文章目录
- 前言
- 一、什么是ELK
- 二、ELK核心组件说明
-
- 1、Elasticsearch
-
- 1.1、什么是Elasticsearch
- [1.2、Elasticsearch 作用](#1.2、Elasticsearch 作用)
- [1.3、Elasticsearch 应用场景](#1.3、Elasticsearch 应用场景)
- [1.4、Elasticsearch 工作原理](#1.4、Elasticsearch 工作原理)
- 2、Logstash
- 3、Kibana
-
- 3.1、Kiabana是什么
- 3.2、Kiabana作用
- 3.3、Kiabana应用场景
- [3.4、Kibana 的工作原理](#3.4、Kibana 的工作原理)
- 三、ELK框架部署
- 四、ELK+Filebeat部署
- 总结
前言
随着业务规模扩大,日志与监控数据激增,ELK Stack 7.8.1 凭借高效采集、存储与可视化能力,成为解决数据治理难题的优选方案。
一、什么是ELK
ELK 是一套开源的日志分析与可视化技术栈的简称,由三个核心组件的首字母组成:
- E:Elasticsearch
- L:Logstash
- K:Kibana
核心作用是实现日志的收集、存储、分析、检索与可视化。
二、ELK核心组件说明
1、Elasticsearch
1.1、什么是Elasticsearch
是一款 分布式、RESTful 风格的开源搜索引擎。实时存储、检索和分析海量数据。
1.2、Elasticsearch 作用
全文检索:支持模糊匹配、关键词检索、短语检索等复杂文本查询;
数据聚合:对数据进行统计分析(如计数、求和、分组),生成指标结果;
分布式存储:自动分片存储数据,支持集群扩展,保证高可用;
实时响应:数据写入后秒级可查,满足实时监控、即时搜索需求。
1.3、Elasticsearch 应用场景
日志 / 日志分析:存储应用日志、系统日志,支持按关键词快速排查问题;
电商搜索:商品标题、描述的全文检索(如 "红色连衣裙" 模糊匹配);
监控告警:采集系统 / 应用指标(CPU、接口响应时间),实时监控并触发告警;
企业级检索:文档库、知识库、内部系统的内容检索(如合同、文档搜索)。
1.4、Elasticsearch 工作原理
数据写入流程:
数据(如日志、文档)被写入 ES 时,先经过「分词器」拆分关键词(如 "Elasticsearch 入门" 拆分为 "elasticsearch""入门");分词后的关键词与文档 ID 建立映射关系(即「倒排索引」,核心数据结构);数据按配置的「分片规则」分发到集群中的主分片,同时同步到副本分片(保证高可用)。
数据查询流程:
接收用户查询请求(如 REST API 调用),解析查询语句;
基于倒排索引快速匹配包含关键词的文档;
对匹配结果进行评分排序(按相关性权重);
合并主分片 + 副本的查询结果,返回给用户。
2、Logstash
2.1、什么是Logstash
是一款 开源的数据处理管道工具。采集、清洗、转换、传输数据,连接数据源与存储 / 分析系统。
2.2、Logstash作用
多源数据采集:支持从文件、数据库、消息队列(Kafka)、HTTP 接口等多种来源采集数据.
数据清洗转换:对非结构化数据(如原始日志)进行过滤、拆分、格式化(如提取字段、去除冗余信息),转为结构化数据;
数据路由传输:将处理后的数据输出到 Elasticsearch、MySQL、Redis 等目标存储。
2.3、Logstash应用场景
1、日志集中采集:收集多台服务器的应用日志、系统日志(如 Nginx 日志、Java 应用日志),统一汇总;
2、数据预处理:将非结构化日志(如 "2025-12-11 10:00:00 INFO user=123 action=login")转为 JSON 结构化格式;
3、跨系统数据同步:将数据库中的业务数据(如订单数据)同步到 Elasticsearch 用于检索分析。
2.4、Logstash工作原理
核心是「三阶段数据处理管道」,流程如下:
1、Input(输入阶段):通过插件采集数据(如 file 插件读取日志文件、kafka 插件消费消息队列数据);
2、Filter(过滤阶段):对采集到的数据进行处理(如 grok 插件解析日志格式、mutate 插件添加 / 删除字段、date 插件格式化时间);
3、Output(输出阶段):通过插件将处理后的结构化数据输出到目标系统(如 elasticsearch 插件写入 ES、file 插件保存到本地文件)。底层采用多线程处理,每个阶段可配置线程数,提高并发处理能力。
3、Kibana
3.1、Kiabana是什么
Kibana 是 开源的数据可视化与分析平台,Elasticsearch 的官方配套工具,核心定位是「让 ES 中的数据 "可视化"」,提供交互式界面供用户查询、分析、展示数据。
3.2、Kiabana作用
1数据可视化:通过图表(折线图、柱状图、饼图、地图等)展示 ES 中的数据;
2交互式查询:提供「Dev Tools」界面,支持直接编写 ES 查询语句(DSL),实时查看结果;
3仪表盘定制:将多个图表组合为仪表盘(如系统监控仪表盘、业务指标仪表盘),支持实时刷新;
4告警配置:对关键指标(如 CPU 使用率、错误日志数量)设置阈值,触发告警(邮件、短信等)。
3.3、Kiabana应用场景
1系统监控:展示服务器 CPU、内存、磁盘使用率,应用接口响应时间、错误率等指标;
2日志分析:通过日志面板筛选、搜索日志,快速定位问题(如报错日志详情);
3业务报表:展示电商订单量、用户活跃度、销售额等业务数据,支持按时间 / 地区拆分;
4数据探索:数据分析师通过交互式查询,探索数据规律(如用户行为偏好)。
3.4、Kibana 的工作原理
1连接 ES:Kibana 启动时需配置 ES 集群地址,通过 ES 的 REST API 与 ES 建立通信;
2数据请求:用户在 Kibana 界面操作(如创建图表、执行查询),Kibana 将操作转换为 ES 支持的查询语句(如 DSL);
3数据获取:ES 执行查询后返回结果,Kibana 接收数据并进行格式化处理;
4可视化渲染:将处理后的数据渲染为图表、仪表盘或日志列表,展示给用户;
5持久化:用户创建的仪表盘、查询语句可保存到 Kibana 本地存储(或 ES 索引中),支持共享。
三、ELK框架部署
1、环境规划
1.1、服务器规划
node1 4G+ ip:192.168.10.105
Elasticsearch7.8.1(集群)、Kibana7.8.1、jdk 1.8.0_131
node2 4G+ ip:192.168.10.106
Elasticsearch7.8.1(集群)、jdk 1.8.0_131
Logstash ip:192.168.10.107
httpd 、Logstash7.8.1
filebeat ip:192.168.10.102
filebeat7.8.1
1.2、系统设置(node1、node2执行)
bash
#1、关闭防火墙
systemctl stop firewalld #关闭防火墙
setenforce 0 #关闭增强功能
#2、更改主机名、配置域名解析、查看Java环境
Node1节点:hostnamectl set-hostname node1
Node2节点:hostnamectl set-hostname node2
#3、主机名与IP解析
vim /etc/hosts
192.168.10.105 node1
192.168.10.106 node2
#4、java安装 version "1.8.0_131 (1.8.0_2** 可能会有问题)
#使用jdk,后续需要调整elasticsearch的路径
yum install -y java
java -versionjdk环境验证:java -version

2、Elasticsearch部署
2.1、Elasticsearch安装
node1、node2操作
bash
#1安装elasticsearch---rpm包,上传包elasticsearch-7.8.1-x86_64.rpm
#rpm安装:需手动找包 + 解决依赖 yum安装:一条命令完成 编译安装:编译步骤多、耗时长
cd /opt
rpm -ivh elasticsearch-7.8.1-x86_64.rpm
#2加载系统服务
#加载新增 / 修改的服务配置(比如刚创建 / 修改了 Elasticsearch 的 service 文件);
systemctl daemon-reload
systemctl enable elasticsearch.service
#3修改elasticsearch主配置文件
cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.bak
vim /etc/elasticsearch/elasticsearch.yml
--17--取消注释,指定集群名字
cluster.name: my-elk-cluster
--23--取消注释,指定节点名字:Node1节点为node1,Node2节点为node2
node.name: node1
# 添加 设置该节点为主节点候选人
node.master: true
# 添加 设置该节点可以存储数据
node.data: true
--33--取消注释,指定数据存放路径
path.data: /data/elk_data
--37--取消注释,指定日志存放路径
path.logs: /var/log/elasticsearch/
--43--取消注释,改为在启动的时候不锁定内存
bootstrap.memory_lock: false
--55--取消注释,设置监听地址,0.0.0.0代表所有地址
network.host: 0.0.0.0
--59--取消注释,ES 服务的默认监听端口为9200
http.port: 9200
transport.tcp.port: 9300
--68--取消注释,集群发现通过单播实现,指定要发现的节点 node1、node2
# 添加(7.8比较特殊)
discovery.seed_hosts: ["192.168.10.105:9300", "192.168.10.106:9300"]
cluster.initial_master_nodes: ["node1", "node2"]
#查看elasticsearch.yml的有效配置
grep -v "^#" /etc/elasticsearch/elasticsearch.yml
#创建数据存放路径并授权。RPM 包安装 Elasticsearch 时,会自动创建elasticsearch用户、组,这是 RPM 包的标准化设计(编译安装 / 解压安装则需要手动创建)。
mkdir -p /data/elk_data
chown elasticsearch:elasticsearch /data/elk_data/
#4 启动elasticsearch
systemctl start elasticsearch.service
netstat -antulp | grep 9200
#5 插入索引 测试索引,索引为 index-demo,类型为 test。
curl -X PUT 'localhost:9200/index-demo1/test/1?pretty&pretty' -H 'content-Type: application/json' -d '{"user":"zhangsan","mesg":"hello world"}'
#6 查看该node节点目前的所有索引,有测试索引index-demo1就正常
curl -X GET "http://localhost:9200/_cat/indices?h=index"2.3、检查节点状态和排错日志
bash
#5 检查单节点 ES 服务是否启动成功.各种方法如下
systemctl status elasticsearch.service
netstat -antulp | grep 9200
浏览器访问 http://192.168.10.105:9200 # 查看node1节点信息
# 查看单节点健康状态
# 绿色:健康 数据和副本 全都没有问题
# 红色:数据都不完整
# 黄色:数据完整,但副本有问题
浏览器访问 http://192.168.10.105:9200/_cluster/health?pretty
# 6、验证集群是否正常,各种方法如下
# 查看集群健康状态
浏览器访问 http://192.168.10.105:9200/_cluster/state?pretty
# curl访问ES的REST API(推荐)
# 若curl无响应,指定节点IP访问(比如在Node1上查)
# number_of_nodes 字段:2(表示两个节点都加入集群);
# number_of_data_nodes 字段:2(两个节点都是数据节点)。
curl -XGET 'http://localhost:9200/_cluster/health?pretty'
curl -XGET 'http://192.168.10.105:9200/_cluster/health?pretty'
# 查看集群节点列表(确认节点发现正常),master 列有一个*,表示该节点是主节点(集群正常选主)。
curl -XGET 'http://localhost:9200/_cat/nodes?v'
正常输出示例(能看到 node1 和 node2 两个节点):
p heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.10.105 10 80 2 0.10 0.05 0.01 mdi * node1
192.168.10.106 12 78 1 0.08 0.04 0.00 mdi - node2单节点日志排错:
bash
#查看ES日志(若服务状态异常,优先看日志定位问题),日志中无 ERROR 级别的报错(如权限、端口占用、配置语法错误)
tail -f /var/log/elasticsearch/my-elk-cluster.log集群日志排错:
bash
/var/log/elasticsearch/my-elk-cluster.log # 集群名.log(主日志文件,核心)
# 补充:RPM安装还会生成以下日志(辅助排查)
/var/log/elasticsearch/elasticsearch.log # 兜底日志(部分版本会复用)
/var/log/messages # 系统日志(包含ES服务启动/崩溃的系统层面信息)
/var/log/elasticsearch/_cat/ # 分片/节点状态日志(可选)
bash
# 实时查看主日志(按Ctrl+C停止),优先看ERROR级别
tail -f /var/log/elasticsearch/my-elk-cluster.log | grep -i "error"
# 进阶:只看ERROR/FATAL级别,过滤掉无关信息
tail -f /var/log/elasticsearch/my-elk-cluster.log | grep -E "ERROR|FATAL"
# 若日志量大,按时间筛选最近100行ERROR
tail -n 100 /var/log/elasticsearch/my-elk-cluster.log | grep -i "error"2.4、测试结果
elasticsearch成功运行。且master值为* ,表示该节点为主节点
curl -XGET 'http://localhost:9200/_cat/nodes?v'

3、Logstash部署
日志收集器,要部署在应用服务上。例如:Apache 节点上
3.1、部署Logstash
bash
#1 前置准备
hostnamectl set-hostname apache
yum -y install httpd
systemctl start httpd
chmod 755 /var/log/httpd/
yum -y install java
java -version
#2 安装Logstash。上传软件包 logstash-7.8.1.rpm 到/opt目录下
cd /opt
rpm -ivh logstash-7.8.1.rpm
systemctl start logstash.service
systemctl enable logstash.service
ln -s /usr/share/logstash/bin/logstash /usr/local/bin/定义logstash配置文件
修改 Logstash 配置文件,让其收集系统日志/var/log/messages,并将其输出到 elasticsearch中。
bash
chmod +r /var/log/messages
vim /etc/logstash/conf.d/system.conf
#---写入-----------------------
input {
file{
path =>"/var/log/messages"
type =>"system"
start_position =>"beginning"
}
file{
path =>"/var/log/httpd/access_log"
type =>"apache"
start_position =>"beginning"
}
}
output {
# 条件1:type为system的日志,输出到system-日期 索引
if [type] == "system" {
elasticsearch {
hosts => ["192.168.10.105:9200"]
index =>"system-%{+YYYY.MM.dd}"
}
}
# 条件2:type为apache的日志,输出到apache-日期 索引(也可自定义其他配置)
else if [type] == "apache" {
elasticsearch {
hosts => ["192.168.10.105:9200"]
index =>"apache-%{+YYYY.MM.dd}" # 仅索引名差异化,其他保持不变
}
}
}
#-----------------------------------------------
systemctl restart logstash
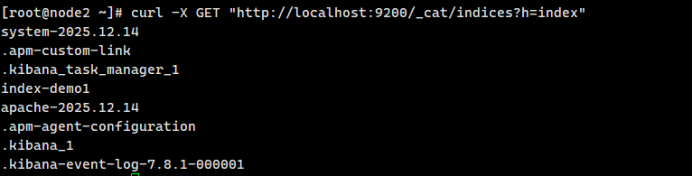
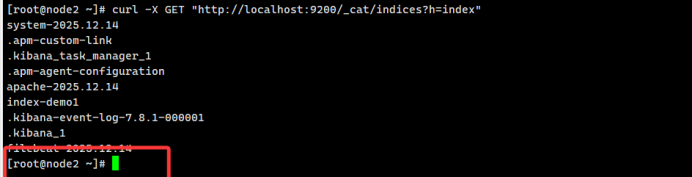
# 在elastsearch节点通过curl -X GET "http://localhost:9200/_cat/indices?h=index" 查看索引信息3.2、测试Logstash
Logstash成功部署,message日志成功输出到el节点.

再通过访问httpd触发access.log日志输出到el,如下所示

4、Kiabana部署
4.1、Kiabana部署流程
(在 Node1 节点上操作)
bash
#1下载或上传压缩包,安装
# wget https://artifacts.elastic.co/downloads/kibana/kibana-6.6.1-linux-x86_64.tar.gz
cd /opt
rpm -ivh kibana-7.8.1-x86_64.rpm
#2设置 Kibana 的主配置文件
vim /etc/kibana/kibana.yml
--2--取消注释,Kiabana 服务的默认监听端口为5601
server.port: 5601
--7--取消注释,设置 Kiabana 的监听地址,0.0.0.0代表所有地址
server.host: "0.0.0.0"
--28--取消注释,设置和 Elasticsearch 建立连接的地址和端口
elasticsearch.hosts: ["http://192.168.10.105:9200"]
--37--取消注释,设置在 elasticsearch 中添加.kibana索引
kibana.index: ".kibana"
# 3.启动 Kibana 服务
systemctl start kibana.service
systemctl enable kibana.service
netstat -natp | grep 56014.2、Kiabana测试
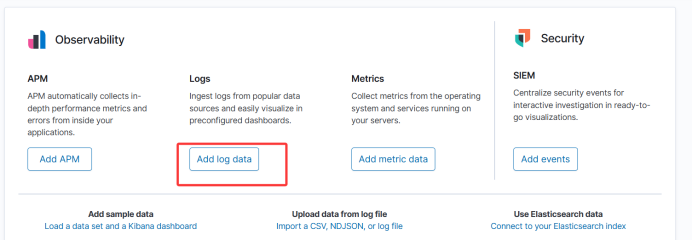
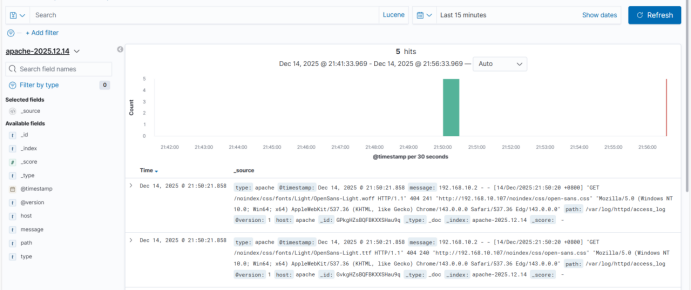
kibana部署,调用el节点数据,进行显示
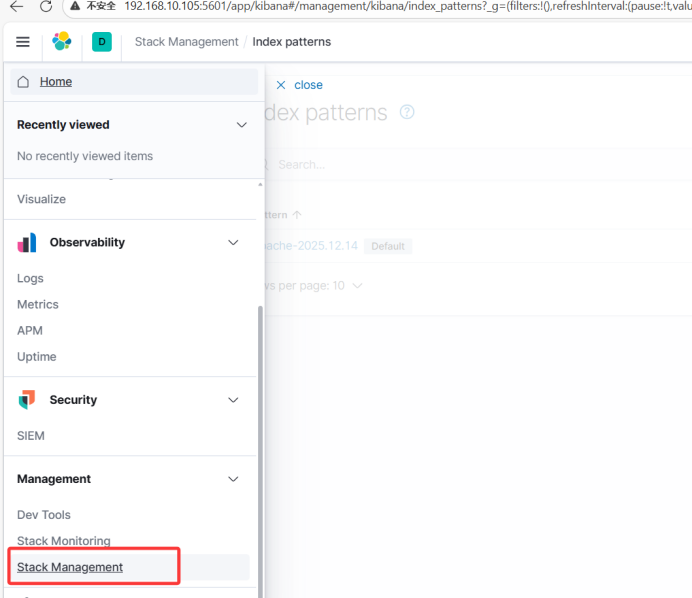
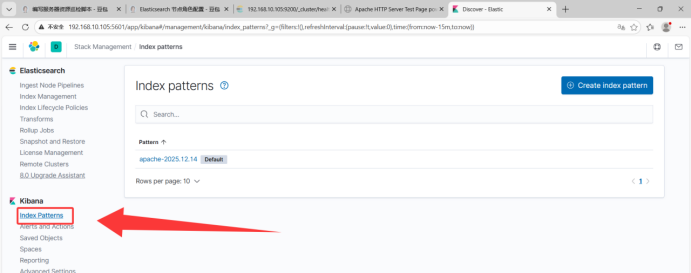
4.3、浏览器访问Kiabana流程
四、ELK+Filebeat部署
1、filebeat介绍
轻量级的开源日志文件数据搜集器。通常在需要采集数据的客户端安装 Filebeat,并指定目录与日
志格式,Filebeat 就能快速收集数据,并发送给 logstash 进或是直接发给 Elasticsearch 存储,性能上相比运行于 JVM 上的 logstash 优势明显,是对它的替代。常应用于 EFLK 架构当中。行解析
filebeat 结合 logstash 带来好处:
1)通过 Logstash 具有基于磁盘的自适应缓冲系统,该系统将吸收传入的吞吐量,从而减轻Elasticsearch 持续写入数据的压力
2)从其他数据源(例如数据库,S3对象存储或消息传递队列)中提取
3)将数据发送到多个目的地,例如S3,HDFS(Hadoop分布式文件系统)或写入文件
4)使用条件数据流逻辑组成更复杂的处理管道
缓存/消息队列(redis、kafka、RabbitMQ等):可以对高并发日志数据进行流量削峰和缓冲,这样
的缓冲可以一定程度的保护数据不丢失,还可以对整个架构进行应用解耦。
2、filebeat部署
bash
#1上传软件包 filebeat-7.8.1-linux-x86_64.tar.gz 到/opt目录
cd /opt
tar zxvf filebeat-7.8.1-linux-x86_64.tar.gz
mv filebeat-7.8.1-linux-x86_64/ /usr/local/filebeat
#2设置 filebeat 的主配置文件
vim /usr/local/filebeat/filebeat.yml
#===写入===
filebeat.prospectors: #7版本以上是filebeat.utils
- type: log
enabled: true
paths:
- /var/log/messages #指定监控的日志文件
- /var/log/*.log
fields: #可以使用 fields 配置选项设置一些参数字段添加到 output 中
service_name: filebeat
log_type: log
#标记 "这份日志是由 102 这台采集服务器采集的"
service_id: 192.168.10.102
--------------Elasticsearch output-------------------
(全部注释掉)
----------------Logstash output---------------------
output.logstash:
hosts: ["192.168.10.107:5044"] #指定 logstash 的 IP 和端口
#3启动 filebeat
cd /usr/local/filebeat
./filebeat -e -c filebeat.yml
bash
4、logstash写入配置文件
vim /etc/logstash/conf.d/logstash.conf
#写入
input {
beats {
port => "5044"
host => "0.0.0.0"
}
}
output {
elasticsearch {
hosts => ["192.168.10.105:9200"]
index => "%{[fields][service_name]}-%{+YYYY.MM.dd}"
}
stdout {
codec => rubydebug
}
}
#启动 logstash
cd /etc/logstash/conf.d/
logstash -f logstash.conf3、测试验证
Filebeat部署完成
总结
本文详解 ELK 7.8.1 核心组件、部署流程及 Filebeat 集成方案,助力搭建稳定的日志分析平台,提升运维与业务分析效率。