DeepAnalyze:首个开源自动数据科学 Agentic LLM
摘要:在大模型应用爆发的今天,如何让 AI 不仅能"陪聊",还能真正干活?DeepAnalyze 给出了答案。作为首个专门面向自动数据科学的 Agentic LLM(代理式大语言模型),它具备全流程数据分析能力,从数据清洗到生成专业报告一气呵成。本文将深度解析 DeepAnalyze 的核心功能、技术架构,并提供保姆级的本地部署教程。
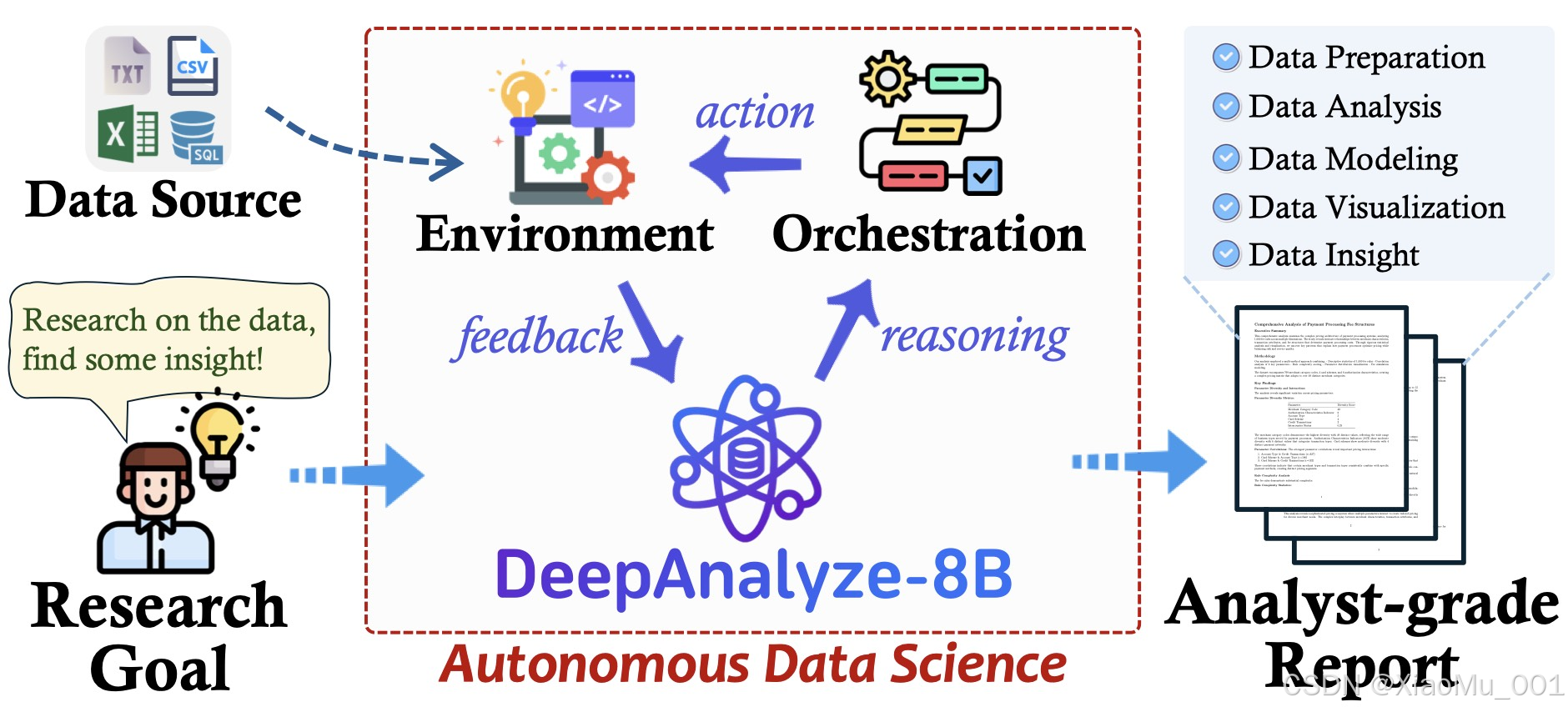
1. 项目背景与介绍
DeepAnalyze 是由 中国人民大学高瓴人工智能学院 (RUC DataLab) 联合 清华大学 共同推出的开源项目。它的定位非常明确:你的 AI 数据分析师。
传统的通用大模型(如 GPT-4, Llama 3)虽然具备编程能力,但在处理复杂的数据科学任务时,往往面临"幻觉"、"无法闭环"等问题。DeepAnalyze 则是专门为此优化的 Agentic LLM,它不仅仅生成文本或代码,更能像人类分析师一样,自主调用工具、执行代码、修正错误,最终产出可用的分析结果。
核心亮点
- 🤖 Agentic(代理式)能力:不仅是 Chatbot,更是能干活的 Agent。它能自主规划任务路径,遇到报错会自我 Debug。
- 🛠 全流程覆盖:支持数据准备、探索性数据分析 (EDA)、特征工程、机器学习建模、数据可视化、报告生成。
- 🔍 广泛的数据支持 :
- 结构化数据:SQL 数据库、CSV、Excel。
- 半结构化数据:JSON、XML、YAML。
- 非结构化数据:TXT、Markdown(支持文本挖掘与研究)。
- 🔓 完全开源:模型权重 (8B)、训练代码、训练数据、Demo 全部开源。
2. 核心功能详解
DeepAnalyze 的强大之处在于它将数据科学的工作流进行了标准化和自动化。
2.1 自动化数据科学管道 (End-to-End Pipeline)
用户只需上传数据并给出一个模糊的目标(例如:"分析这份财报的关键指标"),DeepAnalyze 会自动执行以下步骤:
- Schema Inference:自动读取文件头,理解数据结构。
- Plan Generation:生成分析计划(比如先做缺失值处理,再做相关性分析,最后画图)。
- Code Generation & Execution:生成 Python 代码(Pandas, Matplotlib, Scikit-learn 等)并在沙箱中执行。
- Self-Correction:如果代码运行报错,模型会读取 Traceback,分析原因并重新生成代码,直到运行成功。
- Report Generation:综合代码运行结果和图表,生成图文并茂的分析报告。
2.2 开放式数据研究 (Open-ended Data Research)
除了传统的表格分析,DeepAnalyze 还支持"研究模式"。你可以上传非结构化文档(如 PDF 转出的 TXT),让模型进行信息抽取、总结归纳或跨文档对比分析,生成分析师级别的研究报告。
3. 多样化的交互方式
项目提供了三种交互界面,满足不同用户群体的需求:
-
WebUI (浏览器界面):
- 类似 ChatGPT 的对话界面。
- 支持文件拖拽上传。
- 可视化展示生成的图表和报告。
- 适合大多数用户。
-
JupyterUI (Notebook 集成):
- 基于
jupyter-mcp-server构建。 - 可以直接在 Jupyter Lab 中使用。
- 将分析过程转换为 Markdown 单元格和 Code 单元格,直接执行。
- 适合专业数据科学家。
- 基于
-
CLI (命令行界面):
- 基于 Rich 库构建的精美终端界面。
- 支持流式输出。
- 适合服务器端操作或极客用户。
4. 本地部署实战 (保姆级教程)
DeepAnalyze 基于 Llama-3-8B 架构,官方提供了适配不同显存的量化方案。以下是在 Windows/Linux 环境下利用 vLLM 进行部署的详细步骤。
4.1 硬件要求
在开始之前,请检查你的显存 (VRAM) 是否满足要求:
| GPU 显存 | 模型版本 | 推荐 max-model-len | 说明 |
|---|---|---|---|
| 16GB | 4-bit 量化版 | 49,152 | ✅ 推荐入门配置 |
| 16GB | 8-bit 量化版 | 8,192 | 上下文较短 |
| 24GB (3090/4090) | 4-bit 量化版 | 131,072 | ✅ 支持超长上下文 |
| 24GB | 8-bit 量化版 | 98,304 | 性能平衡 |
| 40GB+ (A100) | 原始模型 | 131,072 | 最佳性能 |
4.2 环境准备
确保已安装 Python 3.8+ 和 CUDA 环境。推荐使用 Conda 创建虚拟环境:
bash
conda create -n deepanalyze python=3.10
conda activate deepanalyze
pip install vllm4.3 下载模型与代码
-
克隆项目仓库:
bashgit clone https://github.com/ruc-datalab/DeepAnalyze.git cd DeepAnalyze -
下载模型权重:
- Hugging Face: RUC-DataLab/DeepAnalyze-8B
- ModelScope: DeepAnalyze-8B
- 建议下载 4-bit 量化版本以节省显存。
4.4 启动后端服务 (vLLM)
使用 vLLM 启动兼容 OpenAI API 的服务。根据你的显存大小选择命令:
场景 A:16GB 显存 (使用 4-bit 量化)
bash
python -m vllm.entrypoints.openai.api_server \
--model /path/to/your/deepanalyze-4bit \
--served-model-name DeepAnalyze-8B \
--max-model-len 49152 \
--gpu-memory-utilization 0.95 \
--port 8000 \
--kv-cache-dtype fp8 \
--trust-remote-code(注意:请将 /path/to/your/deepanalyze-4bit 替换为你实际的模型路径)
场景 B:24GB 显存 (追求长上下文)
bash
python -m vllm.entrypoints.openai.api_server \
--model /path/to/your/deepanalyze-4bit \
--served-model-name DeepAnalyze-8B \
--max-model-len 131072 \
--gpu-memory-utilization 0.95 \
--port 8000 \
--kv-cache-dtype fp8 \
--trust-remote-code4.5 启动前端界面
启动 WebUI :
需要安装 Node.js。
-
进入前端目录安装依赖:
bashcd demo/chat/frontend npm install -
回到 chat 目录启动后端转发服务:
bashcd .. # Windows 用户可能需要手动运行 backend.py,Linux/Mac 用户直接运行 bash start.sh # 这里演示通用 Python 启动方式 python backend.py -
在另一个终端启动前端:
bashcd demo/chat/frontend npm run dev -
浏览器访问
http://localhost:4000(或终端提示的地址)。
启动 CLI (命令行) :
如果你不想折腾 Node.js,CLI 是最快的体验方式。
bash
# 确保 API Server (vLLM) 已经启动在 8000 端口
cd API
python start_server.py # 启动中间层服务
# 新开一个终端
cd demo/cli
python api_cli_ZH.py # 启动中文版 CLI5. 总结
DeepAnalyze 是目前开源社区中少有的、真正具备"数据分析师"职业素养的 Agent 模型。它不仅能够理解复杂的数据结构,更重要的是它具备了自我纠错 和工具使用的能力,这对于自动化数据科学任务至关重要。
无论是对于想要提升效率的数据分析师,还是希望在应用中集成高级数据分析功能的开发者,DeepAnalyze 都是一个值得深入研究和部署的优秀项目。
🔗 资源导航
- GitHub : https://github.com/ruc-datalab/DeepAnalyze
- 论文: DeepAnalyze: Agentic Large Language Models for Autonomous Data Science
- Hugging Face : RUC-DataLab