摘要: 在大模型(LLM)引爆的 AI 时代,数据已不再仅仅是石油,它是氧气。然而,面对日益复杂的反爬技术、动态网页架构以及指数级增长的数据需求,传统的"手写规则+代理池"模式正面临前所未有的工程危机。本文将从企业级视角出发,解构当前数据采集的"不可能三角",并揭示为何 Prompt-Driven(提示词驱动) 的自动化采集架构,将是打破这一僵局的唯一解。
引言:为何现在需要"prompt 生成爬虫"?
过去三年,企业普遍向"数据驱动"转型:AI团队需要构建领域知识库,SEO/AEO团队需要监测竞争内容,风控部门依赖跨站点数据识别风险。无论需求来自哪个方向,本质相同------企业对外部可结构化数据的依赖已全面进入规模化阶段。
然而现实却是:数据采集仍依赖工程师维护脆弱的脚本。新增站点意味着重新搭建逻辑,反爬升级意味着深夜调试代理,页面变化则需要重写选择器。业务侧期望"实时、全面、持续增长"的数据,技术侧却困在"不可预测、不可扩展、难维护"的脚本泥沼里。这背后是结构性矛盾:企业数据需求指数级增长,但传统爬虫方式的可扩展性存在天然上限。只要采集任务仍以"工程师逐行编码"为主要模式,就无法适应高频变化的网页结构,也无法支撑多站点、大规模、低延迟的数据生产需求。
"Prompt 生成爬虫"正是对这种矛盾的系统性回应。它让采集任务回到"业务描述"层面,让AI理解页面、推断结构、生成脚本,并在结构变化时自动重写逻辑。对企业而言,这意味着从"人力驱动的脚本时代"迈向"AI驱动的数据基础设施时代"------业务需求更快落地,技术团队从无休止的脚本维护中解放,把能力投入到更高价值的模型、产品和策略中。
产品一览:什么是 Bright Data AI Scraper Studio?
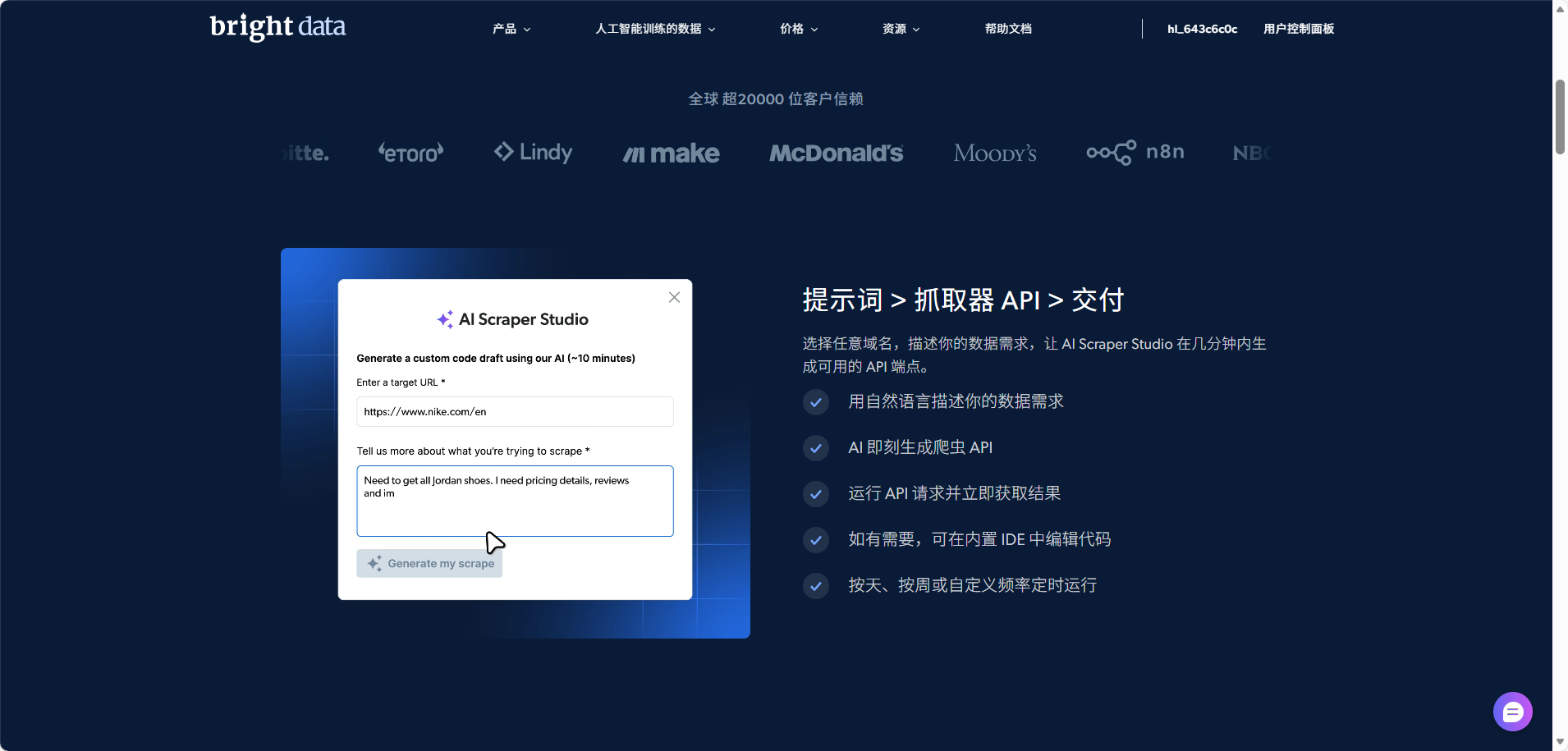
在数以万计的抓取工具中,Bright Data AI Scraper Studio 之所以引起行业高度关注,源于它抓住了企业在数据采集上的核心矛盾:传统爬虫无法规模化,而企业的数据需求正在快速扩大。AI Scraper Studio 的定位非常清晰------它是一套"由 AI 驱动的企业级爬虫生成与管理系统",允许用户用简单的自然语言 prompt 生成可运行的爬虫脚本,并自动形成 API、调度、代理配置、数据导出与维护能力。
如果要用一句话概括 AI Scraper Studio 的价值主张,就是:
"让任何人都能在几分钟内构建可扩展、可维护、可自愈的生产级爬虫。"
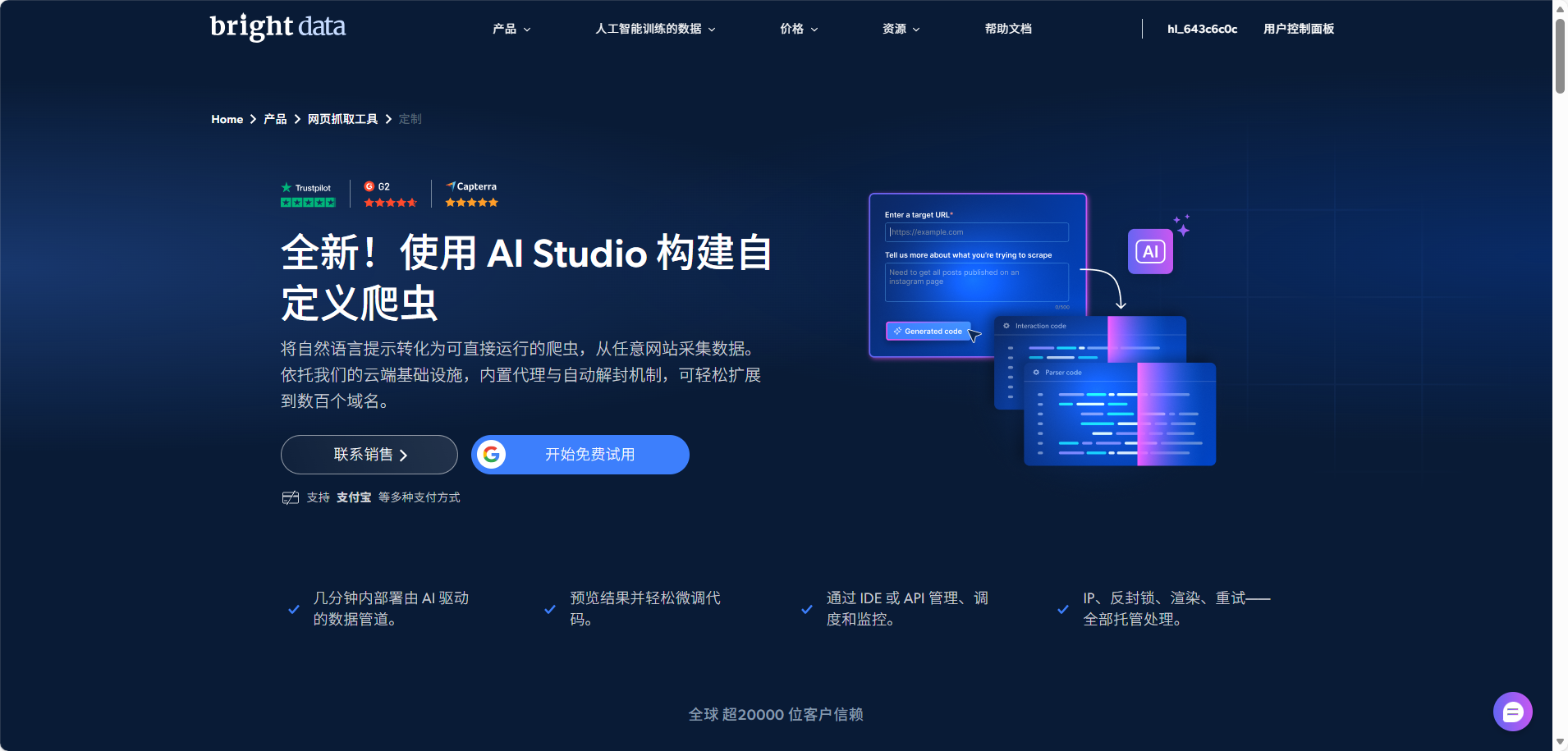
与以往的工具不同,AI Scraper Studio 是一个完整的链路系统,而不是一个辅助脚本生成工具。它从 prompt 开始,通过 AI 解析网页结构,生成爬虫脚本,并可直接通过 API 对外提供数据服务。在这个过程中,它能自动处理翻页、详情页跳转、字段抽取、异常重试、代理切换、反封锁机制,并在网站变化时提供一键自愈(Regenerate)能力。
更重要的是,它不仅面向工程师,也面向业务团队。技术人员可以通过 IDE 模式微调脚本、加入复杂逻辑,而业务团队只需要描述需求即可获得可用的数据结构。这种"AI + 人类协作"的方式极大提高了开发效率,让团队的时间真正投入到高价值工作上,而不是重复修复脚本。
AI Scraper Studio 的典型用户包括技术团队、AI 平台团队、SEO/AEO 团队、电商监控团队、业务情报团队以及数据服务商。对他们来说,数据采集是业务的基础,但他们同样不希望在脚本维护上浪费工程能力。因此,一个能够以分钟级速度上线,具备企业级扩展性且能自动自愈的系统,正好满足了当下最核心的需求。
亮点拆解:AI Scraper Studio 的五大核心能力
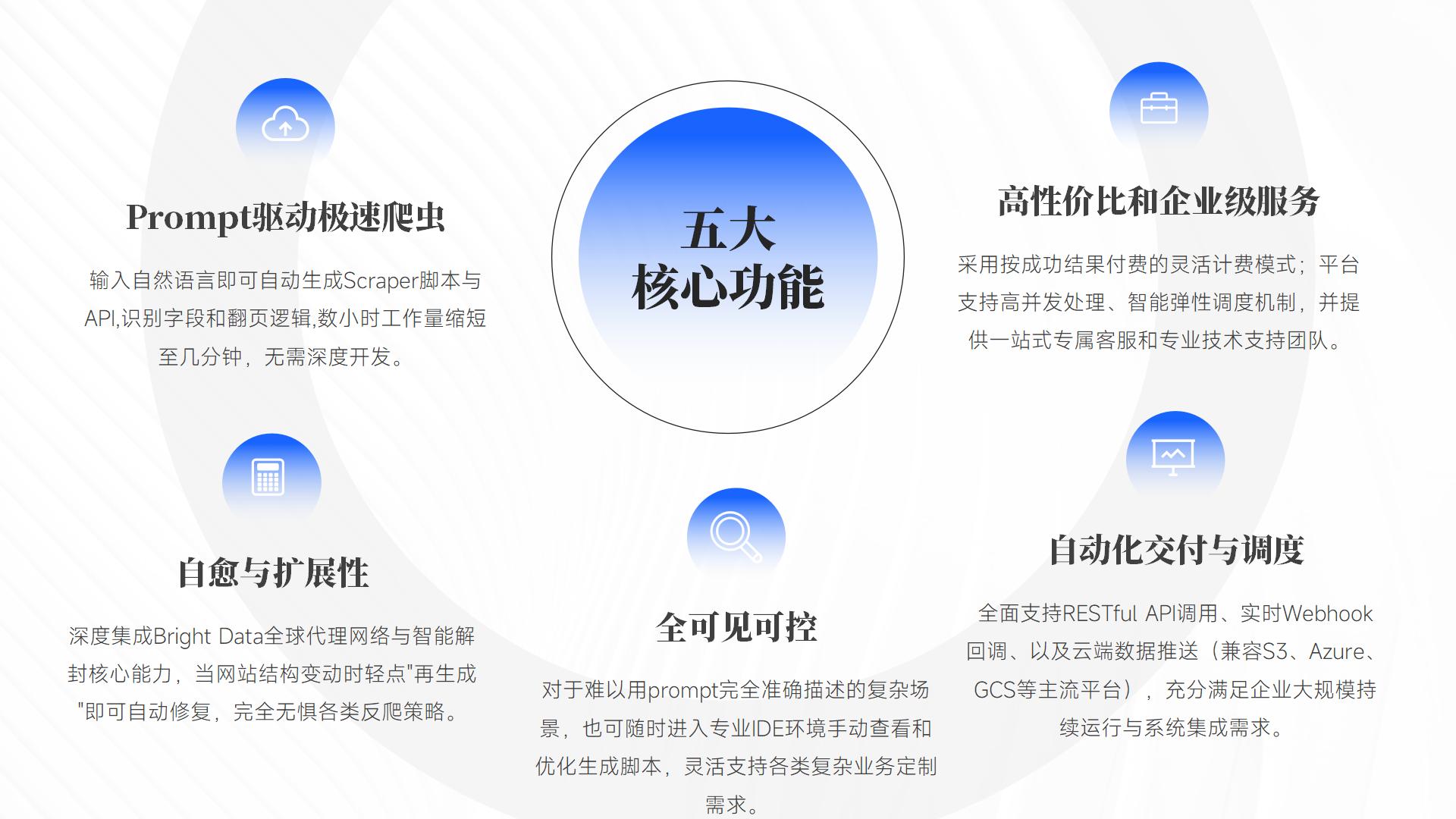
Prompt 驱动:从自然语言到可运行爬虫
AI Scraper Studio 的第一项亮点就是 Prompt 驱动开发,它让网页抓取变成了自然语言描述的任务。例如,当用户输入"抓取某网站所有产品的名称、价格、评价并抓取详情页评论"时,AI 能自动推断页面结构、生成爬虫脚本、识别字段,并自动处理分页与跳转逻辑。这种方式将开发过程中的大量机械劳动交给 AI 执行,让用户专注于业务需求本身。
它的核心价值在于极大缩短开发周期:传统脚本需要数小时或数天,而 Prompt 驱动方式通常只需几分钟。在实际测试中,一个复杂网站的采集任务,我用 Studio 只用5分钟就建立起来,而用传统方式至少需要半天。
Self-Healing 自愈能力:结构变化一键恢复
网页结构频繁变化是企业数据采集最大的痛点。当 DOM 结构调整、class 名变动、渲染方式更换时,传统脚本立刻报错,需要工程师逐行排查。而 AI Scraper Studio 的自愈能力让这一过程变得几乎"自动化"。系统在识别到结构发生变化时,会提示用户是否希望重新生成脚本。用户点击 Regenerate 后,AI 会重新分析页面结构并更新逻辑。
例如,我曾监测一个内容网站,半夜突然结构变化导致解析失败,但 AI Scraper Studio 在自动检测后提供立即恢复建议,几分钟内脚本就重建完成。这让过去费时费力的维护过程变成了"点一下就完成"的简单操作。
全可见与可控:自动生成但不黑箱
尽管是 AI 驱动,但 AI Scraper Studio 并非黑箱系统。所有生成的脚本都可在 IDE 中查看、编辑与调试,用户可以加入特殊逻辑、手动优化选择器、添加 JS 执行、模拟用户行为等。这让企业可以放心采用 AI 工具,因为在自动化的同时仍然保留了充分的工程控制能力。
这种透明性不仅让工程师能够自由调优,也让复杂场景得以落地,例如桌面行为模拟、动态弹窗处理、分步骤逻辑等。
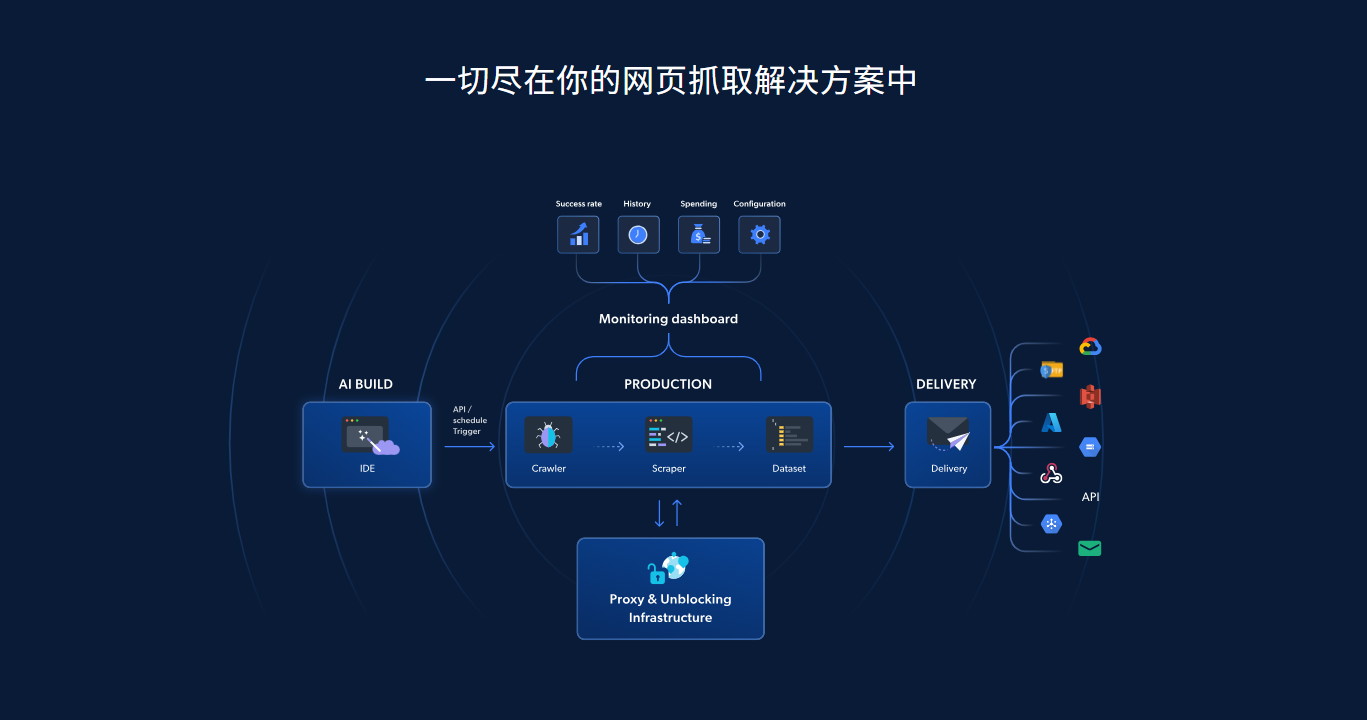
自动化交付:从脚本到 API 的企业级标准流程
传统爬虫往往只能生成结果,但难以快速形成可供系统调用的数据接口。而 AI Scraper Studio 会自动为每个任务生成可调用的 API 端点,支持定时运行、Webhook 推送、云存储导出(S3/GCS/Azure),并能输出 JSON、CSV、XLSX 等格式,让采集任务能够无缝接入数据仓库与分析系统。
这种"脚本即 API"的方式让数据采集真正具备了企业级的可交付性。而在大规模业务场景中,这种能力的重要性会更加凸显。
企业级服务:代理、调度、稳定性一站式整合
在许多行业案例中,反爬、代理被封、访问频率限制、验证码等问题是最耗费工程时间的内容。AI Scraper Studio 背后整合了 Bright Data 的全球代理网络、浏览器模拟、行为模式与解封能力,让反爬问题变成"默认可解决"的基础能力。
在我自己的体验中,当我故意放大抓取频率触发封锁时,AI Scraper Studio 自动切换代理并恢复任务,使失败率从近 50% 降到 3%--5% 的可接受范围,而且这些失败抓取也是不收费的。对于任何需要大规模抓取的企业来说,这种稳定性本身就具有极高价值。
三分钟从 Prompt 到企业级竞品价格监控爬虫上线
想快速体验 AI Scraper Studio 的能力,最简单的方式就是实际跑一次 Demo。整个过程从注册到拿到数据,全程不超过几分钟。
用户进入 Scraper Studio 后,只需输入目标 URL,并写下一个简单的 prompt,例如:"抓取该站点所有产品名称、图片、价格与评分"。AI 会在几秒钟内生成脚本,并输出结构化预览数据。
执行任务后,你可以直接在界面中看到抓取结果,也可以导出为 JSON/CSV/XLSX。更重要的是,你还可以立即通过自动生成的 API 端点调用数据,这意味着刚创建的爬虫已经具备生产可用性。
环境准备与账号配置
- 注册 Bright Data 账号并进入 AI Scraper Studio 免费试用 打开 Bright Data 官网,点击试用进行创建账号
填写邮箱手机号即可快速完成注册
完成后即可进入亮数据控制台页面,按照如下步骤即可进入 AI Scraper Studio。该模块内置若干免费额度,无需配置代理或环境,也无需提前准备任何代码,适合快速验证抓取需求。
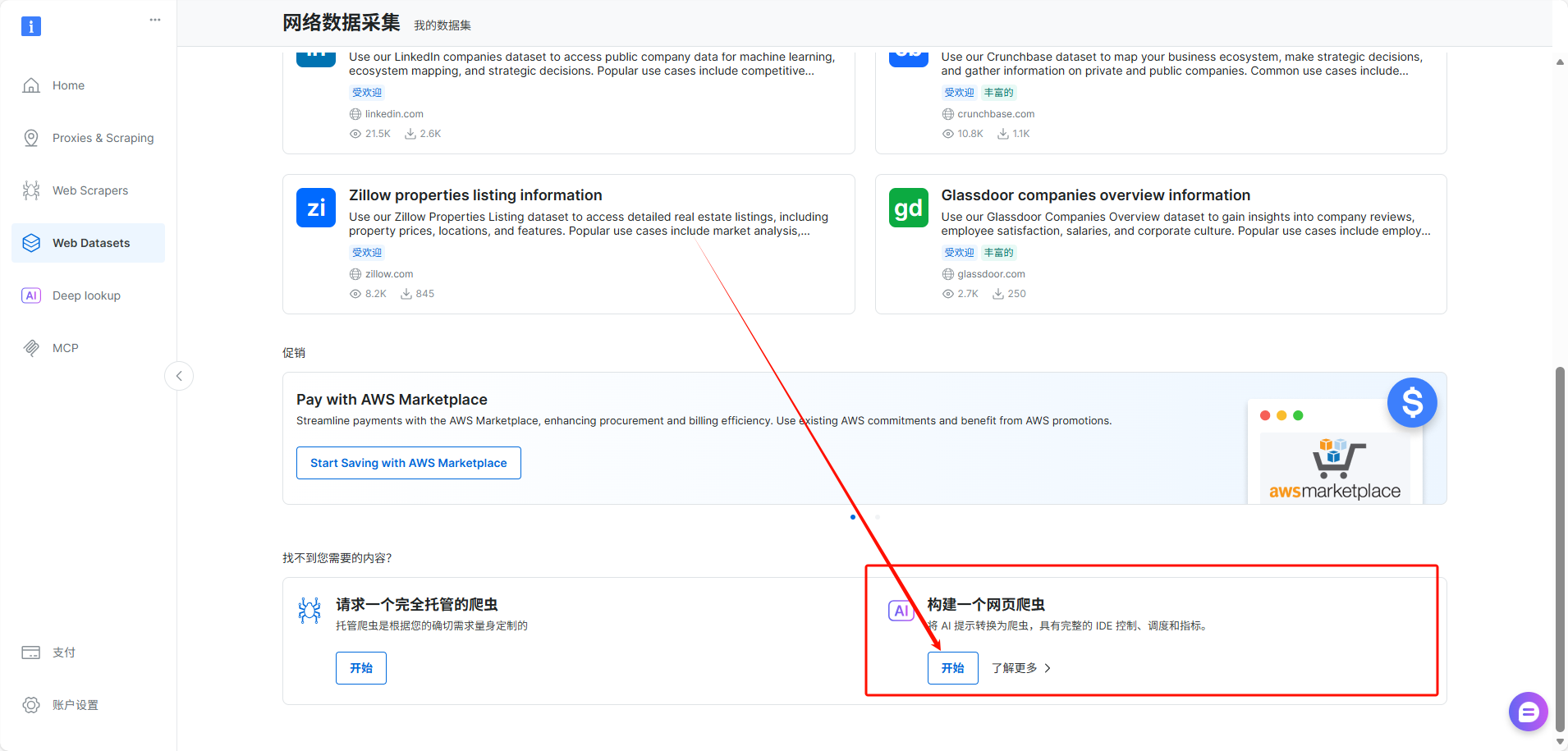
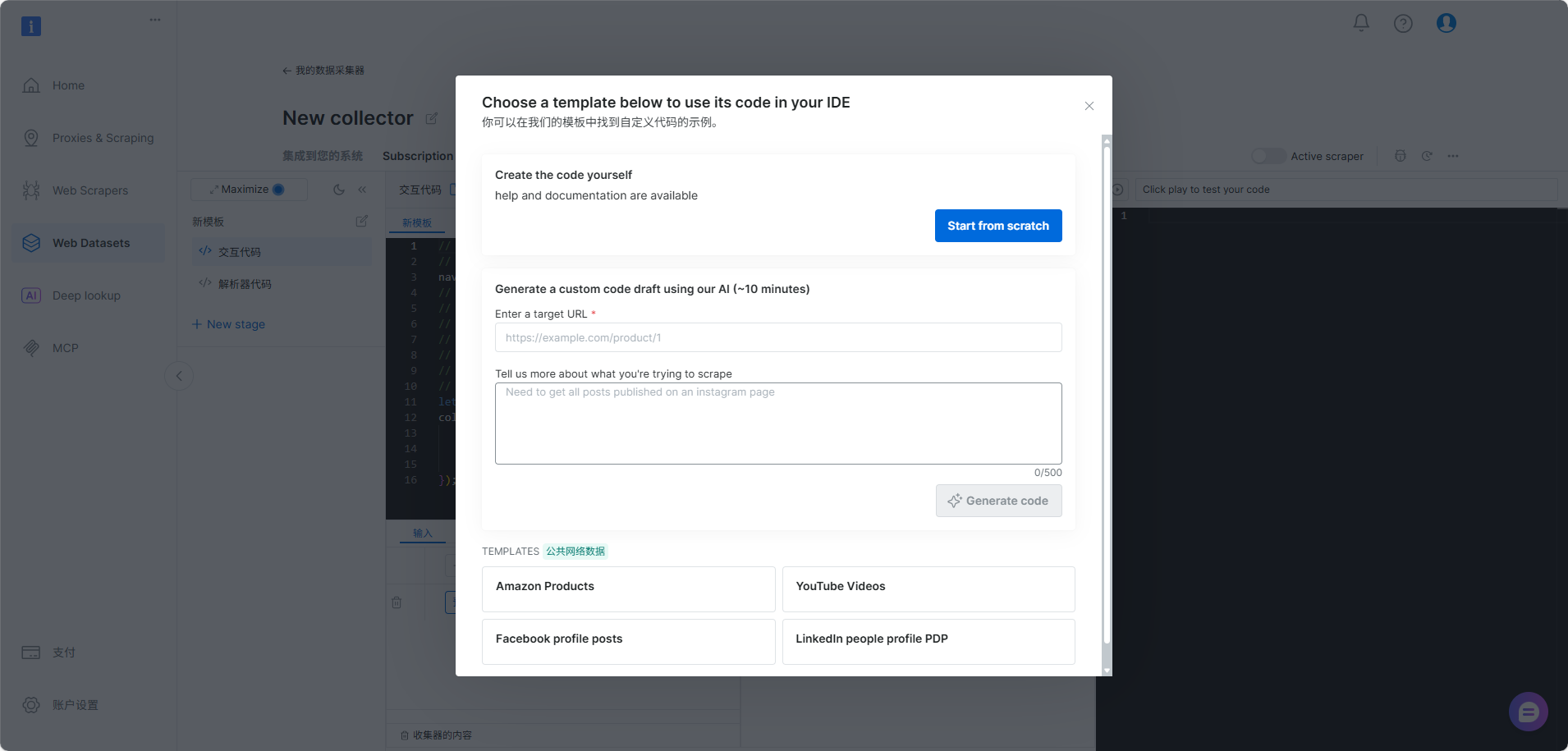
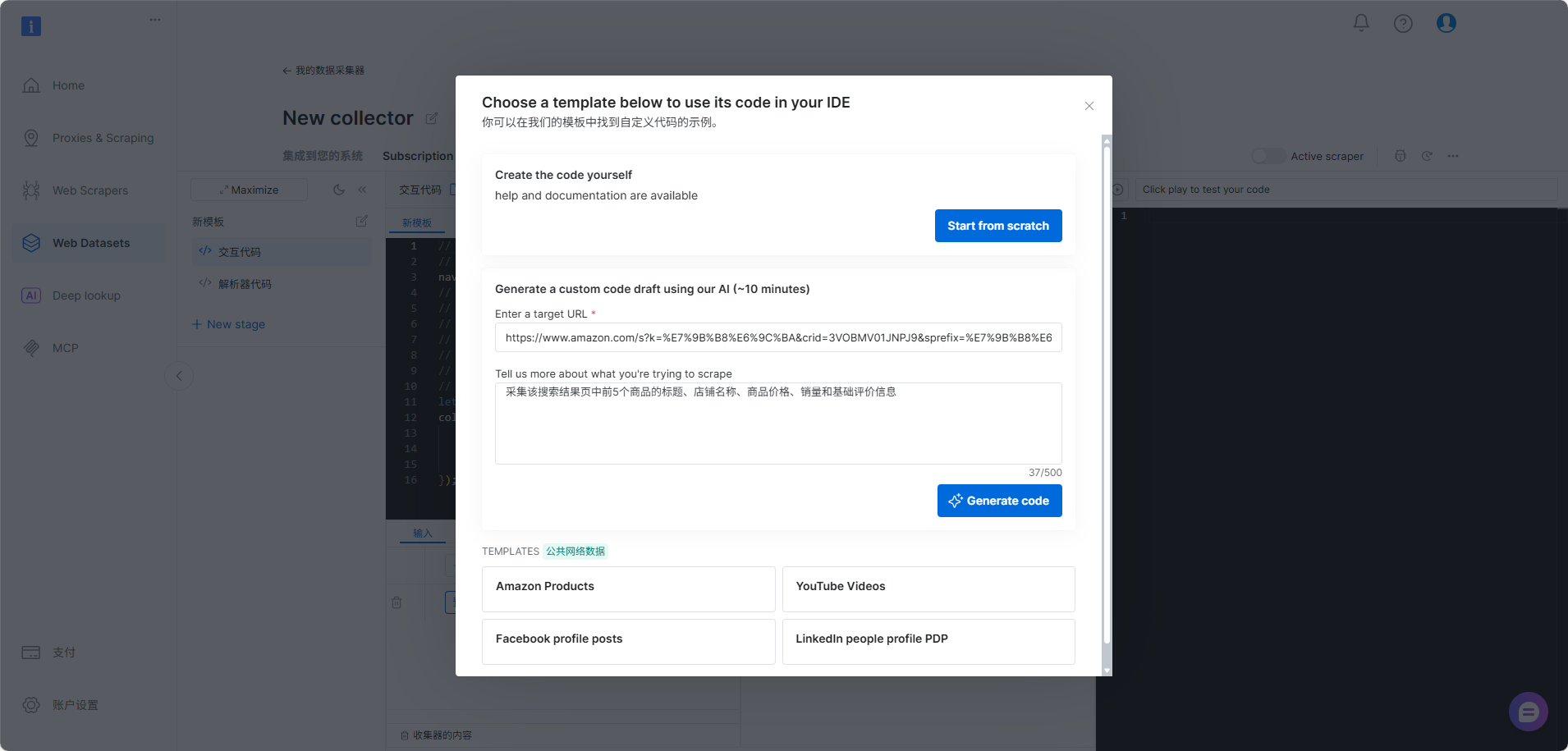
- 输入目标网站URL及抓取目标的自然语言prompt(如"采集该搜索结果页中所有商品的标题、店铺名称、商品价格、销量和基础评价信息),这里我以某电商网站上面的相机为例,帮助企业快速进行竞品信息抓取:
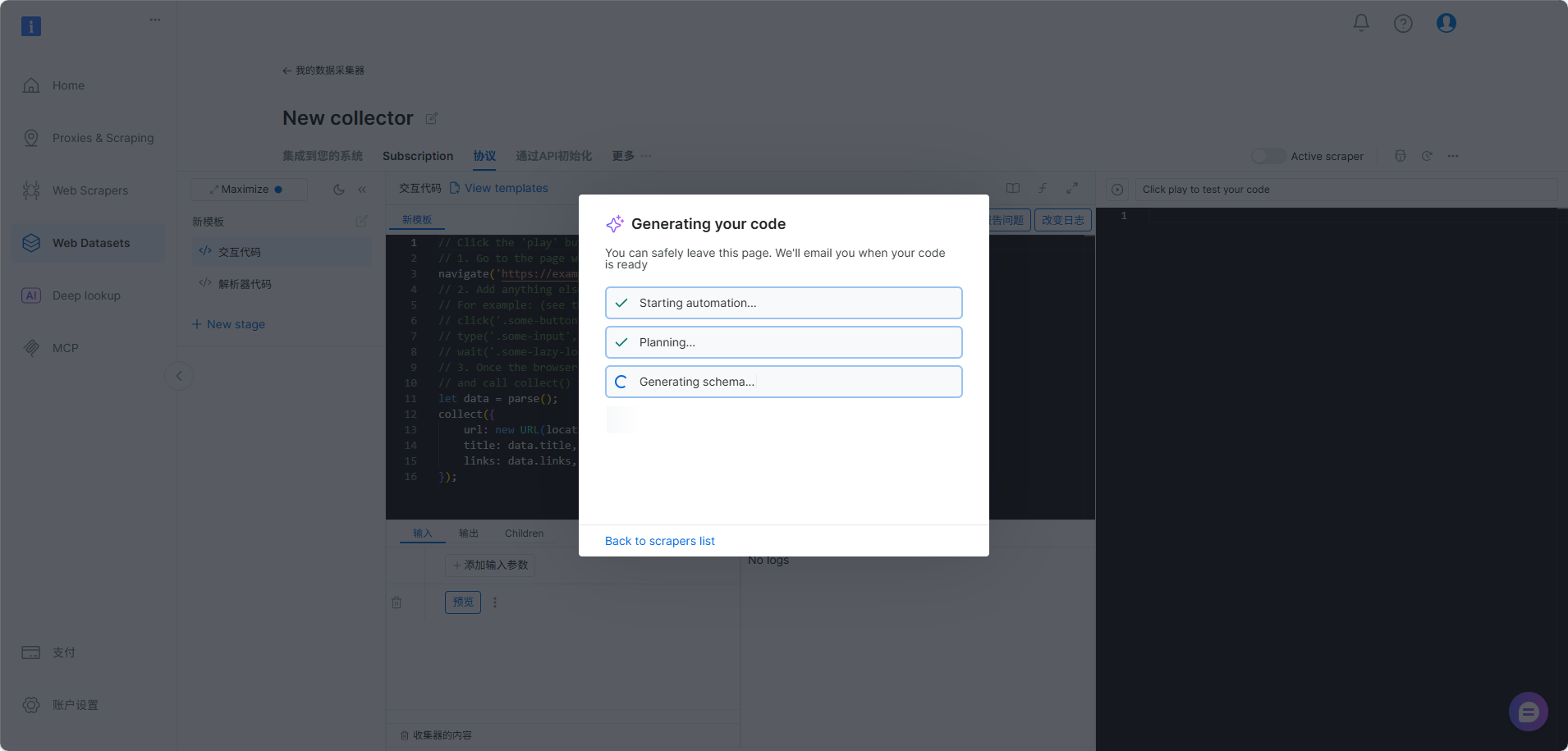
- Studio 自动生成并部署可运行的爬虫代码 提交 Prompt 后,AI Scraper Studio 会自动读取网页结构、生成相应的抓取逻辑,并直接部署到云端运行。整个过程不需要你编写 Python、Node.js 或 Puppeteer 程序,也不需手动处理分页、详情页跳转或等待动态加载。
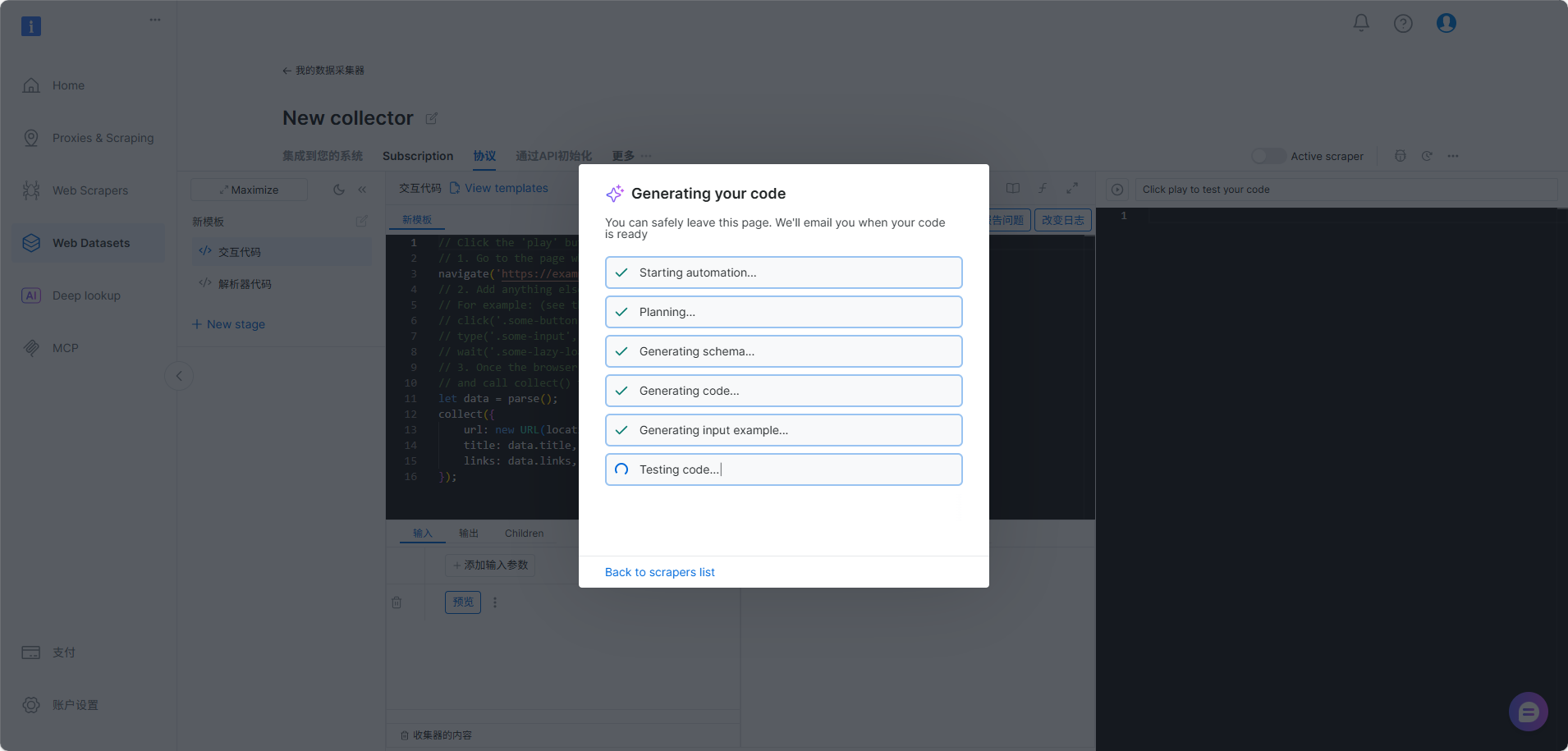
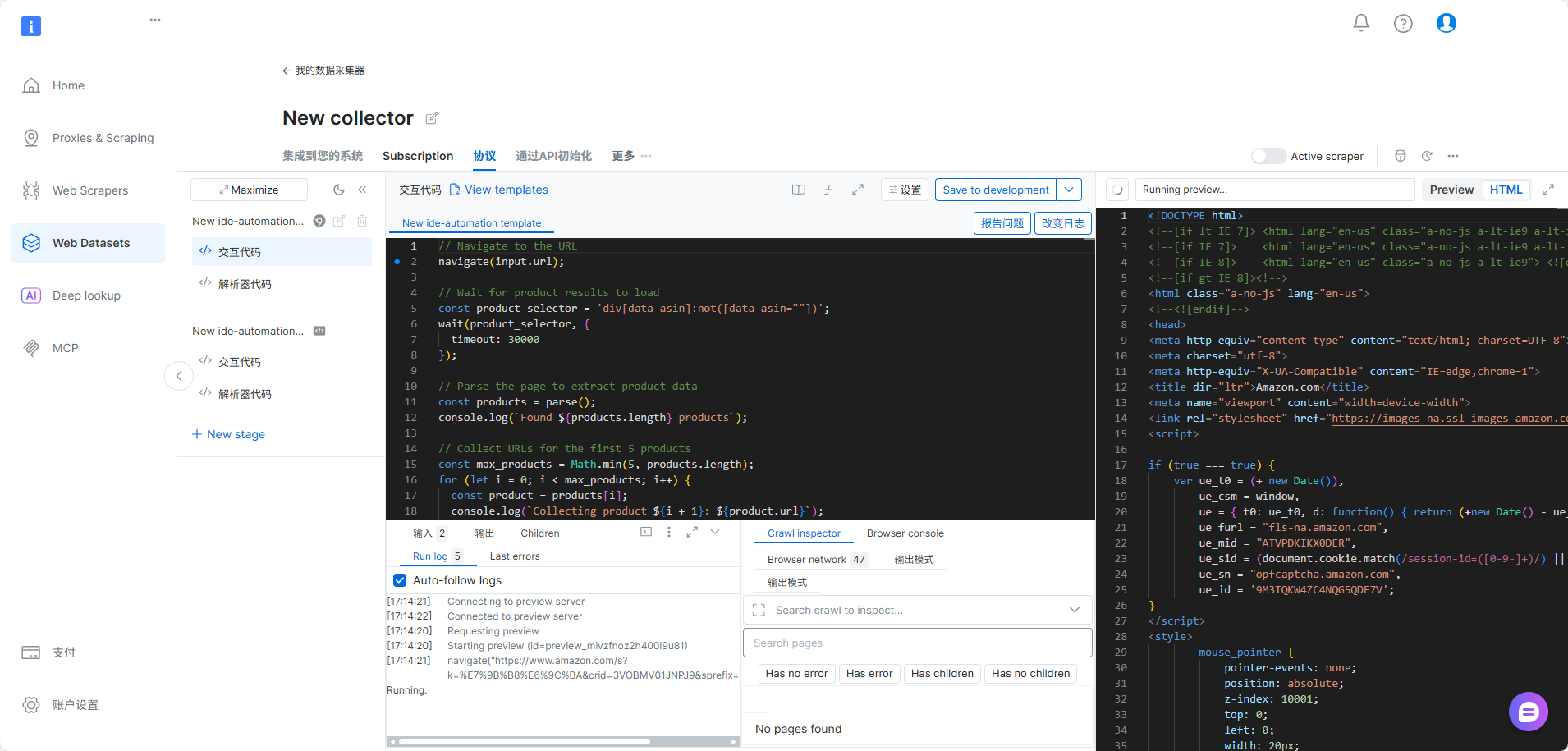
- 通过 API、Webhook 或云存储自动获得结构化数据输出 爬虫成功运行后,所有结果会自动转换成结构化数据,可选择 JSON、CSV、XLSX 等格式。你可以通过 REST API 拉取数据,也可设置 Webhook 或直接将文件同步到云端(S3、GDrive、Azure 等),方便与企业内部 BI 系统或数据仓库对接。
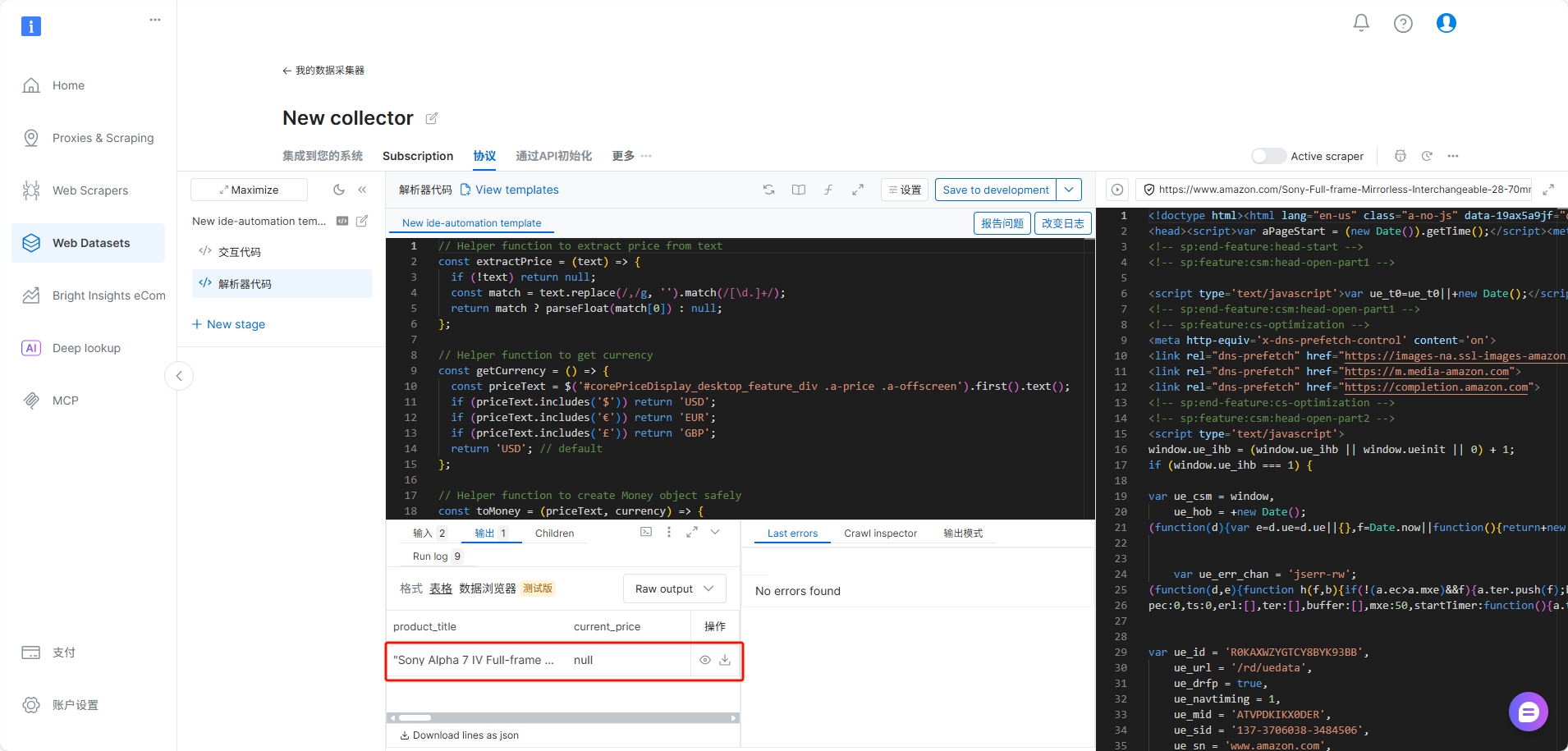
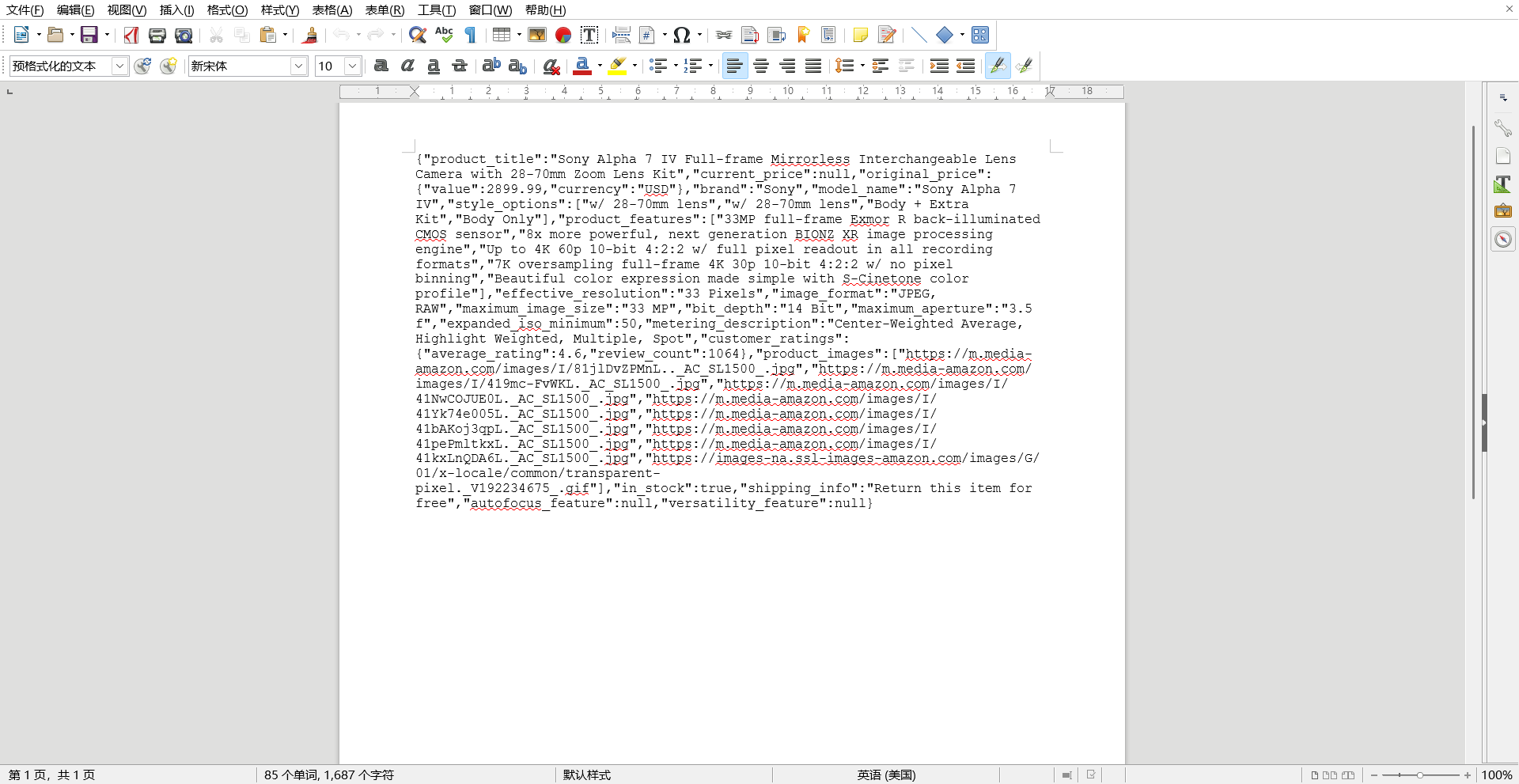
- 当网站反爬或结构变动时,一键 Regenerate 自动完成修复 如果目标站点更新布局或添加反爬机制,传统爬虫往往需要工程师重新编码,而在 AI Scraper Studio 中,你只需点击"一键 Regenerate",系统会重新分析网页并自动修复爬虫逻辑,大幅降低维护成本。
与传统方案对比:如何选择合适的数据采集方案?
企业在构建数据采集能力时,常面临技术投入与业务灵活性的权衡。Bright Data提供三类互补的解决方案:Web Scraper API、Web Scraper IDE自定义开发、以及全新的AI Scraper Studio,分别满足从标准化到高度定制的不同企业需求。
1. Web Scraper API - 标准化场景的快速方案
专用端点,可从 120 多个热门域名提取最新、结构化的网页数据,100% 合规且符合道德规范。
适合人群
适合需要快速获取标准化数据、技术团队有限或无开发资源的企业。典型场景包括电商价格监控、SERP数据分析、社交媒体内容采集等主流平台数据获取。
核心优势
- 零技术门槛:无需编写任何代码,仅通过API调用即可获取结构化数据,非技术团队也能快速上手
- 即开即用:支持Amazon、LinkedIn、Google等数百个主流网站的预构建爬虫,几分钟内即可完成集成上线
- 零运维负担:由Bright Data全程维护脚本更新、反爬应对和基础设施,企业无需投入运维资源
- 灵活计费:采用按成功结果付费模式,失败请求不计费,成本可控且透明
- 高并发支持:原生支持批量请求和大规模数据拉取,适合需要持续监控的业务场景
使用局限
- 覆盖范围受限:仅支持预设的通用网站模板,无法扩展到自定义或小众站点
- 字段固定:数据输出格式和字段由API预定义,无法根据特殊业务需求调整
- 逻辑不可控:抓取流程、分页逻辑、异常处理等均为黑箱,企业无法介入优化
典型应用场景:竞品价格监控系统、市场趋势分析平台、社交媒体舆情监测等标准化数据需求。
2. Web Scraper IDE(Functions) - 深度定制的专业工具
完全托管的 JavaScript 爬虫解决方案,专为开发者设计,可快速、大规模构建爬虫。基于 Bright Data 的解封技术构建,IDE 包含来自主要网站的预置 JavaScript 函数和代码模板,大幅减少爬虫开发和维护时间。
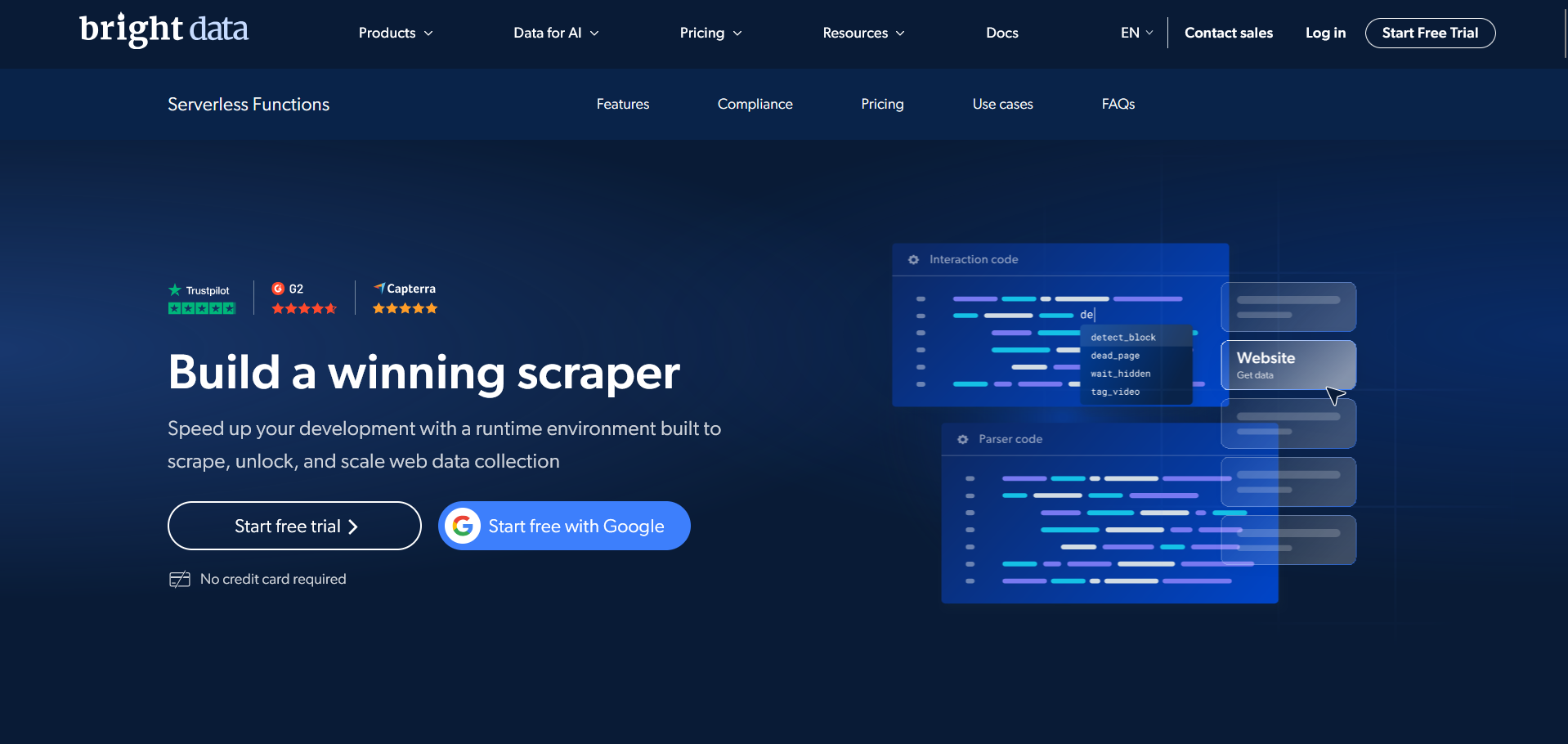
适合人群
适合拥有专业技术团队、需要高度定制化抓取逻辑的企业。适用于复杂业务场景,如多步骤交互、动态表单提交、特殊反爬绕过等需要精细控制的任务。
核心优势
- 无限扩展性:理论上可采集任意网站的任意数据,不受预设模板限制,完全自主定义目标站点和字段
- 代码级深度控制:基于JavaScript开发环境,支持自定义选择器、模拟用户行为、执行复杂业务逻辑
- 基础设施复用:可直接调用Bright Data的全球代理网络、智能解封服务、浏览器模拟和分布式调度能力,无需自建反爬基础设施
- 灵活集成:支持与企业内部系统深度集成,可实现复杂的数据处理流程和业务编排
- 版本管理:代码可纳入企业Git工作流,支持团队协作、测试和持续迭代
使用局限
- 开发门槛高:需要工程师具备JavaScript编程能力和网页结构分析经验,技术要求较高
- 运维成本大:网站结构变动、反爬策略升级等需要人工持续维护脚本,长期运维压力显著
- 扩展成本高:每新增一个目标网站都需要重新开发和测试,在多站点场景下开发周期较长
- 资源依赖强:依赖专业工程师的持续投入,人员流动可能带来知识断层风险
典型应用场景:复杂金融数据采集、需要多步骤登录认证的内部系统、高度定制化的行业垂直数据获取。
3. AI Scraper Studio - AI驱动的智能中台(强烈推荐!)
将自然语言提示转化为可直接运行的爬虫,从任意网站采集数据。依托我们的云端基础设施,内置代理与自动解封机制,可轻松扩展到数百个域名。
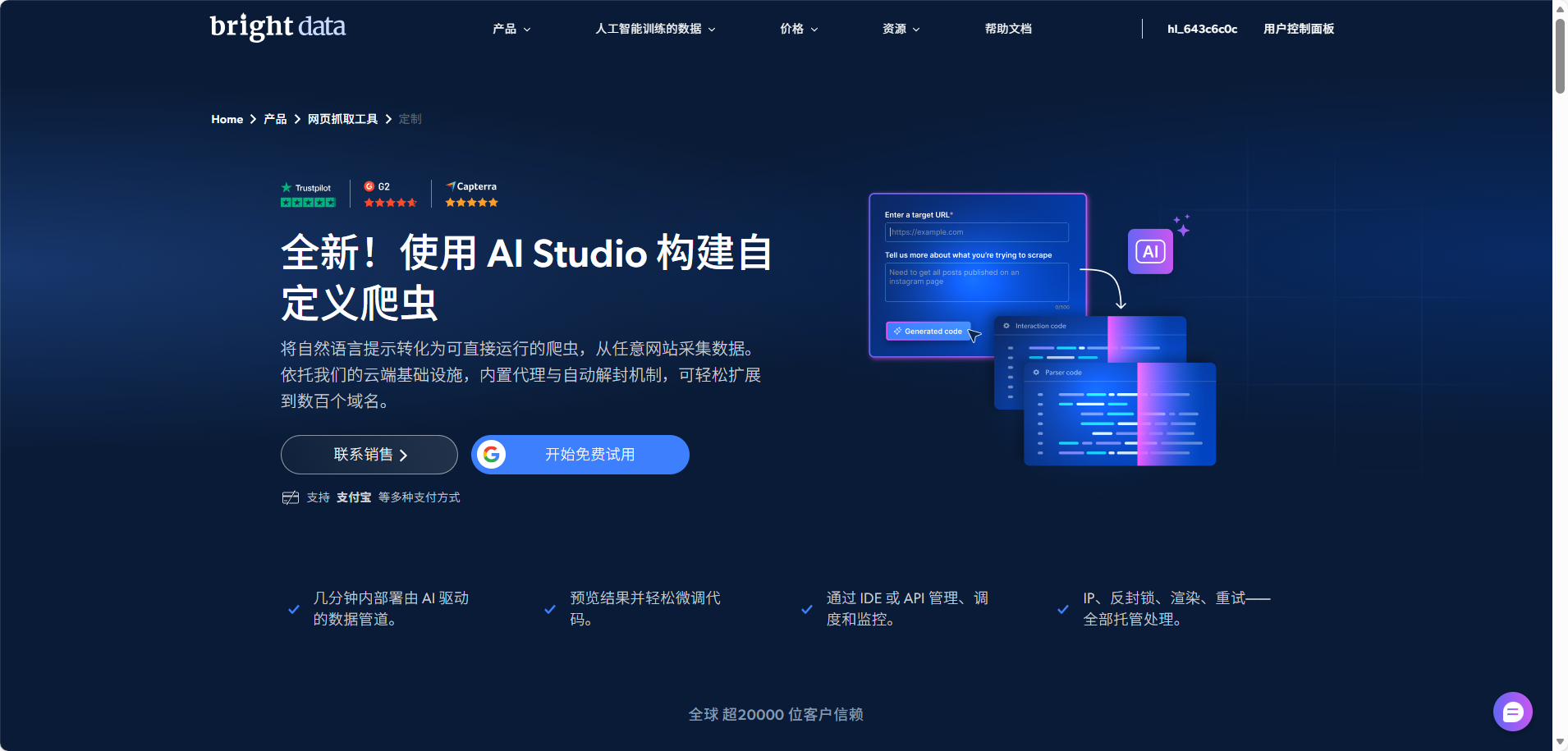
适合人群
适合需要快速覆盖大量网站、技术团队有限但业务扩展快速的成长型企业和数据驱动型组织。特别适合需要同时兼顾开发效率和灵活性的场景。
核心优势
AI Scraper Studio将API的"零代码快速上线"与IDE的"灵活可控"完美结合,通过AI能力重新定义企业数据采集方式:
- 自然语言开发:仅需用简单的中文或英文描述采集需求(如"抓取该网站所有产品的标题、价格和评论"),AI在10-15分钟内自动生成可运行的爬虫脚本
- 快速规模化:相比传统开发方式需数小时甚至数天,AI驱动模式让新站点上线时间缩短至分钟级,轻松实现数百个网站的并行覆盖
- 透明可控:AI生成的代码完全开放,工程师可在内置IDE中查看、调试和优化脚本,在自动化与控制力之间找到最佳平衡
- 智能自愈:当目标网站结构变化时,系统自动检测并提示修复,一键重新生成即可恢复运行,将传统数小时的维护工作压缩至几分钟
- 企业级集成:自动生成RESTful API端点,支持定时调度、Webhook实时推送、云存储导出(S3/Azure/GCS),无缝对接企业数据仓库和BI系统
- 成本优化:按成功结果计费,配合弹性调度和高并发能力,在保证稳定性的同时有效控制采集成本
使用局限
- 依赖AI准确性:对于极端复杂或非常规的页面结构,AI生成的脚本可能需要人工介入优化
- 学习曲线:虽然降低了编码门槛,但有效描述复杂需求仍需要一定的业务理解和prompt技巧
典型应用场景:多品类电商数据采集、跨行业市场研究、大规模内容聚合平台、快速验证新业务数据需求的MVP场景。
如何为企业选择最优方案?
选择合适的数据采集方案,关键在于明确企业当前的技术能力、业务复杂度和扩展速度:
决策矩阵
|-----------------------|------------------------|--------------------|
| 业务场景 | 推荐方案 | 理由 |
| 需要快速获取主流平台标准化数据,无技术团队 | Web Scraper API | 零开发成本,即开即用 |
| 极致定制需求,拥有专业工程团队 | Web Scraper IDE | 代码级控制,无限灵活性 |
| 需要同时覆盖大量网站,追求效率与灵活性并重 | AI Scraper Studio ⭐ | AI加速开发,智能维护 |
| 初期用API,后期需扩展自定义逻辑 | API + AI Studio 组合 | 标准场景用API,特殊需求用AI生成 |
| 技术团队有限但需求快速增长 | AI Scraper Studio ⭐ | 降低技术门槛,加速迭代 |
写在最后:从"脚本维护"到"数据基础设施"
随着数据需求的不断增长,企业面临着前所未有的挑战------如何高效、稳定、可扩展地抓取来自不同平台的海量数据。传统的爬虫方式无法满足现代企业对速度、灵活性和可维护性的需求。而 AI Scraper Studio 的出现,正是为了解决这一问题。通过自然语言描述,AI 自动生成、调度并维护爬虫,企业不再需要耗费大量资源去编写、调试和更新脚本。这不仅极大地提升了数据采集的效率,也为企业建立了一个可持续、低成本、高效的数据采集基础设施。
无论是电商数据监控、SEO 关键词分析、竞品情报收集,还是行业情报获取,AI Scraper Studio 都能为企业提供灵活、可靠的解决方案。它不仅帮助企业节省了工程师的时间,也让业务团队能够更快地响应市场变化,抓取所需数据并快速做出决策。
因此,如果你希望在这个数据驱动的时代,打造一条高效、稳定且可扩展的生产级数据管道,AI Scraper Studio 将是你最佳的选择。通过智能化的数据采集流程,你将能够轻松实现业务增长和技术突破。
立即注册 Bright Data AI Scraper Studio 免费试用 https://get.brightdata.com/sd64v,体验最新 AI 驱动爬虫,每月可有 5000 次免费请求。别再让繁琐的脚本维护消耗你的企业资源,让 AI 重新定义你的数据采集方式!