并发是一种同时处理很多事情的能力,并行是一种同时执行很多事情的手段。
并发状态下几种常见的工作模式:自由竞争模式、map/reduce 模式、DAG 模式:
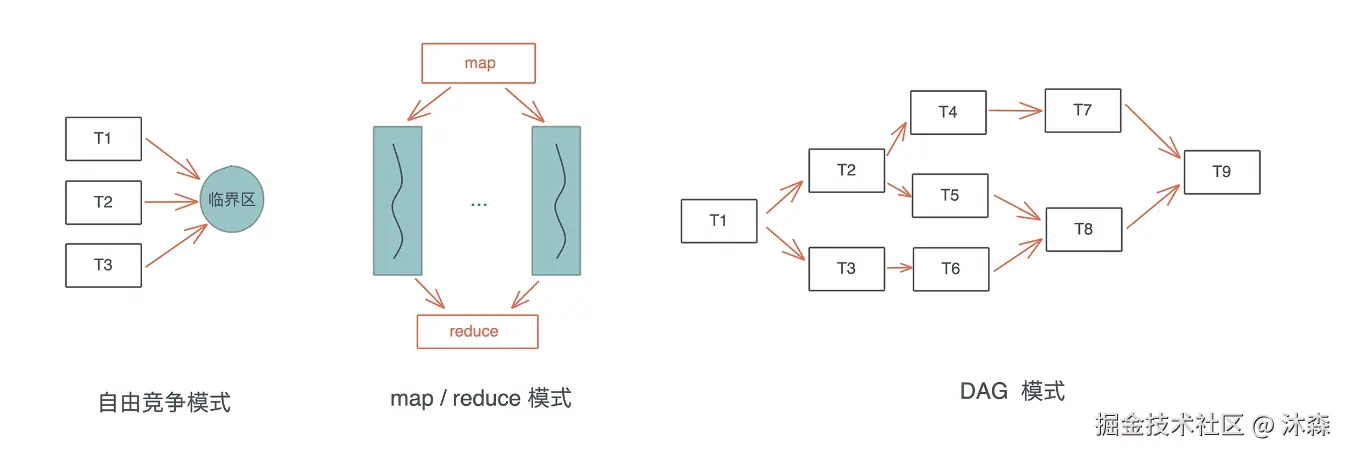
在自由竞争模式下,多个并发任务会竞争同一个临界区的访问权。任务之间在何时、以何 种方式去访问临界区,是不确定的,或者说是最为灵活的,只要在进入临界区时获得独占 访问即可。 在自由竞争的基础上,我们可以限制并发的同步模式,典型的有 map/reduce 模式和 DAG 模式。map/reduce 模式,把工作打散,按照相同的处理完成后,再按照一定的顺序 将结果组织起来;DAG 模式,把工作切成不相交的、有依赖关系的子任务,然后按依赖关系并发执行。
这三种基本模式组合起来,可以处理非常复杂的并发场景。所以,当我们处理复杂问题的时候,应该先厘清其脉络,用分治的思想把问题拆解成正交的子问题,然后组合合适的并发模式来处理这些子问题。
并发原语 Atomic、Mutex、Condvar、Channel 和 Actor mode
Atomic+Compare-and-swap(CAS) (原子操作) ------ "极速且独立的小任务"
这两个概念是并发编程中最底层、最硬核的基石
一、 Atomic(原子性):要么全做,要么不做
1. 问题的根源:i++ 其实是个谎言 在写代码时,你写了一句 count = count + 1(或者 count++),你觉得这是一步操作。 但在 CPU 眼里,这其实是三步:
- Read: 把内存里的
count值读到 CPU 寄存器里(比如读到 0)。 - Modify: 在 CPU 里把这个值加 1(变成 1)。
- Write: 把算好的 1 写回内存。
恐怖故事: 如果线程 A 和线程 B 同时做这件事:
- A 读到了 0。
- B 同时也读到了 0(因为它还没来得及变)。
- A 算出 1,写回内存。
- B 也算出 1,写回内存。
- 结果: 明明加了两次,内存里却是 1,而不是 2。数据"被吞了"。
2. Atomic 的超能力 Atomic(原子操作)就是一种魔法,它能强行把那"三步"合并成不可分割的一步。
-
比喻:瞬移。
- 普通操作像走路:你可能走到一半被绊倒,或者被人插队。
- Atomic 操作像瞬移:你要么还在原地(操作没发生),要么已经到了终点(操作完成了)。你永远不会处于"半路"的状态。
在 Rust 或 C++ 中,当你使用 AtomicI32 的 fetch_add 时,CPU 会保证:无论多少个线程同时抢,最后加出来的数一定是准的。
二、 CAS (Compare-and-Swap):一种"乐观"的赌徒心态
Atomic 是结果 (我们要实现原子性),那么 CAS 就是实现这个结果的手段(CPU 指令)。
CAS 全称是 Compare and Swap(比较并交换) 。它是无锁编程(Lock-free)的核心。
1. 它的逻辑是这样的
CAS 指令包含三个参数:
- 内存地址 (V) :你要改哪个变量?
- 期望值 (A) :你觉得它现在应该是多少?(旧值)
- 新值 (B) :你想把它改成多少?
CAS 的心里话(独白):
"我要把地址 V 里的数据改成 B。但是,除非地址 V 里的数据正如我所料,是 A,我才改。如果我发现 V 里的数据不是 A(说明被别人改过了),我就不改了,告诉我失败。"
2. 通俗案例:试衣间与挂牌
想象一个试衣间,门上挂着牌子,上面写着状态("空" 或 "有人")。
-
场景: 你想进去试衣服。
-
步骤 1 (Read): 你看了一眼牌子,写着"空"。
-
步骤 2 (Calculate): 你准备把牌子翻成"有人"。
-
步骤 3 (CAS 操作):
- 在你伸手去翻牌子的一瞬间(极短的时间),你必须再次确认: "牌子现在还是'空'字吗?"
- 情况一(成功): 是"空"。啪!你把它翻成了"有人",你进去了。
- 情况二(失败): 就在你低头的一瞬间,别人抢先冲进去把牌子翻成了"有人"。你伸手时发现牌子已经是"有人"了(与你期望的"空"不符)。操作失败,你不能翻牌子。
3. 失败了怎么办?(自旋 Loop)
CAS 最经典的使用模式是配合循环(Loop) 。
如果在试衣间门口失败了(CAS 返回 False),你通常不会回家,而是:
- 重新读取: 看看现在牌子是什么字(哦,是"有人")。
- 重新期望: 那我期望它变成"空"(等里面人出来)。
- 再次尝试 CAS: 一直试,直到成功为止。
这在代码里叫 CAS Loop 或者 自旋(Spin) 。
三、 总结:Atomic 和 CAS 的关系
- Atomic 是我们想要的安全感(保证数据不乱)。
- CAS 是 CPU 提供的底层指令 (比如 x86 的
cmpxchg指令),用来构建这种安全感。
它们与"锁"的区别:
- Mutex(锁): 是悲观的。它觉得肯定有人抢,所以先把门锁死,谁也别进,我改完了再开门。(线程会睡觉,切换开销大)
- CAS(原子): 是乐观的。它觉得应该没人抢,我直接去改改看。哎呀被抢了?没事,我重试一次。(线程一直醒着,在 CPU 上空转,响应极快,但如果冲突太剧烈会浪费 CPU)。
四、 那个著名的坑:ABA 问题
讲 CAS 必须讲 ABA,这是面试必考题,也是逻辑漏洞。
案例:你的私房钱 假设你有一个铁盒子,里面存了 100 块钱。
-
你 (线程 A) 看了一眼盒子:有 100 块。你准备存成 200 块。(期望 100,新值 200)。
-
就在这时,你老婆 (线程 B) 过来:
- 她拿走了 100 块去买菜。(盒子变 0)
- 她觉得自己花多了,又从这一百块里找零钱或者借钱,又放回去了 100 块。(盒子变回 100)。
-
你 (线程 A) 回过神来进行 CAS 操作:
- 检查盒子:咦?还是 100 块! (符合期望值)
- CAS 成功! 你把 100 改成了 200。
问题在哪? 虽然钱数是对的,但这 100 块已经不是原来的 100 块了! 盒子的状态其实发生了变化(可能中间夹带了一张收据,或者钱的新旧程度变了)。
在编程中的危害: 如果那个"100"是一个内存地址指针,ABA 问题可能导致你指向了一个已经被释放又被重新分配的内存块,程序会直接爆炸。
怎么解决? 加个版本号。 盒子不光写"100",还写着"版本 1"。老婆动过之后,变成"版本 2"。 你 CAS 的时候检查:期望是"100 且 版本 1"。如果发现是"100 且 版本 2",就知道被动过了。
我们把这两种情况(藏 vs 不藏)对 Atomic/CAS 操作的具体影响 做一个深度拆解。
情况一:不藏在指针里(外挂版本号 -> 变成宽数据)
这是你最关心的点。假设你的数据本身就是 64 位的(比如一个整数 usize),你又硬加了一个 64 位的 version。 现在的总数据量是:64位 + 64位 = 128位。
1. 对 CPU 硬件的影响(这是最大的瓶颈)
绝大多数普通 CPU 的通用寄存器只有 64 位宽。
- 标准 CAS 指令 (
cmpxchg): 一次只能搬运 64 位。它根本搬不动 128 位的数据。 - 强行搬运的后果: 如果你没有特殊指令支持,你无法保证这 128 位是"同时"变化的。可能改了前 64 位,后 64 位还没改,这时候别的线程读进来,数据就裂开了(Tearing)。
2. 解决方案:必须动用"重型武器"
为了处理这种 128 位的情况,CPU 厂商(Intel/AMD/ARM)提供了特殊指令,比如 x86 上的 CMPXCHG16B(Compare and Exchange 16 Bytes)。
- 影响 A - 兼容性问题: 并不是所有 CPU 都支持这个指令(虽然现代桌面 CPU 都支持,但在一些嵌入式或老旧架构上会直接报错)。
- 影响 B - 性能开销: 这种双倍宽度的原子操作,比普通的 64 位 CAS 要慢一些(虽然还是很快,但在极高并发下能测出差距)。
- 影响 C - 内存对齐(Alignment): 这是很多 Rust/C++ 开发者的噩梦。使用 128 位原子操作时,操作系统要求这个变量在内存中的地址必须是 16字节对齐 的。如果没对齐,CPU 会抛出异常,程序直接崩盘(Panic)。
3. Rust 中的体现
在 Rust 中,如果你想做这种操作,通常需要使用 AtomicU128(目前在某些平台上还是不稳定特性 unstable,或者需要特定 CPU feature 开启)。
情况二:藏在指针里(Pointer Tagging / 压缩流)
这就是所谓的"把版本号塞进指针没用的位里"。
1. 为什么能藏?
现在的 64 位电脑(x86-64),虽然指针也是 64 位长,但其实只用了低 48 位 来寻址,高 16 位全是 0(或者全是 1)。
2. 对 Atomic/CAS 的影响(极小)
-
硬件层面: 因为你把版本号塞进去了,整体长度依然是 64 位 。 所以,你可以直接使用最普通、最快、兼容性最好的标准 CAS 指令。硬件毫无压力。
-
代码层面(这是麻烦点): 影响在于你取数据的时候。
- 存的时候: 要做位运算(拼装):
ptr | (version << 48) - 取的时候: 要做位运算(拆解):
val & 0x0000FFFFFFFFFFFF - 如果你忘了拆: 直接拿这个带脏数据的指针去读内存,程序立刻段错误(SegFault)崩溃,因为它指向了一个不存在的非法地址。
- 存的时候: 要做位运算(拼装):
3. 版本号溢出风险
因为只有 16 位空间给你藏,版本号最多到 65535。如果高并发下变化极快,版本号瞬间转完一圈回到 0,ABA 问题会复活。
情况三:如果我又不想藏,CPU 又不支持 128 位怎么办?
这就是最大的影响 ------你不能再单纯用 CAS 了。
很多初学者会想:"我能不能搞两个 Atomic 变量,一个存钱,一个存版本?"
Rust
yaml
struct SafeMoney {
money: AtomicU64,
version: AtomicU64,
}绝对不行! 因为你无法同时锁住这两个变量。
- 线程 A 改了
money(CAS 成功)。 - (时间间隙) 线程 B 读了
money。 - 线程 A 改了
version。
在这个"时间间隙"里,数据处于不一致状态。这就不是原子操作了。
此时的唯一解法: 退回到使用 Mutex(互斥锁)。哪怕再慢,也得用锁把这两个变量包起来,变成一个整体。
总结:CAS 对 Atomic 的影响表
| 方案 | 数据形态 | 硬件 CAS 指令 | 影响/代价 | 适用场景 |
|---|---|---|---|---|
| 标准 CAS | 仅数据 (64位) | 普通 cmpxchg |
无。最快,原生支持。 | 不担心 ABA 的简单计数器 |
| 指针标记 | 数据+版本挤在 64位里 | 普通 cmpxchg |
代码复杂。需要位运算,版本号空间小。 | 链表、栈、队列 (Treiber Stack) |
| 双宽 CAS | 数据+版本 = 128位 | 特殊 cmpxchg16b |
兼容性/对齐。部分平台不支持,必须16字节对齐。 | 需要完整版本号的复杂结构 |
| 分开存 | 数据 Atomic, 版本 Atomic | 无 (做不到) | 逻辑错误。无法保证两者同时变。 | 不可用,必须换成锁 |
所以,你在设计 Rust 高并发结构时,如果能用 Pointer Tagging(藏在指针里) 是最高效的;如果藏不下,就要考虑能不能用 AtomicU128;如果还不行,就老老实实用 Mutex 吧。
二. Mutex
精准地概括现代 Mutex(互斥锁)的两个核心痛点: "公平性问题" 和 "底层实现原理" 。
为了让你彻底理解这段话,我们继续用生活中的例子来拆解。我们将场景设定为:只有一把钥匙的公共休息室。
一、 为什么会有"不公平"?(Spin vs. Wait)
提到的第一段话描述了一个非常经典的**"插队"**(Barging)现象。
1. 角色分配
- 休息室(Critical Section): 被保护的数据/代码。
- 钥匙(Lock): Mutex。
- 老王(持有锁的线程): 正在休息室里休息。
- 小李(等待队列中的线程): 之前来了发现没钥匙,被挂起(Sleeping),坐在门口的长椅上睡着了。
- 小张(新来的 Spin 线程): 刚刚到达,精力旺盛,正在门口转悠(Spinning),还没去长椅上睡觉。
2. 剧情演绎:由于"时机巧合"导致的插队
- 老王出来了: 他推开门,大喊一声:"我好了,谁是下一个?"(这是 Mutex 唤醒队列的操作)。
- 小李被唤醒: 睡在长椅上的小李迷迷糊糊地睁开眼,准备起身,伸个懒腰,走向门口。(注意: 从睡眠到唤醒再到抢锁,需要操作系统介入,这个过程叫上下文切换,虽然很快,但需要时间,比如 5 微秒)。
- 小张的骚操作: 就在老王刚扔下钥匙、小李还没完全站起来的这 0.1 秒 间隙里,一直在门口转悠的小张眼疾手快,一把抓住了钥匙冲进了休息室!
- 结果: 等小李终于走到门口,发现门又锁了!小李心态崩了,只能回到长椅上继续睡。
3. 为什么默认 Mutex 允许这样?
会觉得这不公平,小张明明刚来,凭什么插队? 但在计算机眼里,这为了效率(吞吐量) 。
- 唤醒小李需要时间(CPU 切换开销)。
- 小张已经在 CPU 上跑着了(热数据)。
- 让小张先把活干完,CPU 就不需要空转等待小李醒来。整体上,休息室的使用率更高了。
二、 parking_lot 的 Fair Mutex 是什么?
提到的 parking_lot 是 Rust 中一个性能极强的并发库。它提供的 Fair Mutex(公平锁) 就是为了整治小张这种"插队"行为。
1. 它的规则:严格排队
在 Fair Mutex 模式下,规则变了:
- 当老王扔出钥匙时,他不是把钥匙扔在地上谁抢到算谁的。
- 他是直接把钥匙递给长椅上的第一位(小李) 。
- 或者,即使钥匙在地上,新来的小张 如果看到长椅上有人坐着,必须自觉去长椅后面排队,绝对不允许去抢钥匙。
2. 代价
- 优点: 绝对公平(FIFO),先来后到,不会出现小李永远抢不到锁饿死(Starvation)的情况。
- 缺点: 可能会稍微慢一点点,因为必须要等小李醒过来(上下文切换的开销无法避免了)。
三、 Mutex 与 Atomic 的关系:大锁包小锁
提到的最后一句非常有深度: "你可以把 Mutex 想象成一个粒度更大的 atomic,只不过这个 atomic 不是 cpu 保证的,而是软件算法实现的。"
这句话揭示了 Mutex 的本质架构。
我们可以把 Mutex 看作一个洋葱结构,由内而外分为两层:
1. 内核(硬件层):Atomic
Mutex 的最核心部分,就是一个简单的 Atomic Bool(或者 Atomic Integer)。
- 作用: 仅仅用来标记"有人"还是"没人"。
- 操作: 使用 CPU 的
CAS指令瞬间把0改成1。 - 局限: 它只能告诉你"改成功了"还是"失败了"。如果失败了,它不管你,你只能不停地试(Spin)。
2. 外壳(软件/系统层):Waiting Logic
单纯的 Atomic 如果一直抢不到锁,CPU 会一直空转(像小张一样在门口转圈),这会把电脑发热烧穿。 Mutex 在 Atomic 外面包裹了一层**"睡眠/唤醒逻辑"**:
- 逻辑: 如果我用 Atomic
CAS抢锁失败了,我不要一直傻转。我去求操作系统(OS Kernel):"把我挂起(Park/Sleep),等锁空出来了叫醒我。" - 工具: 在 Linux 上这叫
futex,在 Windows 上叫KeyedEvent。
总结图解
| 维度 | Atomic | Mutex |
|---|---|---|
| 是什么 | 硬件指令 (CPU 层面) | 软件数据结构 (操作系统/库层面) |
| 包含内容 | 仅仅是一个 0/1 的开关 | 开关 (Atomic) + 等待队列 (Queue) + 调度逻辑 |
| 抢不到怎么办 | 只能重试 (Spin) | 可以选择睡觉 (Sleep/Park) |
| 比喻 | 门把手上的锁芯 | 包含了锁芯、门卫、等候区的一整套管理系统 |
一句话总结: Mutex 就是利用 Atomic 这一块"硬砖头",配合操作系统的调度能力,盖出了一间既能锁门、又能让排队的人有地方睡觉的"房子"。
-
Mutex / RwLock (互斥锁):
- 角色: 房间的门锁。一次只能进一个人。
- 并行性: 它是并行的杀手。在锁的范围内,代码被迫变成串行(Serial)。如果你到处用 Mutex,你的多核 CPU 就退化成了单核。
-
Condvar (条件变量):
- 角色: 信号枪。线程 A 说"我没拿到数据,我睡了",线程 B 做完事后开一枪"数据好了,醒醒"。
- 作用: 用于线程间的等待/唤醒协调,是并发调度工具。
2. 对讲机与快递:解耦与通信 (Communication)
这部分是为了让不同的任务之间能够协作。它们不直接产生并行,但它们让并行成为可能(没有通信的并行是瞎子)。
-
Channel (通道 / CSP模式):
- 角色: 传送带。
- Rust 特色:
mpsc(Multi-producer, Single-consumer)。 - 并行关系: 生产者和消费者可以在不同的核心上并行工作,Channel 负责安全地传递数据。这是实现"流水线并行"的关键。
-
Actor Mode (演员模型):
- 角色: 独立的办事员。每个 Actor 有自己的邮箱,只处理发给它的信。
- Rust 生态: 比如
Actix库。 - 并行关系: 每个 Actor 可以跑在不同的线程上。这是一种非常高级的并发架构,天然支持分布式和并行。
3. 战略图纸:真正的并行设计 (Parallelism Patterns)
这里是提到的**"设计并行"的地方。这些不是具体的"锁"或"变量",而是组织代码结构的方法**,目的是为了把任务拆散,塞满所有的 CPU 核心。
-
Free Competition (自由竞争 / 任务抢占):
- 模式: 比如线程池(Thread Pool)。丢进去 100 个任务,由 8 个工人(核心)去抢。
- Rust: 这里的典型是
tokio(虽然主要用于异步 IO 并发) 或rayon的底层的 Work-stealing(工作窃取)机制。这是任务并行。
-
Map/Reduce (映射/归约):
-
模式:
- Map: 把一个大数组切成 8 份,8 个核同时处理(这是纯粹的数据并行)。
- Reduce: 把 8 个结果汇总起来。
-
Rust 神器:
Rayon。这是 Rust 界做并行的标准答案。你只需要把.iter()改成.par_iter(),代码就从单核变成了多核并行。
-
-
DAG (有向无环图):
- 模式: 任务 A 做完,触发 B 和 C 同时做(并行),B 和 C 都做完,触发 D。
- Rust: 这种模式用于复杂的任务依赖并行。Rust 的构建工具 Cargo 编译你的代码时,就是用 DAG 模式:互不依赖的 crate 就在不同核心上并行编译。
简单总结
| 概念 | 它是干嘛的? | 与并行的关系 |
|---|---|---|
| Atomic / Mutex | 保命的 (Safety) | 防止并行出车祸,局部阻止并行 |
| Condvar | 调度的 (Signaling) | 协调暂停和开始 |
| Channel / Actor | 传话的 (Communication) | 连接并行的岛屿 |
| Map/Reduce | 搞生产的 (Data Parallelism) | 真正的并行:把大象切块分给多人搬 |
| DAG | 搞管理的 (Task Parallelism) | 真正的并行:安排谁先谁后,能同时做的尽量同时做 |
Atomic 虽然可以处理自由竞争模式下加锁的需求,但毕竟用起来不那么方便,我们需要更 高层的并发原语,来保证软件系统控制多个线程对同一个共享资源的访问,使得每个线程 在访问共享资源的时候,可以独占或者说互斥访问(mutual exclusive access)。
1. 共享状态:Arc + Mutex
总结: "lock解锁" 补充细节(关键):
-
Arc (拿号): 负责搬运。没有它,所有权规则不允许你把同一个变量塞给 10 个线程。它让大家都有合法的"引用"。
-
Mutex (开门): 负责互斥。
-
自动解锁 (RAII): Rust 最酷的地方在于你不需要写
unlock()。lock().unwrap()是上锁。- 解锁 是隐式的:当持有锁的那个变量(比如代码里的
data)离开{ ... }作用域时,Rust 自动帮你解锁。 - 不用怕忘了解锁导致死锁,编译器帮你管着。
2. 线程同步:join()
总结: "等待" 补充细节(关键):
- 主线程的耐心:
main函数本身也是一个线程。如果main跑完了,它不会等子线程,直接杀进程退出。 join()就是让main线程卡在这里(Block) ,直到子线程跑完交差。它是防止"烂尾工程"的兜底机制。
3. 消息传递:mpsc::channel
总结: "let (tx,rx)=...; clone,然后消费rx" 补充细节(关键):
-
克隆谁? 只能克隆
tx(发送端),这就是 M ulti-P roducer (多生产者)。rx(接收端) 必须独享。 -
所有权转移:
tx.send(val)之后,val就归rx了,原来的线程再也碰不到它。这是为了安全。 -
断开信号:
rx的for循环什么时候停?只有当所有的tx都被drop掉之后,rx才会知道"没人发消息了",从而结束循环。- 坑点:这就是为什么主线程里要
drop(tx),否则rx会一直等下去。
- 坑点:这就是为什么主线程里要
4. 数据并行:Rayon
总结: "就是一个 iter(),par_iter() 属性的不一样是吧" 补充细节(关键):
-
一字之差,天壤之别:
.iter()= 单核串行(老牛拉车,一步一步走)。.par_iter()= 多核并行(车队出发,任务自动切块分发)。
-
Work-Stealing (工作窃取): 你不需要告诉 Rayon 怎么分。如果核 A 算完了,它会去帮还没算完的核 B 偷任务做。
-
无锁: 在
map/reduce的过程中,通常不需要 Mutex,因为大家各算各的,互不干扰,速度最快。
极简记忆表
| 场景 | 代码关键词 | 核心逻辑 | 这里的"锁" |
|---|---|---|---|
| 抢资源 | Arc<Mutex<T>> |
大家改同一个值 | Mutex (显式锁,必须排队) |
| 流水线 | mpsc / tx.clone() |
我做完给你 | Ownership (所有权转移就是一种锁) |
| 压榨CPU | par_iter() |
大家各算各的 | 无锁 (Lock-free,速度最快) |
第一步:看任务类型(是在"算"还是在"管"?)
1. 如果你的任务是:暴力计算(CPU 密集型)
-
特征: 你有一个巨大的数组、列表、图片像素点,你要对里面的每一个元素做相同的操作(比如平方、滤镜、加密)。而且算出第一个元素的结果,不影响第二个元素。
-
关键问句: "这个大循环能拆开各算各的吗?"
-
你的选择: Rayon (
par_iter) -
Electron 场景:
- 用户上传了 100 张高清图片,你要把它们全部压缩成缩略图。
- 你要扫描硬盘里的 10 万个文件,计算它们的 MD5 哈希值。
2. 如果你的任务是:逻辑协调(IO 密集型 / 流程型)
- 特征: 任务没那么重,但是逻辑很复杂。涉及多个模块之间的配合,比如"A 模块下载完,通知 B 模块解压,B 解压完通知 C 模块入库"。
- 关键问句: "这些线程之间需要说话吗?"
- 你的选择: Channel (
mpsc) 或 Mutex(进入下一步)。
第二步:看数据流向(是在"传球"还是在"抢球"?)
如果任务属于上面的第 2 类(逻辑协调),你需要进一步判断:
1. 传球模式 (Pipeline)
-
特征: 数据在一个线程产生,处理完后,交给下一个线程。原来的线程就不再关心这个数据了。
-
比喻: 厨师炒好菜(生产者),递给传菜员(Channel),传菜员端给客人(消费者)。厨师炒完就不管那盘菜了。
-
你的选择: Channel (
mpsc) -
Electron 场景:
- 日志系统: 任何线程报错,都把错误信息塞进 Channel,主线程专门负责把 Channel 里的字写进
.log文件。 - 下载器: 线程 A 负责下载数据块,下载好一块就塞进 Channel,线程 B 负责把收到的数据块拼接写入硬盘。
- 日志系统: 任何线程报错,都把错误信息塞进 Channel,主线程专门负责把 Channel 里的字写进
2. 抢球模式 (Shared State)
-
特征: 这一份数据,大家都要读,大家都要改。它必须静止在那里,谁用谁拿。
-
比喻: 公司的会议室。销售部要用,研发部也要用。谁抢到钥匙谁进去,进去锁门,用完出来还钥匙。
-
你的选择: Arc + Mutex
-
Electron 场景:
- 全局配置: 用户在设置里改了
theme = "dark",所有线程都需要读取这个配置,偶尔也要修改它。 - 连接池/缓存: 维护一个数据库连接池,所有线程都要去池子里借连接,用完放回去。
- 全局配置: 用户在设置里改了
第三步:决策总结表(一秒速查)
| 痛点 | 典型特征 | 推荐工具 | 为什么? |
|---|---|---|---|
| 我要算得快 | 大数组、图像处理、矩阵运算 | Rayon | 它是专门为利用多核 CPU 算力设计的,且无锁,最快。 |
| 我要解耦 | 流水线、日志、消息通知、单向流动 | Channel | 让线程各司其职,避免竞争,代码最干净。 |
| 我要共享 | 全局状态、缓存、计数器、状态机 | Mutex | 没办法,这就是必须"排队"的场景。 |
结合 Electron + Rust 项目的实战建议
既然做的是 Electron 应用,Rust 通常作为后端(Node.js 的 NAPI 插件)存在。以下是三个经典场景的"最佳实践":
-
场景:搜索本地文件(Everything 模式)
- 需求: 遍历 C 盘 100 万个文件,找出名字含 "test" 的。
- 选型: Rayon。
- 理由: 文件系统的遍历和字符串匹配是并行的。用
par_iter可以让 8 个核同时去扫不同的文件夹。
-
场景:Rust 告诉 Electron 进度条
- 需求: Rust 在后台解压大文件,需要每秒告诉 Electron 前端"进度 50%"。
- 选型: Channel (Rust 侧) + Callback/Promise (NAPI 侧)。
- 理由: 解压线程(生产者)算出进度,通过 Channel 发给主线程,主线程再调用 JS 的回调函数通知前端。千万不要让解压线程直接去调 JS 函数(跨语言调用通常要求在主线程)。
-
场景:App 的状态管理
- 需求: 记录当前有多少个正在进行的任务,用户点"暂停"时,所有线程都要停。
- 选型: Arc<Mutex> 。
- 理由:
is_paused是一个全局布尔值,所有干活的线程每干一步都要检查它。这就是典型的共享状态。