在 C 语言的面试和实际开发中,sizeof 是一个出现频率极高的关键词。初学者往往认为它只是用来计算变量占用空间的,但实际上,sizeof 的背后隐藏着CPU 架构 、硬件总线 甚至高并发性能的秘密。
今天,我们不注重于对齐规则,而是从硬件视角出发,彻底搞懂为什么要对齐?不对齐会发生什么?以及如何掌控对齐。
1. sizeof 的结果居然和想象中不一样!
我们可以先来看一段简单的代码,大家可以先思考一下它会输出多少?
c
#include <stdio.h>
struct demo {
char a; // 1 字节
int b; // 4 字节
};
int main() {
printf("sizeof(struct demo) = %zu\n", sizeof(struct demo));
return 0;
}我是在 64 位 Linux 系统下运行,大家的结果大概率也是这样的:

怎么样,可能有的人已经知道了这个细节,但按照正常人的思维,1加4是等于5的,结果为什么会是8呢?为什么有3个字节的内存被白白浪费了?其实这并不是编译器的 BUG ,而是编译器为了迎合 CPU 而做出的妥协。
要理解这一点,我们必须跳出软件的代码逻辑,看看硬件总线是如何工作的。
2. CPU 读取内存的方式
要理解内存对齐,首先要明白一个核心概念:CPU 读取内存并不是一个字节一个字节读的,而是一块一块读的。
2.1 数据总线与读取粒度
CPU 和内存之间有一条" 高速公路 ",叫数据总线 (Data Bus) 。这条路的宽度是固定的:
对于32位 CPU :总线宽度 32 bit,一次搬运 4 字节。
对于64位 CPU :总线宽度 64 bit,一次搬运 8 字节。
除此之外,还有一条规则:
我拿32位 CPU 来举例子,它一次只能搬运4个字节。这个规则的大致内容是,这个32位 CPU ,每次搬运只能从地址为4的倍数处(0,4,8,12等)开始搬运4个字节。
可能有人无法理解这条规则存在的意义,那我们先来看一下内存条的物理结构。
实际上,现代标准内存条(DIMM)物理位宽通常都是 64 位的。
对于 64 位 CPU,它能充分利用内存条的物理位宽,一次吞吐 8 字节。
对于 32 位 CPU ,受限于 CPU 内部的数据总线宽度,它逻辑上依然只能把内存当作 4 字节宽的设备来访问。
假设我们是一个 32 位的 CPU(一次读4字节):CPU 和内存之间有 32 根数据线 (D0 - D31)。内存条内部并不是一个字节一个字节存的,而是像4列宽的表格一样存的,想象一下有四列的 execl 表格,CPU 每次读一行(一个 Row ,也就是4个字节)。它的物理寻址逻辑是这样的:
Row 0 (地址 0) : 包含字节 0, 1, 2, 3
Row 1 (地址 4) : 包含字节 4, 5, 6, 7
Row 2 (地址 8) : 包含字节 8, 9, 10, 11
当你给内存发送读取地址 0 的信号时,内存芯片会同时把 Row 0 的 4 个字节,通过 32 根线一次性发给 CPU。
那如果你想读地址 1 呢? 也就是说你想要 字节 1, 2, 3, 4。字节 1, 2, 3 在 Row 0 里。字节 4 在 Row 1 里。而内存控制器一次只能选中一行 。它不能让数据线的一半连着 Row 0,另一半连着 Row 1。这就是物理限制。
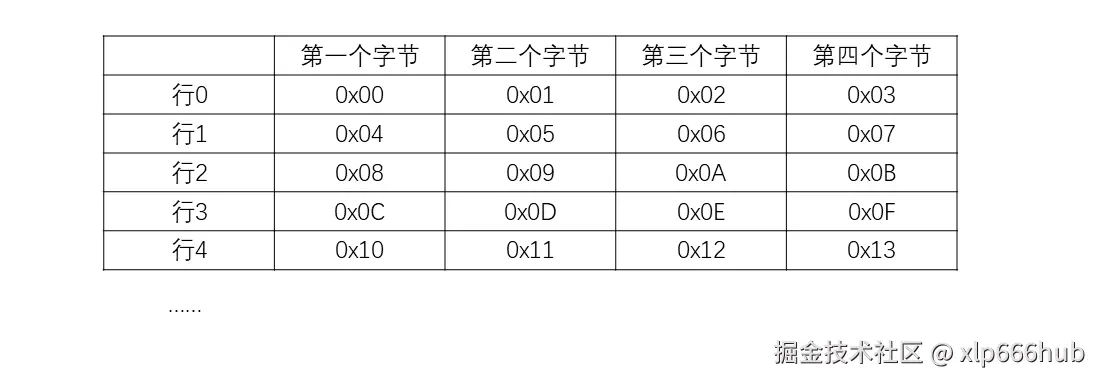
这也就解释了为什么会有4的倍数 这条规则------这本质上是为了匹配内存颗粒的物理位宽,以达到最高的传输效率。
这里再简单提一下,对于 64 位 CPU ,上面的表格中每行就是 8 个单元,代表每次读取 8 个字节。
如果我们非要读取地址 1 的数据(跨越了第0行和第1行)时,到底会发生什么?
- 在严格的架构上(如早期的 ARM、DSP) :硬件电路为了简化设计,强制要求地址必须对齐。如果 CPU 发现你试图从地址 1 读取 4 字节,它根本无法生成对应的时序信号,直接抛出 Bus Error 或 Hard Fault ,程序当场崩溃。
- 在宽容的架构上(如 x86) :CPU 硬件内部集成了复杂的处理逻辑。它会帮我们处理这种情况,自动发起两次 内存访问(一次读第0行,一次读第1行),然后在 CPU 内部将两部分数据拼接起来。虽然程序没崩,但消耗了双倍的总线周期。
因此内存对齐的本质,就是为了保证在任何架构下,都能通过单次总线传输完成数据的读取,既不死机,也不降速。
2.2 不同数据类型的自然对齐逻辑
明白了总线的物理限制后,我们就能推导出不同数据类型在内存中的存放法则。
只要遵循下面这条黄金定律,就能保证数据永远不会跨越行边界:
数据的起始地址,必须是该数据类型大小的整数倍。 即:Address % sizeof(Type) == 0。
下面我来解释一下为什么,我们还是看上面的内存表格。
- 对于 char :因为它只有 1 个字节。无论你把它放在哪个位置,它都绝对不可能同时跨越两行。因此 char 不需要对齐,地址任意。
- 对于short:它占 2 个字节。
如果放在 0:占 0, 1,在 Row 0 内,安全。
如果放在 1:占 1, 2,在 Row 0 内,安全。
如果放在 2:占 2, 3,在 Row 0 内,安全。
如果放在 3 (奇数):占 3, 4。跨行了。
因此,为了防止这种情况,short 的地址必须是 2 的倍数
-
对于 int :占满了一整行。
如果放在 0:占 0, 1, 2, 3,完美填满 Row 0,安全。
如果放在 1:占 1, 2, 3, 4。跨越了 Row 0 和 Row 1。跨行!
因此int 的地址必须是 4 的倍数,这样才能保证它永远只落在同一行里,被 CPU 一次抓取。
-
对于Double (8字节) : 在 64位系统 下,必须 8 字节对齐,否则跨越总线周期。
在 32位系统 下,虽然总线一次只能搬 4 字节,被迫读两次(这已经是极限了),但依然建议 8 字节对齐(或者至少 4 字节对齐),否则可能需要读三次!
-
对于Long : 千万不要想当然地认为 long 是 8 字节。
在 64位 Windows 下,long 依然是 4 字节(同 int)。
在 64位 Linux 下,long 才是 8 字节。
工程经验:在设计跨平台通信协议时,严禁使用 long ,请直接使用
<stdint.h>中的int32_t或int64_t,明确指定字节宽,彻底消灭歧义。
2.3 结构体中的隐形填充
在明白了上面所讲的细节之后,我们再回过头看最开始的那个结构体 Demo,就能理解编译器为什么要浪费那 3 个字节了。
c
struct demo {
char a; // 1 字节
int b; // 4 字节
};假设起始地址是 0,我们来模拟一下编译器安排内存的过程:
放置 char a:char 是一字节数据,对齐要求是 1。把它放在地址 0x00。
放置 int b:int 是四字节数据,对齐要求是 4。它必须放在 4 的倍数地址上。如果紧挨着 a 放,地址是 0x01 ,而 0x01 不是4的倍数,放在这里,CPU 读它需要两次总线操作,甚至报错。因此把 int b 放在地址 0x04。
这时,0x01, 0x02, 0x03 这三个位置是空的。编译器会在这些位置自动填入 Padding Bytes(填充字节) ,顾名思义,这些字节只是起到了填充的作用。
最终的内存布局如下:

计算总大小 :1 (a) + 3 (padding) + 4 (b) = 8 字节。
这就解释了为什么 sizeof(demo) 是 8,而不是 5。这是用空间换时间的典型策略。
3. 编译器的对齐原则
讲完了总线宽度和自然对齐,我们再来看看软件层面。编译器在处理结构体时,并不是随意填充的,而是严格遵循一套对齐算法 。这也正是我们能手动计算 sizeof 的依据。
编译器主要遵循两条核心原则:成员对齐 和 整体对齐。
3.1 成员对齐
结构体中每个成员相对于结构体首地址的偏移量 (Offset) ,必须是该成员大小的整数倍(或者编译器指定的对齐模数 #pragma pack(n),取二者较小值)。
我们还是以 struct demo 为例:
c
struct Demo {
char a; // 1 byte
int b; // 4 bytes
};结构体第一个成员的首地址 与整个结构体的首地址 是相同的,所以我们说,结构体第一个成员相对于结构体首地址的偏移量为0。
放置a:char 大小为 1。偏移量 0 正好是 1 的倍数。放在 Offset 0。
放置b:int 大小为 4。此时离 a 最近的可以存放的位置是 Offset 4。
也就是说,为了让 b 放在 Offset 4,编译器自动在 a 后面填充了 3 个字节(Padding)。

最终的内存布局是这样的。
3.2 整体对齐
结构体的总大小 ,必须是其内部最大成员大小的整数倍。
为什么要这样规定? 其实这是为了结构体数组。
如果结构体是这样的:
c
struct demo_reverse {
int a; // 4 bytes
char b; // 1 byte
};a 在 Offset 0,占据着0,1,2,3四个字节的位置。
b 是 char 型,可以任意放,那就放在 Offset 4 这个位置。
这样看起来确实是不需要填充的。
但是,如果我们定义一个数组 struct Reverse arr[2]; 会发生什么?
arr0 :占据地址 0x00 到 0x04。
arr1 :如果结构体大小是 5,也就是说没有填充,那么 arr[1] 的起始地址就是 0x05。
这时候问题出现了:arr[1].a 的地址0x05 。0x05 不是 4 的倍数。这意味着,数组里第二个元素的 int 成员竟然不对齐了 ,CPU 读它会变慢或者崩溃。
怎么解决呢?其实也很简单,编译器强制要求:结构体总大小 = 最大成员的倍数。这样就不会出现上面的问题了。
目前大小为 5,需要补齐到 8 (这是4的倍数)。所以在 char b 后面,编译器会加 3 个字节的 Padding。
此时的内存布局是这样的:

3.3 如何控制对齐
在某些场景下(比如网络传输),我们不想浪费空间,或者协议规定了紧凑排列,我们可以修改编译器的默认行为。
3.3.1 #pragma pack(n)
告诉编译器:不要按成员大小对齐,按我指定的 n 来对齐。
c
#pragma pack(1) // 强制按 1 字节对齐(相当于不对齐)
struct packed_demo {
char a;
int b;
};
#pragma pack() // 用来恢复默认a 在 0,b 在 1(因为 1 是 pack(1) 的倍数)。总共 1 + 4 = 5 字节。但是CPU 读写效率会降低。
3.3.2 __attribute__((packed)) (GCC 特有)
在 Linux 内核源码中,下面这种情况是很常见的:
c
struct packet {
char head;
int len;
} __attribute__((packed));这个效果和 3.3.1 中介绍的方法效果是相同的。
4. 实战避坑:网络通信与跨平台传输
理解了对齐,你就能避开嵌入式网络编程中最大的"坑"。很多人在本地跑代码没问题,一联调设备就崩,原因往往就在这里。
4.1 当 64位服务器遇上 32位单片机
在网络编程(物联网)中,我们经常直接把结构体指针转成 void*,通过 Socket 或串口直接发送出去。
假设我们定义了一个通信协议包:
c
struct Packet {
char cmd; // 1 byte (命令字)
int length; // 4 bytes (数据长度)
};发送端(64位 Linux 开发机):根据对齐规则,cmd 后面补 3 字节 Padding,sizeof(Packet) = 8。
发送的数据流为:[cmd] [X] [X] [X] [len_byte1] [len_byte2]...
接收端(资源受限的 32位 STM32 单片机):为了节省珍贵的 RAM,固件工程师可能在编译选项里开启了 -fpack-struct(全局紧凑模式),或者手动设置了对齐。 接收端认为:sizeof(Packet) = 5。 此时,它读取第 1 个字节当 cmd,紧接着读取第 2-5 个字节当 length。
结果是接收端把发送端填充的那 3 个垃圾字节当成了 length 的高位数据。
那么这种问题该怎么解决呢?请看下一章。
4.2 强制取消对齐
在设计跨平台通信协议时,我们不能依赖编译器的默认对齐行为,因为你不知道对方的编译器是怎么想的。
我们需要显式地让编译器不要填充。
c
struct Packet {
char cmd;
int length;
} __attribute__((packed));
#pragma pack(1)
struct Packet {
char cmd;
int length;
};
#pragma pack() 这也是上面提到的两种方法。
sizeof 变成了 5 。发送端和接收端的内存布局完全一致。但代价是性能的牺牲 。CPU 读取这个 length 时,因为地址不对齐(Offset 1),硬件需要进行两次总线访问和拼接。但在网络传输的正确性面前,这点 CPU 损耗是必须付出的。
4.3 关于 long 的陷阱
除了对齐,数据类型的大小是另一个大坑。这里我先说结论:永远不要在跨平台协议中使用 long。
因为 C 语言标准只规定 long 至少和 int 一样大,但是并没有规定具体是多少。
在Windows 64位中:long 是 4 字节 。 在Linux 64位中:long 是 8 字节。
如果你在协议里写了 long timestamp;,Windows 发给 Linux,数据就会彻底错位。
那么不用 long 的话,该怎么定义 long 大小的数据类型呢?答案是永远使用 <stdint.h> 中的定长类型,明确指定位宽,不给编译器留任何解释空间:
c
#include <stdint.h>
#pragma pack(1)
struct ProtocolHeader {
uint8_t cmd;
uint32_t length;
int64_t timestamp;
};
#pragma pack()在底层开发中,显式定义是永远优于隐式定义的。
5. 高并发下的伪共享
如果说前面的 Padding 是为了对齐而填充,那么在多线程高并发 领域,我们有时需要反其道而行之,也就是为了不对齐而填充。
这听起来很矛盾?让我们回到硬件层面,聊聊 Cache Line。关于 Cache Line的详细内容我前面的文章已经讲的非常详细了,这里我们就直接进入本章节的内容。
5.1 同一个缓存行内的竞争
Cache Line 大小通常是 64 字节 。这意味着,当你读取一个 4 字节的整数时,CPU 会顺便把附近的 60 个字节也都加载到 L1 Cache 中(空间局部性)。但在多核多线程环境下,这个机制可能会好心办坏事。假设我们有一个全局结构体,被两个线程频繁访问:
c
struct SharedData {
long a; // 线程 A 频繁修改
long b; // 线程 B 频繁修改
};long 占 8 字节,a 和 b 紧挨着,加起来才 16 字节。在内存中,它们有很大概率会处在同一个 64 字节的 Cache Line 中。
请看下面的过程:
Core A 修改了变量 a。根据 MESI 缓存一致性协议 ,它必须广播告诉其他核心:这一行 Cache Line 已经被修改了,它是脏的,你们已经获取的 Cache Line 无效。 Core B 此时想修改变量 b。虽然 b 和 a 逻辑上无关,但因为它们在同一行 Cache Line,Core B 发现自己手里的 Cache 失效了。 Core B 不得不重新从 L3 或主存拉取最新的 Cache Line 数据,然后修改 b。这一修改,又导致 Core A 的 Cache Line 失效。
结果是两个线程明明修改的是不同的变量,却在硬件缓存层面互相打架,导致 CPU 在核心间疯狂倒腾数据,总线带宽被占满,性能暴跌。
这就是著名的伪共享 (False Sharing) 。
5.2 解决方案
为了解决这个问题,我们需要手动填充 ,把 a 和 b 分到不同的缓存行,让他们老死不相往来。具体做法如下:
我们需要在 a 后面强行塞入填充字节,使其填满一个 Cache Line:
c
struct SharedData {
volatile long a;
// 强制填充 56 字节,加上long型的a正好64字节
char padding1[56];
volatile long b;
// 尾部也填充,防止 b 和后面的变量冲突
char padding2[56];
};5.3 应用案例
这种方法虽然会浪费很多字节,但是在极致的高并发领域,是非常有必要的。
Linux 内核 :在自旋锁和一些网络设备驱动的数据结构中,经常使用 ____cacheline_aligned 宏来强制对齐到 64 字节,防止多核竞争。
6. 结语
到这里,这篇文章就结束了,从最开始的一个经典案例,到对硬件层面的解读,和编译器的优化以及作为编程人员的我们该怎样控制对齐,再到网络和跨平台通信的坑和高并发下的伪共享,相信大家已经很全面的认识并理解了内存对齐存在的意义,以及如何控制它。如果大家有任何问题可以发在评论区,我看到了都会恢复
最后,如果这篇文章对你有帮助,记得点赞和关注哦~