析方 | 职责范围 | 典型问题 |
|---|---|---|
| MCU | 整车电源管理、休眠唤醒、看门狗 | 全系统黑屏、异常重启 |
| QNX | Hypervisor、显示资源调度、早期启动 | 多屏同时异常 |
| BSP | Linux/Android内核、驱动、Display子系统 | 显示驱动异常 |
| Android FW | Framework层、SurfaceFlinger、SystemServer | 中控卡死、ANR |
| 仪表HMI | 仪表应用层渲染 | 仪表闪屏、仪表卡死 |
| 仪表中间件 | 仪表数据通信、刷新机制 | 仪表数据异常 |
| 对应应用 | 具体App | 单应用卡死 |
| 性能团队 | 系统性能优化 | 整体卡顿 |
问题分类与分配详解
一、黑屏问题
黑屏是最常见也最"吓人"的问题类型。根据影响范围 和持续性,分为以下子类:
1.1 持续黑屏
现象一:中控和仪表都黑屏
首要分析方:MCU 与 QNX 电源模块
分析思路:
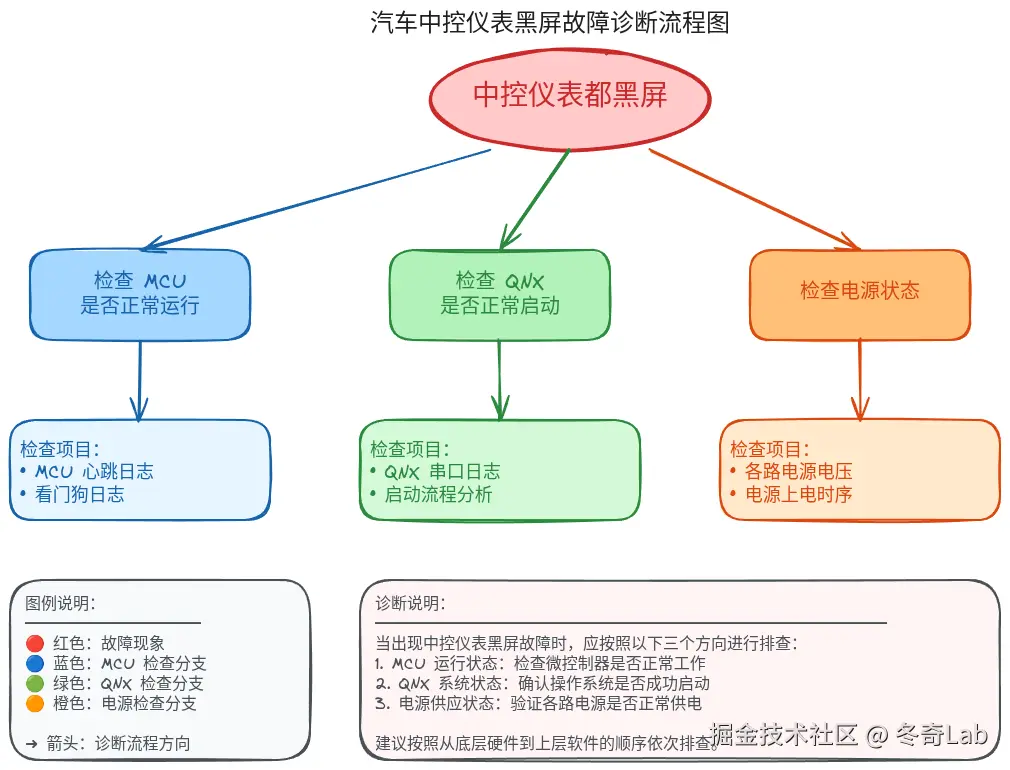 排查步骤:
排查步骤:
- 检查 MCU 串口日志,确认 MCU 状态
- 检查 QNX 串口日志,确认 Hypervisor 启动状态
- 检查各显示屏背光控制信号
- 确认 SOC 主芯片电源时序是否正常
关键日志:
bash
# MCU 日志关注点
[MCU] Power state: xxx
[MCU] Watchdog: xxx
# QNX 日志关注点
[QNX] display_manager: initialized
[QNX] screen: display attached后续流转:
- 若发现异常 → 交对应团队分析
- 若 MCU/QNX 正常 → BSP 分析
- 若 BSP 正常 → 由项目/质量拉通各方分析,架构支持
现象二:仅仪表黑屏(中控正常)
首要分析方:BSP
分析思路:
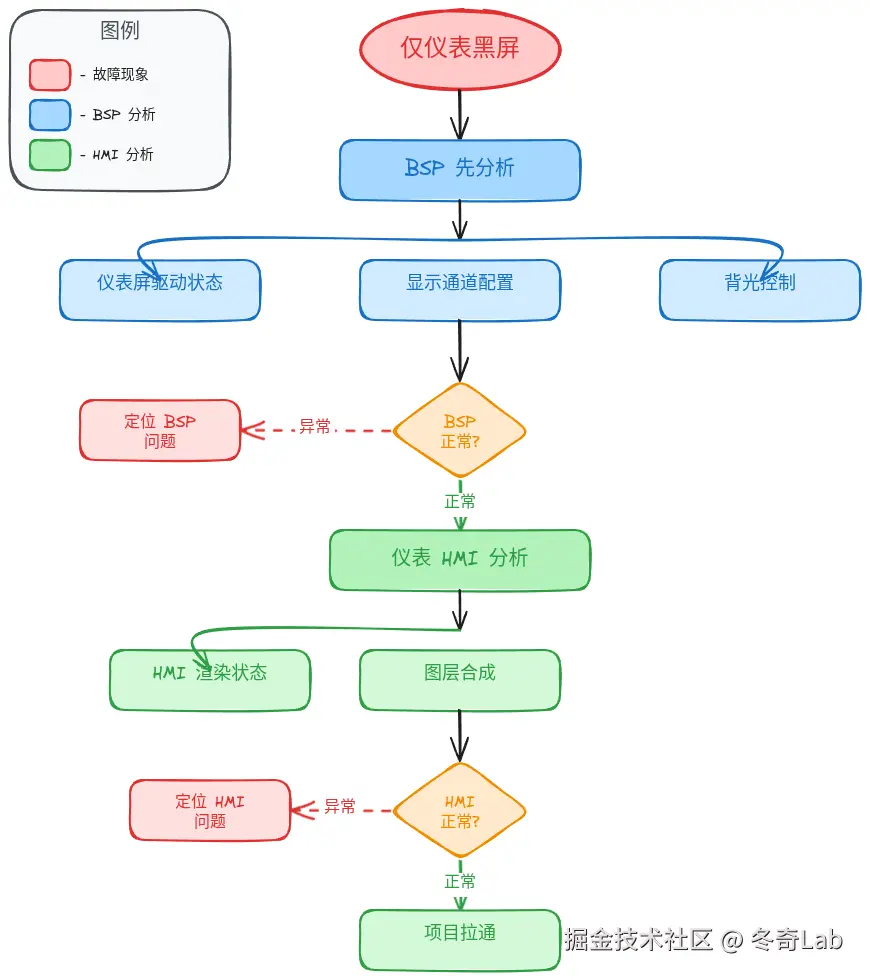
排查步骤:
- 检查仪表屏 MIPI/LVDS 信号是否正常
- 查看 Display 驱动日志,确认屏幕初始化状态
- 检查仪表系统 HMI 渲染进程状态
- 对比中控显示链路,排查差异点
现象三:仅中控黑屏(仪表正常)
首要分析方:MCU 与 QNX 电源模块
分析思路:
中控单独黑屏,仪表正常,说明 SOC 主芯片在运行,问题可能在:
- 中控屏电源管理
- Android 显示通道
- SurfaceFlinger 状态
排查步骤:
- 检查中控屏背光、电源状态
- 检查 Android SurfaceFlinger 状态
- 查看 Display HAL 层日志
- 检查 QNX 到 Android 的显示资源分配
后续流转:
- MCU/QNX 异常 → 对应团队
- 若正常 → Android FW 分析 → BSP 分析 → 项目拉通

1.2 闪屏
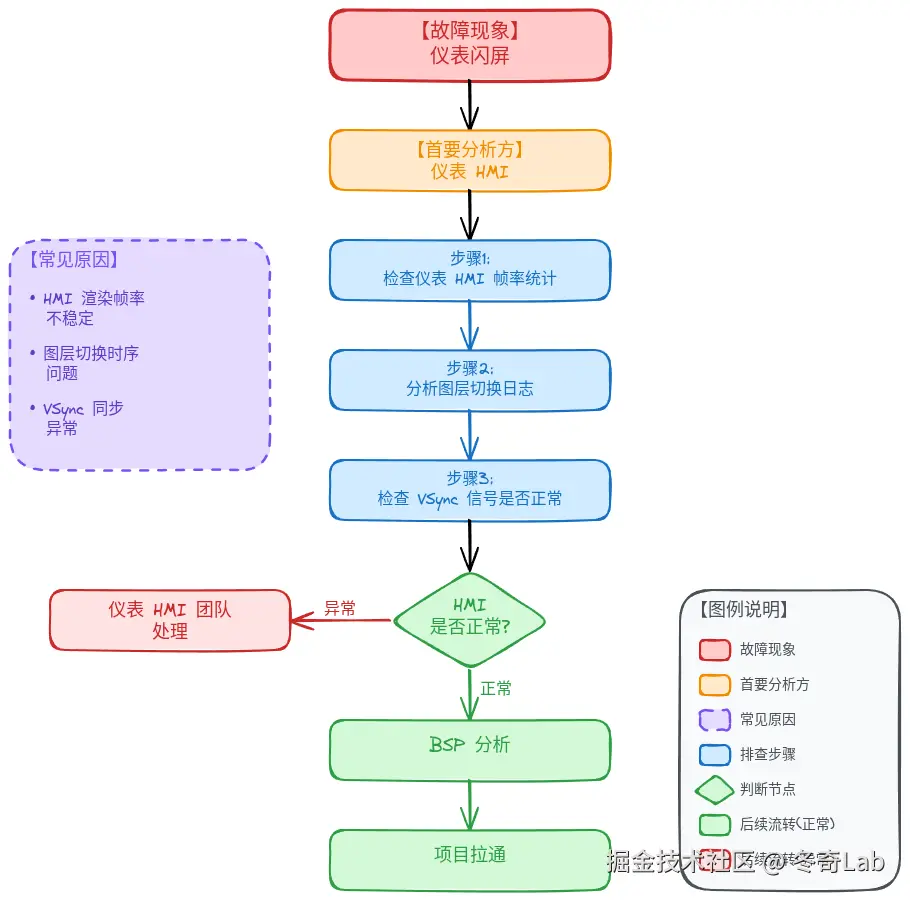
仪表闪屏
首要分析方:仪表 HMI
常见原因:
- HMI 渲染帧率不稳定
- 图层切换时序问题
- VSync 同步异常
排查步骤:
- 检查仪表 HMI 帧率统计
- 分析图层切换日志
- 检查 VSync 信号是否正常
后续流转:HMI 正常 → BSP 分析 → 项目拉通
中控闪屏
首要分析方:Android 前台应用
分析思路:
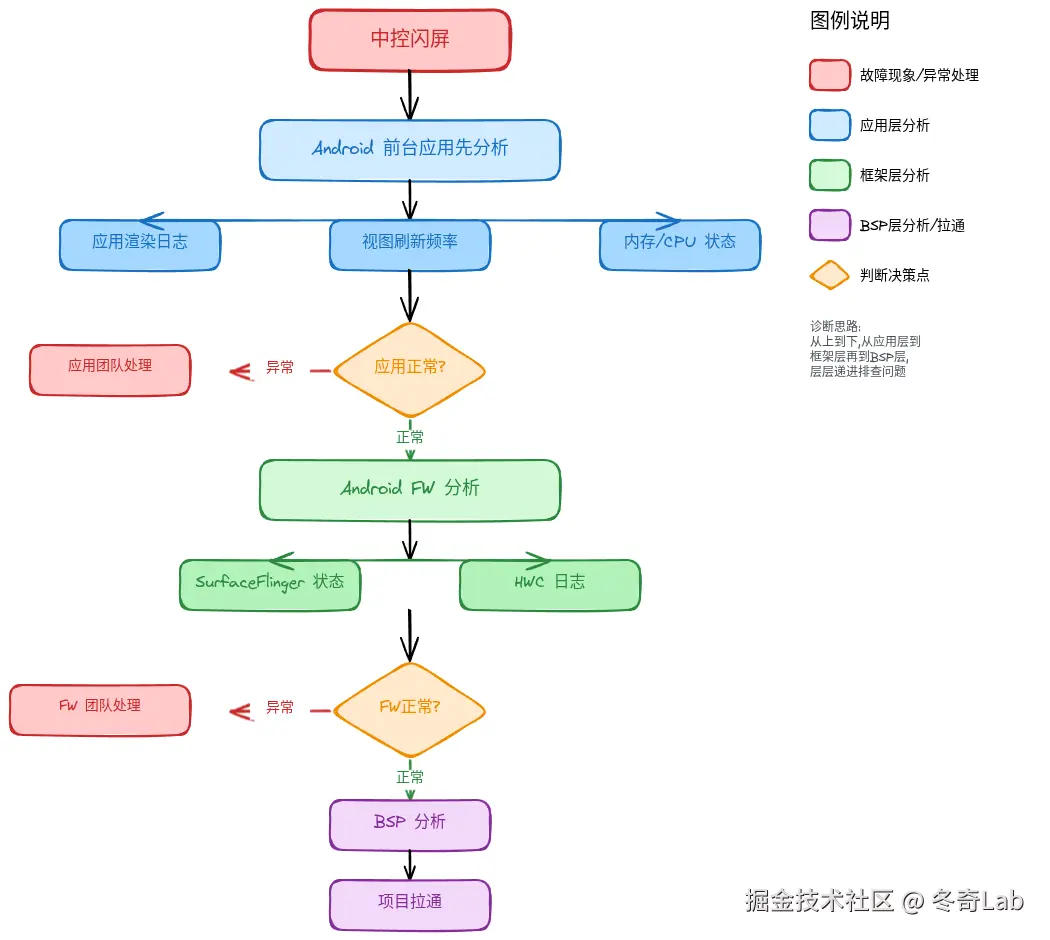
1.3 部分区域黑屏
首要分析方:对应应用
说明:部分区域黑屏通常是某个应用的 Surface 未正确渲染,直接交给对应应用分析。
二、卡死问题
卡死的特点是:屏幕有显示,但触摸无响应或界面定格。
2.1 中控卡死
整个屏幕卡死,各处点击都无响应
首要分析方:Android FW
分析思路:
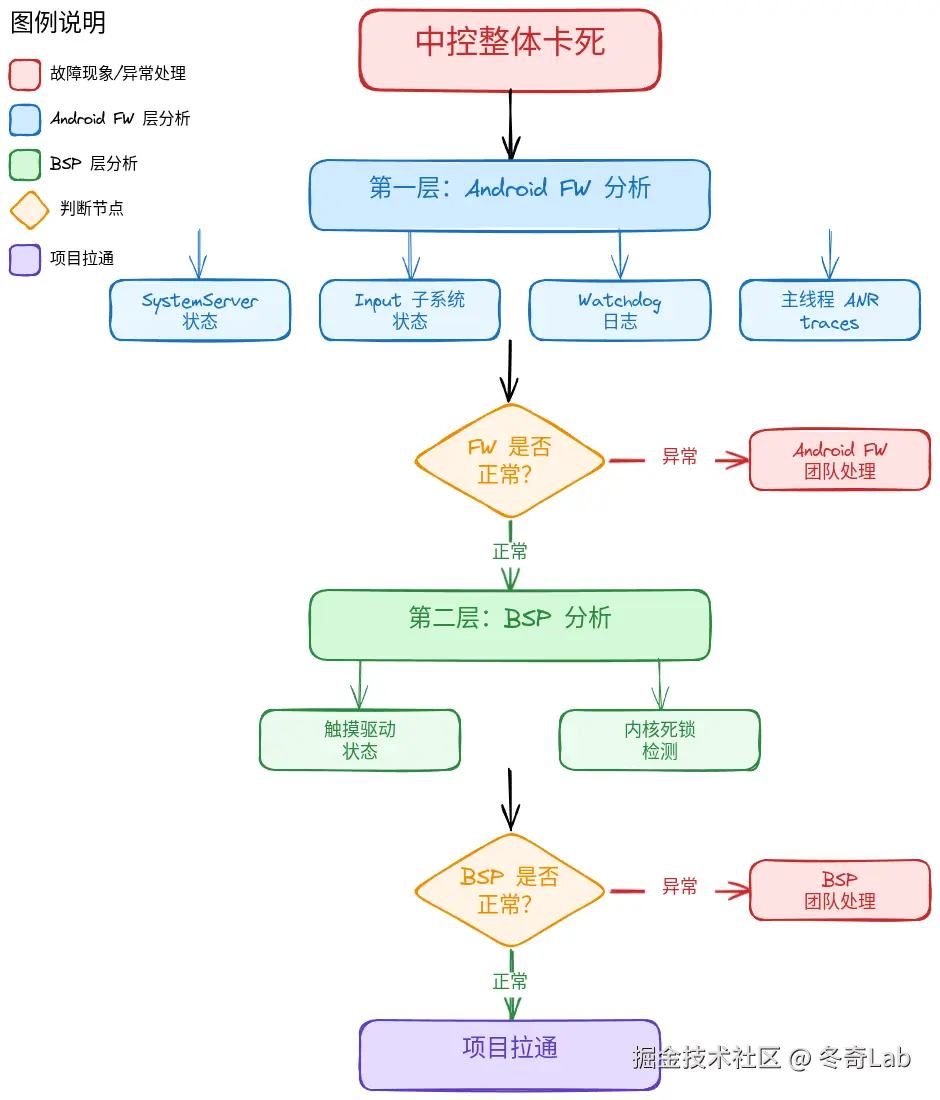
关键排查命令:
bash
# 检查 SystemServer 状态
adb shell dumpsys activity
# 检查输入子系统
adb shell dumpsys input
# 获取 ANR traces
adb pull /data/anr/traces.txt
# 检查系统负载
adb shell top -n 1
adb shell cat /proc/loadavg单个应用卡死
首要分析方:对应应用
排查步骤:
- 获取应用的 ANR traces
- 分析应用主线程状态
- 检查是否有死锁或长耗时操作
2.2 仪表卡死
首要分析方:仪表 HMI 或仪表中间件
分析思路:
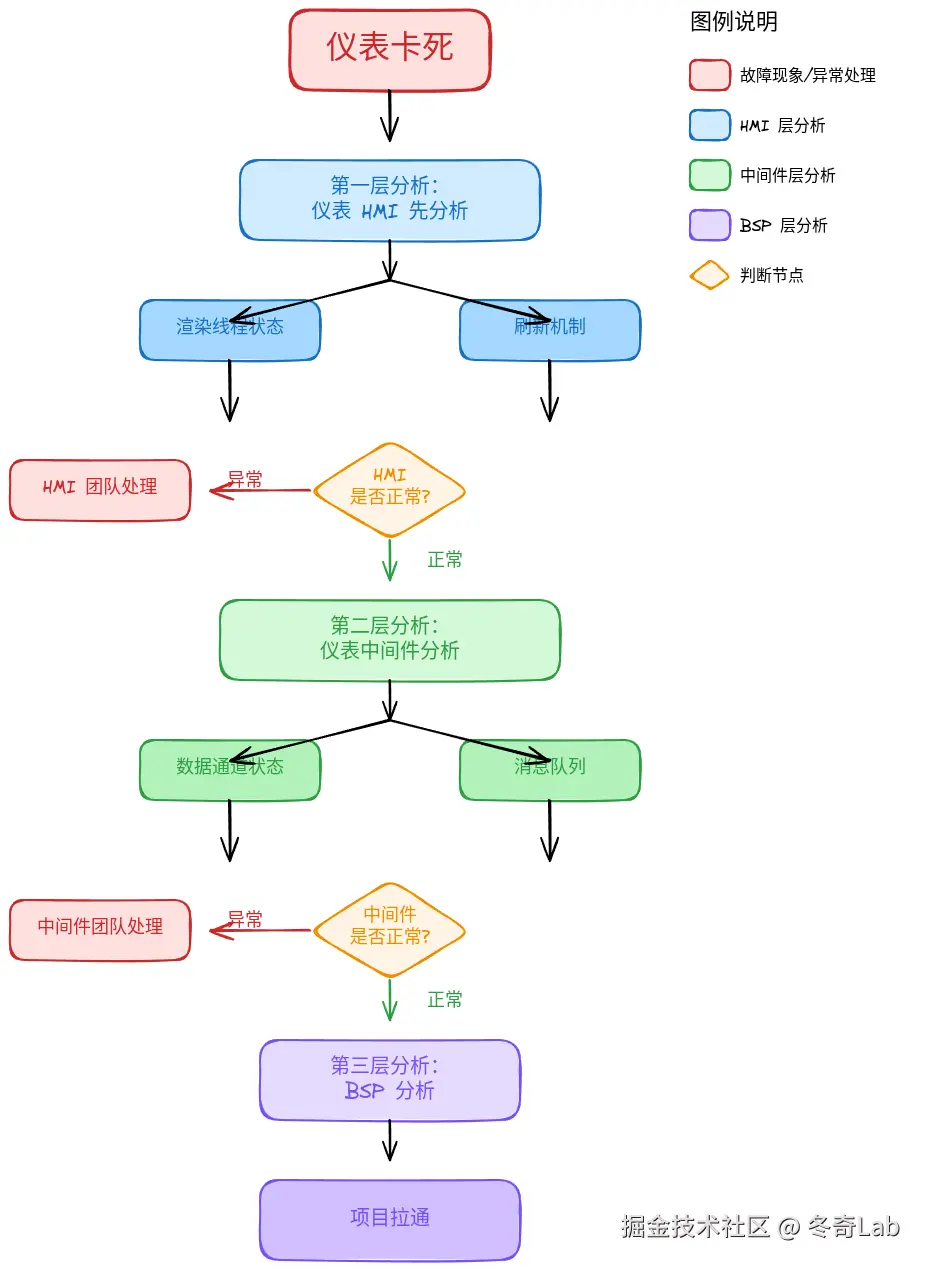
三、卡顿问题
卡顿与卡死的区别:卡顿有响应,只是响应慢;卡死完全无响应。
3.1 整个系统卡顿、响应慢
首要分析方:性能团队
排查方向:
- CPU 占用率、调度情况
- 内存压力、Swap 使用
- IO 等待、磁盘性能
- 温控降频情况
3.2 单个应用卡顿
首要分析方:对应应用
四、异常重启
4.1 仪表、中控都重启
首要分析方:MCU
分析思路 : 
4.2 仅中控重启(仪表正常)
首要分析方:Android FW
分析思路:
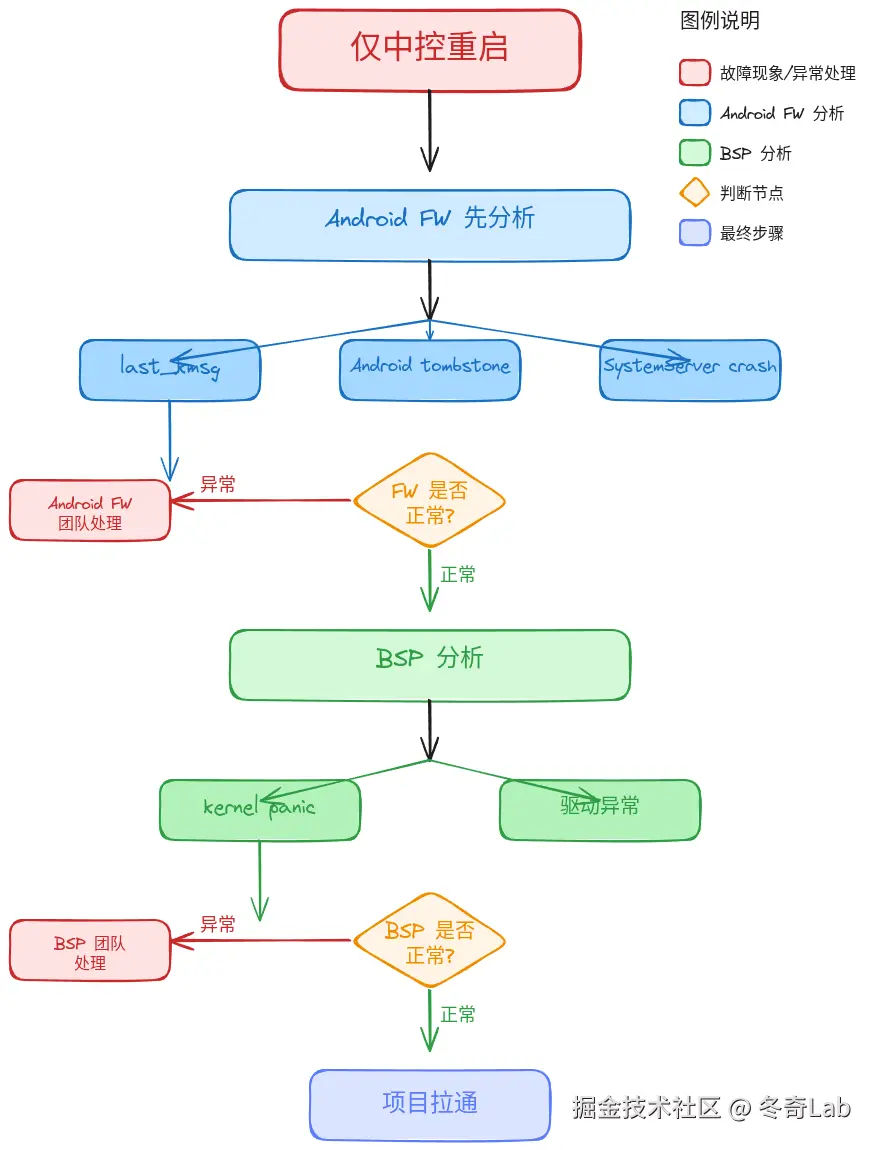
关键日志获取:
bash
# 获取上次重启前的内核日志
adb shell cat /sys/fs/pstore/console-ramoops-0
# 获取 tombstone
adb pull /data/tombstones/
# 检查重启原因
adb shell getprop ro.boot.bootreason问题分配速查表
为便于快速查阅,汇总如下:
| 问题现象 | 首要分析方 | 后续流转 |
|---|---|---|
| 中控仪表都黑屏 | MCU/QNX电源 | → BSP → 项目拉通 |
| 仅仪表黑屏 | BSP | → 仪表HMI → 项目拉通 |
| 仅中控黑屏 | MCU/QNX电源 | → Android FW → BSP → 项目拉通 |
| 仪表闪屏 | 仪表HMI | → BSP → 项目拉通 |
| 中控闪屏 | 前台应用 | → Android FW → BSP → 项目拉通 |
| 部分区域黑屏 | 对应应用 | → 项目拉通 |
| 中控整体卡死 | Android FW | → BSP → 项目拉通 |
| 单应用卡死 | 对应应用 | → 项目拉通 |
| 仪表卡死 | 仪表HMI/中间件 | → BSP → 项目拉通 |
| 整体卡顿 | 性能团队 | → 项目拉通 |
| 单应用卡顿 | 对应应用 | → 项目拉通 |
| 全系统重启 | MCU | → QNX中间件 → BSP → 项目拉通 |
| 仅中控重启 | Android FW | → BSP → 项目拉通 |
问题报告规范
为了让问题能够快速被分析,测试同学在提交黑卡死问题时,请包含以下信息:
必填信息
markdown
## 问题描述
- 现象:[黑屏/卡死/闪屏/重启]
- 影响范围:[中控/仪表/全部]
- 持续时间:[持续/间歇/已恢复]
- 复现频率:[必现/高概率/偶发]
## 环境信息
- 车型项目:
- 软件版本:
- 硬件版本:
## 操作步骤
1. xxx
2. xxx
3. 问题出现
## 日志附件
- [ ] MCU 日志
- [ ] QNX 日志
- [ ] Android logcat
- [ ] kernel log
- [ ] ANR traces(如有)
- [ ] tombstone(如有)日志采集脚本示例
bash
#!/bin/bash
# collect_blackscreen_logs.sh
# 黑卡死问题日志采集脚本
TIMESTAMP=$(date +%Y%m%d_%H%M%S)
LOG_DIR="blackscreen_logs_${TIMESTAMP}"
mkdir -p ${LOG_DIR}
# Android 日志
adb logcat -d > ${LOG_DIR}/logcat.txt
adb shell dmesg > ${LOG_DIR}/dmesg.txt
adb bugreport > ${LOG_DIR}/bugreport.zip
# ANR 和 tombstone
adb pull /data/anr/ ${LOG_DIR}/anr/
adb pull /data/tombstones/ ${LOG_DIR}/tombstones/
# 系统状态
adb shell dumpsys meminfo > ${LOG_DIR}/meminfo.txt
adb shell dumpsys cpuinfo > ${LOG_DIR}/cpuinfo.txt
adb shell dumpsys SurfaceFlinger > ${LOG_DIR}/surfaceflinger.txt
adb shell dumpsys input > ${LOG_DIR}/input.txt
# pstore (重启后)
adb shell cat /sys/fs/pstore/console-ramoops-0 > ${LOG_DIR}/pstore.txt 2>/dev/null
echo "日志已采集到 ${LOG_DIR} 目录"常见问题 FAQ
Q1: 问题被分配后,分析方认为不是自己的问题怎么办?
A : 首要分析方有责任给出明确的分析结论,说明:
- 自己负责的模块状态是否正常
- 提供支撑结论的日志证据
- 建议下一步由谁分析
不能简单回复"不是我的问题"就转走。
Q2: 问题复现不了怎么办?
A:
- 增加日志级别,部署监控脚本
- 与测试沟通具体操作场景
- 尝试压力测试复现
- 分析历史日志,寻找规律
Q3: 多个团队的结论相互矛盾怎么办?
A : 由软件架构 或项目技术负责人组织联合排查会议,各方带着日志和证据一起分析。
总结
黑卡死问题的高效解决,依赖于:
- 清晰的分类标准 ------ 知道问题属于哪一类
- 明确的分配原则 ------ 知道先找谁分析
- 规范的流转机制 ------ 知道分析不出来找谁
- 完善的日志采集 ------ 有足够的信息支撑分析
希望本文能够帮助各项目团队在面对黑卡死问题时,不再"踢皮球",而是快速、精准地定位和解决问题。
记住:没有解决不了的 bug,只有找不到的 root cause。而找到 root cause 的前提,是先找对分析它的人。