Ray 分布式训练的多智能体路径规划强化学习项目
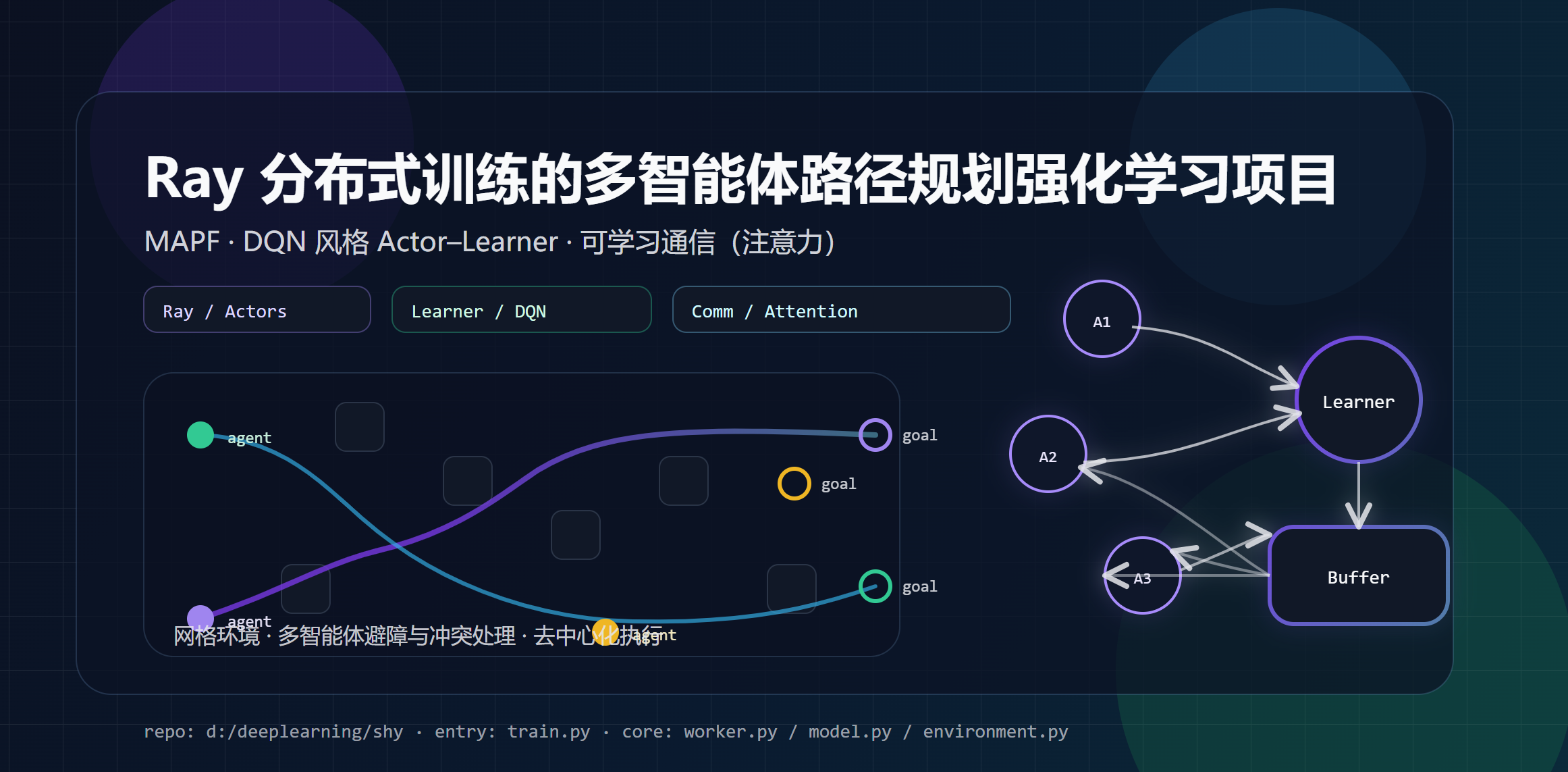
本文基于本仓库代码(train.py / worker.py / environment.py / model.py 等),介绍如何用 Ray 分布式 Actor--Learner 训练一个带可学习通信模块 的去中心化多智能体路径规划(MAPF)策略,并总结工程实现中的关键点与常见问题。
插播个新闻-有个山东潍坊的老赖-昵称是"皮蛋solo粥🌴" ,请我技术协助解决问题,解决完人家就跑了,真给山东人丢脸,下面是一些证据:
后面再问就不回消息了,
关键词(建议保留):MAPF、多智能体、强化学习、DQN、Ray、Actor-Learner、分布式训练、通信注意力、PyTorch、dtype/AMP。
1. 背景:去中心化 MAPF 与分布式强化学习
**MAPF(Multi-Agent Path Finding)**的典型目标是:在带障碍的网格地图中,多个智能体从各自起点出发到达各自目标点,要求尽量少碰撞/冲突、尽快完成。
本仓库采用 去中心化执行 (每个 agent 根据局部观测决策),训练阶段使用 分布式 off-policy 强化学习(DQN 风格),通过多 Actor 并行采样 + 单 Learner 更新参数的方式提升数据吞吐。
2. 工程总览:核心文件与职责
train.py- 训练入口:启动 Ray,创建并启动
GlobalBuffer、Learner、多个Actor。 - 启动时打印
torch.cuda.is_available()与 GPU 信息,并优先选择默认设备(可用则 GPU)。
- 训练入口:启动 Ray,创建并启动
worker.py@ray.remote远程组件:GlobalBuffer:全局优先级经验回放池(Prioritized Replay)+ 后台 batch 预取。Learner:执行训练更新、维护 target network、对外提供最新权重。Actor:与环境交互采样,产生 episode 经验并写入回放池。
environment.py- 网格环境实现:地图生成、观测构造、冲突检测、奖励计算、可视化辅助。
model.py- 网络结构:CNN 编码器 + GRU(时序记忆)+ 通信模块(多头注意力)+ Dueling Q 头。
buffer.pySumTree:优先级采样结构。LocalBuffer:单个 episode 的暂存与 TD-error 计算。
configs.py- 环境参数、训练参数、通信参数、课程学习参数、测试参数统一配置。
3. 算法与训练架构:Ray Actor--Learner(DQN 风格)
整体流程可以理解为一个"高吞吐数据生成 + 稳定参数更新"的流水线:
- Actors 并行采样
- 每个
Actor持有一个Environment与一份Network(推理用)。 - 循环执行:
env.reset()获取初始观测model.step(obs, pos)选择动作(epsilon-greedy)env.step(actions)与环境交互- 将 transition 写入
LocalBuffer
- episode 结束时
LocalBuffer.finish()打包整段轨迹并GlobalBuffer.add.remote(data)发送到全局回放池。
- GlobalBuffer 统一存储与优先级采样
GlobalBuffer用大数组存放多 episode 数据(obs/action/reward/hidden/mask 等)。- 维护
SumTree实现 Prioritized Experience Replay。 - 后台线程
prepare_data()会提前准备训练 batch,减小 Learner 等待。
- Learner 单点训练与参数广播
Learner在初始化时选择设备:torch.device('cuda' if torch.cuda.is_available() else 'cpu')。- 持有
model与tar_model(target network),周期性同步。 - 从
GlobalBuffer拉取 batch,计算 TD loss,反向传播更新。 Actor定期调用learner.get_weights()拉取最新参数并更新本地推理网络。
这种结构的优势在于:
- 多 Actor 并行采样提高数据吞吐
- Learner 单点更新便于控制优化器与 target network 同步
- 回放池解耦采样与训练,提升稳定性
4. 环境设计:网格世界、冲突规则与奖励
在 environment.py 中:
- 动作空间(5 维):停留 / 上 / 下 / 左 / 右
- 地图生成:按障碍密度随机生成 0/1 网格,并确保至少存在可用连通区域用于采样起点/终点。
- 冲突处理 :
- 越界/撞墙:回退并给 collision 惩罚
- 交换位置冲突(swap):双方回退并惩罚
- 其他同格冲突处理(文件后半段)
- 奖励函数 由
configs.reward_fn控制,例如:- move:小负值
- collision:更大负值
- finish:正奖励
环境还构造了启发式相关特征(如到目标的距离梯度),用于增强观测信息。
5. 模型设计:CNN + GRU + 通信注意力 + Dueling Q
model.py 的 Network 主要由四部分组成:
- 局部观测编码(CNN)
- 将局部栅格观测编码为 latent 向量。
- 使用残差块与
CPCA(通道/空间注意力模块)提升表征能力。
- 时序记忆(GRUCell)
- 在 step 推理时维护 hidden state,使 agent 具备一定记忆能力。
- 在训练 forward 时按序列展开,并取指定 step 的 hidden 用于 Q 估计。
- 通信模块(CommBlock + Multi-Head Attention)
- 根据 agent 之间相对距离与视野构造通信 mask。
- 对通信邻居做多头注意力聚合并用 GRUCell 更新隐藏表征。
- Dueling Q 头
V(s)+A(s,a)组合得到Q(s,a),提升稳定性。
6. 如何运行与复现实验
6.1 训练
在已安装依赖的环境中运行:
bash
python train.py启动时会打印:
torch.cuda.is_available()- GPU 数量与名称(如可用)
default device selected: cuda|cpu
6.2 配置项
直接修改 configs.py:
- 训练规模:
num_actors,batch_size,learning_starts,training_times - 环境规模:
init_env_settings,max_num_agents,max_map_lenght - 通信配置:
max_comm_agents,num_comm_layers,num_comm_heads
6.3 生成测试集/评测
bash
python test.py测试集位于 ./test_set,评测时会从 ./models 读取权重(详见 test.py 内的 test_model)。
7. 工程踩坑:CPU/GPU 与 dtype(FP16/FP32)一致性
分布式训练中最常见的问题之一,是 dtype 或 device 不一致导致的运行时报错,典型表现例如:
Input type (Half) and bias type (float) should be the samemat1 and mat2 must have the same dtype, but got Half and float
这类问题的根因通常是:
- 回放池/采样数据是 FP16
- 模型参数是 FP32
- AMP/autocast 使部分中间结果变成 FP16
- CPU 上对 FP16 的算子支持不完整
解决思路(建议择一策略贯彻到底):
-
策略 A:全链路 FP32(最稳,CPU/GPU 都可)
- 采样 batch 用 float32
- 模型参数 float32
- 禁用 AMP(或仅在 GPU 上谨慎启用)
-
策略 B:全链路 AMP/GPU(性能更好,但约束更多)
- Learner 必须在 GPU
- 输入/中间状态/损失计算路径遵守 AMP 规则
- 关键张量与参数 dtype 要统一
本仓库已在模型训练前向中做了 dtype 对齐处理,以降低 dtype 混用导致的报错概率。
8. 下一步可以改进什么
- 增加
requirements.txt或environment.yml,让依赖版本可复现。 - 将 checkpoint 保存/加载流程与评测流程在 README/博客中进一步标准化。
- 为训练与评测增加更清晰的日志与可视化(例如 TensorBoard)。
参考与致谢
- 原始 DHC 项目与示意图来源:
- https://github.com/ZiyuanMa/DHC
.yml`,让依赖版本可复现。
- https://github.com/ZiyuanMa/DHC
- 将 checkpoint 保存/加载流程与评测流程在 README/博客中进一步标准化。
- 为训练与评测增加更清晰的日志与可视化(例如 TensorBoard)。
参考与致谢
- 原始 DHC 项目与示意图来源: