【数据操作与可视化】Serborn绘图-类别散点图和热力图
一、类别散点图
通过 stripplot()函数可以画一个散点图, stripplot0函数的语法格式如下。
sql
seaborn.stripplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, jitter=False)上述函数中常用参数的含义如下
- (1) x,y,hue:用于绘制数据的输入。
- (2) data:用于绘制的数据集。
- (3) jitter:表示抖动的程度(仅沿类別轴)。当很多数据点重叠时,可以指定抖动的数量或者设为True使用默认值。
为了让大家更好地理解,接下来,通过 stripplot()函数绘制一个散点图,示例代码如下。
ini
# 获取tips数据
tips = sns.load_dataset("tips")
sns.stripplot(x="day", y="total_bill", data=tips)运行结果如下图所示。
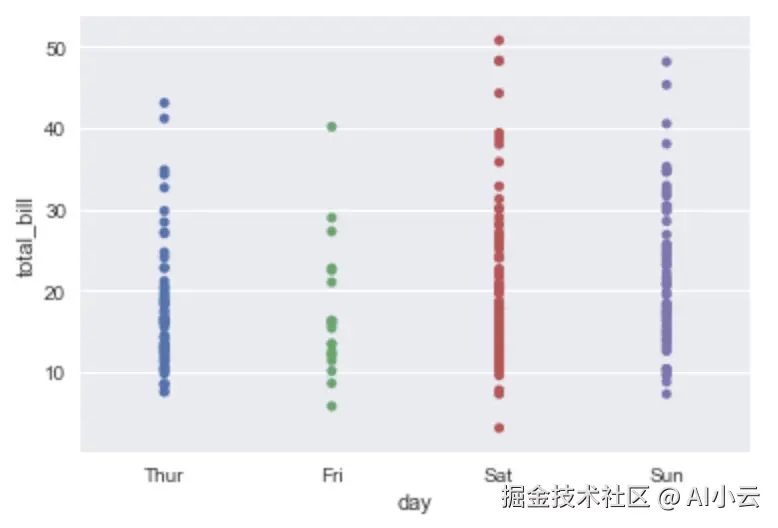
从上图中可以看出,图表中的横坐标是分类的数据,而且一些数据点会互相重叠,不易于观察。为了解决这个问题,可以在调用striplot()函数时传入jitter参数,以调整横坐标的位置,改后的示例代码如下。
ini
sns.stripplot(x="day", y="total_bill", data=tips, jitter=True)运行结果如下图所示。

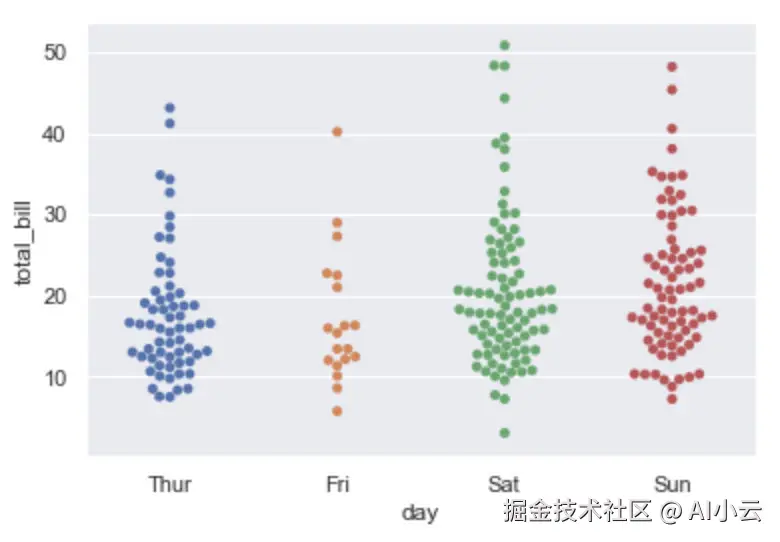
除此之外,还可调用 swarmplot0函数绘制散点图,该函数的好处是所有的数据点都不会重叠,可以很清晰地观察到数据的分布情况,示例代码如下。
ini
sns.swarmplot(x="day", y="total_bill", data=tips)运行结果如图所示。
二、热力图
基于advertising.csv的数据,利用matplotlib的热力图(heatmap)可以直观快速了解哪些列对销售额的影响最大,代码如下:
python
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
ads = pd.read_csv('./advertising.csv')
print(ads.head()) # 显示数据列名和少量数据
sb.heatmap(ads.corr(), annot=True) # corr:计算相关系数,annot=True,显示数字
plt.show()
从上图绘制的相关系数热力图来看,微信(wechat)的广告投放对销售额(sales)所产生的影响最大,也就是说微信广告的效果最好,微博次之,其他广告渠道最差。
当然,除了使用热力图来绘制相关性,我们也可以使用散点图来绘制两两影响,代码如下:
ini
sb.pairplot(ads, x_vars=['wechat', 'weibo', 'others'], y_vars='sales')
plt.show()
同样可以比较直观的看出,微信与销售额之间成更好的正相关,拟合度更高。同时,根据以上可视化图像,也可以辅助我们选择一个更为合适的函数进行拟合。