目录
[(三)Unicode 与 ISO/IEC 10646:全球字符的统一框架](#(三)Unicode 与 ISO/IEC 10646:全球字符的统一框架)
[(四)GBK:从国标到 Unicode 的过渡](#(四)GBK:从国标到 Unicode 的过渡)
[五、字频统计:从 "字符计数" 到 "语言理解"](#五、字频统计:从 “字符计数” 到 “语言理解”)
[1. 汉字输入:让输入更高效](#1. 汉字输入:让输入更高效)
[2. 汉字识别:校正单字的误差](#2. 汉字识别:校正单字的误差)
[3. 中文文本校对:检测别字与错误](#3. 中文文本校对:检测别字与错误)
[4. 词汇获取:识别未登录词](#4. 词汇获取:识别未登录词)
[六、结语:底层技术支撑中文 AI 的未来](#六、结语:底层技术支撑中文 AI 的未来)
一、引言
在计算机与人类语言交互的历史中,中文信息处理始终面临着独有的挑战:与西文 "字母 - 字节" 的简单映射不同,汉字作为表意文字,其数量庞大、结构复杂,从 "在机器中存储" 到 "被机器理解",都需要一套精密的底层规则作为支撑。字符编码 解决了 "汉字如何在计算机中表示" 的问题,而字频统计则回答了 "汉字如何被机器高效处理与理解" 的命题 ------ 这两者共同构成了中文信息处理的基石,支撑着从早期打字软件到现代大语言模型的所有中文应用。
二、从混乱到统一:西文字符编码的奠基
在计算机诞生之初,"如何用二进制表示字符" 是第一个需要解决的核心问题。早期的计算机厂商各自制定编码规则:IBM 的编码与 DEC 的编码无法互通,一台电脑输出的文本在另一台电脑上可能显示为乱码 ------ 这种 "编码巴别塔" 严重阻碍了信息交换。
1960 年代,美国国家标准局(ANSI)制定了美国标准信息交换码(ASCII) ,首次实现了西文字符的统一编码。ASCII 采用 7 位二进制表示字符,共包含 128 个字符:其中包括 10 个阿拉伯数字、52 个英文字母(大小写)、32 个标点符号与运算符,以及 34 个控制码(如换行符LF对应十进制 10、回车符CR对应 13)。
7 位 ASCII 的成功,让计算机之间的文本交换成为可能,但它的局限也很明显:仅能覆盖英文,无法表示其他语言的字符。于是,8 位 ASCII 应运而生 ------ 在 7 位的基础上增加 1 位高位,扩展出 256 个字符(2⁸=256),其中高位为 1 的字符(十进制 128~255)用于表示英文之外的符号(如法语的 "é"、德语的 "ö")。
但 8 位 ASCII 的扩展,依然无法解决中文的编码问题:汉字数量超过十万,仅常用字就有数千个,远非 256 个码位能容纳 ------ 这倒逼了中文特有的字符编码体系的诞生。
三、中文编码的演进:从国标到全球统一
汉字的 "多字符、表意性" 特征,决定了其编码必须采用多字节方案。从 1980 年代至今,中文编码经历了 "区域标准→过渡兼容→全球统一" 的三次迭代,每一次迭代都对应着中文信息处理场景的扩展。
(一)国标码(GB2312):中文编码的第一次统一
20 世纪 70 年代,中国开始研究汉字信息处理技术,但不同科研单位、厂商各自制定编码规则:有的用 2 字节表示汉字,有的用 3 字节,同一汉字在不同系统中可能对应不同的二进制数 ------ 一份北京的文档传到上海,打开后可能全是乱码。
1980 年,原中国国家标准总局发布GB2312-80《信息交换用汉字编码字符集 ------ 基本集》,首次实现了中文编码的全国统一:
- 编码方案:采用 2 字节表示一个汉字,每个字节的十进制范围为 161(A1)~254(F7),因此编码空间为 94×94=8836 个码位(94=254-161+1)。
- 字符分布:在 8836 个码位中,定义了 7445 个字符,包括 6763 个汉字(分 "一级常用字" 3755 个、"二级非常用字" 3008 个),以及标点、数字、日文假名、希腊字母等符号。
- 区位码:为了方便使用,GB2312 将编码空间划分为 "区"(行)和 "位"(列),每个汉字的 "区码 + 位码" 构成其区位码 ------ 例如 "爸" 对应的区码是 16、位码是 55,区位码为 1655。
GB2312 的诞生,让中文终于能在计算机中 "稳定存在":早期的中文打字机、DOS 系统的中文支持,都基于这一标准。但它的局限也很快显现:仅 6763 个汉字无法覆盖生僻字、人名(如 "镕")、古汉字,处理古代汉语文本时会出现大量 "□" 占位符。
(二)大五码(Big5):台湾地区的编码实践
几乎与 GB2312 同期,中国台湾地区也面临着编码混乱的问题:倚天、IBM、王安等厂商各自推出编码方案,不同电脑之间的中文文本无法互通。1984 年,台湾 "中央标准局" 发布《中文标准交换码》,业界通称大五码(Big5)。
Big5 的编码空间分为 "非汉字区""李改字区""汉字区",共包含 13053 个字符:其中常用字 5401 个、次常用字 7652 个,按笔画数和部首排序。它解决了台湾地区的中文编码统一问题,成为台港地区文本处理的主流标准 ------ 但由于与 GB2312 的编码规则完全不同,两岸三地的文本交换依然是 "乱码重灾区":一份内地的 GB2312 文档传到台湾,打开后会显示成无法识别的符号,反之亦然。
(三)Unicode 与 ISO/IEC 10646:全球字符的统一框架
随着全球化的推进,"不同地区编码不兼容" 的问题愈发突出:内地用 GB2312、台湾用 Big5、日本用 JIS、韩国用 KS------ 一份包含多语言的文档,在不同地区的电脑上会呈现完全不同的乱码。
1984 年,国际标准化组织(ISO)成立 ISO/IEC JTC1/SC2 委员会,推进 "多文种统一编码";1980 年代末,美国 HP、微软、IBM 等企业成立Unicode Consortium ,目标是制定一套覆盖全球所有字符的编码标准。1991 年,Unicode 1.0 发布;1993 年,ISO 发布ISO/IEC 10646《通用多八位编码字符集》(UCS),并与 Unicode 组织达成合作:两者共享同一套字符集,Unicode 是 ISO/IEC 10646 的实现方案。
Unicode 的核心设计是 "四维编码空间":
- 分为 128 个 "组(Group)",每组包含 256 个 "平面(Plane)";
- 每个平面包含 256 个 "行(Row)",每行包含 256 个 "码位(Cell)";
- 其中 "基本多文种平面(BMP,Group 0、Plane 0)" 是实际应用的核心,包含了中日韩统一表意文字(CJK Unified Ideographs)------ 这意味着内地的 "国"、台湾的 "國"、日本的 "国",在 Unicode 中对应同一个编码(U+56FD),彻底解决了跨地区汉字编码不统一的问题。
(四)GBK:从国标到 Unicode 的过渡
为了兼容 GB2312,同时支持 Unicode 的扩展字符,1995 年电子部与国家技术监督局联合发布GBK《汉字内码扩展规范》:
- 向下兼容:完全支持 GB2312 的所有字符,原有 GB2312 文档无需转换即可在 GBK 系统中打开;
- 向上扩展:编码空间扩展至 20982 个字符,新增了生僻字、古汉字,以及台湾 Big5 中的部分字符;
- 编码规则:第一字节范围为 129~254,第二字节范围为 64~127、129~254,覆盖了更多汉字的表示需求。
GBK 成为了 Windows 95 及之后版本的默认中文编码,解决了 GB2312 的生僻字痛点,同时实现了与 Unicode 的部分兼容,是中文编码从 "区域标准" 向 "全球统一" 过渡的关键一步。
(五)GB18030:现代中文的编码终极方案
2000 年,GB18030-2000 发布,2003 年取代 GBK 成为新的国家标准:
- 变长编码:支持单字节(兼容 ASCII)、双字节(兼容 GBK)、四字节三种编码方式,四字节部分对应 Unicode 的扩展平面,可表示超过 10 万个字符;
- 全面兼容:与 Unicode 一一对应,覆盖了所有常用字、生僻字、古汉字,甚至包括少数民族文字(如藏文、蒙文);
- 应用场景:满足了人名、地名、古籍数字化、学术研究等场景的需求 ------ 例如《康熙字典》中的生僻字,终于能在计算机中正常显示和存储。
四、字符编码的实践价值:中文文本处理的基础工具
字符编码不仅是 "存储汉字的规则",更是中文文本自动处理的 "前置工具"------ 通过编码规则,我们可以快速对字符进行分类、过滤、分析,为后续的自然语言处理任务铺路。
例如,在编程中,我们可以通过字符的 ASCII 码(或 Unicode 码)判断其类型:
python
def char_type(byte_data):
"""判断字符类型:0=西文字符,1=汉字,2=其他国标码字符"""
if len(byte_data) == 1:
# 单字节:西文字符(ASCII)
return 0
else:
# 双字节:取第一字节判断
first_byte = byte_data[0]
if first_byte >= 176:
# 汉字(GB2312/GBK)
return 1
else:
# 其他国标码字符(标点、符号)
return 2这个简单的函数,是中文分词、信息提取、文本校对等任务的基础:例如在自动分词前,我们需要先区分 "汉字" 与 "西文标点",避免将 "," 误判为汉字;在信息提取中,我们可以过滤掉 "其他国标码字符",只保留汉字和数字。
五、字频统计:从 "字符计数" 到 "语言理解"
如果说字符编码解决了 "汉字如何存在" 的问题,那么字频统计则解决了 "汉字如何被理解" 的问题 ------ 它通过统计汉字(及汉字组合)的出现频率,揭示了中文的语言规律,支撑着从汉字输入到智能对话的所有应用。
(一)字频统计的核心应用场景
字频统计的价值,体现在中文信息处理的每一个环节:
1. 汉字输入:让输入更高效
字频是输入法设计的核心依据:频度高的字,输入码更短、排序更靠前,减少用户的击键次数与重码选择。
- 例如拼音输入法中,"的" 是中文中出现频率最高的字(占比约 5%),输入 "de" 时会直接排在第一位;
- 五笔输入法中,高频字 "一""是""在" 采用 "一级简码",仅需 1 个键即可输入。
这种 "高频字优先" 的设计,让中文输入效率提升了 30% 以上 ------ 早期的输入法正是因为忽略了字频,导致用户需要频繁翻页选择,体验极差。
2. 汉字识别:校正单字的误差
印刷体汉字识别(OCR)的难点在于:单字的字形可能因模糊、变形而被误判,但结合字频与上下文,可以大幅提升准确率。
- 例如,OCR 识别出 "于 X",其中 "X" 的字形既像 "由" 又像 "甲",但 "由于" 是高频搭配(双字频远高于 "于甲"),因此可以确定 "X" 是 "由";
- 早期 OCR 软件的识别准确率仅为 70% 左右,引入字频与上下文后,准确率提升至 95% 以上。
3. 中文文本校对:检测别字与错误
文本中的别字,往往是 "字形 / 字音相似 + 高频搭配缺失" 的结果 ------ 字频统计可以快速定位这些错误:
- 例如文档中出现 "罗期边防部队","罗期" 的双字频极低,而 "罗斯" 是高频搭配,且 "期" 与 "斯" 字形相似,因此可以判断 "期" 是别字;
- 现代文本校对系统中,"字频 + 搭配频度" 是检测别字的核心算法之一,能覆盖 80% 以上的常见错误。
4. 词汇获取:识别未登录词
自动分词的最大痛点是 "未登录词"------ 即词表中没有的新词(如 "内卷""躺平")、专有名词(如 "谷爱凌")。通过双字频统计,可以快速识别这些词:
- 例如 "内卷" 在早期词表中不存在,但在社交媒体文本中,"内" 与 "卷" 的双字频极高,且无法拆分为现有词,因此可以判定为新词;
- 陈小荷等学者曾对 90 个现代汉语文本进行统计,发现 1500 个未登录词中,有 1000 个可以通过双字频统计识别 ------ 这是现代新词提取的核心方法之一。
(二)单字字频统计:高效的数组存储策略
单字字频统计的核心是 "快速记录每个汉字的出现次数",直接遍历字表查找会导致效率极低 ------ 利用汉字的编码规则,可以将汉字映射为数组下标,实现 O (1) 的访问效率。
以 GB2312 为例,汉字的第一字节范围是 176~247,第二字节范围是 161~254,因此可以通过公式计算数组下标:
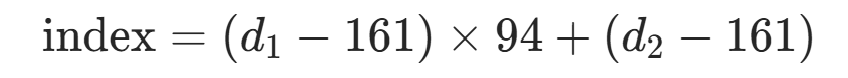
其中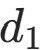 是第一字节的十进制值,
是第一字节的十进制值,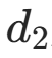 是第二字节的十进制值。
是第二字节的十进制值。
例如 "啊" 的=176、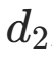 =161,对应的下标是(176−161)×94+(161−161)=1410------ 我们可以创建一个大小为 8836 的数组,将 "啊" 的频度直接存储在索引 1410 的位置,无需遍历查找。
=161,对应的下标是(176−161)×94+(161−161)=1410------ 我们可以创建一个大小为 8836 的数组,将 "啊" 的频度直接存储在索引 1410 的位置,无需遍历查找。
(三)双字字频统计:计算语言的条件概率
双字字频统计的核心是计算 "条件概率"------ 即已知前一个字的情况下,后一个字出现的概率:

例如 "中" 的单字频度是 1000,"中国" 的双字频度是 500,则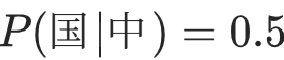 ------ 这意味着 "中" 后面跟着 "国" 的概率是 50%。
------ 这意味着 "中" 后面跟着 "国" 的概率是 50%。
这种条件概率,是 n-gram 语言模型的基础 ------ 现代大语言模型(如 GPT)的底层逻辑,本质上是基于更复杂的 "上下文 - 下一个词" 的概率计算,而双字字频统计正是这一逻辑的雏形。
六、结语:底层技术支撑中文 AI 的未来
从 GB2312 的 6763 个汉字,到 GB18030 的十万字符;从单字字频的数组存储,到双字字频的条件概率 ------ 字符编码与字频统计,看似是 "基础到枯燥" 的技术,却支撑着中文信息处理的每一次进步。
今天,当我们用拼音输入法快速打字、用 OCR 识别古籍、用大语言模型生成中文文本时,背后都是字符编码的统一规则与字频统计的语言规律在发挥作用。它们是中文从 "纸质文字" 走向 "数字语言" 的桥梁,也是中文 AI 从 "能处理" 到 "能理解" 的底层逻辑 ------ 未来,随着古籍数字化、多语言交互的需求增加,这些底层技术将继续演进,支撑中文在数字世界中绽放更强大的生命力。
七、总结
本文围绕 "字符编码与字频统计是中文信息处理的底层基石" 展开,核心内容如下:
- 西文字符编码的奠基:早期厂商编码混乱,ASCII 码实现西文统一,但 8 位扩展仍无法覆盖汉字,倒逼中文编码体系诞生。
- 中文编码的演进:从 GB2312 首次统一内地编码(但字符量有限),到 Big5 解决台港编码(与内地不兼容),再到 Unicode/ISO10646 实现全球字符统一;中间 GBK 作为过渡兼容方案,最终 GB18030 以变长编码覆盖超 10 万字符,成为现代中文编码的终极方案。
- 字符编码的实践价值:可通过编码规则快速分类字符,是中文分词、信息提取等 NLP 任务的前置工具。
- 字频统计的作用与方法:其支撑了汉字输入(高频字优化效率)、OCR 识别(校正字形误差)、文本校对(检测别字)、词汇获取(识别未登录词);技术上,单字通过编码映射数组实现高效存储,双字统计则计算条件概率,是 n-gram 等语言模型的雏形。
本文最后指出,这两项底层技术是中文从纸质文字转向数字语言的桥梁,将持续支撑中文 AI 的发展。