最近公司正在推荐Ai相关项目,目前主要是大模型相关的应用层面开发,但自己还是希望能够基础入手,全方位了解一下机器学习,深度学习,强化学习,自然语言,大模型等Ai相关的知识点,仅了解相关概念,不去深入了解算法实现。本文主要介绍一下机器学习的基本概念。
什么是机器学习
引用周志华带佬的机器学习一书提到的案例,我们在生活中挑选西瓜的时候,经常会假嘛若鬼地敲一下西瓜,听一听声音,如果发出 "嘭嘭" 的闷声,说明西瓜成熟度好,果肉饱满。若发出 "当当" 的清脆声,可能西瓜还未成熟;若发出 "噗噗" 声,则可能西瓜内部已过度成熟或有腐烂现象。也有老手看外观,看瓜蒂,根茎,表皮,掂重量等操作,
这些都是经验之谈,都是人类从大量实验中探索出来的规律与模式。这一过程在人工智能中的实现就是机器学习。
机器学习是计算机基于数据构建概率统计模型并运用模型对数据进行预测与分析的学科。
机器学习基本术语
我们还是以西瓜为例,其数据如下:
| 形状 | 色泽 | 瓜皮 | 敲声 | 瓜蒂 |
|---|---|---|---|---|
| 椭圆 | 青绿 | 硬 | 嘭嘭 | 粗壮 |
| 圆形 | 绿色 | 硬 | 嘭嘭 | 蜷缩 |
这些数据,每条数据都是关于一个西瓜的描述,形状,色泽,瓜皮,敲声,瓜蒂都是这条数据的属性(Attribute) ,属性的取值称为属性值(Attribute Value) ,不同的属性值有序排列得到的向量就是数据,也叫实例(Instance)或者叫做样本(Sample) 。
形状,色泽,瓜皮,敲声,瓜蒂作为五个坐标轴,这就是一个描述西瓜的五维空间,这些维度组成了特征空间(Feature Space) ,每一组属性值的集合都是这个空间中的一个点,所以我们也把每一个样本都称为特征向量(Feature Vector)。
我们知道,机器学习可说是从数据中来,到数据中去,需要机器学习能够从数据中学习得到一个模型,这个过程就叫做学习(Learning)或者训练(Training), 参与训练的数据被称为训练集(training data) ,其中每个样本都被称为训练样本(training sample) 。
我们训练出来的模型,到底效果如何,这个时候需要一部分数据进行验证(Validate) ,参与验证的数据则被称为验证集(Validation Data) ,其中每个样本都被称为验证样本(Validation Sample) 。
最后,我们如何对未知的数据进行推理判断,要判断一个未被剥开的瓜是好瓜还是坏瓜,这个过程叫做预测(Prediction) 或者叫做推理(Inference) 。
机器学习分类
如果我们仅对瓜判断好坏,这类的值为离散值,那么此类学习任务称为分类 。瓜的好坏分类只有两种,一个是好,一个是坏,对于只有两个类别的任务,被称为二分类 。涉及到多个类别时,则称为多分类。
如果我们是对瓜的成熟度进行判断,例如瓜的成熟度为0.95,0.37,这类的值为连续值,那么此类学习任务称为回归,输入变量和输出变量均为连续变量。
我们还可以对瓜做聚类(Clustering) ,即将训练集中的西瓜分成若干组,每组称为一个簇(Cluster) 。把瓜可以分为浅色瓜,深色瓜,但是在聚类学习过程中,这些概念咱们事先是不知道,所以我们需要先标注。 这一类任务,被称为聚类任务 ,也可以是标注任务,输入变量和输出变量均为变量序列。
根据是否标注,可以将学习任务分为两大类:
- 监督学习:基于已知类别的训练数据进行学习;
- 无监督学习:基于未知类别的训练数据进行学习;
还有一种就是半监督学习:同时使用已知类别和未知类别的训练数据进行学习。
监督学习的主要代表就是分类和回归,无监督学习的主要代表就是聚类。
另外还有深度学习,强化学习
- 深度学习:深度学习是机器学习的一个子领域,专注于应用多层神经挽留过进行学习,深度学习擅长处理复杂的数据如图像、音频、文本,因此在AI中的应用非常有效;
- 强化学习:强化学习是一种通过与环境交互,并基于奖励和惩罚机制来学习最优策略的方法。强化学习算法通过试错法来优化决策过程,以实现最大化累积奖励。常见算法包括Q-Learning、策略梯度和DQN等。
机器学习整体流程
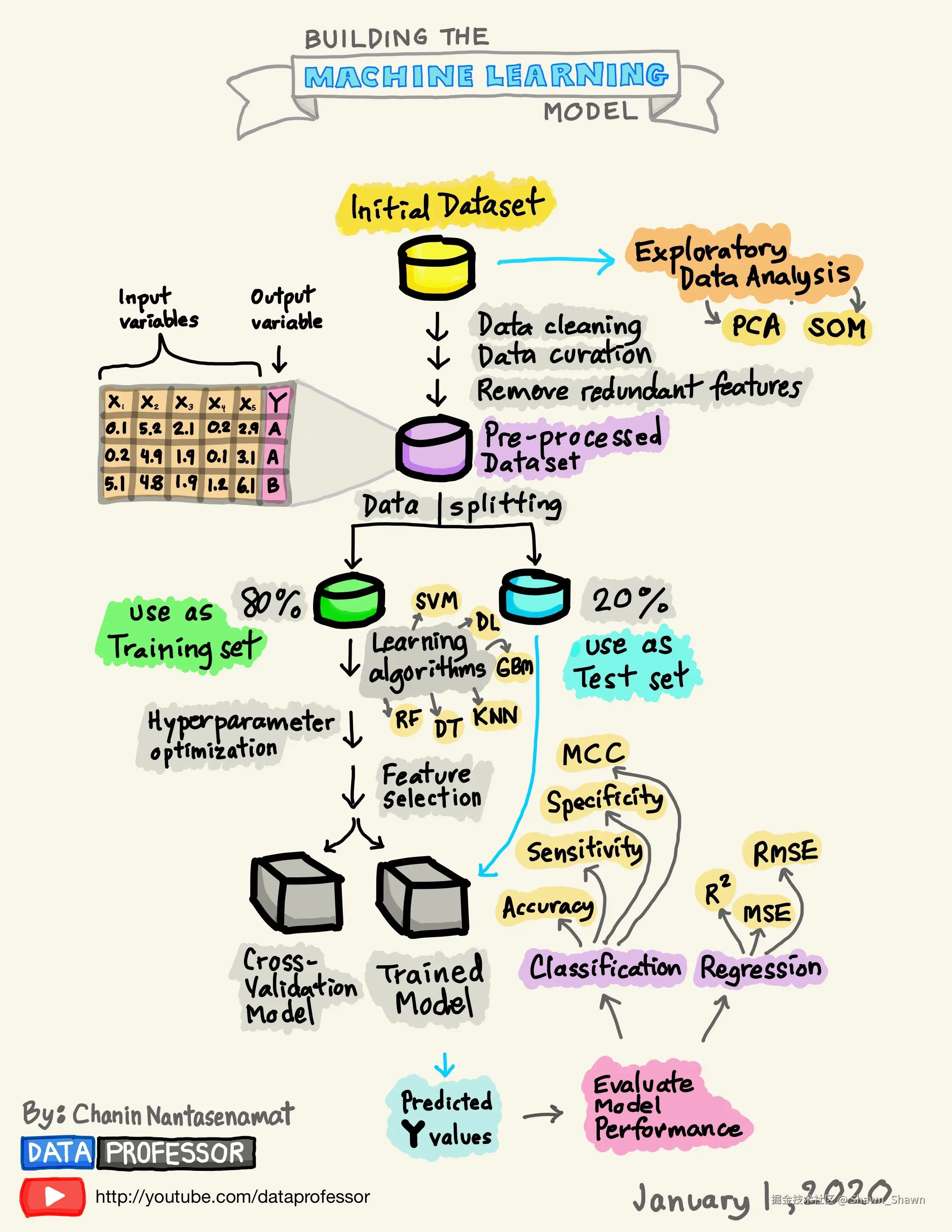
准备数据集
在做机器学习算法的时候,第一步就是要做数据集准备,有了数据集之后,可以做探索性数据分析(Exploratory Data Analysis),也可以做数据预处理(Pre-Processed Dataset)。
探索性数据分析
进行探索性数据分析(Exploratory data analysis, EDA)是为了获得对数据的初步了解。EDA主要的工作是:对数据进行清洗,对数据进行描述(描述统计量,图表),查看数据的分布,比较数据之间的关系,培养对数据的直觉,对数据进行总结等。
探索性数据分析方法简单来说就是去了解数据,分析数据,搞清楚数据的分布。主要注重数据的真实分布,强调数据的可视化,使分析者能一目了然看出数据中隐含的规律,从而得到启发,以此帮助分析者找到适合数据的模型。
通常使用的三大EDA方法包括:
- 描述性统计:平均数、中位数、模式、标准差。
- 数据可视化:热力图(辨别特征内部相关性)、箱形图(可视化群体差异)、散点图(可视化特征之间的相关性)、主成分分析(可视化数据集中呈现的聚类分布)等。
- 数据整形:对数据进行透视、分组、过滤等。
数据预处理
数据预处理,其实就是数据治理,对数据进行清理、数据整理或普通数据处理。指对数据进行各种检查和校正过程,以纠正缺失值、拼写错误、使数值正常化/标准化以使其具有可比性、转换数据(如对数转换)等问题。
数据的质量将对机器学习算法模型的质量好坏产生很大的影响。因此,为了达到最好的机器学习模型质量,传统的机器学习算法流程中,其实很大一部分工作就是在对数据进行分析和处理。
数据预处理的主要目的就是:减少噪音数据对训练数据的影响。
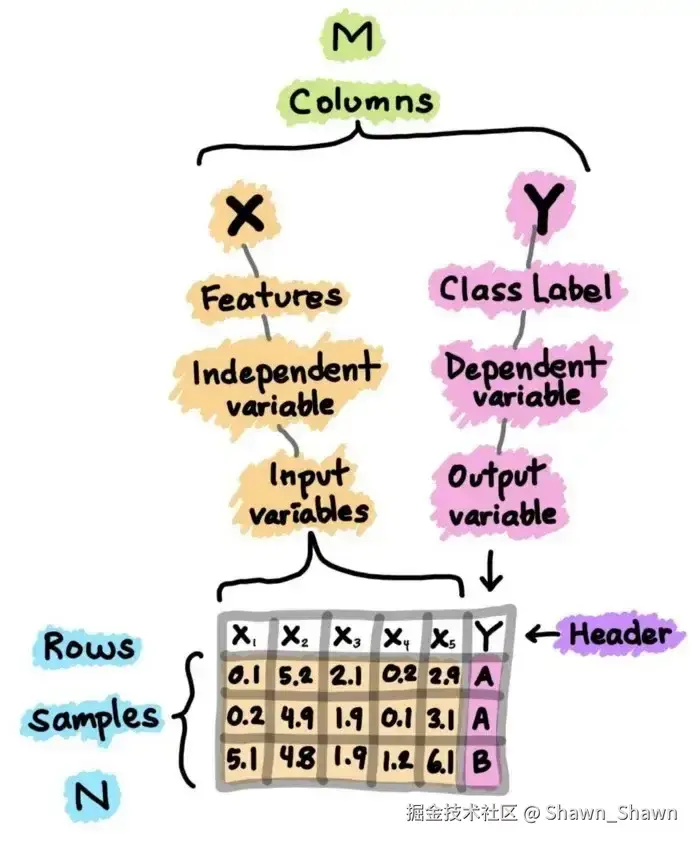
数据集本质上是一个M×N矩阵,其中M代表列(特征),N代表行(样本)。列主要有两部分组成,x和y,x为特征/独立变量/输入变量,y为类别标签/依赖变量/输出变量
数据分割
需要把预处理完成的数据,按照一定的规则,将完整的数据分割成训练集和验证集。

或者分割成训练集和验证集以及测试集
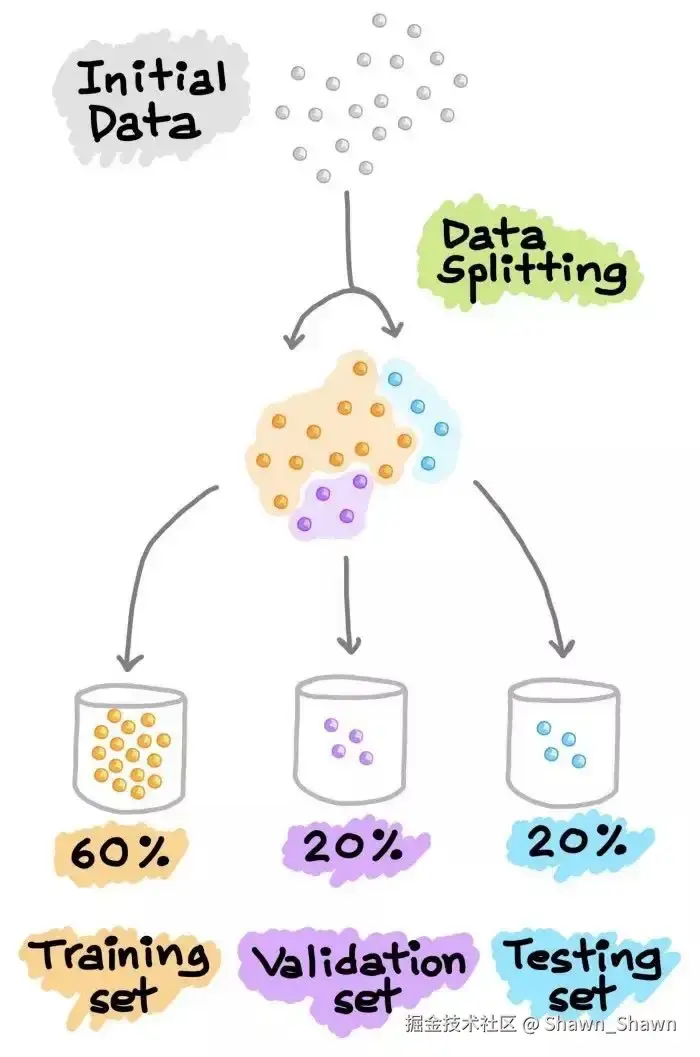
一般数据集分割的比例也如上图所示:
- 训练集/验证集:80%/20%
- 训练集/验证集/测试集:60%/20%/20%
模型训练
数据分割成训练集和验证集之后,就可以使用训练集,选择机器学习算法进行模型训练
常见的机器学习算法有:
- SVM:支持向量机
- KNN:k近邻算法(KNN)
- DL:深度学习
- GBM:Grandient Boosting Machine,机器学习梯度推进机
- RF:Random Forest,随机森林
- DT:Decision Tree,决策树
决定模型训练的好坏主要有两种手段:
- 超参数调优
- 特征工程
超参数
超参数是算法工程师用来管理机器学习模型训练的外部配置变量。有时也称为模型超参数,超参数会在训练模型前手动进行配置。与参数不同,超参数是在学习过程中自动导出的内部参数,而不是由数据科学家设置的。
常见的超参数有:
- 学习率是指算法更新估算值的速率
- 学习率衰减是指随着时间的推移,逐渐降低学习率,以加快学习速度
- 小批次大小是指训练数据批次大小
- Epoch 是模型一次训练的轮数
- Eta 是指用于防止过拟合的收缩步长
超参数调优手段有:
- 贝叶斯优化:贝叶斯优化是一种基于贝叶斯定理的技术,它描述了与当前知识相关的事件发生的概率。将贝叶斯优化用于超参数优化时,算法会从一组超参数中构建一个概率模型,以优化特定指标。它使用回归分析迭代地选择最佳的一组超参数。
- 网格搜索:借助网格搜索,您可以指定一组超参数和性能指标,然后算法会遍历所有可能的组合来确定最佳匹配。网格搜索很好用,但它相对乏味且计算量大,特别是使用大量超参数时。
- 随机搜索:虽然随机搜索与网格搜索基于相似的原则,但随机搜索在每次迭代时会随机选择一组超参数。当相对较少的超参数主要决定模型的结果时,该方法效果良好。
特征工程
特征工程是机器学习中最重要的一部分,因为根据已有的训练数据,可选用的算法是有限的;那么在同样的算法下特征的选取是不同的,100个人对一件事情会有100种看法,也就有100种特征,最后特征的质量决定模型的好坏。
特征工程是一个过程,这个过程将数据转换为能更好的表示业务逻辑的特征,从而提高机器学习的性能。
特征工程包括数据清理,特征提取,特征选择等过程
模型评估
最后训练出来的模型,需要用验证集进行验证。验证结果ok过后,将模型发布上线,对模型进行预估/推理,评估模型性能的性能指标有:
- 二分类:准确率(AC)、灵敏度(SN)、特异性(SP)和马太相关系数(MCC)
- 回归:确定系数(R²)、均方误差(MSE)以及均方根误差(RMSE)
经验误差与泛化误差:
- 经验误差:是指AI模型在"训练数据"上的预测误差。模型在已经见过的数据上的表现有多好。就像学生做自己平时一直练习的题,做错的比例。
- 泛化误差:是指AI模型在"新、未见过的数据"上的预测误差。模型在实际应用时,能不能正确应对新情况。学生去参加考试,做没练过的新题,做错的比例,代表模型的"真实水平"。
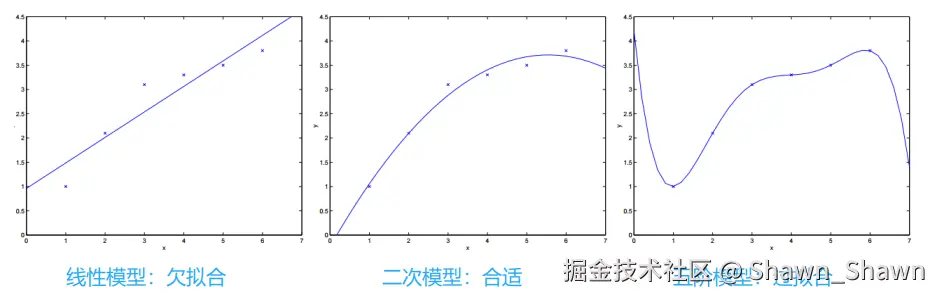
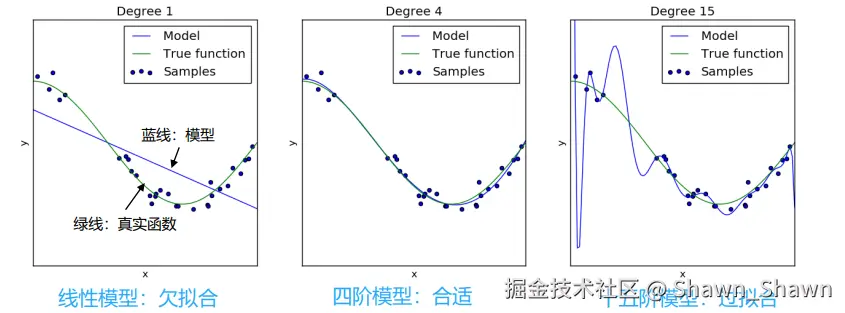
过拟合与欠拟合:
- 过拟合:模型在"训练数据"上表现非常好,但在新数据(实际应用)上效果很差。
- 欠拟合:模型在训练数据上和新数据上都表现很差。
****
指标计算公式:
真正例率和假正例率
| **** | 实际正例 | 实际负例 |
|---|---|---|
| 预测为正例 | TP(真正例) | FP(假正例) |
| 预测为负例 | FN(假负例) | TN(真负例) |
- TP和TN越大越好
- FP和FN越小越好
真正例率:又称召回率,也称查全率:

假正例率:又称误报概率:
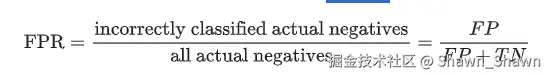
准确性:所有分类中正确分类的比例:
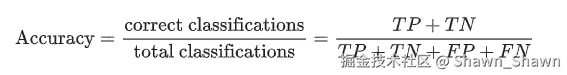
精确率:模型所有预测为正分类中实际正分类的比例:
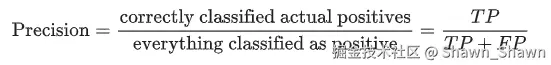
PR 曲线(Precision-Recall Curve) : 是一种用于评估分类模型性能的可视化工具,特别适用于样本类别极度不平衡的任务。
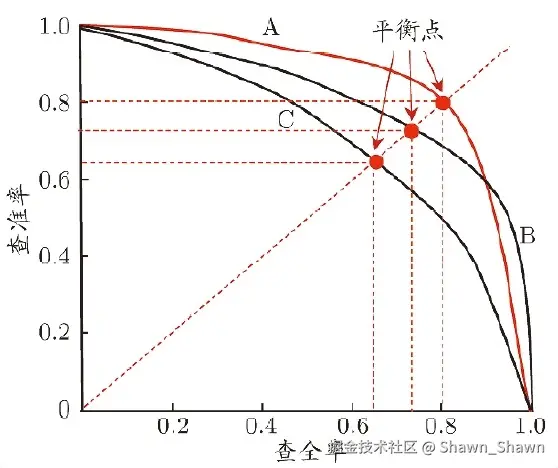
- A 表现最好的模型,查准率和查全率整体较高。
- B表现最差的模型,查准率下降很快,说明大量误报。
- C中等水平,查全率上升时查准率下降较缓慢。
F1计算公式:

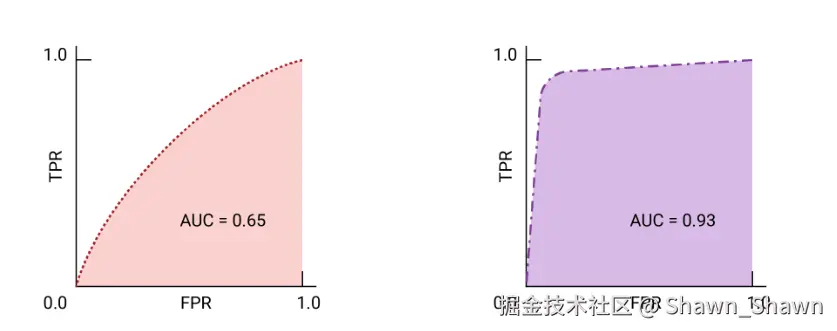
ROC曲线:
- ROC 曲线 是模型在所有阈值上的表现的可视化表示。
- ROC 曲线的绘制方法是计算真正例率 (TPR) 和假正例率 (FPR) 值
- ROC 曲线下面积 (AUC) 表示模型的概率,如果给定一个随机选择的正类别和负类别样本,正值将大于负
参考文献
- 谷歌AI开发者:developers.google.com/machine-lea...
- 微软AI:learn.microsoft.com/zh-cn/train...
- Github: github.com/dataprofess...**