文章目录
- 自定义协议(应用层)
- HTTP协议
- 协议格式------请求
-
- URL
- [URL encode -- urlencode](#URL encode -- urlencode)
- 认识方法(method)
-
- [GET和POST的区别 ★ -- 经典面试题!!!](#GET和POST的区别 ★ -- 经典面试题!!!)
- GET和POST误区!!!!★
- 认识报头(Header)部分
- 协议格式------响应
-
- 状态码
-
- [1.200 OK](#1.200 OK)
- [2.404 Not Found](#2.404 Not Found)
- [3.403 Forbidden](#3.403 Forbidden)
- [4.405 Method Not Allowed](#4.405 Method Not Allowed)
- [5.500 Internal Server Error](#5.500 Internal Server Error)
- [6.504 Gateway Timeout](#6.504 Gateway Timeout)
- [7.301 Moved Permanently(永久重定向)](#7.301 Moved Permanently(永久重定向))
- [8.302 Move temporarily(临时重定向)](#8.302 Move temporarily(临时重定向))
- 其他
- 结语
这里是@那我掉的头发算什么
刷到我,你的博客算是养成了😁😁😁

自定义协议(应用层)
在网络初识那部分,我们讲了TCP/IP五层模型。在其中,程序员接触最多的其实就是应用层。程序员写的代码中,只要涉及到网络通信,都可以视为应用层的一部分。在其中所涉及的一些协议,很多都是程序员自定制的。
那么,如何自定义协议?
1.根据需求,明确传输哪些信息。
这个其实很简单,就拿点外卖来说,用户需要传递的信息就是自己的位置以及ID等。服务器给出的响应就是商家id名字,食物图片,评分,配送费等。
2.约定好组织信息的格式
组织信息的格式
- 行文本(Line Text)
结构:单条数据占一行,字段用逗号、制表符或自定义分隔符分割,无嵌套结构。
优点:极致简洁,存储 / 传输成本低,支持流式读取(适合超大文件),几乎无解析开销。
缺点:不支持嵌套和复杂数据类型,字段无自描述性,易因分隔符冲突导致解析错误。 - XML(Extensible Markup Language)
结构:通过 <标签> 定义层级关系,支持属性、嵌套和命名空间,语法严格规范。

图中的标签都是自己定义的,可读性非常好。
优点:结构化强、自描述性好,支持版本兼容和复杂元数据,成熟生态(解析工具 / 验证机制完善)。
缺点:冗余度高(标签占比大),消耗更多的带宽(带宽很贵),解析速度慢,文件体积大,不适合高并发场景。 - JSON(JavaScript Object Notation)
结构:键值对(key:value)格式,支持数组、字典嵌套,语法简洁灵活。
优点:轻量易读(人眼可直接解析),跨语言兼容性极强(所有主流语言原生支持),解析速度快,支持大部分业务场景的复杂数据结构。
缺点:不支持注释(需通过约定字段兼容),二进制数据需 Base64 编码(增加开销),无强制 schema 验证(需额外工具保证数据一致性)。 - Protobuf(Protocol Buffers)
结构:先定义 .proto 协议文件(指定字段类型、名称和编号),编译后生成对应语言的解析代码,二进制格式存储 / 传输。
优点:文件体积极小(仅为 JSON 的 1/3~1/10),解析速度极快(比 JSON 快 5~10 倍),支持跨平台 / 跨语言,字段编号支持向后兼容(无需改动旧系统)。
缺点:可读性差(二进制无法直接查看),需额外维护 .proto 文件,调试需专用工具(如 protoc 编译器、Wireshark 插件),初期配置成本略高。
生产应用中,JSON 是通用首选(API / 配置),Protobuf 适合高并发 / 大数据传输,XML 用于传统系统 / 规范场景,行文本仅适用于简单日志 / 配置。
其中JSON因为兼具可读性好与冗余少最常使用。
当然,除了自定义协议之外,还有很多大佬们已经搞好的现成的协议。其中,重中之重的是http协议,在当前web开发中必不可少!
HTTP协议
请求与响应
HTTP是一问一答模式的协议
客户端发送一个请求,服务器端返回一个响应。
请求和响应是一一对应的。
当然,网络通信中也有其他的模型。比如多问一答常用于上传大文件,一问多答常用于下载大文件,多问多答在远程控制方面应用比较广(我主要常用todesk这个软件,感觉挺好用的)。
在浏览器打开网页的场景,其实就是典型的一问一答式的场景,此处使用http协议就非常合适~~~~
抓包工具
什么是抓包工具?
想要解析网络数据包的格式,此时就可以使用抓包工具,使用抓包工具就解析数据格式肥肠方便。
抓包工具相当于一个"代理",这个代理可以是用户端的代理,也可以是服务器端的代理:
正向代理(代表客户端干活):
反向代理(代表服务器干活):
这两者的工作原理差不多,都是在数据传输的过程中,在服务器端和客户端之间加上一个代理,在数据从一端传输到另一端之间,先将数据传输给代理,再由代理转发给目标。
比如说你下载了一个抓包工具并且启动,此时你的所有请求会先发给这个抓包程序,抓包程序再发给服务器,服务器给你的响应也要先发给这个抓包程序,然后再发给你。
相信聊到这里很多人会反应过来,这个抓包程序我自己抓着玩还挺有意思的,但是要是别人在我不知情的情况下,使用抓包程序把我电脑上的数据用抓包程序抓走了,那不轧钢了?!!
还真是,就比如前几年网上都在说公共场合不要随便连wifi,确实有可能里面被动了手脚,你的手机数据就被别人盗取了。。。。。。
fiddler ------肥肠简单豪用的抓包工具
下载途径也是十分简单,俺就用一个小栏讲讲就好:
1.找到官网:
2.下载免费版本哦

3.Tools + Options
4.在https界面把所有东西都打勾(有些√需要你把别的勾选上了才会出现)
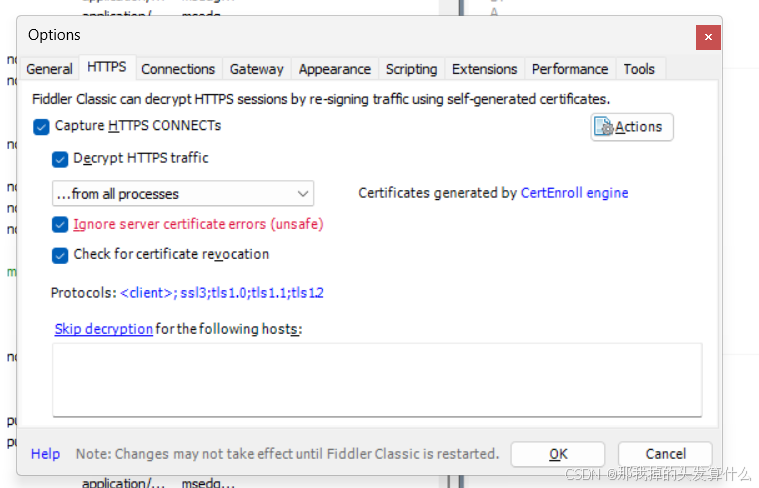
5.tips(期间出现了什么需要你信任他的证书什么类似的必须点同意!)
当然如果你忘记点了,那没招了,只能重新下载,不然不让你用
抓包工具简单使用
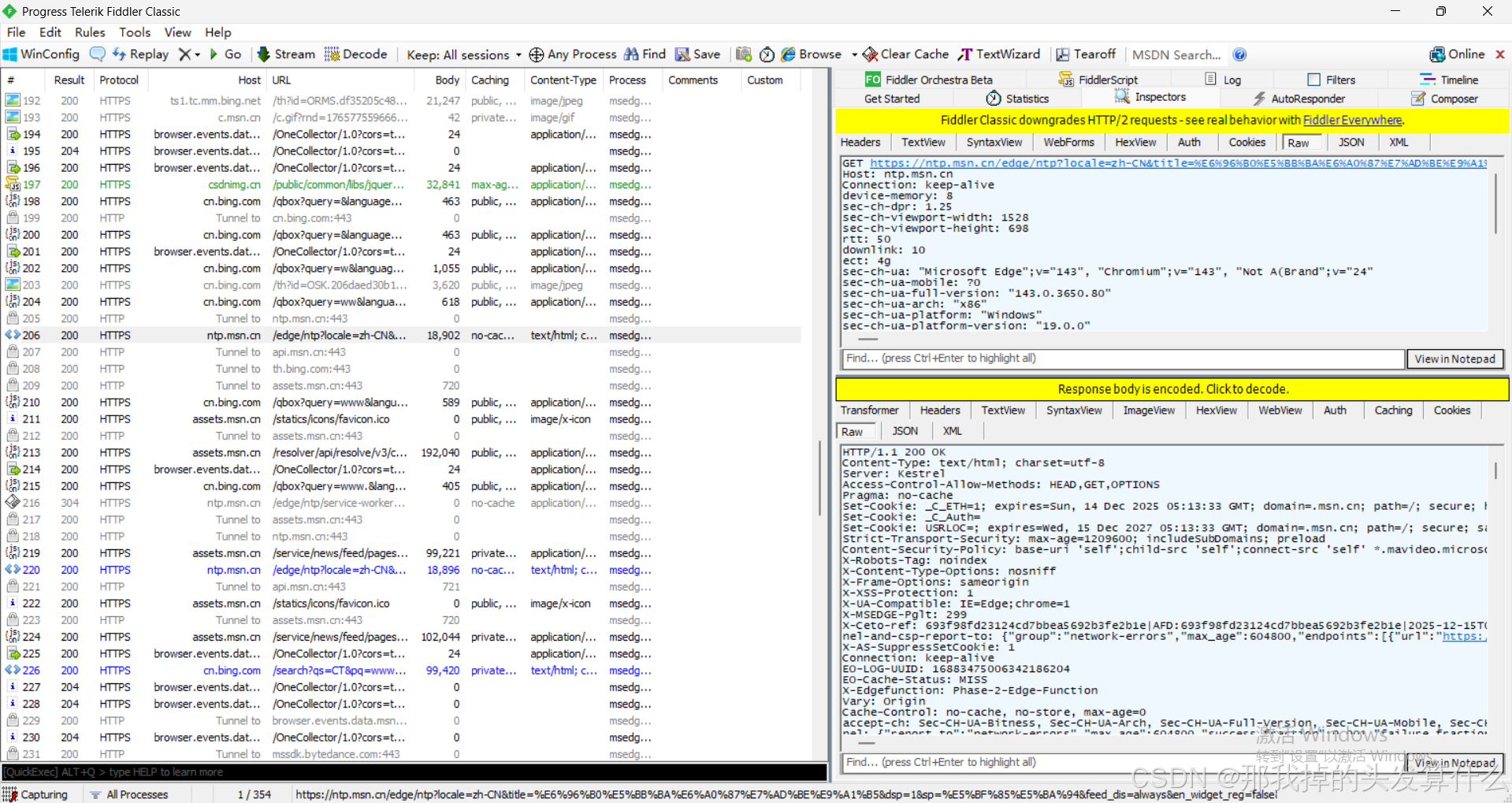
左侧窗口就是当前的请求/响应列表,这个窗口在不停的跳动,因为电脑上的很多程序都在偷偷的做一些事情。
我们此时可以打开浏览器随便进入一个网址,然后回到此页面,点击一条蓝色的行,在右边把上面和下面的选项都选上raw这个选项,此时你就可以得到和我一样的页面了。(如上图)
这个页面中,红色的表示出错,蓝色的表示这个请求得到了个网页,绿色的表示得到了一个js,灰色的表示这个响应的数据已经被缓存了。
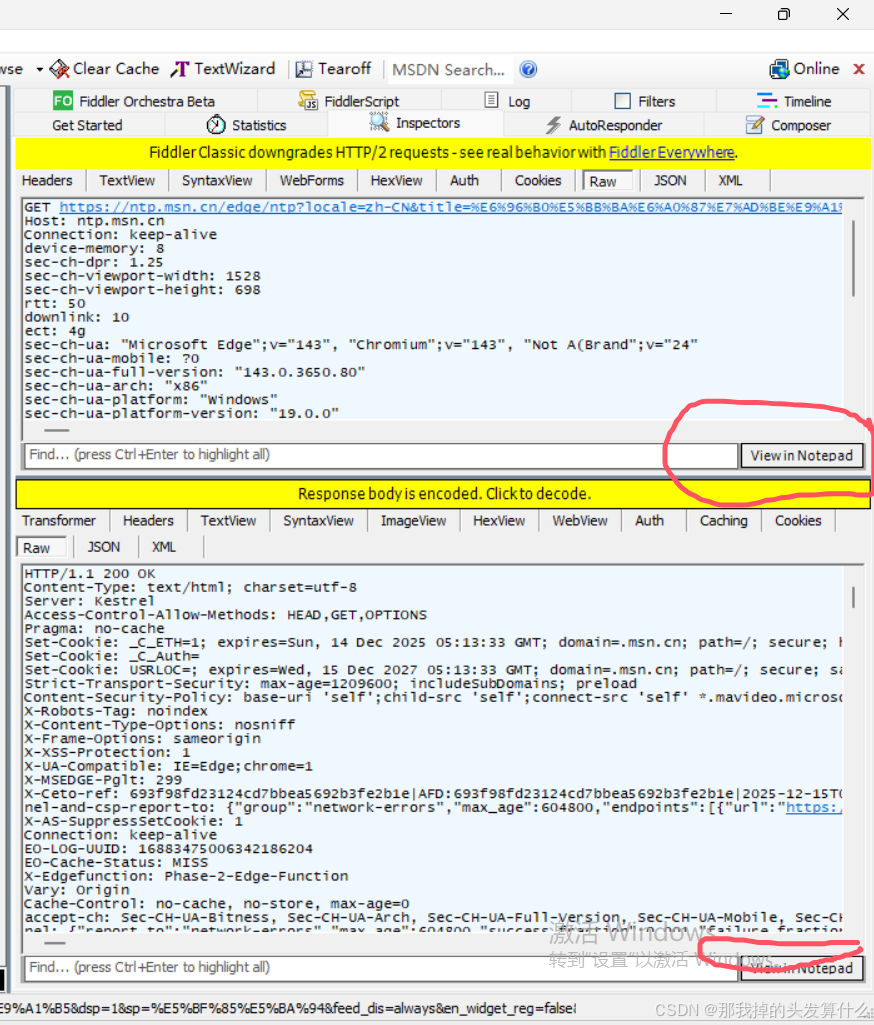
此时我们点击这个按键,就可以将这些数据使用记事本打开了。但是此时打开的话看到的还是乱码,为了节省带宽,这些数据一般是被压缩过的,我们可以点击中间那个黄色的那一行来解析数据,再打开之后就是正常文本啦~~~
其中,上面的是请求,下面的是响应:

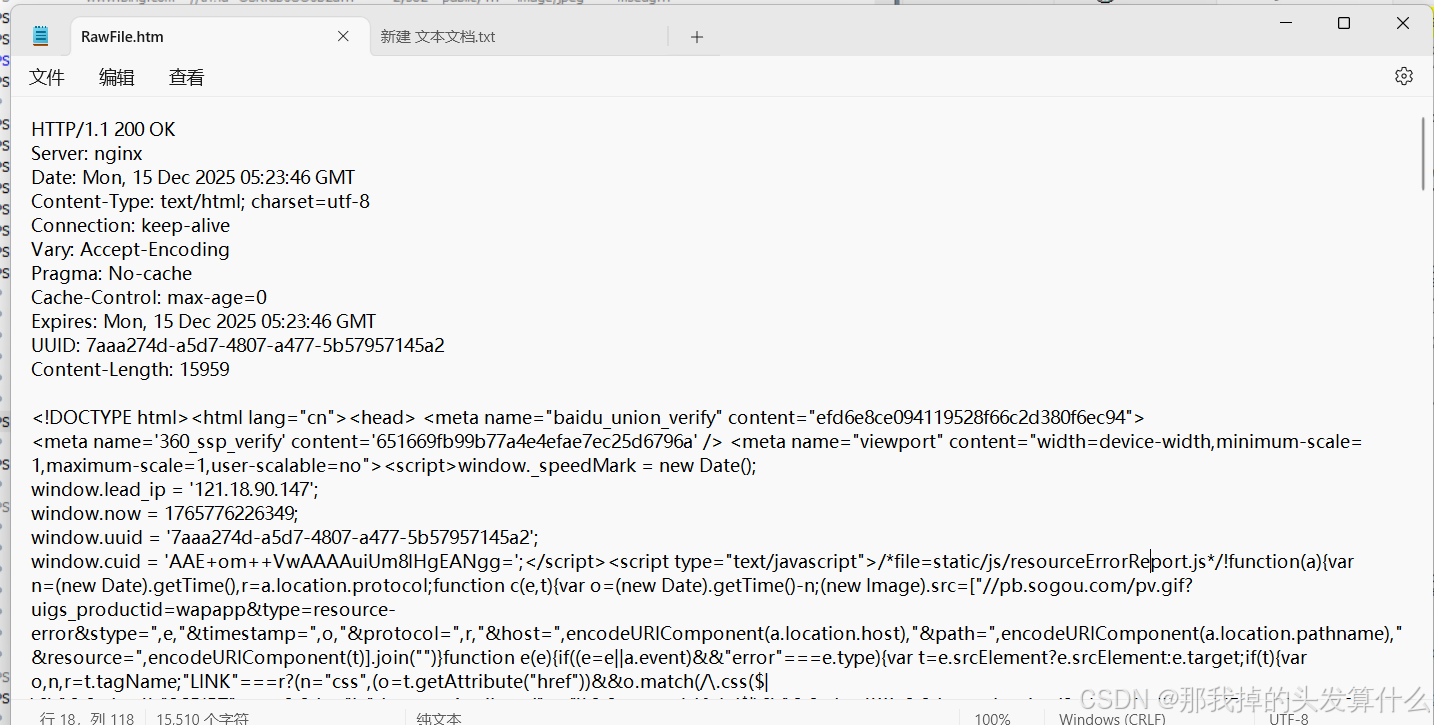
直观上看上去有点摸不到头脑,我们来细细的剖析一下下~:
请求:

响应:

请求与响应的格式也是非常相似,大致这样:
请求:1.首行2.请求头3.空行4.正文
响应:1.首行2.响应头3.空行4.正文
我们上面那个例子中请求的正文是空的,确实许多请求的正文部分都是没有数据的,但是某些场景下还是需要的,就比如下面的登录请求:
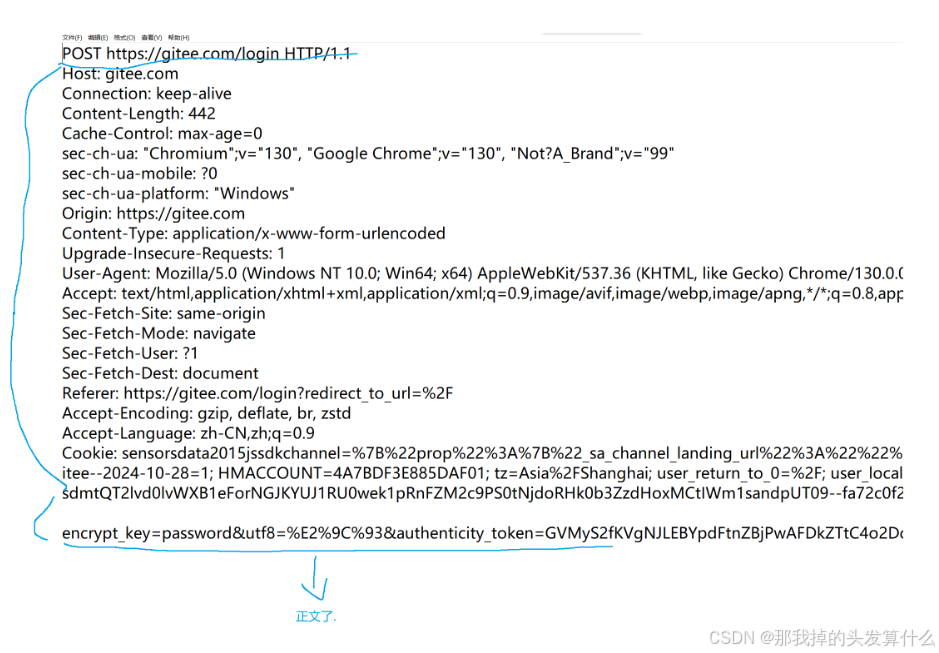
协议格式------请求
URL
URL是用来描述互联网上唯一资源的位置的。
就拿我这篇文章的网址来说(我现在还没发呢,发了之后你们看到的网址不是我现在创作时的网址):

其实我们之前在学习数据库JDBC配置datasource的时候也涉及到配置URL:

此处的协议名称就不是http/https了,毕竟URL又不是HTTP协议特有的东西。
这里还有端口号3306,但是上面的网址却没有,那是因为浏览器会添加默认的端口号,如果是HTTP->80,HTTPS->443.。
IP地址这一块使用/分割是因为这个地址是有层次的路径,/之后的是子路径。我们可以这样理解这一部分:通过IP可以定位到一台主机,一台主机上有很多的程序,通过端口号定位到目标程序,再通过子目录定位到想要的某个资源。
比如说我们打开B站视频模块里面的某一个具体的视频:

完整URL:

咱们的一个URL可以像上面这样很全面,当然也可以很简单,比如:
URL encode -- urlencode
咱们简单的搜索一下c++,会得到这样的一个网页:
搜索abc:
搜索你好:
https://www.sogou.com/web?**query=你好** &_ast=1765782875&_asf=www.sogou.com&w=01029901&p=40040100&dp=1&cid=&s_from=result_up&sourceid=5_01_03&sessiontime=1765782896353

URL 本身的结构里,像 : / ? # & = 这些符号是有专门作用的:
?:分隔 URL 路径和查询参数(query string)
&:分隔多个查询参数
=:分隔参数名和参数值
比如 sogou.com/web?query=xxx&asf=ww 里,? & = 都是 URL 的 "控制符号"。
为什么需要转义(urlencode)?
如果你的查询内容里本身包含这些控制符号 / 非英语字符,不转义会让服务器 "认错",导致请求失败:
例子 1:想搜 "c++",如果直接写 query=c++,URL 里的+会被当成 "空格",服务器会解析成 "c "(c 加空格)。
所以得把+转成%2B,变成 query=C%2B%2B。
例子 2:想搜 "你好",中文不属于 URL 默认支持的 ASCII 字符,必须转成 "%+UTF-8 十六进制编码":
"你" 的 UTF-8 编码是E4 BD A0 → 转成%E4%BD%A0;
"好" 的 UTF-8 编码是E5 A5 BD → 转成%E5%A5%BD;
所以实际请求里的 query 是%E4%BD%A0%E5%A5%BD。
浏览器为了让用户看得懂,显示的时候会把转义后的内容还原(比如显示 "你好"),但实际发请求时,传的是转义后的 % 开头的编码(抓包就能看到)。所以我们平时去看搜素栏里的数据发现就是中文,但是抓包或者复制出来就是转义后的编码。
认识方法(method)
其实请求这里涉及到的方法还真不少。。。。。。
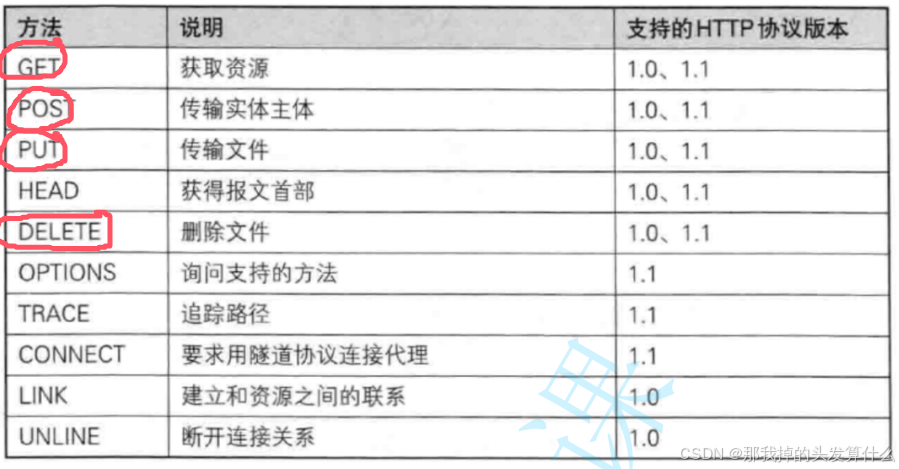
不过还好,我们只会涉及其中的四个,并且主要学习的也就两个-GET&POST。
从语义上来说,GET就是获取资源,对网页仅仅是访问,不会修改数据。POST是创建/提交资源,向服务器发送数据,当然也会修改数据库中的数据。
不过,程序员实际实现的时候,是可以自行灵活掌握的。
一般来说,
1.获取html,获取css,获取js等操作,都是get
2.登录,上传文件是典型的post
获取css\js\html的话,像我们这样直接刷新(F5)一个页面来重新访问是抓不到的,只能拿到访问网页的请求和响应:
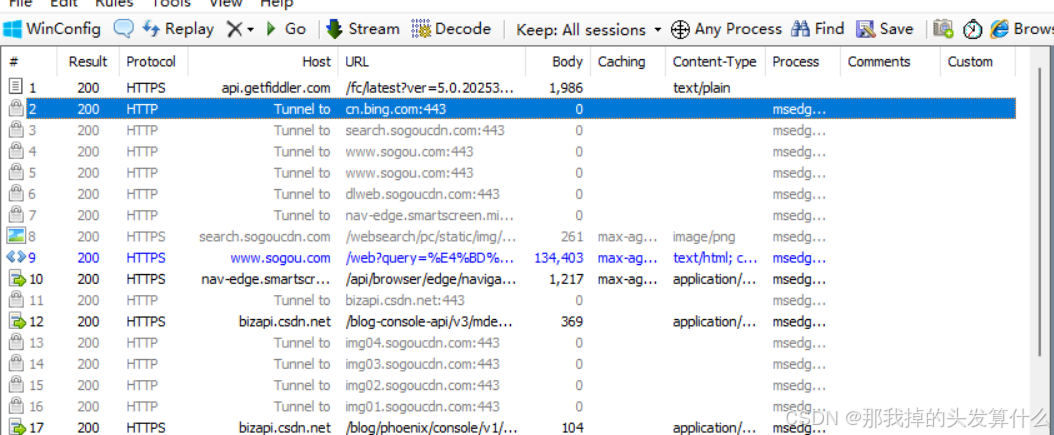
因为访问一次服务器需要加载的东西很多,如果每次都需要重新加载,未免太浪费时间(你翻个页啥的不也算重新加载嘛),所以浏览器自身有一个缓存机制:将网页依赖的静态资源(CSS、JS、图片、字体、音频等)这些不会频繁变化的资源缓存到本地硬盘,下次加载时直接从硬盘读取。
不过,如果我们使用强制刷新(ctrl + F5)就可以打破缓存机制了。
此时抓包的结果就会有很大的变化:
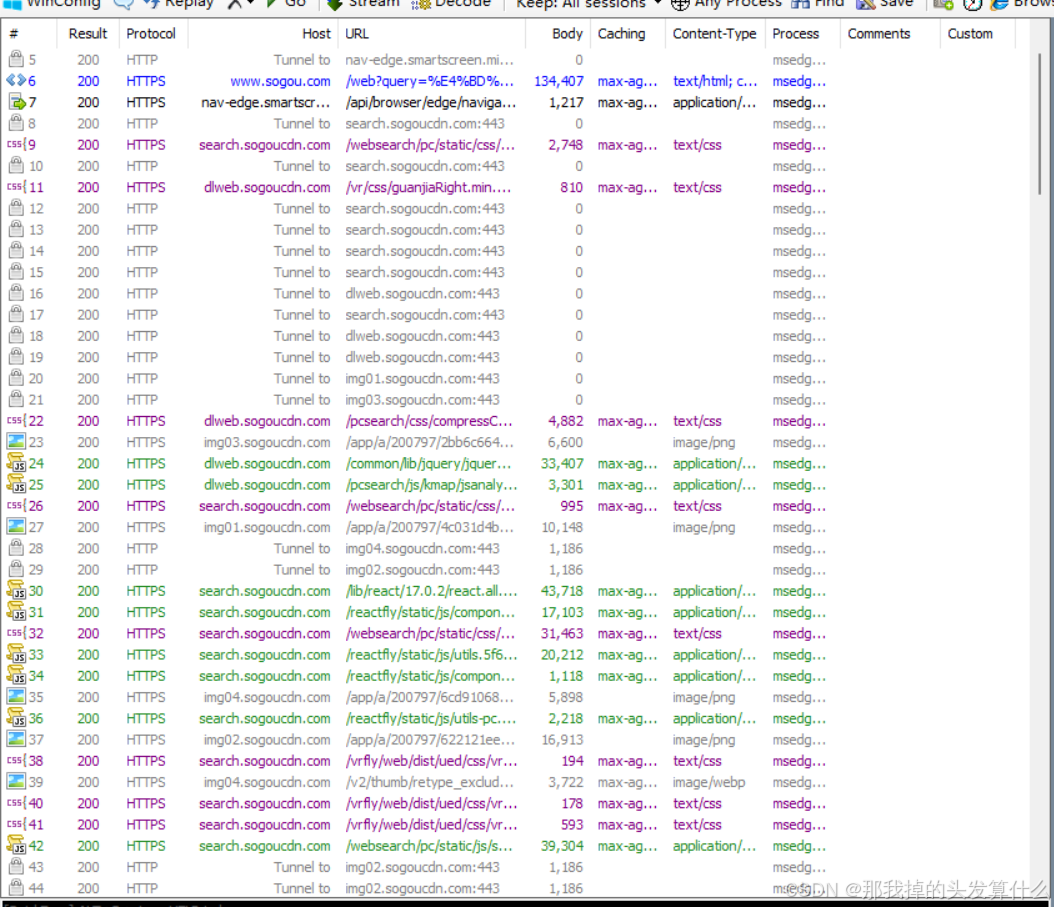
Fiddler 默认颜色规则(对应你截图里的情况):
蓝色:对应 HTML 类资源(Content-Type 为text/html),比如截图里第 5 行的text/html;
紫色:对应 CSS 样式文件(Content-Type 为text/css),比如截图里第 9、10 行的text/css;
黄色:对应图片资源(Content-Type 为image/png/image/jpg等),比如截图里第 23 行的image/png;
绿色(截图里部分行):对应 JavaScript 文件(Content-Type 为application/javascript/text/javascript);
黑色 / 灰色:对应 "Tunnel 隧道请求"(比如截图里的Tunnel to行),是 HTTPS 连接时的加密通道建立请求。

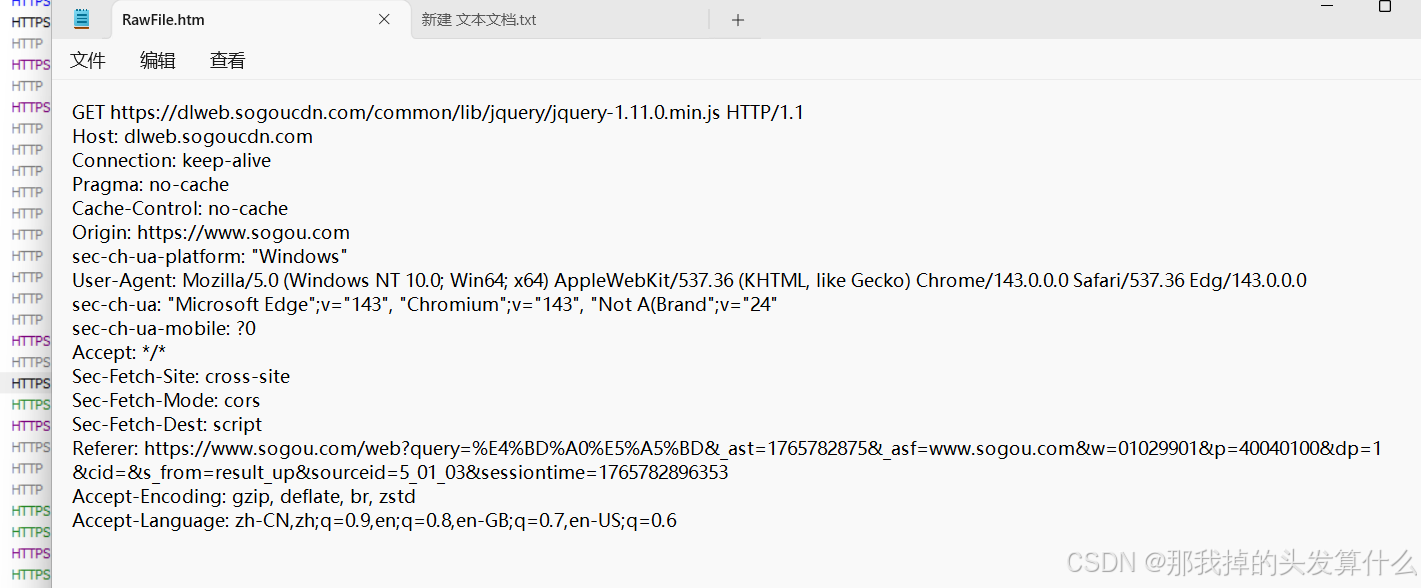
而这些html啦,css啦,js啦,首行中显示的都是GET方法!
还有就是这些请求中都没有body部分,如果需要通过GET给服务器发送一些数据,一般都是通过query string发送过去~~
我们在一些登录的场景下,抓包工具抓到的方法就是POST了:
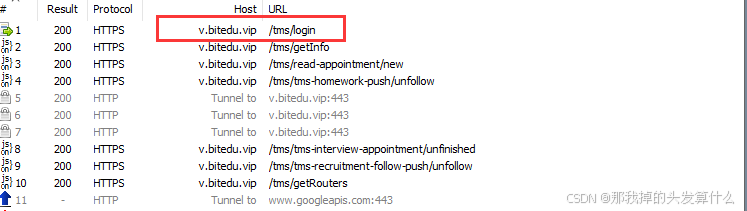
POST https://v.bitedu.vip/tms/login HTTP/1.1
Host: v.bitedu.vip
Connection: keep-alive
Content-Length: 105
sec-ch-ua: " Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"
sec-ch-ua-mobile: ?0
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
Access-Control-Allow-Methods: PUT,POST,GET,DELETE,OPTIONS
Content-Type: application/json;charset=UTF-8
Access-Control-Allow-Origin: *
Accept: application/json, text/plain, /
Access-Control-Allow-Headers: Content-Type, Content-Length, Authorization, Accep
Origin: https://v.bitedu.vip
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: cors
Sec-Fetch-Dest: empty
Referer: https://v.bitedu.vip/login
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: username=123456789; rememberMe=true
{"username":"123456789","password":"xxxx","code":"jw7l","uuid":"d110a05ccde64b16
可以看到,方法为POST。
这里的body部分就是一些登录使用的账号密码等,如果是上传文件(图片也是文件),比如更换头像这一场景,body部分显示的就是图片的信息,一般是图片的二进制信息转码后的数据。
GET和POST的区别 ★ -- 经典面试题!!!
1.语义上的区别~
2.携带数据的方式不同
POST通过body携带数据,GET通过query string携带数据。
不过呢。。。。。。其实GET和POST在上面两点中没有本质区别,其实语义上可以混着用,而且POST也是可以带有quey string,GET理论上也可以带有body,只是这两个现象比较少见,他们的区别实质上只是使用方法习惯上的不同!
3.GET请求常建议 设置成幂等的,POST无要求
幂等:请求一样得到的响应也是一样的
4.GET设置成了幂等的,所以可以允许GET请求的结果被缓存(浏览器缓存机制),POST不要求幂等,认为不能被缓存。
不过呢。。。。。。GET也是建议设置成幂等的。咱就比如说,你打开b站主页,你刷新几次,每一次推送给你的都是不同的视频,因为目前的互联网比较讲究"个性化推荐"。
所以呢,其实GET和POST始终保持着一种很暧昧的方式...
GET和POST误区!!!!★
这些误区主要是针对网上的一些说法,这些说法十分的片面和主观,容易误导他人。现在来分析一下某些观点:
1.POST比GET更安全???
此种说法常见于登录场景下,如果使用GET方法用户名密码就会通过url的query string传输,直白的显示在浏览器搜索栏里,所以GET不安全。
这个说法很片面,安不安全关键是"加密传输",加密传输下,就算加密后的数据被看到了也没关系,毕竟没法被破解,还是拿不到你的用户名密码。并且,虽然POST是通过body部分传输的数据,但只要懂抓包,随便下个软件就能轻松拿到数据,此时如果是明文传输,也不安全~~
2.GET传输数据有长度限制???
上古时期IE浏览器的年代,确实对URL长度有限制,如果传输的数据过多,可能会被截断。但是这个问题早就被解决了,现在允许很长的URL的出现。
3.GET只能传输文本,POST可以传输二进制
GET在URL中确实只能放文本,因为二进制会被转码成文本样式。但是GET有时候可以带有body部分,而body部分允许带有二进制。
所以以上三个观点都是不对的!!!
认识报头(Header)部分
报头部分是一对对的键值对,其中每一行的键值对都有其特定的意义,我们将主要介绍其中几个常见的键值对。
1.HOST
表示服务器主机的地址和端口或者域名
要注意区分,他与首行中的地址不一样,Host的地址是实际服务器所在的地址,是真实的地址,而如果有代理,首行则表示的是代理的地址。
2.Content-Length
表⽰ body 中的数据⻓度,单位是字节。
主要用于看请求中是否有body。
意义:
一个链接上可以发送很多个请求,服务器收到请求之后需要划分哪里到哪里是一个完整的请求。
如果显示没有body,读取到空行,就可以认为一个请求结束了。
如果有body,读取到空行后,查看Conteng-Length的值,根据值再读取固定长度的字节。
3.Content-Type
表示请求中的body的数据格式,提示接收方如何解析body中的数据

4.User-Agent (简称 UA)
例子:

UA里面表示了用户的设备的浏览器和操作系统的情况(版本与类型)
作用:
1.早期网页的适配困境
网页功能从 "仅文本" 逐步升级(加图片、样式、JS、多媒体),但同一时段用户浏览器版本有新旧差异(旧版支持功能少,新版功能多)。
若只做多功能页面,旧版浏览器用户无法正常显示;若只做少功能页面,又会失去竞争优势。
解决方案:通过 UA 区分浏览器 / 系统版本,给旧浏览器返回 "少功能简版页面",给新浏览器返回 "多功能富版页面"------ 但这需要程序员维护多套代码。
2.2024 年 UA 的新用途
浏览器本身差异变小,但 UA 可以用来区分设备类型(PC / 手机 / 平板),给不同设备返回对应版本的页面。
5.Referer
表示这个页面是从哪个页面跳转过来的。
直接在搜索栏输入url和点击收藏页打开的页面是没有Referer的。
如果我们搜索搜狗浏览器并且点击进入网站:

如果直接通过URL跳转:

此时就没有Referer。。
6.★Cookie
Cookie 是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器下次请求同一服务器时被携带并发送回去。
实际应用中,浏览器会限制js,禁止他随意修改用户本地硬盘的数据,防止他做坏事。但是实际开发中又确实想要把一些数据保存到本地,于是引入了cookie。cookie本质也不是直接储存,可以理解为他是把数据存储到了浏览器网页里,会随着浏览器下一次请求服务器时被发送过去。
核心作用:
身份识别与会话维持
用户登录网站后,服务器会生成唯一标识的 Cookie 发送给浏览器。后续用户访问该网站的其他页面时,浏览器会自动携带这个 Cookie,服务器就能识别出用户身份,不用重复登录。
分类:
会话 Cookie(临时 Cookie)这类 Cookie 不保存在硬盘上,只存在于浏览器的内存中。浏览器关闭后,会话 Cookie 就会被删除。
持久 Cookie(永久 Cookie)这类 Cookie 会被保存在用户的硬盘中,直到设定的过期时间到达才会被删除。即使关闭浏览器,再次打开后依然有效。
临时Cookie常用于安全性较高的网站,比如学校官网,每次登录都要重新验证身份,但是访问里面的各个模块不用重新登陆
持久Cookie常用于不要求安全性的网站,比如娱乐性的短视频网站,基本上一次登录可以用很久很久。
协议格式------响应
状态码
首先呢,状态码有很多很多...但是!我们依然是只需要学习其中常用的几个!
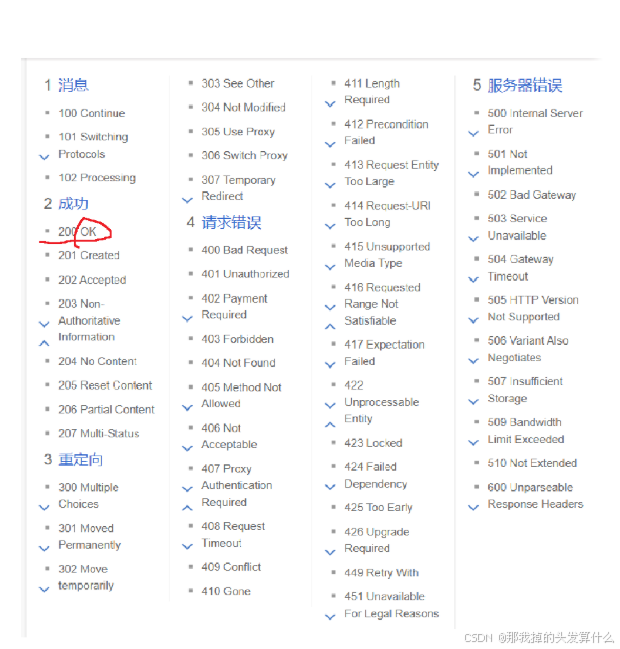
1.200 OK
最常见的状态码,表示成功!
去抓包工具随便一截,几乎都是200:
2.404 Not Found
ip和端口对上了,也就是服务器是存在的,但是路径对应的资源不存在。
可能是路径错了,或者资源被删除。
就比如说,我们在搜狗网址的基础上加上一个我们自己就感觉不存在的路径:

自然会返回404。但是服务器是存在的,并且收到了这个请求。
3.403 Forbidden
表⽰访问被拒绝. 有的⻚⾯通常需要⽤⼾具有⼀定的权限才能访问(登陆后才能访问). 如果⽤⼾没有登陆直接访问, 就容易⻅到 403.
例如: 查看码云的私有仓库, 如果不登陆, 就会出现 403.

4.405 Method Not Allowed
前⾯我们已经学习了 HTTP 中所⽀持的⽅法, 有 GET, POST, PUT, DELETE 等.
但是对⽅的服务器不⼀定都⽀持所有的⽅法(或者不允许⽤⼾使⽤⼀些其他的⽅法).
5.500 Internal Server Error
服务器出现内部错误. ⼀般是服务器的代码执⾏过程中遇到了⼀些特殊情况(服务器异常崩溃)会产⽣这个状态码.相当于出现了异常但是没有被捕获,崩了。
咱们平时常⽤的⽹站很少会出现 500 (但是偶尔也能看到)
6.504 Gateway Timeout
当服务器负载⽐较⼤的时候, 服务器处理单条请求的时候消耗的时间就会很⻓, 就可能会导致出现超时的情况
7.301 Moved Permanently(永久重定向)
含义:请求的资源已「永久迁移」到新 URL,浏览器会缓存这个重定向关系;
场景:网站域名更换(比如 old.com 迁到 new.com)、页面永久下线并指向新页面。
8.302 Move temporarily(临时重定向)
含义:请求的资源「临时迁移」到新 URL,浏览器不会缓存;
场景:用户未登录时访问需要登录的页面,临时跳转到登录页;活动页面临时指向新地址。
其他
状态码还有很多很多,记忆起来十分困难马,还好有规律:

结语
写到这里,关于应用层协议的核心知识点就全部梳理完毕啦!
从自定义协议的 4 种格式选型(行文本 / XML/JSON/Protobuf),到 HTTP 协议的 "一问一答" 本质、Fiddler 抓包的保姆级操作,再到 GET/POST 的面试高频考点和 3 大误区避坑,还有状态码的核心规律,基本上覆盖了大家学习、面试和工作中最常用的核心内容~
其实应用层协议的核心逻辑很简单:"约定好格式,明确好语义" 。不管是自己设计协议,还是使用 HTTP 这种现成协议,只要抓住这一点,再结合实际抓包拆解,再复杂的协议也能快速吃透!
如果这篇博客帮你理清了思路,别忘了 点赞 + 收藏 + 转发 三连,助力这篇干货冲热榜,让更多人少走弯路~ 要是你在实际开发中遇到了协议解析、抓包调试的问题,或者有其他想补充的知识点,欢迎在评论区留言交流,咱们一起踩坑一起进步!
最后,祝大家都能把应用层协议学扎实,面试时对答如流,工作中轻松解决各类网络通信问题~ 咱们下篇博客再见啦!😉