
你每天用的ChatGPT、文心一言、通义千问,为什么能听懂你的问题、写出流畅的回答?核心秘密就藏在它们的"骨架"------大模型架构里。就像汽车底盘决定行驶性能,大模型的架构设计直接决定了它的理解能力、生成效果和运行效率。今天用大白话把复杂的大模型架构拆明白,零基础也能看懂!
一、大模型的"地基":Transformer架构
讲大模型架构,绕不开的核心技术是Transformer。2017年谷歌团队提出的这一架构,直接颠覆了此前的AI技术路线,如今所有主流大模型(无论是GPT系列还是国产模型),本质上都是在Transformer的基础上优化而来。
Transformer的核心优势是并行计算 (可同时处理大量数据)和自注意力机制(能理解文字间的上下文关系),这两个特点让模型能高效学习海量知识,也是大模型能训练到千亿级参数的关键。
2个核心概念(不用记公式!)
-
自注意力机制:相当于模型的"火眼金睛",能自动识别一句话里每个词的重要性和关联关系。比如"苹果发布了新手机,它的摄像头很出色",模型能通过自注意力机制判断"它"指的是"新手机",而非"苹果"。
-
并行计算:传统AI处理文字是"逐字逐句"的,像人读书一样从左到右;而Transformer能同时处理一整句话的所有词,效率直接翻倍,为大规模参数训练提供了可能。
Transformer的基本结构:编码器+解码器
Transformer的核心由编码器(Encoder) 和解码器(Decoder) 两部分组成,类似工厂的"理解车间"和"生成车间"。下图清晰地展示了完整的数据流动和内部组件关系: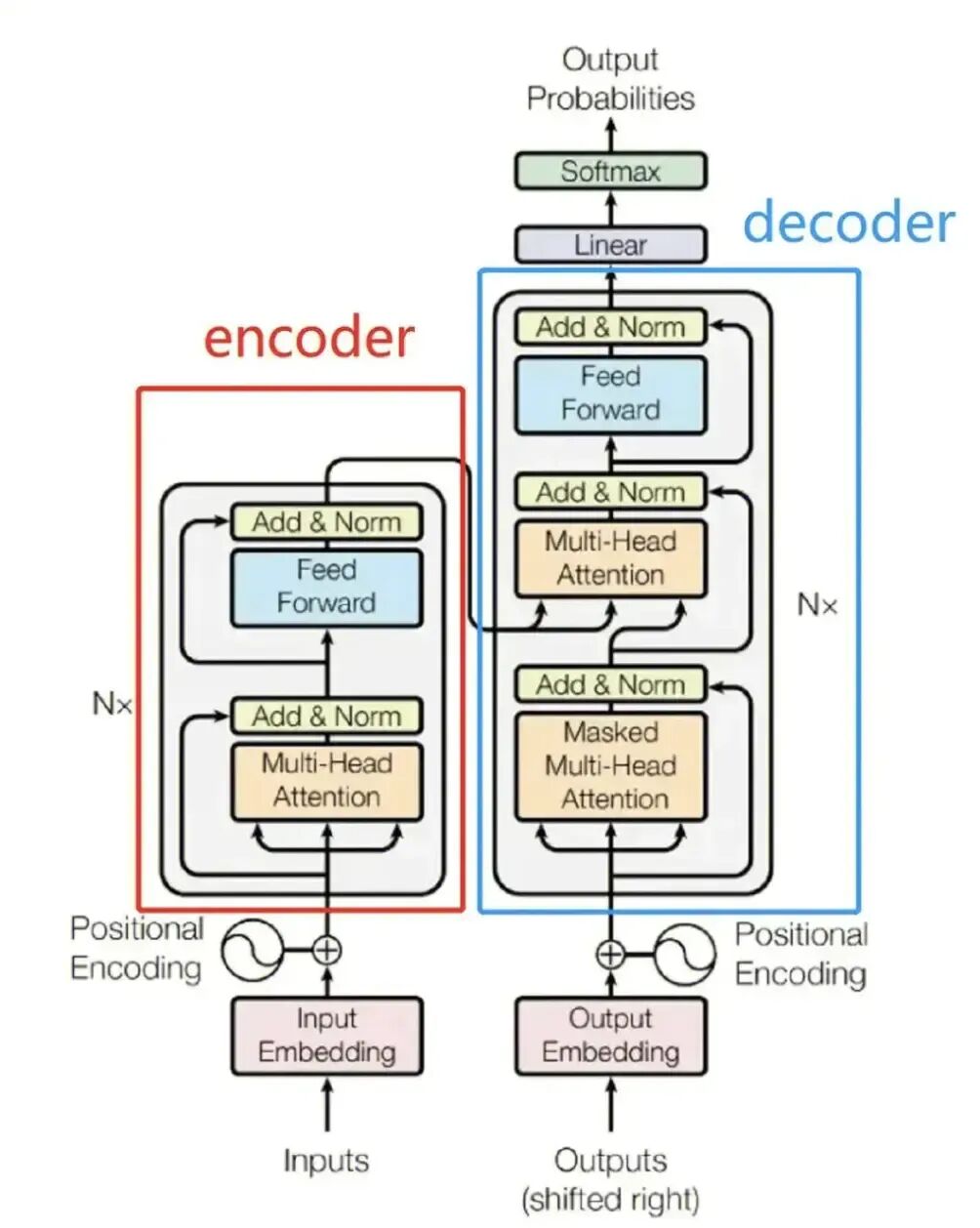
流程详解:
-
编码器(Encoder) :负责"深度理解"输入内容。多个编码器层堆叠,每一层都通过多头自注意力机制 分析词与词之间的全局关系,再通过前馈神经网络强化特征。最终输出一个富含语义的"上下文特征向量"。
-
解码器(Decoder) :负责"逐步生成"输出内容。每一层解码器首先通过掩码自注意力 关注已生成的部分(避免"偷看"未来答案),然后通过编码器-解码器交叉注意力,聚焦于编码器提供的源信息特征,最后预测下一个最可能的词。这个过程循环进行,直至生成完整回答。
二、大模型的3种主流架构:各有专长
虽然都基于Transformer,但不同大模型会根据用途选择不同的架构组合,主要分为3类,就像不同类型的工厂各司其职:
1. 自回归模型(仅解码器 / Decoder-only):生成任务的"王者"
-
核心特点:仅使用Transformer的解码器部分,擅长"续写式"生成,比如写文章、聊天、编代码。
-
工作逻辑:生成文字时像写作文,从第一个词开始,根据前文预测下一个词,逐步完成整段文本(GPT-3、GPT-4、LLaMA系列均采用此架构)。
-
核心优势:生成文本流畅度高、逻辑连贯,特别适配对话和创作类场景。
2. 自编码模型(仅编码器 / Encoder-only):理解任务的"专家"
-
核心特点:仅使用Transformer的编码器部分,专注于"理解"文本,不擅长生成内容。
-
工作逻辑:把整段文本一次性输入,编码器通过双向自注意力机制(同时看前后文)全面理解文本含义,适合做分类、提取关键词、识别实体等任务。
-
代表模型:BERT(比如判断一句话的情感倾向、提取文章核心观点等)。
3. 序列到序列模型(编码器-解码器 / Encoder-Decoder):转换任务的"能手"
-
核心特点:同时使用编码器和解码器,擅长"输入→转换→输出"的任务,比如翻译、写摘要、语音转文字。
-
工作逻辑:编码器先理解输入内容(如英文句子),再把理解结果传给解码器,解码器生成对应的输出(如中文翻译)。
-
代表模型:T5、BART(比如把"Hello World"翻译成"你好世界",或把长文本浓缩成摘要)。
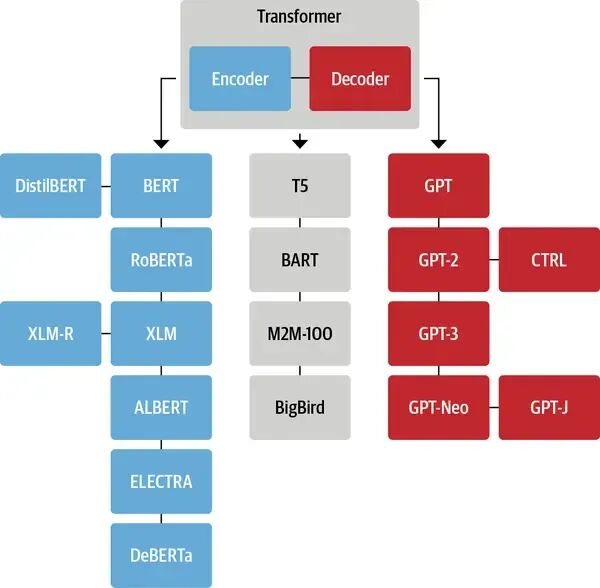 各类架构的典型代表
各类架构的典型代表
三、大模型的"进阶装备":架构创新让能力翻倍
随着大模型参数从百亿涨到千亿,单纯的Transformer架构已不够用,工程师们加入了"进阶装备",让模型又强又高效:
1. 混合专家系统(MoE):用"分工"提升效率
-
核心思路:类似医院的专科医生,大模型被分成多个"专家子网络",每个子网络专注处理某一类任务(如逻辑推理、文学创作、专业知识问答)。
-
工作原理:输入问题时,"门控网络"会判断该让哪些专家处理,只激活部分子网络,而非整个模型运转。
-
核心优势:既提升模型容量(更多专家协同),又降低计算成本(不用全模型运转),GPT-4就采用了这种架构,由多个"专家模型"组成。
2. 多模态融合架构:不止懂文字,还能看图片、听声音
-
核心思路:打破只能处理文本的局限,让模型同时理解文字、图片、视频、语音等多种信息(如GPT-4V能看懂图片并回答相关问题)。
-
工作原理:通过"联合嵌入层"把不同模态的信息(图片像素、文字编码、语音波形)转换成统一格式,再输入Transformer架构处理。
-
应用场景:图片生成文字描述、视频内容分析、语音转文字+翻译等。
3. 稀疏激活技术:让模型"轻装上阵"
-
核心思路:传统大模型是"密集型"的,每次计算都会激活所有神经元;稀疏激活技术让模型只激活与当前任务相关的部分神经元,像跑步时只动用必要肌肉。
-
核心优势:在不降低性能的前提下,减少计算量和内存占用,让大模型能在普通设备上更快运行(如手机端部署的轻量化大模型)。
下图以MoE为例,展示了进阶架构的工作流程: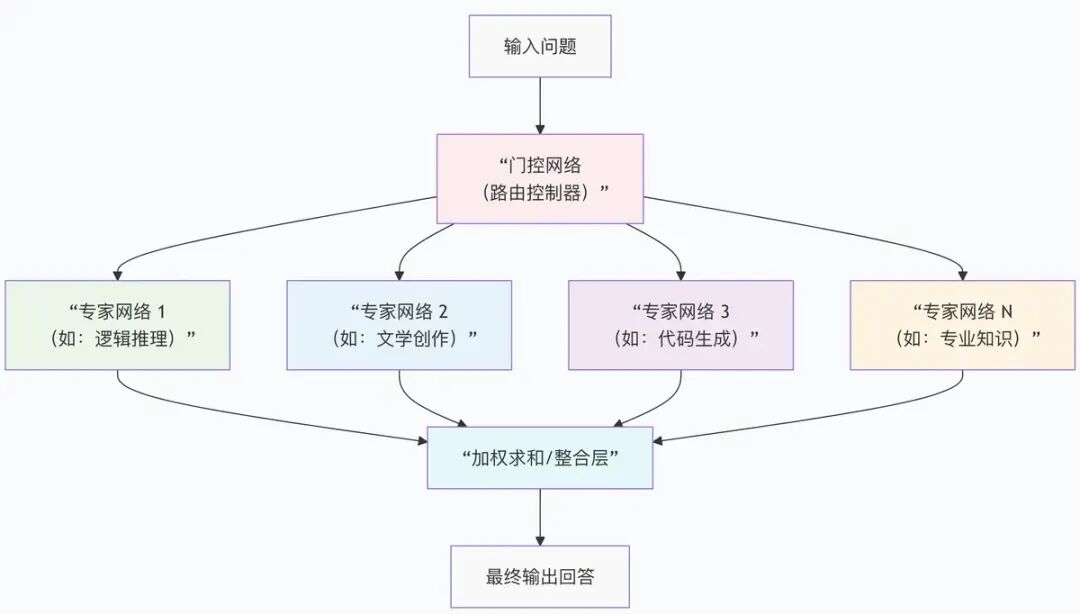
四、大模型架构的演进逻辑与趋势
从早期的BERT、GPT-1到现在的GPT-4、文心一言4.0,大模型架构的演进有清晰逻辑,未来主要有3个方向:
-
从密集到稀疏:越来越多模型采用MoE等稀疏架构,用"按需激活专家"的方式,在减少计算资源消耗的同时实现更强能力;
-
从通用到专用:在通用大模型基础上,针对医疗、法律、教育等行业做"领域微调"(如医疗大模型专注疾病诊断,法律大模型专注法条解读),让模型更懂行业知识;
-
多模态深度融合:文字、图片、视频、语音、3D模型等信息会深度整合,模型能像人一样"全方位感知世界"(如未来模型能看懂设计图并生成施工方案,或听懂需求并生成视频)。
五、一句话总结大模型架构
大模型的架构本质是"以Transformer为核心骨架,根据任务需求选择编码器/解码器组合,再通过MoE、多模态融合、稀疏激活等创新技术,实现高效的理解与生成"。
就像盖房子,Transformer是钢筋水泥框架,编码器/解码器是不同功能的房间,MoE等技术是智能家居系统------这些部分组合起来,才造就了我们现在看到的智能大模型。
下次再用ChatGPT写文案、用文心一言查资料时,你就知道它背后的"骨架"是怎么工作的了!如果想了解某类模型(如GPT-4的MoE细节)或某个技术(如多头注意力的计算逻辑)。