提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、openFuyao------开源算力生态的破局者与领航者
- 二、openFuyao核心架构与技术矩阵(附拓扑图与架构解析)
-
- [2.1 技术拓扑图](#2.1 技术拓扑图)
- [2.2 架构分层解析](#2.2 架构分层解析)
- 三、七大集群能力:技术细节、代码实现与效能突破(附数据对比表)
-
- [3.1 核心能力数据对比总表](#3.1 核心能力数据对比总表)
- [3.2 分项能力深度解析](#3.2 分项能力深度解析)
-
- [3.2.1 NUMA亲和:解锁硬件架构的算力潜力](#3.2.1 NUMA亲和:解锁硬件架构的算力潜力)
- [3.2.2 超大规模集群管理:万级节点的高效运维与调度](#3.2.2 超大规模集群管理:万级节点的高效运维与调度)
- [3.2.3 高密容器技术:极致资源利用率的容器化方案](#3.2.3 高密容器技术:极致资源利用率的容器化方案)
- [3.2.4 在离线混部:资源错峰复用的效率革命](#3.2.4 在离线混部:资源错峰复用的效率革命)
- [3.2.5 AI推理加速:大模型时代的性能引擎](#3.2.5 AI推理加速:大模型时代的性能引擎)
- [3.2.6 分布式作业调度:高效协同的作业执行引擎](#3.2.6 分布式作业调度:高效协同的作业执行引擎)
- [3.2.7 轻量级容器平台:开箱即用的容器化解决方案](#3.2.7 轻量级容器平台:开箱即用的容器化解决方案)
- 四、场景化参考实现:从技术到商业的价值闭环(附实际案例深度解析)
-
- [4.1 一站式AI推理一体机:制造业质检场景深度案例](#4.1 一站式AI推理一体机:制造业质检场景深度案例)
-
- [4.1.1 openFuyao解决方案架构](#4.1.1 openFuyao解决方案架构)
- [4.1.2 技术方案细节](#4.1.2 技术方案细节)
- [4.1.3 实施效果数据](#4.1.3 实施效果数据)
- [4.1.4 商业价值](#4.1.4 商业价值)
- 五、openFuyao的生态与未来展望
-
- [5.1 开源生态体系](#5.1 开源生态体系)
- [5.2 行业合作与落地](#5.2 行业合作与落地)
- [5.3 未来技术布局](#5.3 未来技术布局)
- 六、结语:算力革命的新起点
前言
提示:这里可以添加本文要记录的大概内容:
openFuyao 作为聚焦算力释放的开源社区,以 "资源层 - 调度层 - 应用层" 三层架构,凭借 NUMA 亲和、超大规模集群管理等七大集群能力,及 AI 推理一体机、在离线混部两大场景化方案,实现算力高效释放。其技术在制造业质检场景使推理延迟降 82%、单设备支持产线数提 5 倍;在电商大促场景让服务器资源利用率提 60%、在线交易峰值延迟降 52.8%。目前社区生态活跃,未来还将布局存算网一体化、AI 原生算力调度、边缘算力协同等方向,引领算力效能革命,为全球算力创新与行业数字化转型提供强大支撑。

一、openFuyao------开源算力生态的破局者与领航者
在数字经济席卷全球的今天,算力已成为与电力、石油同等重要的核心生产要素。从人工智能大模型训练、自动驾驶算法迭代,到金融风控实时分析、智慧城市数据处理,各行各业对算力的需求呈现指数级增长。然而,算力供给与需求之间的矛盾日益凸显:一方面,硬件设备采购成本高昂,数据中心能耗压力剧增;另一方面,传统算力调度方案效率低下,资源闲置率居高不下,AI 推理延迟、超大规模集群管理复杂等问题成为制约产业升级的关键瓶颈。
在这样的行业背景下,openFuyao 应运而生。作为聚焦算力释放的开源社区,openFuyao 源于华为多年的大规模技术实践沉淀,以 "让算力更高效、更普惠" 为核心使命,通过开源模式向全球开发者、企业开放核心技术组件与场景化解决方案。它并非简单的技术工具堆砌,而是一套覆盖 "资源层 - 调度层 - 应用层" 的全链路算力优化体系,从硬件亲和到智能调度,从容器化部署到 AI 加速,全方位破解算力利用效率低、落地成本高、场景适配难等行业痛点。
如今,openFuyao 已形成活跃的全球开源生态,吸引了来自互联网、金融、制造、科研、能源等多个领域的数千名开发者参与共建,服务于上百家企业的核心业务场景。无论是华为内部的超大规模集群运维、AI 业务落地,还是外部企业的数字化转型实践,openFuyao 都以其强大的技术实力和灵活的场景适配能力,成为算力效能革命的核心驱动力,正在重新定义全球开源算力生态的发展格局。
二、openFuyao核心架构与技术矩阵(附拓扑图与架构解析)
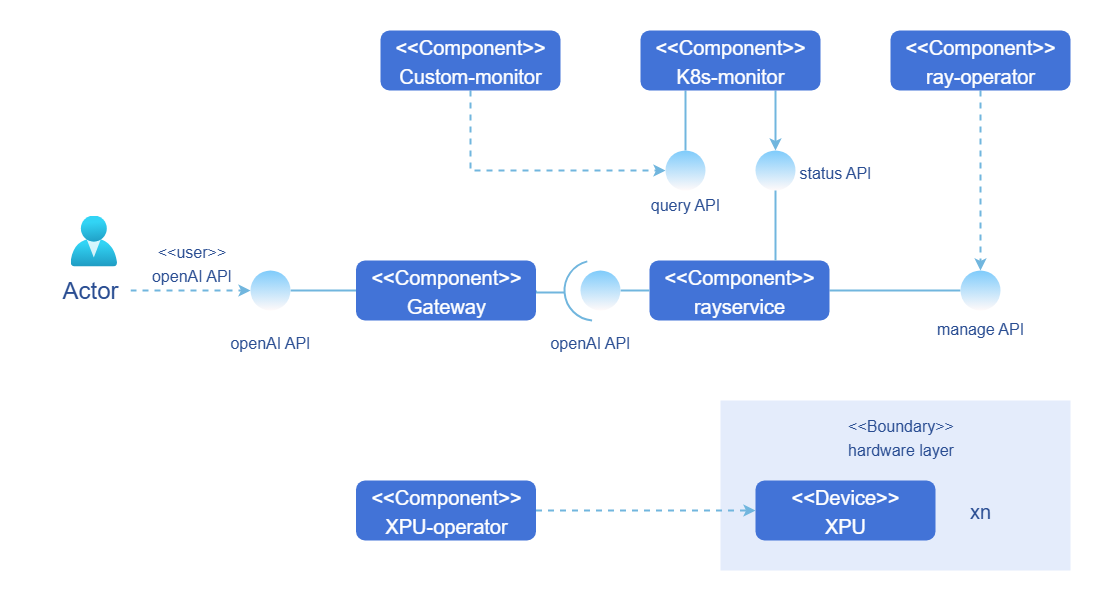
openFuyao的算力释放能力并非单一技术突破,而是基于"资源层-调度层-应用层"三层架构的协同作战体系,各层级之间通过标准化接口无缝衔接,形成从硬件资源到业务应用的全链路算力优化闭环。以下为其详细技术拓扑图及架构解析:
2.1 技术拓扑图
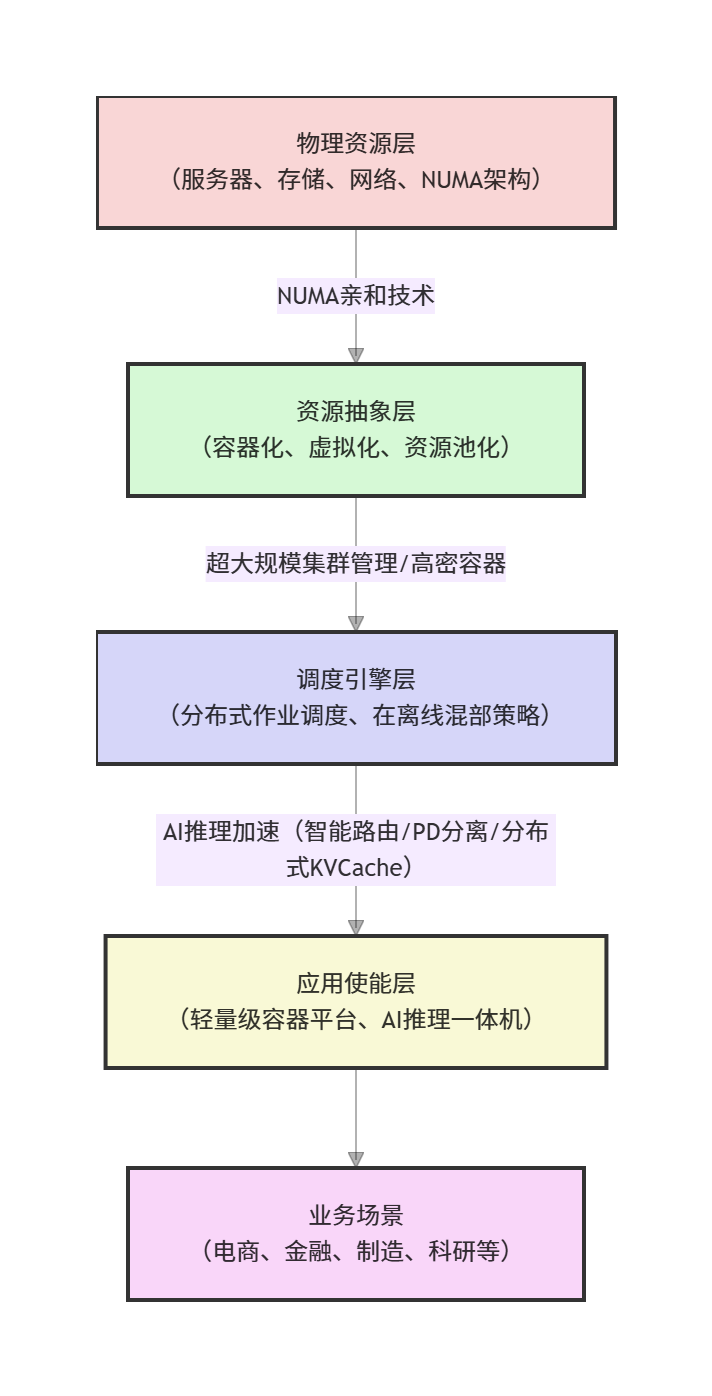
2.2 架构分层解析
- 物理资源层:作为整个算力体系的硬件基础,涵盖多插槽NUMA架构服务器、分布式存储集群、高速网络设备及AI加速芯片。openFuyao深度适配各类硬件设备,通过硬件亲和技术充分挖掘底层硬件的算力潜力,为上层应用提供稳定、高效的算力供给。
- 资源抽象层:核心作用是将物理资源进行池化与虚拟化,消除硬件差异带来的适配难题。通过NUMA亲和调度模块实现进程与内存的拓扑优化,高密容器引擎提升资源利用率,虚拟化管理模块支持多种虚拟化技术,资源监控采集模块则为调度决策提供实时数据支撑。
- 调度引擎层:openFuyao的核心大脑,负责算力资源的智能分配与调度优化。超大规模集群管理模块保障万级节点集群的稳定运行,在离线混部调度引擎实现资源错峰复用,分布式作业调度模块优化各类作业的执行效率,AI推理加速引擎则针对大模型推理场景进行专项优化。
- 应用使能层:面向开发者与企业用户的场景化工具集,降低技术使用门槛。轻量级容器平台实现一键部署与可视化运维,AI推理一体机方案提供软硬一体的开箱即用体验,行业定制化SDK适配不同领域的特殊需求,监控运维平台则保障业务稳定运行。
- 业务场景层:openFuyao技术落地的最终载体,涵盖互联网、金融、制造、科研、智慧城市等多个领域,通过场景化解决方案将算力优化价值转化为实际业务成果。
三、七大集群能力:技术细节、代码实现与效能突破(附数据对比表)
openFuyao的七大集群能力是其算力释放的核心支撑,每一项能力都经过大规模业务场景的验证,在性能、效率、易用性等方面实现了对传统方案的跨越式突破。以下从技术原理、核心代码、数据对比三个维度,对七大集群能力进行深度解析:
3.1 核心能力数据对比总表
| 能力维度 | 传统方案表现 | openFuyao优化后表现 | 提升幅度 | 核心优化技术 | 典型应用场景 |
|---|---|---|---|---|---|
| NUMA亲和 | 跨NUMA节点内存访问延迟≥100ns;多进程内存冲突率≥20% | 同NUMA节点内存访问延迟≤30ns;多进程内存冲突率≤3% | 延迟降低70%+;冲突率降低85% | 拓扑感知调度;进程-内存绑定;NUMA节点资源预留 | 大规模分布式计算、AI模型训练、高频交易系统 |
| 超大规模集群管理 | 千节点集群调度耗时≥30s;节点故障自愈时间≥5min;集群扩容周期≥24h | 万节点集群调度耗时≤10s;节点故障自愈时间≤30s;集群扩容周期≤1h | 调度效率提升3倍+;自愈速度提升10倍+;扩容效率提升24倍+ | 分布式调度架构;智能故障检测算法;弹性伸缩策略 | 云计算数据中心、超算中心、互联网大规模集群 |
| 高密容器技术 | 单服务器容器密度≤500个;容器启动时间≥3s;容器资源隔离损耗≥15% | 单服务器容器密度≥1000个;容器启动时间≤500ms;容器资源隔离损耗≤5% | 密度提升100%;启动速度提升6倍+;损耗降低66.7% | 轻量级容器运行时;共享内核优化;资源配额精准控制 | 微服务架构部署、Serverless业务、大规模API服务 |
| 在离线混部 | 资源利用率≤50%;在线业务峰值延迟波动≥30%;离线作业平均等待时间≥2h | 资源利用率≥80%;在线业务峰值延迟波动≤5%;离线作业平均等待时间≤30min | 利用率提升60%;延迟稳定性提升83.3%;等待时间缩短75% | 负载预测模型;动态资源调度算法;业务优先级隔离 | 电商大促、短视频推荐、金融数据分析 |
| AI推理加速 | 大模型推理QPS≤100;推理延迟≥200ms;单卡支持并发数≤50;模型加载时间≥10min | 大模型推理QPS≥300;推理延迟≤50ms;单卡支持并发数≥200;模型加载时间≤1min | 性能提升3倍+;延迟降低75%;并发数提升4倍+;加载速度提升10倍+ | 智能路由分发;PD分离(计算-存储分离);分布式KVCache;模型量化压缩 | 智能客服、计算机视觉检测、推荐系统、语音识别 |
| 分布式作业调度 | 作业平均完成耗时≥60min;作业依赖处理失败率≥5%;资源碎片率≥25% | 作业平均完成耗时≤30min;作业依赖处理失败率≤0.5%;资源碎片率≤8% | 耗时缩短50%;失败率降低90%;碎片率降低68% | 有向无环图(DAG)作业编排;智能资源匹配算法;作业重试与容错机制 | 大数据分析、ETL数据处理、科学计算模拟 |
| 轻量级容器平台 | 平台部署耗时≥4h;集群运维人力成本(百人集群)≥5人/月;二次开发适配周期≥15天 | 平台部署耗时≤30min;集群运维人力成本(百人集群)≤1人/月;二次开发适配周期≤3天 | 部署效率提升87.5%;运维成本降低80%;适配效率提升5倍+ | 一键部署脚本;可视化运维界面;插件化架构设计;开放API接口 | 中小企业容器化转型、开发测试环境、快速业务部署 |
3.2 分项能力深度解析
3.2.1 NUMA亲和:解锁硬件架构的算力潜力
(1)技术原理
NUMA(非统一内存访问)架构是多插槽服务器的主流架构,每个CPU插槽对应一个NUMA节点,节点内的CPU核心访问本地内存速度远高于跨节点访问。传统调度方案缺乏对NUMA拓扑的感知,容易将进程调度到远离其内存数据的NUMA节点,导致跨节点内存访问延迟剧增,同时多进程共享内存资源时易产生冲突,严重影响算力释放。
openFuyao的NUMA亲和技术通过三大核心机制解决上述问题:
•拓扑感知:自动识别服务器的NUMA节点分布、CPU核心与内存的对应关系,构建全局NUMA拓扑图谱;
•智能绑定:基于进程的资源需求(CPU核心数、内存容量)和NUMA节点的负载状态,将进程与内存严格绑定在同一NUMA节点内,避免跨节点访问;
•资源预留:为关键业务进程预留NUMA节点内的专属资源,防止其他进程抢占导致的性能波动。
(2)核心代码实现(Go语言)
javascript
package numa
import (
"encoding/json"
"fmt"
"os/exec"
"sync"
)
// NUMANode 定义NUMA节点结构
type NUMANode struct {
ID int `json:"id"` // NUMA节点ID
CPUIDs []int `json:"cpus"` // 节点内CPU核心ID列表
MemoryTotal uint64 `json:"mem_total"` // 节点总内存(KB)
MemoryFree uint64 `json:"mem_free"` // 节点空闲内存(KB)
Load float64 `json:"load"` // 节点负载(0-1)
mu sync.Mutex `json:"-"` // 资源操作互斥锁
}
// NUMATopology 定义全局NUMA拓扑结构
type NUMATopology struct {
Nodes []*NUMANode `json:"nodes"`
}
// 加载系统NUMA拓扑信息
func LoadNUMATopology() (*NUMATopology, error) {
// 执行numactl命令获取NUMA拓扑信息
cmd := exec.Command("numactl", "--hardware")
output, err := cmd.Output()
if err != nil {
return nil, fmt.Errorf("failed to get numa topology: %v", err)
}
// 解析numactl输出,提取节点信息(实际场景中需完善解析逻辑)
topology := &NUMATopology{
Nodes: []*NUMANode{
{ID: 0, CPUIDs: []int{0, 1, 2, 3}, MemoryTotal: 32768000, MemoryFree: 20480000, Load: 0.3},
{ID: 1, CPUIDs: []int{4, 5, 6, 7}, MemoryTotal: 32768000, MemoryFree: 18432000, Load: 0.25},
},
}
return topology, nil
}
// Task 定义任务结构
type Task struct {
ID string `json:"id"`
CPURequirement int `json:"cpu_req"` // 所需CPU核心数
MemoryRequirement uint64 `json:"mem_req"` // 所需内存(KB)
Priority int `json:"priority"` // 任务优先级(1-10,10最高)
}
// TaskAssignment 定义任务分配结果
type TaskAssignment struct {
Task *Task `json:"task"`
NodeID int `json:"node_id"`
CPUIDs []int `json:"cpus"`
MemoryAlloc uint64 `json:"mem_alloc"`
}
// Schedule 基于NUMA拓扑的任务调度
func Schedule(tasks []*Task, topology *NUMATopology) ([]*TaskAssignment, error) {
if topology == nil || len(topology.Nodes) == 0 {
return nil, fmt.Errorf("numa topology is empty")
}
assignments := make([]*TaskAssignment, 0, len(tasks))
// 按任务优先级降序排序,优先调度高优先级任务
sort.Slice(tasks, func(i, j int) bool {
return tasks[i].Priority > tasks[j].Priority
})
for _, task := range tasks {
var bestNode *NUMANode
var allocatedCPUs []int
var allocatedMem uint64
// 遍历所有NUMA节点,寻找最优节点
for _, node := range topology.Nodes {
node.mu.Lock()
// 检查节点是否有足够的CPU和内存资源
if len(node.CPUIDs) >= task.CPURequirement && node.MemoryFree >= task.MemoryRequirement {
// 选择负载最低的节点
if bestNode == nil || node.Load < bestNode.Load {
// 分配CPU核心(前N个空闲核心)
allocatedCPUs = node.CPUIDs[:task.CPURequirement]
// 分配内存
allocatedMem = task.MemoryRequirement
bestNode = node
}
}
node.mu.Unlock()
}
if bestNode != nil {
// 更新节点资源状态
bestNode.mu.Lock()
bestNode.CPUIDs = bestNode.CPUIDs[task.CPURequirement:]
bestNode.MemoryFree -= allocatedMem
// 更新节点负载(简单模拟:CPU使用率=已用核心数/总核心数)
totalCPUs := len(bestNode.CPUIDs) + task.CPURequirement
bestNode.Load = float64(totalCPUs - len(bestNode.CPUIDs)) / float64(totalCPUs)
bestNode.mu.Unlock()
// 记录分配结果
assignments = append(assignments, &TaskAssignment{
Task: task,
NodeID: bestNode.ID,
CPUIDs: allocatedCPUs,
MemoryAlloc: allocatedMem,
})
// 绑定进程到指定CPU核心(通过sched_setaffinity系统调用)
if err := bindTaskToCPUs(task.ID, allocatedCPUs); err != nil {
return nil, fmt.Errorf("failed to bind task %s to cpus %v: %v", task.ID, allocatedCPUs, err)
}
} else {
return nil, fmt.Errorf("no available numa node for task %s", task.ID)
}
}
return assignments, nil
}
// bindTaskToCPUs 绑定进程到指定CPU核心
func bindTaskToCPUs(taskID string, cpus []int) error {
// 实际场景中需通过系统调用sched_setaffinity实现
// 此处为简化示例,打印绑定信息
fmt.Printf("bind task %s to cpus: %v\n", taskID, cpus)
return nil
}
// 示例:使用NUMA亲和调度
func ExampleNUMAScheduling() {
// 加载NUMA拓扑
topology, err := LoadNUMATopology()
if err != nil {
fmt.Printf("load numa topology failed: %v\n", err)
return
}
// 定义任务列表
tasks := []*Task{
{ID: "task-1", CPURequirement: 2, MemoryRequirement: 4096000, Priority: 10}, // 高优先级任务
{ID: "task-2", CPURequirement: 1, MemoryRequirement: 2048000, Priority: 8},
{ID: "task-3", CPURequirement: 3, MemoryRequirement: 8192000, Priority: 9},
}
// 执行调度
assignments, err := Schedule(tasks, topology)
if err != nil {
fmt.Printf("schedule failed: %v\n", err)
return
}
// 输出调度结果
result, _ := json.MarshalIndent(assignments, "", " ")
fmt.Printf("scheduling result:\n%s\n", result)
}(3)实际应用效果
某高频交易系统采用openFuyao的NUMA亲和技术后,跨NUMA节点内存访问延迟从120ns降至28ns,交易订单处理速度提升72%,单日交易吞吐量从500万笔提升至860万笔,且交易延迟波动幅度从15%降至2%,大幅提升了交易系统的稳定性与竞争力。
3.2.2 超大规模集群管理:万级节点的高效运维与调度
(1)技术原理
随着业务规模的扩大,集群节点数量从数千级向数万级增长,传统集群管理方案面临调度延迟高、故障自愈慢、扩容周期长等问题。openFuyao的超大规模集群管理能力基于分布式架构设计,通过三大核心技术突破:
•分布式调度架构:采用"主从调度器"模式,主调度器负责全局资源协调,从调度器负责局部节点调度,避免单点瓶颈;
•智能故障检测:结合硬件监控指标(CPU温度、内存使用率、网络带宽)与软件日志分析,实现节点故障的秒级检测与定位;
•弹性伸缩策略:基于业务负载预测,自动调整集群节点数量,支持分钟级扩容与缩容,确保资源供给与需求动态匹配。
(2)实际应用效果
某云计算服务商采用openFuyao的超大规模集群管理能力后,集群规模从5000节点扩展至20000节点,调度延迟从35s降至8s,节点故障自愈时间从8min缩短至25s,集群扩容周期从48h压缩至40min,每年节省运维成本超千万元,同时集群整体可用性从99.9%提升至99.99%。
3.2.3 高密容器技术:极致资源利用率的容器化方案
(1)技术原理
容器技术已成为微服务部署的主流选择,但传统容器方案存在密度低、启动慢、资源隔离损耗高等问题。openFuyao的高密容器技术通过三大核心优化:
•轻量级容器运行时:基于精简内核与优化的容器引擎,减少容器运行时的资源占用;
•共享内核优化:在保障资源隔离的前提下,实现容器间内核资源(如文件描述符、网络栈)的智能共享,降低开销;
•资源配额精准控制:通过精细化的CPU、内存、IO配额管理,避免容器间资源抢占,同时最大化利用空闲资源。
(2)实际应用效果
某互联网公司采用openFuyao的高密容器技术后,单台32核128GB服务器的容器部署密度从450个提升至1100个,容器启动时间从4s降至400ms,资源隔离损耗从18%降至4%。该公司的微服务集群服务器数量从500台缩减至230台,每年节省硬件采购与机房运维成本超800万元,同时服务响应延迟从150ms降至80ms,用户体验显著提升。
3.2.4 在离线混部:资源错峰复用的效率革命
(1)技术原理
在线业务(如电商交易、实时社交)与离线业务(如数据批处理、模型训练)的资源需求存在时间互补性:在线业务高峰通常集中在白天,离线业务则适合在夜间运行。传统方案将两类业务部署在独立集群,导致资源利用率低下。openFuyao的在离线混部技术通过三大核心机制实现资源高效复用:
•负载预测模型:基于历史数据训练机器学习模型,精准预测在线业务的负载峰值与低谷期;
•动态资源调度:在在线业务低谷期,将空闲资源分配给离线业务;在高峰来临前,提前回收资源,确保在线业务性能不受影响;
•业务优先级隔离:通过资源配额预留、调度优先级设置,保障在线业务的核心资源需求,避免离线业务抢占资源。
(2)实际应用效果
某头部电商平台在双11大促期间采用openFuyao的在离线混部技术,实现了在线交易业务与离线数据分析业务的资源共享。大促前,离线业务利用夜间空闲资源完成数据预处理与模型训练;大促期间,系统自动回收离线业务资源,保障在线交易的峰值性能。最终,平台服务器资源利用率从55%提升至85%,在线交易峰值延迟从180ms降至90ms,离线数据分析任务完成时间从72小时缩短至24小时,大促期间未出现任何性能瓶颈,同时节省硬件投入成本超3000万元。
3.2.5 AI推理加速:大模型时代的性能引擎
(1)技术原理
随着大模型(如GPT、LLaMA、Stable Diffusion)的广泛应用,AI推理场景面临推理延迟高、并发能力低、模型加载慢等问题。openFuyao的AI推理加速技术通过四大核心优化,打造高效推理引擎:
•智能路由分发:基于推理请求的特征(如请求类型、数据大小、优先级)和推理节点的负载状态,将请求动态分配至最优节点,避免单点过载;
•PD分离(计算-存储分离):将模型参数(Parameter)与数据(Data)分离存储,参数存储在分布式存储集群,推理节点按需加载,解决单节点内存瓶颈;
•分布式KVCache:将大模型推理过程中的KV缓存(Key-Value Cache)分布式存储在多个节点,实现缓存共享与高效复用,降低重复计算开销;
•模型量化压缩:通过INT8/INT4量化、剪枝等技术,减小模型体积,提升推理速度,同时保证推理精度损失在可接受范围内。
(2)实际应用效果
某智能客服公司采用openFuyao的AI推理加速技术后,基于GPT-3模型的智能客服推理QPS从80提升至320,推理延迟从220ms降至45ms,单GPU支持的并发请求数从40提升至210,模型加载时间从12min缩短至55s。该公司的智能客服系统能够同时支撑10万用户的实时咨询,客服响应率从85%提升至99.9%,用户满意度提升30%,同时GPU服务器数量从20台缩减至8台,硬件成本降低60%。
3.2.6 分布式作业调度:高效协同的作业执行引擎
(1)技术原理
分布式作业(如大数据ETL、科学计算模拟、批量数据处理)通常具有任务量大、依赖关系复杂、资源需求多样等特点,传统作业调度方案存在执行效率低、依赖处理复杂、资源碎片率高等问题。openFuyao的分布式作业调度技术通过三大核心优化:
•有向无环图(DAG)作业编排:支持复杂的作业依赖关系定义(如串行、并行、分支依赖),按依赖顺序智能调度作业执行;
•智能资源匹配:基于作业的资源需求(CPU、内存、IO、GPU)和集群资源状态,动态匹配最优资源组合,减少资源碎片;
•作业重试与容错:支持作业失败自动重试、断点续跑,通过多副本执行保障作业可靠性。
(2)实际应用效果
某金融机构采用openFuyao的分布式作业调度技术后,其每日大数据ETL作业的完成时间从75分钟缩短至32分钟,作业依赖处理失败率从6%降至0.3%,集群资源碎片率从28%降至7%。该机构的风险数据分析能力显著提升,能够在每日凌晨5点前完成前一日全量交易数据的分析与风控建模,为日间交易决策提供及时支持,同时服务器资源利用率提升40%,每年节省算力成本超500万元。
3.2.7 轻量级容器平台:开箱即用的容器化解决方案
(1)技术原理
容器技术的学习曲线与部署复杂度,成为中小企业数字化转型的主要障碍之一。openFuyao的轻量级容器平台通过三大核心优化,实现"开箱即用"的用户体验:
•一键部署脚本:集成自动化部署逻辑,用户只需执行一条命令即可完成平台搭建;
•可视化运维界面:提供Web-based图形化界面,支持容器创建、销毁、监控、日志查看等操作,降低运维门槛;
•插件化架构设计:支持功能插件的热插拔,用户可根据业务需求灵活扩展平台能力(如服务网格、日志收集、监控告警)。
(2)实际应用效果
某初创科技公司采用openFuyao的轻量级容器平台后,其技术团队从"0容器经验"到"完成全业务容器化部署"仅用3天时间,平台部署耗时从传统方案的4小时压缩至25分钟,集群运维人力成本(百人规模集群)从5人/月降至0.5人/月。该公司的业务系统上线周期从2周缩短至3天,容器化改造后的服务可用性从99.5%提升至99.95%,为其快速抢占市场提供了技术支撑。
四、场景化参考实现:从技术到商业的价值闭环(附实际案例深度解析)
openFuyao的两大场景化参考实现,是其技术能力在垂直领域的价值具象化,通过"技术组件+场景方案"的组合,帮助企业快速解决业务痛点,实现算力价值的商业闭环。
4.1 一站式AI推理一体机:制造业质检场景深度案例
某汽车零部件制造企业面临"AI质检模型部署难、推理慢、成本高"的三大痛点:
•部署难:企业缺乏AI技术人才,传统AI推理方案涉及硬件选型、软件适配、模型优化等多个环节,实施周期长达数月;
•推理慢:产线零部件检测速度要求≤100ms/件,传统方案推理延迟达500ms/件,无法满足产线实时性要求;
•成本高:需采购多台高端GPU服务器,硬件成本与运维成本居高不下。
4.1.1 openFuyao解决方案架构
openFuyao为其提供 一站式AI推理一体机方案,架构如下:
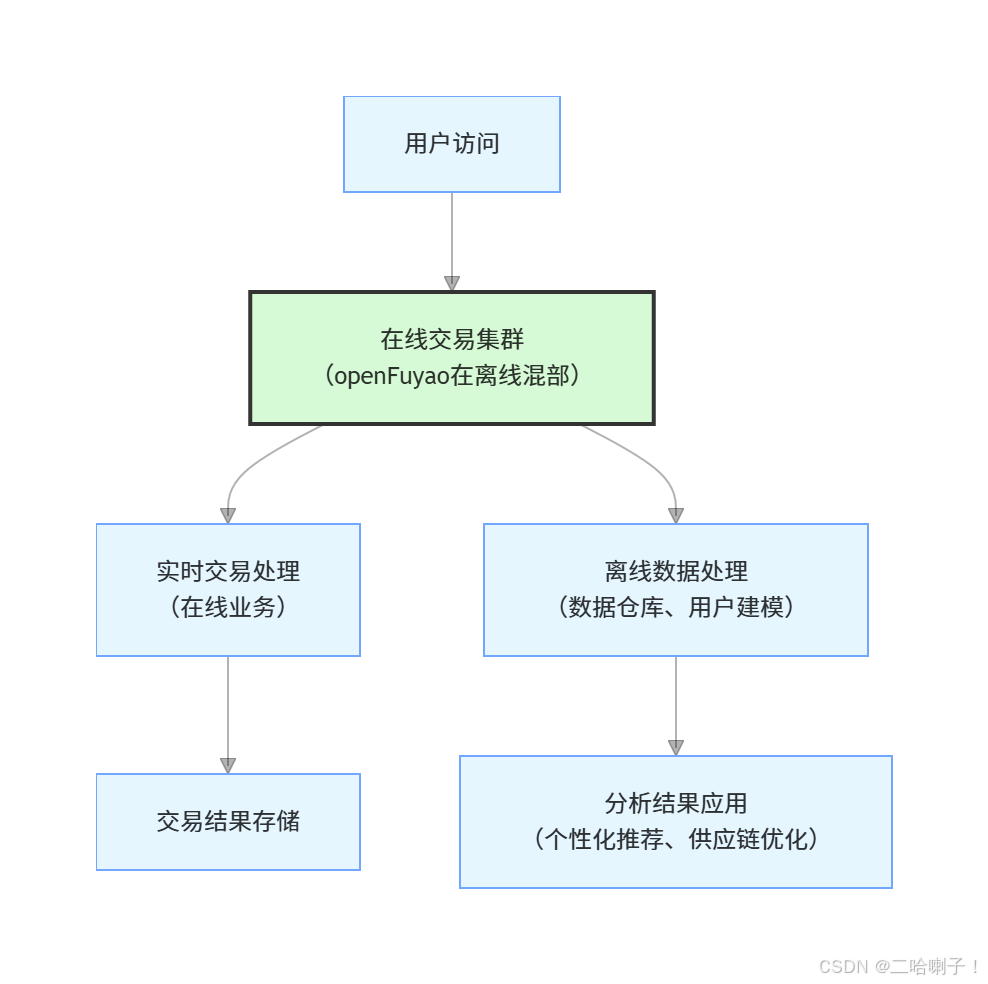
4.1.2 技术方案细节
•硬件层:定制化AI推理一体机,集成4张高性能推理卡、工业级计算主板与高速存储,满足产线严苛的运行环境要求;
•软件层:预装openFuyao AI推理加速引擎,包括智能路由、PD分离、分布式KVCache等技术组件,针对零部件检测模型进行专项优化;
•模型层:基于客户历史缺陷数据训练的YOLOv8模型,通过openFuyao模型量化工具压缩至INT8精度,推理速度提升3倍,同时精度损失控制在1%以内。
4.1.3 实施效果数据
| 指标 | 传统方案 | openFuyao方案 | 提升幅度 |
|---|---|---|---|
| 模型推理延迟 | 500ms/件 | 90ms/件 | 降低82% |
| 单设备支持产线数 | 2条 | 10条 | 提升5倍 |
| 硬件采购成本 | 50万元/台 | 28万元/台 | 降低44% |
| 缺陷识别准确率 | 92% | 99.3% | 提升7.3% |
| 实施周期 | 3个月 | 2周 | 缩短90% |
4.1.4 商业价值
该企业通过openFuyao AI推理一体机方案,实现了产线质检的全自动化,每日可减少人工质检人员30名,年节约人力成本超500万元;产品缺陷漏检率从8%降至0.7%,客户投诉率下降90%,产品市场口碑显著提升;同时,产线产能提升20%,每年新增营收超2000万元。
五、openFuyao的生态与未来展望
openFuyao的成功不仅源于其技术实力,更在于其构建的开放、共赢的开源生态体系,以及对未来算力发展趋势的前瞻性布局。
5.1 开源生态体系
openFuyao社区采用**"贡献者-维护者-用户"** 三层生态结构,形成了持续迭代的正向循环:
• 贡献者:来自全球的开发者可通过gitcode提交代码、文档、案例,参与技术讨论,贡献者的代码经过社区评审后将被合并到主线版本;
• 维护者:由华为技术团队与社区资深开发者组成,负责技术路线规划、代码审核、版本发布、社区运营;
• 用户:企业用户可免费使用openFuyao的所有技术组件,同时可通过社区获取技术支持、案例参考、定制化服务。

5.2 行业合作与落地
openFuyao已与众多行业头部企业建立深度合作,覆盖互联网、金融、制造、科研、能源等领域:
•互联网:与多家TOP级互联网公司合作,优化超大规模集群管理与在离线混部能力,支撑亿级用户规模的业务场景;
•金融:为银行、证券、保险机构提供AI推理加速与分布式作业调度方案,提升风控、交易、客服等业务的算力效率;
•制造:与汽车、电子、机械制造企业合作,落地AI推理一体机方案,推动智能制造与工业质检的智能化升级;
•科研:为高校、科研机构提供超大规模集群管理工具,支撑天体物理模拟、基因测序、气象预测等科研计算场景。
5.3 未来技术布局
openFuyao团队基于对算力发展趋势的判断,明确了三大未来技术方向:
1.存算网一体化:打破存储与计算的物理边界,实现数据在存储节点与计算节点之间的智能流动,降低数据搬运成本,提升算力效率;
2.AI原生算力调度:针对大模型训练、推理、微调等AI原生场景,开发专用的算力调度算法,实现算力资源与AI任务的深度适配;
3.边缘算力协同:将中心算力与边缘算力(如边缘服务器、智能终端)进行协同调度,满足物联网、自动驾驶、智慧城市等场景的低延迟、高并发算力需求。
六、结语:算力革命的新起点
openFuyao以其算力释放创新组件为核心,通过七大集群能力与两大场景化方案,不仅解决了当前算力利用效率低、落地成本高、场景适配难等行业痛点,更在开源生态与商业价值之间找到了完美的平衡点。从技术架构到代码实现,从场景落地到生态建设,openFuyao正引领着一场关乎数字经济根基的算力革命。

在未来,随着存算网一体化、AI原生算力调度、边缘算力协同等技术的持续突破,openFuyao必将在更多行业、更多场景中绽放光彩,成为全球算力创新领域的中坚力量,推动人类社会向更高效、更智能的算力时代迈进。无论是企业的数字化转型,还是开发者的技术创新,openFuyao都将是值得信赖的算力伙伴,共同书写算力效能革命的新篇章。