本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在这里。
检索增强生成(Retrieval-Augmented Generation,RAG)框架通过融合从大型文档语料库中检索到的关键信息,显著提升了生成语言模型的能力。这种策略不仅增强了生成回答的准确性,还提高了其相关性。在本文中,我们将探讨如何在Langchain4j环境下有效利用RAG技术。
RAG的重要性
RAG技术通过将外部信息无缝融入生成流程,极大地提升了生成模型的效能。与传统方法不同,RAG不完全依赖于语言模型的预训练知识库,而是能够动态地从广泛的文档语料库中检索出相关信息,从而确保生成的回答不仅准确,还富含上下文信息。
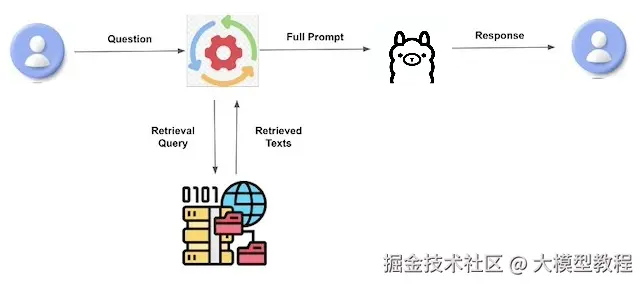
RAG不仅有效降低了模型产生幻觉的风险,还能够将模型原始训练数据中可能未涵盖的最新特定领域知识融入模型输出。通过缩小模型内静态知识与动态实时信息之间的鸿沟,RAG显著提升了生成响应的质量和可靠性,使其在那些对精确性和上下文敏感度要求极高的应用场景中显得尤为宝贵。
使用Langchain4j和Ollama3搭建的RAG系统中的关键组件
为了在Langchain4j和Ollama3框架下实现RAG,本文将关注以下几个核心组件:
1.EmbeddingStore:负责管理从文档中提取的嵌入向量。
2.EmbeddingStoreIngestor:负责将文档录入系统并生成相应的嵌入向量。
3.OllamaEmbeddingModel:用于从文本数据中生成嵌入词,为检索提供支持。
4.OllamaLanguageModel:利用检索到的数据生成精确且上下文相关的响应。
分步示例
首先,请确保你的Ollama3引擎已启动并正在运行。下面的文章将详细介绍这一过程: Getting started with langchain4j and Llama Model。
然后,在代码中添加以下依赖项:
xml
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-ollama</artifactId>
<version>0.33.0</version>
</dependency>接下来,假设我们的目标是向文本文件中添加新内容,具体来说,是定义一种适合出现在史诗奇幻作品《指环王》中的新异兽。
The Shadowmire is a mysterious and ancient creature that dwells in the darkest, most secluded swamps of Middle-earth.
It has the body of a large, sleek panther, but its fur is a deep, iridescent black that seems to absorb light.
Its eyes are a piercing emerald green, glowing with an eerie luminescence that can be seen from afar.
请将该文本文件保存在Maven项目资源目录下(或类路径中的任何位置),例如命名为dictionary.txt。
随后,我们开始编写代码,以便将这些信息集成到OllamaLanguageModel中。接下来,我们将构建一个提示,利用文本文件中的数据来查询模型。
ini
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.DocumentSplitter;
import dev.langchain4j.data.document.loader.FileSystemDocumentLoader;
import dev.langchain4j.data.document.parser.TextDocumentParser;
import dev.langchain4j.data.document.splitter.DocumentSplitters;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.input.Prompt;
import dev.langchain4j.model.input.PromptTemplate;
import dev.langchain4j.model.ollama.OllamaEmbeddingModel;
import dev.langchain4j.model.ollama.OllamaLanguageModel;
import dev.langchain4j.store.embedding.EmbeddingMatch;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.EmbeddingStoreIngestor;
import dev.langchain4j.store.embedding.inmemory.InMemoryEmbeddingStore;
import java.net.URL;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.time.Duration;
import java.util.List;
import java.util.Map;
public class RAGIngestor {
private static Duration timeout = Duration.ofSeconds(900);
public static void main(String args[]) throws Exception {
EmbeddingModel embeddingModel = OllamaEmbeddingModel.builder()
.baseUrl("http://localhost:11434")
.modelName("llama3")
.build();
EmbeddingStore embeddingStore = new InMemoryEmbeddingStore();
URL fileUrl = RAGIngestor.class.getResource("/dictionary.txt");
Path path = Paths.get(fileUrl.toURI());
Document document = FileSystemDocumentLoader.loadDocument(path, new TextDocumentParser());
DocumentSplitter splitter = DocumentSplitters.recursive(600, 0);
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.documentSplitter(splitter)
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
ingestor.ingest(document);
Embedding queryEmbedding = embeddingModel.embed("What is the Shadowmire ?").content();
List<EmbeddingMatch<TextSegment>> relevant = embeddingStore.findRelevant(queryEmbedding, 1);
EmbeddingMatch<TextSegment> embeddingMatch = relevant.get(0);
String information = embeddingMatch.embedded().text();
Prompt prompt = PromptTemplate.from("""
Tell me about {{name}}?
Use the following information to answer the question:
{{information}}
""").apply(Map.of("name", "Shadowmire","information", information));
// Initialize the language model for generating the response
OllamaLanguageModel model = OllamaLanguageModel.builder()
.baseUrl("http://localhost:11434")
.modelName("llama3")
.timeout(timeout)
.build();
String answer = model.generate(prompt).content();
System.out.println("Answer:"+answer);
}
}代码说明:
1.初始化嵌入模型:我们利用OllamaEmbeddingModel创建了一个与Ollama3服务相连的嵌入模型实例。
2.初始化嵌入存储:设置一个内存中的嵌入存储空间,用于存储文档的嵌入向量。
3.加载和解析文档:从文件系统加载文档,并将其解析成可处理的文本段。
4.分割文档:使用递归分割器将文档分解成更小的、易于管理的部分。
5.输入文档:为文档的每个片段生成嵌入向量,并将其存储在嵌入存储区。
6.创建查询嵌入:针对用户的查询内容,生成相应的嵌入向量。
7.检索相关信息:在嵌入存储中执行相似性搜索,以找到与查询嵌入向量相匹配的相关文本片段。
8.准备提示:结合检索到的信息和预设模板,构建一个完整的提示。
9.初始化语言模型:使用OllamaLanguageModel初始化一个生成模型,准备生成响应。
10.生成回复:根据准备好的提示,利用语言模型生成最终的响应内容。
执行上述代码后,系统经过几分钟的处理,该提示将返回生成的响应:

结论
通过融合检索式模型和生成式模型的优势,RAG结合Langchain4j和Ollama3提供了一种强有力的方法,以增强自然语言处理任务的准确性和相关性。本教程概述了实现RAG的基本框架,该框架可以根据特定的用例和数据集进行进一步的定制和扩展。
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在这里。