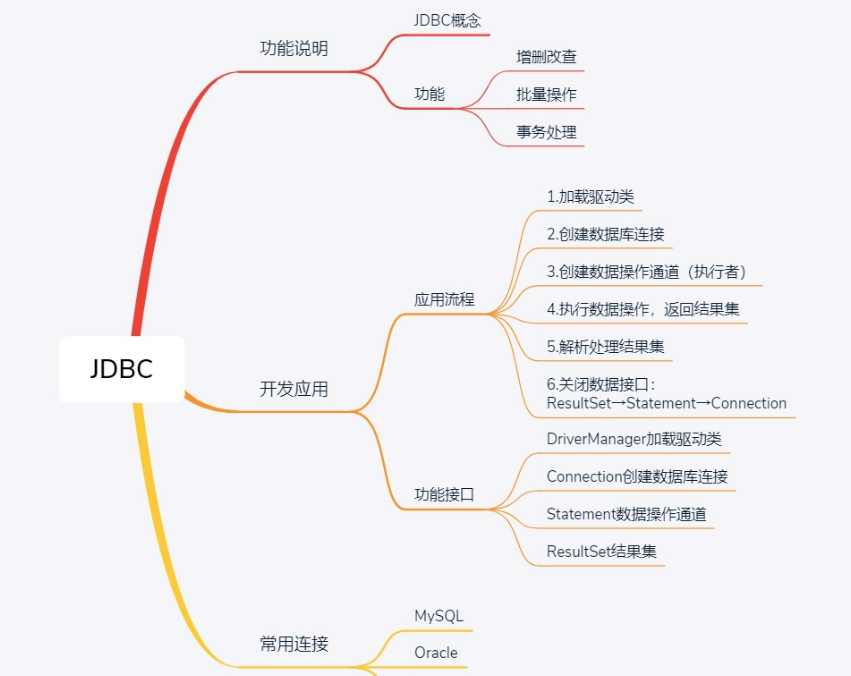
介绍
JDBC就是另外一种操作数据库的方式
JDBC:Java DataBase Connectivity
Mysql提供了驱动包
驱动包:就是MYSQL厂商提供了一套JDBC规范的实现。
jdbc包含四个对象
- DriverManager: 驱动管理类
- Connection接口:连接对象
- Statement接口:执行sql语句
- ResultSet接口:处理查询后的结果集
步骤
手动导入
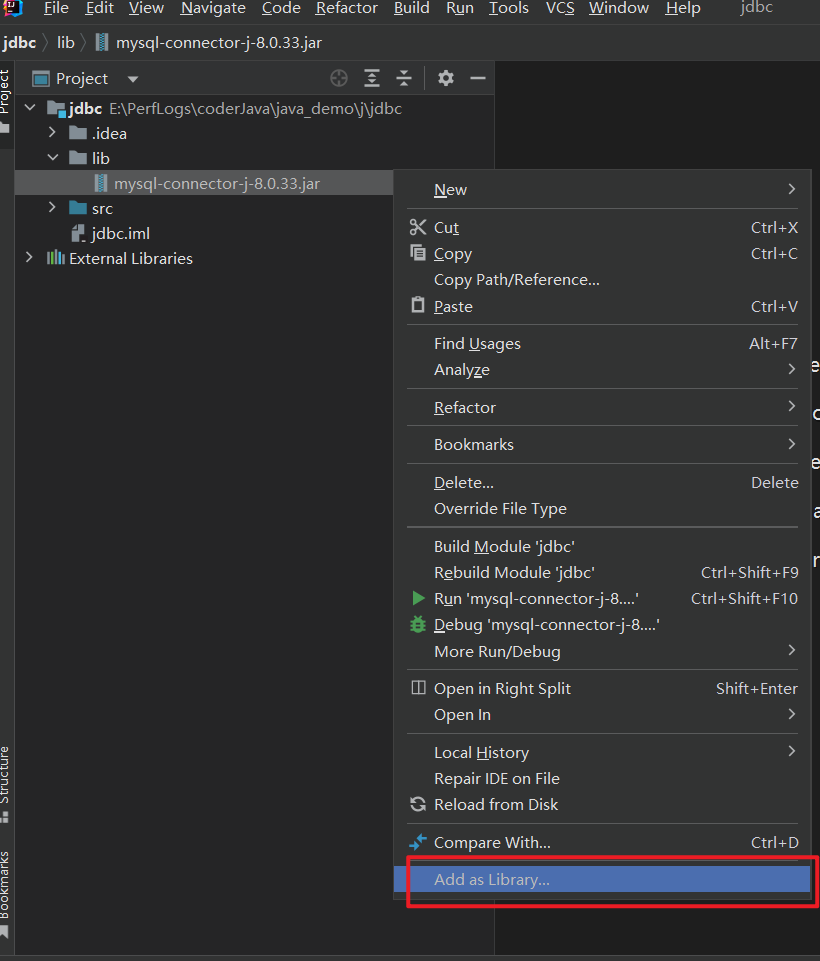
idea导入类库版本
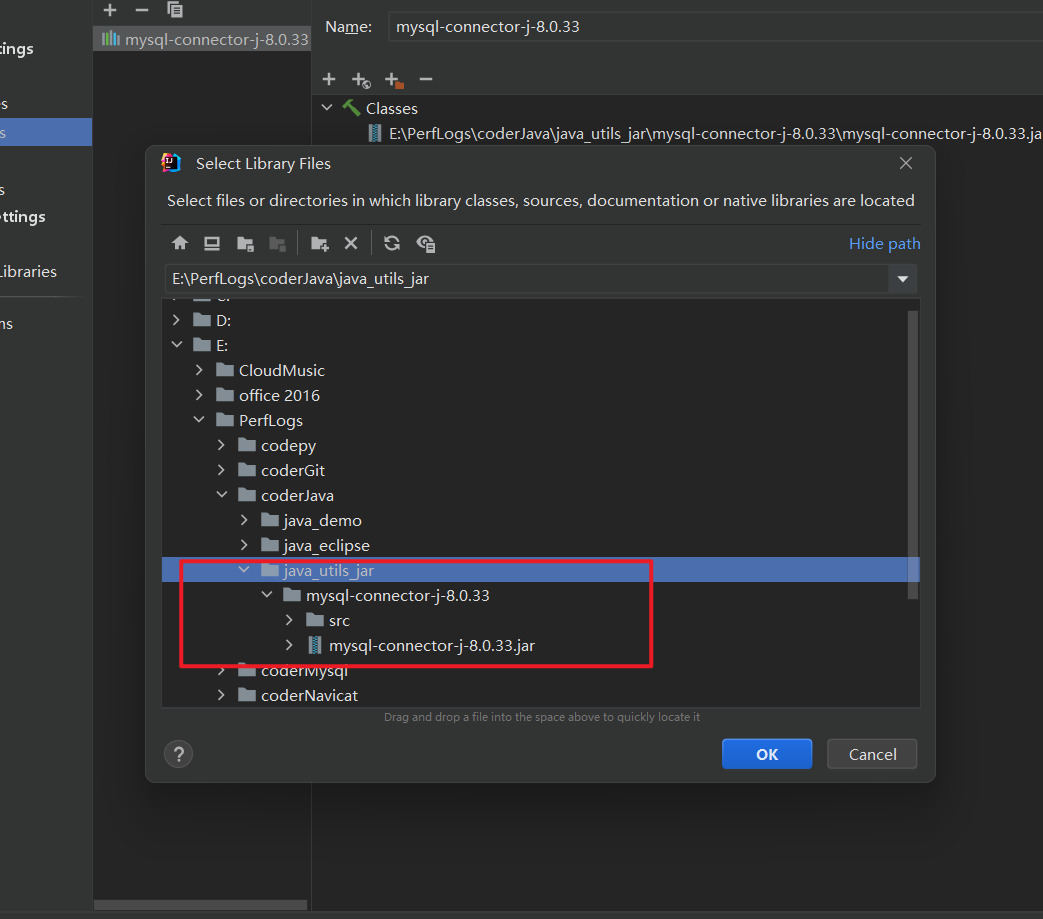
- 打开项目结构(Project Structure)
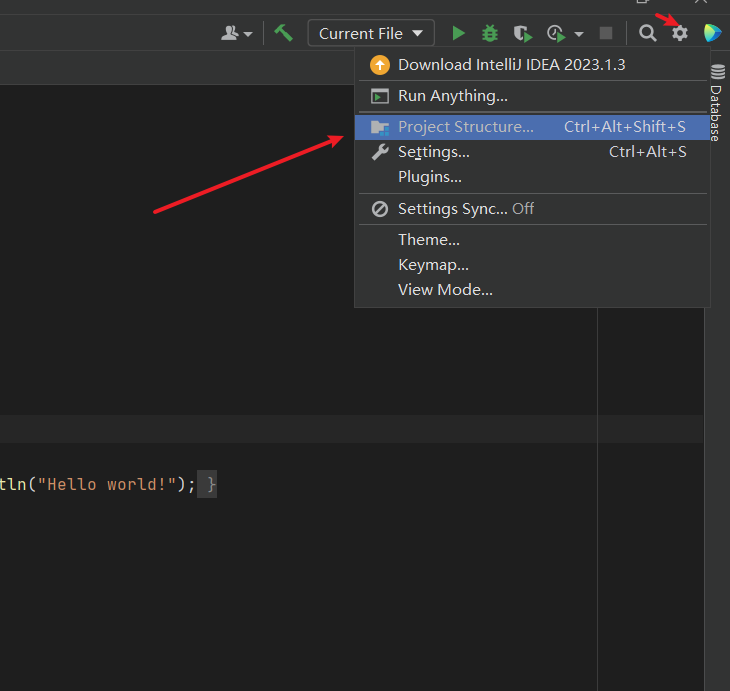
选择Libraries 添加 java
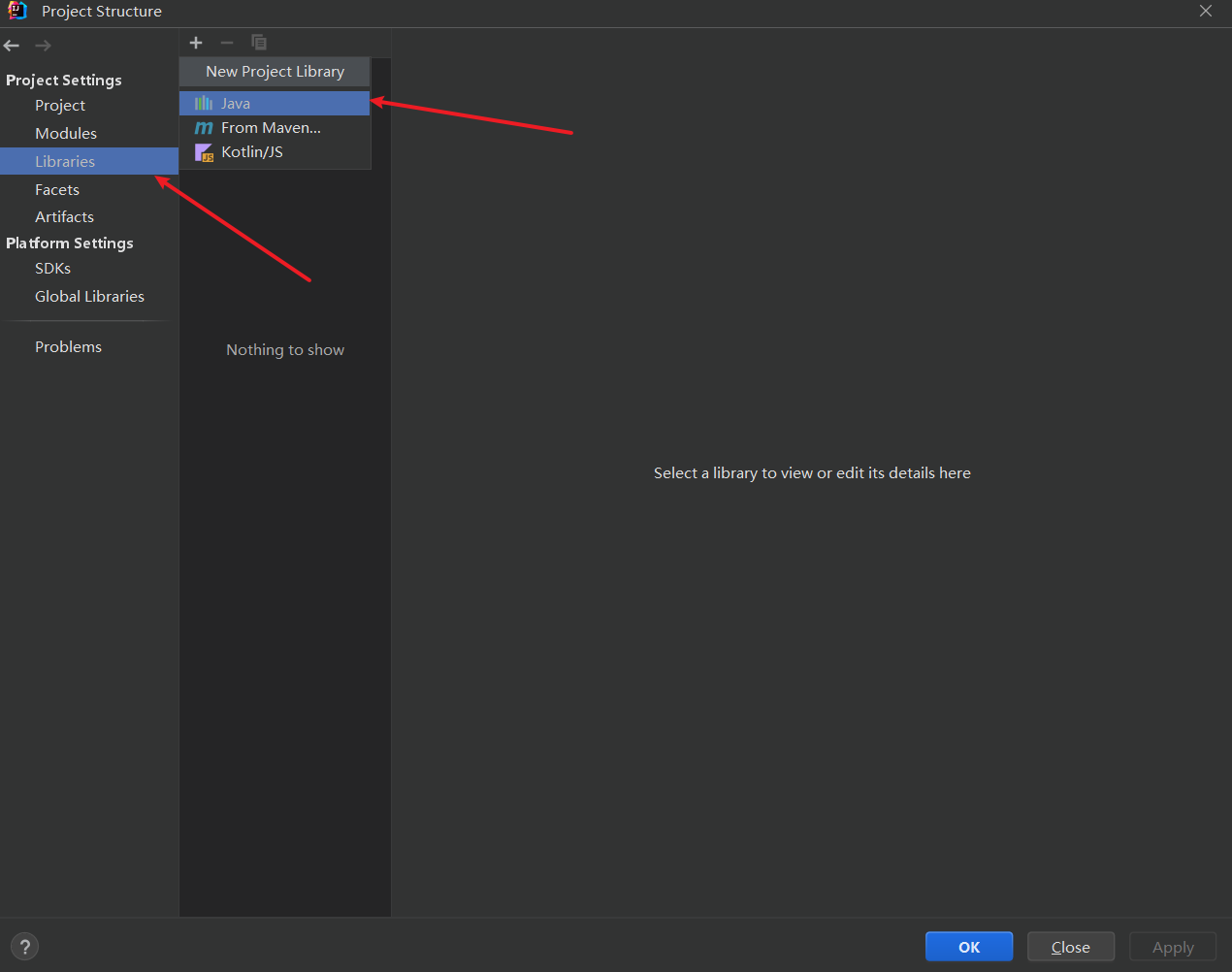
选择对应的路径
JDBC步骤【重要】
准备数据
sql
create table tb_user (
id int(11) primary key auto_increment comment "用户列表",
username varchar(30) comment "用户名",
password varchar(30) comment "密码",
phone varchar(11) comment "手机号",
createTime date comment "注册时间",
money double(10,2) comment "帐户余额",
sex int(1) comment "性别 0女1男"
);标准步骤
- 加载驱动 :通过DriverManager注册数据库驱动
- 建立连接 :使用DriverManager.getConnection()获取Connection对象
- 创建Statement :通过Connection创建SQL执行对象
- 执行SQL :使用Statement执行SQL语句
- 处理结果 :通过ResultSet处理查询结果
- 关闭资源 :按ResultSet → Statement → Connection顺序关闭资源
jdbc:mysql://127.0.01:3306/数据库名?useSSL=false&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai ;
java
public class Demo_insert {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
// 1 . 加载驱动
// ps:利用反射技术,将驱动类加载到JVM
Class.forName("com.mysql.cj.jdbc.Driver") ;
// 2 . 通过驱动管理对象获取连接对象
// jdbc:mysql:是协议 固定写法
// localhost:3306 域名
// java2023 是库名
String url = "jdbc:mysql://localhost:3306/java2023";
String username = "root";
String password = "root";
Connection connection = DriverManager.getConnection(url, username, password);
// 3 . 获得执行sql语句的对象
Statement statement = connection.createStatement();
// 4 . 通过执行语句对象, 执行sql,获取结果
String sql = "insert into tb_user (id,username,password,phone,createTime,money,sex) VALUES (2, \"小罗\",\"123456\",\"17783466057\",\"2023-07-02\",2000.0,1);";
// 执行查询 是 executeQuery()
// 执行增删改 是 executeUpdate()
int i = statement.executeUpdate(sql);
if(i > 0) {
System.out.println("插入成功");
}
// 5 . 关流
statement.close();
connection.close();
}
}获取添加最后一个数据的id
select last_insert_id(); -- 获取最后一个添加的id,前提是添加数据时不能指定id
查询结果集ResultSet【重要】
查询返回的是一种虚拟表,Java的JDBC中是使用结果集(ResultSet)来封装这个虚拟表,结果集就是一个集合
java
public class Demo_ResultSet {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
Class.forName("com.mysql.cj.jdbc.Driver");
String url = "jdbc:mysql://localhost:3306/java2023?useSSL=false";
String username = "root";
String password = "root";
Connection connection = DriverManager.getConnection(url,username,password);
Statement statement = connection.createStatement();
String sql = "SELECT * FROM tb_user ; ";
ResultSet resultSet = statement.executeQuery(sql);
// resultSet.next()
/* if (resultSet.next()) {
int anInt = resultSet.getInt(1);
String userStr = resultSet.getString(2);
System.out.println(userStr);
System.out.println(anInt);
}*/
while (resultSet.next()) {
String username1 = resultSet.getString("username");
System.out.println(username1);
}
statement.close();
connection.close();
}
}PreparedStatement批量添加
sql
create table category(
cid int primary key auto_increment ,
cname varchar(10)
);
- 注意:
- mysql默认情况下不会批量添加, 添加的时候都是一条一条添加的,这里的批量添加其实就是将多个要添加的数据先打包到内存,然后再将打包好的数据一起添加到数据库中,这里效率会提高
- 由于mysql默认情况下不会批量添加,所以我们想要进行批量添加的操作,需要手动开启功能
- jdbc:mysql://localhost:3306/msb_test01?rewriteBatchedStatements=true
- 批量添加方法: 用到PreparedStatement中的方法
- void addBatch() -> 将一组数据保存起来,给数据打包,放到内存中
- executeBatch() -> 将打包好的数据一起发给mysql
jdbc.properties文件:
properties
driver=com.mysql.cj.jdbc.Driver
url=jdbc:mysql://localhost:3306/msb_test01?rewriteBatchedStatements=true
user=root
pwd=root
java
static void main() throws SQLException {
Connection connection = JDBCUtils.getConnection();
String sql = "insert into category(cname) values (?)";
PreparedStatement pds = connection.prepareStatement(sql);
for (int i = 0; i < 100; i++) {
pds.setObject(1,"xiaobo" + i);
// 将数据一起添加到内存中
pds.addBatch();
}
// 执行sql:将内存中的数据一起发送给mysql
int[] ints = pds.executeBatch();
JDBCUtils.close(connection,pds,null);
}连接池
- 问题描述:
- 我们之前每个操作都需要先获取一条新的连接对象,用完之后就需要销毁,如果频繁的去创建连接对象,销毁对象,会耗费内存资源
- 解决:提前先准备好连接对象,放到一个容器中,然后来了操作直接从这个容器中拿连接对象,用完之后还回去
xml文件
xml:可扩展性标记语言
- 标记语言:就是文件中由标签组成的 -> <标签名></标签名>
- 可扩展性:标签名可以自定义
连接池之C3p0(了解)
- 导入C3P0的jar包
c3p0-0.9.5.2.jar
mchange-commons-java-0.2.12.jar
下载地址:https://sourceforge.net/projects/c3p0/
- 创建c3p0配置文件(xml):
- 取名: c3p0-config.xml (名字必须是这个)
右键->新建->file->xxx.xml
b. c3p0-config.xml配置:
xml
<c3p0-config>
<!-- 使用默认的配置读取连接池对象 -->
<default-config>
<!-- 连接参数 -->
<property name="driverClass">com.mysql.cj.jdbc.Driver</property>
<property name="jdbcUrl">jdbc:mysql://localhost:3306/msb_test01?rewriteBatchedStatements=true</property>
<property name="user">root</property>
<property name="password">root</property>
<!--
连接池参数
初始连接数(initialPoolSize):刚创建好连接池的时候准备的连接数量
最大连接数(maxPoolSize):连接池中最多可以放多少个连接
最大等待时间(checkoutTimeout):连接池中没有连接时最长等待时间,单位毫秒
最大空闲回收时间(maxIdleTime):连接池中的空闲连接多久没有使用就会回收,单位毫秒
-->
<property name="initialPoolSize">5</property>
<property name="maxPoolSize">10</property>
<property name="checkoutTimeout">2000</property>
<property name="maxIdleTime">1000</property>
</default-config>
</c3p0-config>连接池之Druid德鲁伊(掌握)
- 概述: 是阿里巴巴开发的
- 导入jar包: druid-1.2.27.jar
下载地址:https://mvnrepository.com/artifact/com.alibaba/druid/1.2.27
- 配置文件: xxx.properties
properties
driver=com.mysql.cj.jdbc.Driver
url=jdbc:mysql://localhost:3306/msb_test01
username=root
password=root
#连接池参数
initialSize=5
maxActive=10
maxWait=1000:::color5
- 读取配置文件
DruidDataSourceFactory.createDataSource(properties集合);
工具类:
java
package com.luo.utils;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import com.mchange.v2.c3p0.ComboPooledDataSource;
import javax.sql.DataSource;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
/**
* @author xiaobo
* @date 2025/12/2 星期二
* @description com.luo.utils
*/
public class DruidUtils {
private DruidUtils() {
}
private static DataSource dataSource;
static {
try {
// 创建Properties对象,用于存储配置文件中的键值对
Properties properties = new Properties();
// 通过类加载器获取druid.properties配置文件的输入流
// getClassLoader()获取类加载器,getResourceAsStream()查找并加载资源文件
InputStream resourceAsStream = DruidUtils.class.getClassLoader().getResourceAsStream("druid.properties");
// 从输入流中加载配置信息到Properties对象中
properties.load(resourceAsStream);
// 使用Druid连接池工厂类,根据配置创建数据源实例
// 数据源包含连接池的所有配置信息,是获取数据库连接的核心对象
dataSource = DruidDataSourceFactory.createDataSource(properties);
} catch (Exception e) {
// 捕获所有可能的异常并打印堆栈信息
// 实际生产环境中应使用更规范的日志记录
e.printStackTrace();
}
}
public static Connection getConnection() {
Connection connection = null;
try {
connection = dataSource.getConnection();
} catch (Exception e) {
e.printStackTrace();
}
return connection;
}
public static void close(Connection connection, Statement statement, ResultSet resultSet) {
if (statement != null) {
try {
statement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (resultSet != null) {
try {
resultSet.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (connection != null) {
try {
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}DBUtils工具包
-
commons-dbutils : 是简化jdbc开发步骤的工具包
-
核心对象:
- QueryRunner: 执行sql
- ResultSetHandler :处理结果集
- Dbutils: 关闭资源,事物处理
-
导入jar包
QueryRunner
- 构造: QueryRunner()
- 特点:
- 我们需要自己维护连接对象
- 支持占位符?
- 方法:
- int update(Connection conn ,String sql ,Object... params) -> 增删改
- conn:连接对象
- sql:sql语句
- params: 自动为sql中的?赋值 -> 直接传递给?
- queyr(Connection conn, String sql,ResultHandler res, Object... parmas) -> 查询
- conn:连接对象
- sql:sql语句
- res: 处理结果集,ResultHandler是一个接口,我们传入对应的实现类,不同的实现类对结果集有不同的处理
- parmas: 自动为sql中的?赋值
- int update(Connection conn ,String sql ,Object... params) -> 增删改
- 有参构造QueryRunner(DataSource)
- 特点:
- 不需要自己维护连接对象 ,也就是不需要传入 Connection 对象
- 支持占位符?
ResultSetHandler 结果集
BeanHandler
- 作用: 将查询出来的结果集中的第一行数据封装成javabean对象
- 方法:
- query(String sql , ResultSetHanlder res , Object... parmas) -> 有参QueryRunner时使用
- query(Connection conn, String sql , ResultSetHandler res , Object... parmas) ->无参QueryRunner时使用
- 构造: BeanHandler(Class type)
传递的class对象其实就是我们想要封装的javaben类的class对象
想查询出来的数据封装成哪个javabean对象,就写哪个javabean的class对象
- 怎么理解:
将查询出来的结果集为javabean中的成员属性赋值
java
static void main() throws Exception{
QueryRunner queryRunner = new QueryRunner(DruidUtils.getDataSource());
// 创建 BeanHandler对象
ResultSetHandler<Category> categoryBeanHandler = new BeanHandler<>(Category.class) ;
String sql = "select * from category where cid = ?" ;
Category res = queryRunner.query(sql, categoryBeanHandler);
System.out.println(res);
}BeanListHandler
:::color1
- 作用: 将查询出来的结果每一条数据都封装成一个一个的javabean对象,将这些javabean对象放到List集合中
- 构造: BeanListHandler(Class type)
传递的class对象其实就是我们想要封装的javaben类的class对象
想查询出来的数据封装成哪个javabean对象,就写哪个javabean的class对象
:::
java
@Test
public void beanListHandlerTest() throws SQLException {
QueryRunner queryRunner = new QueryRunner(DruidUtils.getDataSource());
String sql = "select * from category";
// 创建BeanListHandler对象
BeanListHandler<Category> beanListHandler = new BeanListHandler<>(Category.class);
List<Category> categoryList = queryRunner.query(sql, beanListHandler);
System.out.println(categoryList);
}ScalarHandler
:::color2
- 作用:主要是处理单值的查询结果,执行的select语,结果只有1个
- 构造:
- ScalarHandler(int columnIndex) -> 不常用 -> 指定第几行
- ScalarHandler(String columnName) -> 不常用 -> 指定列名
- ScalarHandler() -> 常用 默认代表查询结果的第一行第一列数据
- 注意:
Scalarhandler和聚合函数使用更有意义
:::
ColumnListHandler
:::color2
- 作用: 将查询出来的结构中的某一列数据,存储到List集合中
- 构造:
ColumnListHandler(int columnIndex) ->指定第几列
ColumnListHandler(String columnName) ->指定列名
ColumnListHandler() -> 默认显示查询结果中的第一列数据
- 注意:
ColumnListHandler可以指定泛型类型,如果不指定,返回的List泛型就是Object类型,可以不指定泛型
:::
事物
:::color2
- 事物就是:用来管理一组操作的(一组操作中包含了多条sql语句的),要么都成功,要么都失败
- 注意:
- mysql默认自带事物,但是mysql的自带事物,每次只能管理一条sql语句,所以想让mysql一次管理多条sql语句,需要关闭mysql自带事物,开启手动事务
- 方法: Connection中的方法:
- setAutoCommit(boolean auto Commit) -> 当参数为false,证明关闭mysql自带事物,自动开启手动事务
- void commit() -> 提交事务 -> 事物一旦提交,数据将永久保存,不能回到原来的数据
- void rollback() -> 回滚事物 -> 数据将恢复到原来的样子 -> 提前是事物没有提交
:::
java
@Test
public void transferDemo() {
QueryRunner queryRunner = new QueryRunner();
Connection connection = DruidUtils.getConnection();
try {
// 开启事务 false:关闭mysql自带事物,开启手动事务
connection.setAutoCommit(false);
String outMoneySql = "update account set money = money - ? where name = ? " ;
String intMoneySql = "update account set money = money + ? where name = ? " ;
queryRunner.update(connection,outMoneySql,1000,"碎梦") ;
System.out.println(1/0);
queryRunner.update(connection,intMoneySql,1000,"龙吟") ;
System.out.println("转账完成");
// 完成之后提交事务
connection.commit();
} catch (SQLException e) {
try {
connection.rollback();
System.out.println("转账失败");
} catch (SQLException ex) {
e.printStackTrace();
}
e.printStackTrace();
}
}