文章目录
- [Ⅰ. 线程同步](#Ⅰ. 线程同步)
-
- [一、`wait` && `notify`](#一、
wait&¬ify) - [二、`wait` 与 `sleep` 的区别](#二、
wait与sleep的区别)
- [一、`wait` && `notify`](#一、
- [Ⅱ. 单例模式](#Ⅱ. 单例模式)
- [Ⅲ. 阻塞队列](#Ⅲ. 阻塞队列)
-
- [一、标准库中的阻塞队列 -- `BlockingQueue`](#一、标准库中的阻塞队列 --
BlockingQueue) - 二、自主实现阻塞队列(理解原理、细节即可)
- [一、标准库中的阻塞队列 -- `BlockingQueue`](#一、标准库中的阻塞队列 --
- [Ⅳ. 线程池](#Ⅳ. 线程池)
-
- [一、Java 线程池总体架构](#一、Java 线程池总体架构)
-
- [为什么常用 `ExecutorService` 而不用 `ThreadPoolExecutor` 直接接收线程池对象❓❓❓](#为什么常用
ExecutorService而不用ThreadPoolExecutor直接接收线程池对象❓❓❓) -
- [① 面向接口编程的思想](#① 面向接口编程的思想)
- [② 常用的工厂方法都返回 `ExecutorService`](#② 常用的工厂方法都返回
ExecutorService) - [③ 实际开发只用到 `ExecutorService` 的方法就够了](#③ 实际开发只用到
ExecutorService的方法就够了)
- [为什么常用 `ExecutorService` 而不用 `ThreadPoolExecutor` 直接接收线程池对象❓❓❓](#为什么常用
- 二、快速上手
-
- [① 使用 `Executors` 创建线程池](#① 使用
Executors创建线程池) - [② 提交任务到线程池](#② 提交任务到线程池)
- [③ 关闭线程池](#③ 关闭线程池)
- [① 使用 `Executors` 创建线程池](#① 使用
- [三、`ThreadPoolExecutor` 参数的理解💥💥💥](#三、
ThreadPoolExecutor参数的理解💥💥💥) - 四、自主实现简易线程池(理解原理、细节即可)
- [Ⅴ. 定时器](#Ⅴ. 定时器)
-
- [一、标准库中的定时器 -- `Timer`](#一、标准库中的定时器 --
Timer) - 二、自主实现定时器(理解原理、细节即可)
- [一、标准库中的定时器 -- `Timer`](#一、标准库中的定时器 --

Ⅰ. 线程同步
一、wait && notify
下面的方法,都是 Object 类实现的,所以所有类都存在这些线程同步方法!
| 方法 | 描述 | 说明 |
|---|---|---|
void wait() |
无限期等待,直到被唤醒 | 必须在 synchronized 中使用 |
void wait(long timeout) |
最多等待 timeout 毫秒 |
超时未被唤醒也会继续执行 |
void notify() |
无参数,随机唤醒一个等待线程 | 只能唤醒一个,不能控制具体唤醒哪个线程 |
void notifyAll() |
无参数,唤醒所有等待该对象锁的线程 | 所有被唤醒线程会竞争锁,推荐用于并发协作 |
wait 做的事情如下所示:
- 使当前执行代码的线程进行等待,腾出
CPU使用权,释放当前的锁 - 满足一定条件时被唤醒,重新尝试获取这个锁(不一定能拿到锁)
一般 wait() 的使用如下所示:
java
synchronized (locker) {
// 使用 while 防止 "虚假唤醒"
while (!条件成立) {
locker.wait(); // 🟢 这段逻辑是实现同步的关键一步,应该放在逻辑开头
}
// 当条件满足,才继续做事
}✅注意事项:
wait()和notify()必须在synchronized内使用 ,否则会抛出IllegalMonitorStateException- 一般放在条件不满足的位置(比如队列满或空)
- 用
while而非if来包裹wait(),防止虚假唤醒
二、wait 与 sleep 的区别
| sleep() | wait() | |
|---|---|---|
| 所属类 | Thread 类的静态方法 |
Object 类的方法 |
是否需要锁(synchronized) |
❌ | ✅ 需要,且必须在同步代码块中使用 |
| 是否释放锁 | ❌ | ✅ 释放锁,等待期间不占有对象锁 |
是否释放CPU |
✅ | ✅ |
| 唤醒方式 | 超时唤醒 | 被 notify()/notifyAll() 或超时唤醒 |
| 是否可中断 | ✅ 抛出 InterruptedException |
✅ 抛出 InterruptedException |
| 是否用于线程间通信 | ❌ | ✅ 能,用于线程间协调与同步 |
| 主要用途 | 暂停线程(模拟延迟、限流等) | 条件不满足时挂起线程,等待其他线程通知继续执行 |
Ⅱ. 单例模式
使用设计模式的目的:为了代码可重用性、让代码更容易被他人理解、保证代码可靠性。设计模式使代码编写真正工程化。设计模式就是软件工程的基石脉络,如同大厦的结构一样。
一个类只能创建一个对象,这就是 单例模式 ,该模式可以保证系统中该类只有一个实例,并提供一个访问它的全局访问点,该实例被所有程序模块共享。比如在某个服务器程序中,该服务器的配置信息存放在一个文件中,这些配置数据由一个单例对象统一读取,然后服务进程中的其他对象再通过这个单例对象获取这些配置信息,这种方式简化了在复杂环境下的配置管理。
一、饿汉模式
饿汉模式属于 "急切加载" 的方式,即在类加载时就立即创建单例对象,而不管是否会被使用。
- 优点:
- 实现简单,代码简洁。
- 线程安全,不需要额外的同步机制。
- 缺点:
- 若单例对象的成员数据过多,那么会导致整个程序启动变慢。
- 如果有多个单例类是相互依赖并且有初始化依赖顺序的,那么饿汉模式在创建的时候是控制不了这种依赖顺序。
java
public class StarvingSingleton {
// 静态变量,存储单例对象,使用final修饰
private static final StarvingSingleton instance = new StarvingSingleton();
// 私有化构造方法,防止外部通过new创建对象
private StarvingSingleton() {
}
// 提供获取单例成员接口
public static StarvingSingleton getInstance() {
return instance;
}
}💥注意事项:
- 将
instance设为final,是为了防止其它代码意外修改单例对象的引用,从而避免创建多个实例的情况。
二、懒汉模式
懒汉模式的核心思想是 "延迟加载",即只有在第一次使用单例对象时才创建它。这种方式可以节省资源,因为单例对象只有在真正需要时才会被创建!
- 优点:
- 因为对象在主程序之后才会创建,所以程序启动比饿汉模式要快。
- 只有在需要时才创建单例对象,避免了不必要的资源占用。
- 可以控制不同的单例类的依赖关系以及控制依赖顺序。
- 缺点:
- 涉及到多线程安全问题,需要加锁,实现更复杂。
java
public class LazySingleton {
// 静态变量,存储单例对象,同时使用volatile修饰
private static volatile LazySingleton instance = null;
// 私有化构造方法,防止外部通过new创建对象
private LazySingleton() {
}
// 提供一个公共的静态方法,返回单例对象
public static LazySingleton getInstance() {
if(instance == null) { // 第一次检查
synchronized(LazySingleton.class) { // 加锁
if(instance == null) { // 第二次检查
instance = new LazySingleton();
}
}
}
return instance;
}
}💥注意事项:
- 将
instance设为volatile,是为了防止编译器优化出现的指令重排序问题 ,导致上述第14行代码拿到的对象是null(重排序导致先赋值,再初始化,结果拿到的是没初始化前的null对象),此时一使用该对象,直接就奔溃了! - 这个双重判断,叫做 "双重检查锁定DCL",第一层检查是为了避免不必要的加锁带来的效率问题 ,第二层检查是为了实现单例对象,目的不同!
Ⅲ. 阻塞队列
阻塞队列是一种特殊的队列,也遵守 "先进先出" 的原则,并且阻塞队列也是一种线程安全的数据结构,并且具有以下特性:
- 当队列满的时候,继续入队列就会阻塞,直到有其他线程从队列中取走元素。
- 当队列空的时候,继续出队列也会阻塞,直到有其他线程往队列中插入元素,
阻塞队列的一个典型应用场景就是 "生产者消费者模型",这是一种非常典型的开发模型,如下图所示:
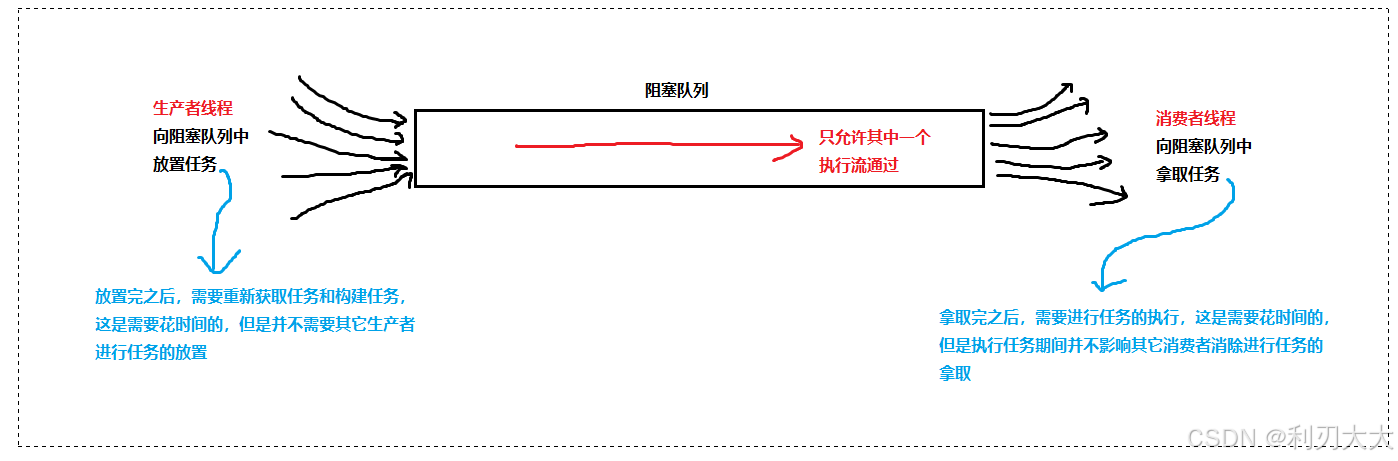
生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,而是直接扔给阻塞队列;消费者不找生产者要数据,而是直接从阻塞队列里取。
下面是生产者消费者模型的优缺点:
- 优点:
- 削峰填谷。减少出现生产者资料生产少了之后消费者也消费的少,或者消费者消费地快导致生产者来不及生产的情况。
- 降低耦合度。生产者线程只负责生产资料然后放到阻塞队列中,而不关心消费者的任务;消费者线程只需要从阻塞队列中获取资料进行消费,而不关心生产者的任务。
- 减少资源竞争,提升程序效率。可以理解为有了阻塞队列之后,生产者和消费者都只能依次排队操作队列,且队列会自动安排进出顺序,这不就既高效又有秩序了吗?
- 缺点:
- 系统更加复杂。
- 引入队列的层数太多,会增加网络传输的开销。
一、标准库中的阻塞队列 -- BlockingQueue
在 Java 标准库中,java.util.concurrent 包提供了多种阻塞队列的实现,这些阻塞队列都实现了 BlockingQueue 接口。
以下是 BlockingQueue 接口的主要方法:
| 方法 | 描述 |
|---|---|
void put(E e) |
将元素插入队列的尾部,如果队列已满,则阻塞等待,直到有空间可用 |
E take() |
从队列头部取出并移除元素,如果队列为空,则阻塞等待,直到有元素可用 |
E poll(long timeout, TimeUnit unit) |
从队列头部取出并移除元素,如果队列为空,则等待最多指定的时间,如果在指定时间内没有元素可用,则返回 null |
E poll() |
从队列头部取出并移除元素,如果队列为空,则立即返回 null |
E peek() |
查看队列头部的元素,但不移除它,如果队列为空,则返回 null |
int remainingCapacity() |
返回队列剩余的容量,即还可以插入多少元素 |
boolean offer(E e, long timeout, TimeUnit unit) |
将元素插入队列的尾部,如果队列已满,则等待最多指定的时间,如果在指定时间内没有空间可用,则返回 false |
boolean offer(E e) |
将元素插入队列的尾部,如果队列已满,则立即返回 false |
int drainTo(Collection<? super E> c) |
将队列中的所有元素转移到指定的集合中,返回转移的元素数量 |
int drainTo(Collection<? super E> c, int maxElements) |
将队列中的最多 maxElements 个元素转移到指定的集合中,返回转移的元素数量 |
💥注意事项:
- 插入和弹出队列的操作,只有
put()和take()有阻塞等待的效果 ,其它方法比如offer()、add()、poll()等是不带阻塞功能的,所以一般只用put()和take()即可。 BlockingQueue是一个接口,创建对象时候需要用以下常见的阻塞队列实现类:
| 队列类型 | 底层结构 | 有界性 | 处理优先级 | 线程安全机制 | 适用场景 |
|---|---|---|---|---|---|
| ArrayBlockingQueue | 数组(大小固定) | 有界(必须指定) | FIFO |
ReentrantLock | 严格控制任务数量、防止 OOM,适合内存敏感系统(如任务缓冲) |
| LinkedBlockingQueue | 链表 | 有界或无界 | FIFO |
插入与移除锁分离(putLock / takeLock) |
任务量大但可控时可用无界; 希望高并发性能但需限制任务量时选用有界 |
| SynchronousQueue | 无(容量为 0) |
无存储 | N/A |
ReentrantLock | 适合高并发短任务、任务直接移交等场景 |
| PriorityBlockingQueue | 堆结构 | 无界 | 优先级 | ReentrantLock | 任务需按优先级处理,如支付系统处理高金额、实时任务优先执行 |
| DelayQueue | 堆结构 | 无界 | 延迟 + 优先级 | ReentrantLock | 定时任务调度,如订单超时取消、缓存过期处理 |
二、自主实现阻塞队列(理解原理、细节即可)
💥注意事项:
- 在判断队列为空或者队列为满的时候,要用
while判断,而不能用if判断。因为比如队列为满的时候被唤醒了,也不一定队列就不满,有可能在唤醒期间有其它线程又插入了数据,此时就会出现问题!
java
public class MyBlockingQueue {
// 使用循环队列模拟阻塞队列
private String[] arr;
private int head = 0;
private int tail = 0;
private int size; // 有效元素个数
private static final Object lock = new Object();
public MyBlockingQueue(int capacity) {
arr = new String[capacity];
}
public void put(String value) throws InterruptedException {
synchronized (lock) {
// 用 while 来判断队列是否满,看看是否要阻塞
while(size >= arr.length) {
lock.wait();
}
// 插入数据
arr[tail] = value;
tail = (tail + 1) % arr.length;
size++;
// 唤醒消费者
lock.notify();
}
}
public String take() throws InterruptedException {
synchronized (lock) {
// 用 while 来判断队列是否空,看看是否要阻塞
while(size == 0) {
lock.wait();
}
// 拿到数据
String value = arr[head];
head = (head + 1) % arr.length;
size--;
// 唤醒生产者
lock.notify();
return value;
}
}
}Ⅳ. 线程池
一、Java 线程池总体架构
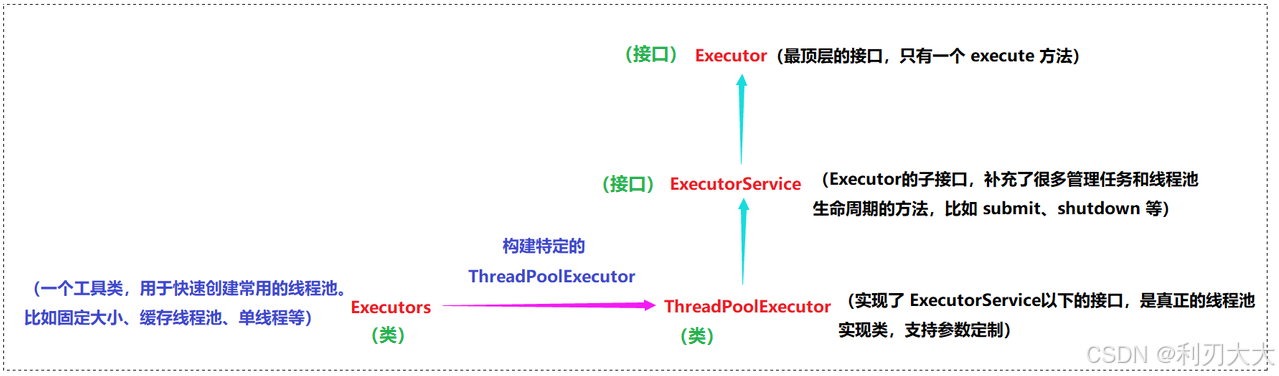
Java 线程池的核心接口是 Executor 和 ExecutorService ,最常用的实现类是 ThreadPoolExecutor。
并且 Java 还帮我们搞了一个工厂类 Executors ,用于创建特定需求的 ThreadPoolExecutor,省去了麻烦的构造传参过程。
它们的关系如下图所示:
为什么常用
ExecutorService而不用ThreadPoolExecutor直接接收线程池对象❓❓❓① 面向接口编程的思想
- 灵活与扩展性:
ExecutorService是接口,ThreadPoolExecutor是实现类。接口能屏蔽实现细节,提高代码的灵活性 。比如以后你想换成另一个线程池实现,比如ScheduledThreadPoolExecutor,只用改一行初始化、不用大改其他代码。- 更好的解耦:依赖接口而不是实现类,可以让你的代码更松耦合。测试、替换实现、未来新实现(比如自定义线程池)都更容易。
② 常用的工厂方法都返回
ExecutorService常见的线程池创建方法返回的本来就是
ExecutorService接口:这样别人用你的代码/方法,只要依赖
ExecutorService的API就行,不用知道是不是ThreadPoolExecutor,还是别的啥池子。③ 实际开发只用到
ExecutorService的方法就够了
- 线程池的绝大多数常用操作,比如
execute()、submit()、shutdown()等等,全部定义在ExecutorService接口里。日常99%的场景都不需要依赖实现类的特有方法。- 只有极少数高级场景(比如你要去读线程池的活动线程数
activeCount,或者定制特殊的配置参数),才可能需要用到实现类ThreadPoolExecutor的专有方法。
二、快速上手
① 使用 Executors 创建线程池
java
public static void main(String[] args) {
// 1. 固定大小线程池:适用于负载稳定的场景
ExecutorService p1 = Executors.newFixedThreadPool(10);
// 2. 可缓存线程池:有任务就创建新线程,空闲线程会回收,适用于大量短生命周期的任务
ExecutorService p2 = Executors.newCachedThreadPool();
// 3. 单线程的线程池,保证任务顺序执行
ExecutorService p3 = Executors.newSingleThreadExecutor();
// 4. 定时/周期性线程池:适用于延迟或周期性任务调度
ExecutorService p5 = Executors.newScheduledThreadPool(10);
}线程池与阻塞队列的匹配关系如下表所示:
| 线程池类型 | 使用的阻塞队列 | 设计目标 |
|---|---|---|
| FixedThreadPool | LinkedBlockingQueue | 固定线程数,任务队列无界,避免线程频繁创建 |
| CachedThreadPool | SynchronousQueue | 线程数动态扩展,任务直接传递,适合短时任务 |
| SingleThreadExecutor | LinkedBlockingQueue | 单线程顺序执行任务 |
| ScheduledThreadPool | DelayedWorkQueue | 延迟或周期性任务调度 |
要手动创建线程池的话,可以看后面 ThreadPoolExecutor 参数的解释!
② 提交任务到线程池
创建出线程池之后,就要提交 "任务" 到线程池中,由线程池自己调度或创建新线程来完成该 "任务"。下面是 Executor 中给出的两个提交任务的接口:
| execute | submit (推荐⭐⭐⭐) | |
|---|---|---|
| 接收参数类型 | Runnable(无返回值) |
Runnable |
| 返回值 | void(无返回) |
Future(可获得返回和异常) |
| 任务异常处理 | 线程池会捕获但不会报告异常 | Future.get() 时抛出 ExecutionException |
| 任务中断支持 | 无 | 可以 cancel 中断任务 |
| 用途 | 简单任务,不关心结果 | 需要关心任务结果或异常 |
现代最佳实践其实推荐多用 submit,因为哪怕暂时不需要返回值,有 Future 也能后续扩展,比如取消、结果统计等。
java
// 1. 创建一个指定数量线程的线程池
ExecutorService p1 = Executors.newFixedThreadPool(10);
// 2. 让线程池中10个线程来处理100个打印任务
for(int i = 0; i < 100; ++i) {
int index = i;
p1.submit(() -> { // submit不处理返回值是没问题的!
System.out.println(Thread.currentThread().getName() + ":" + index);
});
}③ 关闭线程池
用 shutdown() 优雅关闭,不再接收新任务,等待现有任务执行完毕。
Java
p1.shutdown();三、ThreadPoolExecutor 参数的理解💥💥💥
java
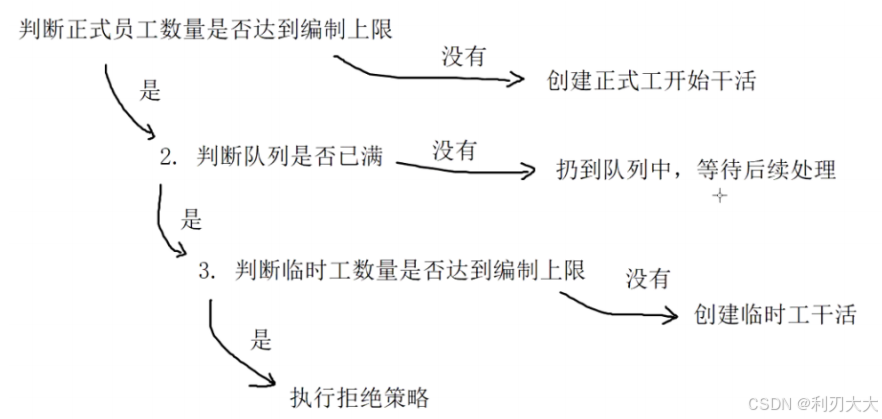
ThreadPoolExecutor pool = new ThreadPoolExecutor(
int corePoolSize, // 核心线程数
int maximumPoolSize, // 最大线程数
long keepAliveTime, // 非核心闲置线程最大存活时间
TimeUnit unit, // keepAliveTime的时间单位
BlockingQueue<Runnable> workQueue, // 任务队列
ThreadFactory threadFactory, // 线程工厂
RejectedExecutionHandler handler // 拒绝策略
);corePoolSize:核心线程数量(不会被回收,相当于正式员工,一旦录用,永不辞退)maximumPoolSize:最大线程数量 (相当于正式员工 + 临时工的数量,当临时工那部分闲置超过了keepAliveTime,就会被炒掉)- 当最大活动线程数量超过
maximumPoolSize,新任务就会触发下面的 "拒绝策略"。
- 当最大活动线程数量超过
keepAliveTime:非核心闲置线程最大存活时间 (即临时工允许的闲置时间)- 如果设置了
allowCoreThreadTimeOut(true),那么核心线程如果也空闲时间超过该值也会被回收。
- 如果设置了
unit:keepAliveTime的时间单位(纳秒、微妙、毫秒、秒、分钟、小时、天)workQueue:线程池内部存储待执行任务的阻塞队列threadFactory:创建线程的工厂类,控制创建线程的细节 (如线程命名、优先级、是否为守护线程等)-

-
Java自带了现成的创建线程的工厂类,最常用的就是Executors.defaultThreadFactory() -
只有在有特殊需求时才需要自定义,比如:
- 想让线程名带有特定业务标识、更好排查问题
- 希望线程变成 "守护线程"
- 想统一捕获线程内部未捕获异常
- 对线程优先级有特殊要求
- 希望在线程创建时做监控或自定义初始化
-
handler:拒绝策略,就是任务太多,超过workQueue的容量后,要怎么处理 ,有四种内置选项:AbortPolicy(默认):直接抛出RejectedExecutionException异常DiscardPolicy:直接丢弃DiscardOldestPolicy:丢弃队列里最老的任务,然后再尝试入队当前任务CallerRunsPolicy:由提交任务的线程自己执行该任务
java
ThreadPoolExecutor pool = new ThreadPoolExecutor(
5, // corePoolSize
10, // maximumPoolSize
60, // keepAliveTime
TimeUnit.SECONDS, // 单位
new ArrayBlockingQueue<>(100), // 有界队列
Executors.defaultThreadFactory(), // 默认线程工厂
new ThreadPoolExecutor.AbortPolicy() // 拒绝策略
);
// 如果要手动自定义线程工厂,可以按照下面这样子处理,然后传myFactory给ThreadPoolExecutor即可
AtomicInteger threadId = new AtomicInteger(1);
ThreadFactory myFactory = r -> {
Thread t = new Thread(r, "mythread-" + threadId.getAndIncrement());
t.setDaemon(true); // 设置线程为守护线程
return t;
};💥注意事项:
- 参数中
BlockingQueue<Runnable>中的Runnable和ThreadFactory.newThread(Runnable r)中的Runnable是不同的,区别如下所示:ThreadFactory.newThread(Runnable r)中的r- 这个
Runnable r不是你的 "具体业务",而是线程池 "工作线程" 的调度骨架 (Worker)。它的职责就是反复从任务队列BlockingQueue<Runnable>中取任务出来执行,一旦取到任务就执行任务的run()。 - 换句话说,这个
Runnable r更像是 "消费者行为的实现",并不是你自己提交的具体业务任务。
- 这个
- 阻塞队列或者
submit(Runnable r)中的r- 这才是你写的 "具体业务":比如下载文件、处理订单、统计数据......
- 需要注意的是
submit(Runnable r)中的r和阻塞队列BlockingQueue<Runnable>中的Runnable是一回事 ,都是指具体业务,阻塞队列相当于提供了一个存放submit提交业务的空间! - 它被丢进线程池的任务队列,等消费者(即线程池
Worker线程)来拿走处理。
- 总结:
submit(Runnable r)中的r是 "具体业务",这些业务会被当作 "原料" 投向线程池由工作线程拿去处理,而工作线程的属性等是由ThreadFactory.newThread(Runnable r)中的r提供的,并且这些工作线程由线程池自主调度,不需要程序员手动处理。
四、自主实现简易线程池(理解原理、细节即可)
实现一个简易的线程池,是为了帮助理解线程池中阻塞队列的作用、线程的执行这些环节,实现起来并不难,只需要用一个阻塞队列,然后启动线程执行阻塞队列中的任务即可!
java
public class MyThreadPool {
private BlockingQueue<Runnable> qe = new LinkedBlockingQueue<>();
public MyThreadPool(int n) {
for(int i = 0; i < n; ++i) {
Thread thread = new Thread(() -> {
// 让每个线程循环处理阻塞队列中的业务,然后执行
while (true) {
try {
Runnable r = qe.take();
r.run();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
thread.start(); // 别忘了启动线程
}
}
// 将具体业务插入到阻塞队列中,具体调度由阻塞队列自己处理
public void submit(Runnable r) {
try {
qe.put(r);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}测试代码非常简单,提交任务让线程池去处理即可,如下所示:
java
public static void main(String[] args) throws InterruptedException {
MyThreadPool mtp = new MyThreadPool(5);
for(int i = 0; i < 100; ++i) {
int index = i;
mtp.submit(() -> {
System.out.println(Thread.currentThread().getName() + "处理" + index + "号业务");
});
}
}
Ⅴ. 定时器
定时器是软件开发中的一个重要组件,就是程序中闹钟,时间到了就会执行某段提前设定好的代码。比如网络通信中的最大未响应时间,超过一段时间没有收到数据,此时程序应该尝试发起重新连接等等情况。
一、标准库中的定时器 -- Timer
Timer 是 Java 中提供的一种简单的定时任务调度工具类,用于安排一个任务在指定的时间执行一次,或者周期性地执行。
Timer 的接口如下表所示:
| 方法签名 | 说明 | 是否周期执行 | 延迟类型 |
|---|---|---|---|
schedule(TimerTask task, long delay) |
延迟 delay 毫秒后执行一次任务 | ❌ | 固定延迟 |
schedule(TimerTask task, Date time) |
在指定时间点 time 执行一次任务 | ❌ | 固定时间点 |
schedule(TimerTask task, long delay, long period) |
延迟 delay 毫秒后开始,每隔 period 毫秒执行一次任务 | ✅ | 固定延迟(上次任务结束后再延迟) |
schedule(TimerTask task, Date firstTime, long period) |
指定首次时间 firstTime,之后每隔 period 毫秒执行 | ✅ | 固定延迟 |
scheduleAtFixedRate(TimerTask task, long delay, long period) |
延迟 delay 毫秒后开始,每隔 period 毫秒强制执行一次(不管上次是否完成) | ✅ | 固定频率(时间点为准) |
scheduleAtFixedRate(TimerTask task, Date firstTime, long period) |
指定首次时间点 firstTime,之后按固定频率周期执行 | ✅ | 固定频率 |
cancel() |
取消当前定时器中所有已安排的任务 | --- | --- |
purge() |
清除已被取消的任务(返回清除的个数) | --- | --- |
💥注意事项:
- 固定延迟 :下一个任务从上一个任务执行完毕后开始计算延迟,不会并发,适合非精确定时。
- 固定频率 :下一个任务的开始时间是按理想周期时间表推进,即使上一个没执行完也尝试补上,可能并发,适合高精度周期调度。
在使用的时候,Timer 需要配合 TimerTask 一起使用,如下所示:
java
// 1. 定义Timer对象
Timer timer = new Timer();
// 2. 调用schedule设置定时任务TimerTask,以及定时时长,其中TimerTask要重写run()
timer.schedule(new TimerTask() {
@Override
public void run() {
System.out.println("定时器执行3000ms");
}
}, 3000);其中 TimerTask 实现了 Runnable 接口,本质上就是在 Runnable 的基础上增加了一些属性、方法等,所以定义 TimerTask 时候重写一下其中的 run() 即可!
二、自主实现定时器(理解原理、细节即可)
java
// 任务类,保存任务以及任务执行时间
class Task implements Comparable<Task> {
private Runnable task;
private long time; // 为了方便判断时间是否到达, 所以保存绝对的时间戳
public Task(Runnable task, long time) {
this.task = task;
this.time = System.currentTimeMillis() + time; // 注意这里存放的是时间戳,所以要计算一下
}
public Runnable getTask() {
return task;
}
public long getTime() {
return time;
}
@Override
public int compareTo(Task o) {
return (int)(this.time - o.time);
}
}
public class MyTimer {
// 使用优先级队列作为存放定时任务的容器,且要以时间间隔最小的任务作为堆顶
private PriorityQueue<Task> qe = new PriorityQueue<>();
// 队列涉及到多线程操作,需要进行加锁
// 并且为了避免"忙等",可以用wait()和notify()配合,来让出CPU资源
private final Object locker = new Object();
public MyTimer() {
// 构建线程去处理定时任务
Thread thread = new Thread(() -> {
while(true) {
// 加锁
try {
synchronized(locker) {
// 判断是否有定时任务
if(qe.isEmpty() == true) {
// 1. 直接continue会导致忙等,浪费cpu资源
locker.wait();
}
// 走到这说明存在定时任务,则判断是否到达执行时间
Task t = qe.peek();
if(t.getTime() > System.currentTimeMillis()) {
// 2. 时间还没到,直接continue同样会造成忙等,浪费cpu资源,所以这里同样使用wait()等待唤醒
// 不同的是这里要设置超时时间,因为在wait()阻塞到该定时任务时间到之前如果没有新的任务来的话,这个线程
// 都不会被唤醒,导致任务没有及时处理,所以要设置超时时间为剩余等待时间!
long gap = t.getTime() - System.currentTimeMillis();
locker.wait(gap);
} else {
// 时间到了,执行任务
t.getTask().run();
qe.poll();
}
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
thread.start();
}
// 插入定时任务
public void schedule(Runnable r, long delay) {
synchronized (locker) {
qe.offer(new Task(r, delay));
locker.notify();
}
}
}💥注意事项:
- 标准库里面有一个现成的阻塞优先级队列
BlockingPriorityQueue,但这里不用它的原因是因为BlockingPriorityQueue没有定时阻塞的功能 ,在构造方法中判断是否到达执行任务的时间,没办法进行定时阻塞,从而没办法实现该逻辑,所以只能用PriorityQueue加上synchronized来实现! - 一旦程序中涉及到加锁的地方存在条件判断的时候,要考虑清楚当条件不符合时候会不会出现形如 "忙等" 的情况,然后分析这种 "忙等" 的情况对程序带来的效率问题大不大,大的话最好要用
wait()和notify()配合组合和唤醒,避免CPU资源浪费!