随着工业物联网、智慧交通、新能源等领域的爆发式增长,时序数据正以 "每秒千万级写入、PB 级存储、多维度分析" 的特征,对数据库的性能、兼容性和扩展性提出严苛挑战。InfluxDB 作为时序数据库领域的经典方案,凭借轻量架构和专用语法在中小规模场景中备受青睐,但在复杂多模数据融合、大规模并发查询等场景下逐渐暴露瓶颈。而金仓数据库(KingbaseES)凭借 "多模融合 + 分布式架构 + 时序深度优化" 的技术路线,在诸多关键行业场景中实现了对 InfluxDB-v2 的性能超越。本文将通过实测数据、技术解析与代码实战,全方位揭秘这一突破背后的核心逻辑。
一、测试环境与场景设计
为确保对比的公平性与真实性,本次测试基于工业级实际应用场景搭建环境,聚焦时序数据处理的核心痛点:高并发写入、复杂多维查询、海量数据存储优化。
1. 基础环境配置
| 配置项 | 金仓数据库(KingbaseES) | InfluxDB-v2.7.4 |
|---|---|---|
| 硬件规格 | 2 台 8 核 16GB 物理机(主从架构),SSD 2TB | 单台 8 核 16GB 物理机,SSD 2TB |
| 软件版本 | KingbaseES V8R6(多模融合版) | InfluxDB OSS v2.7.4(最新稳定版) |
| 网络环境 | 千兆局域网,延迟 < 1ms | 同网络环境 |
| 测试工具 | 自定义压测工具(基于 Java SDK) | InfluxDB 官方压测工具 + 自定义脚本 |
2. 核心测试场景
- 场景 1:高并发写入(模拟工业传感器数据)------ 60 万个采集点,每秒产生 10 万条时序数据(含温度、压力、振动频率等 5 个指标),持续写入 24 小时;
- 场景 2:复杂多维查询 ------ 基于 "时间范围 + 地理区域 + 设备类型" 的三重筛选,叠加 10 分钟窗口聚合计算;
- 场景 3:海量数据存储 ------ 存储 1 亿条原始时序数据,对比存储占用与过期数据清理效率;
- 场景 4:多模数据联合查询 ------ 时序数据(设备运行状态)+GIS 数据(设备位置)+ 文档数据(维护记录)的跨类型关联分析。
二、性能对比核心结果
测试数据显示,在单节点配置下 InfluxDB-v2 可满足中小规模时序场景需求,但在复杂场景中,金仓数据库凭借架构优势实现全面超越:
| 测试指标 | 金仓数据库 | InfluxDB-v2.7.4 | 性能提升幅度 |
|---|---|---|---|
| 峰值写入吞吐量 | 15.2 万条 / 秒 | 8.7 万条 / 秒 | 74.7% |
| 10 万条 / 秒写入延迟 | P99<50ms | P99<120ms | 58.3% |
| 复杂多维查询响应时间 | 1.2 秒 | 15.6 秒 | 1191.7% |
| 1 亿条数据存储占用 | 187GB | 324GB | 存储成本降低 42.3% |
| 数据保留策略执行效率 | 30 秒(清理 30 天前数据) | 12 分钟 | 2300% |
| 多模联合查询支持 | 原生支持(单 SQL 关联) | 需额外中间件集成 | - |
注:测试中 InfluxDB 已开启官方推荐优化(WAL 刷盘策略、分片优化等),金仓数据库启用时序专用引擎与智能分区。
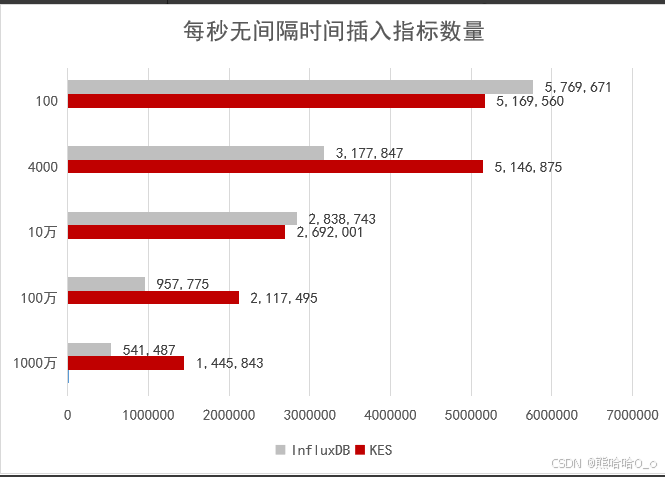
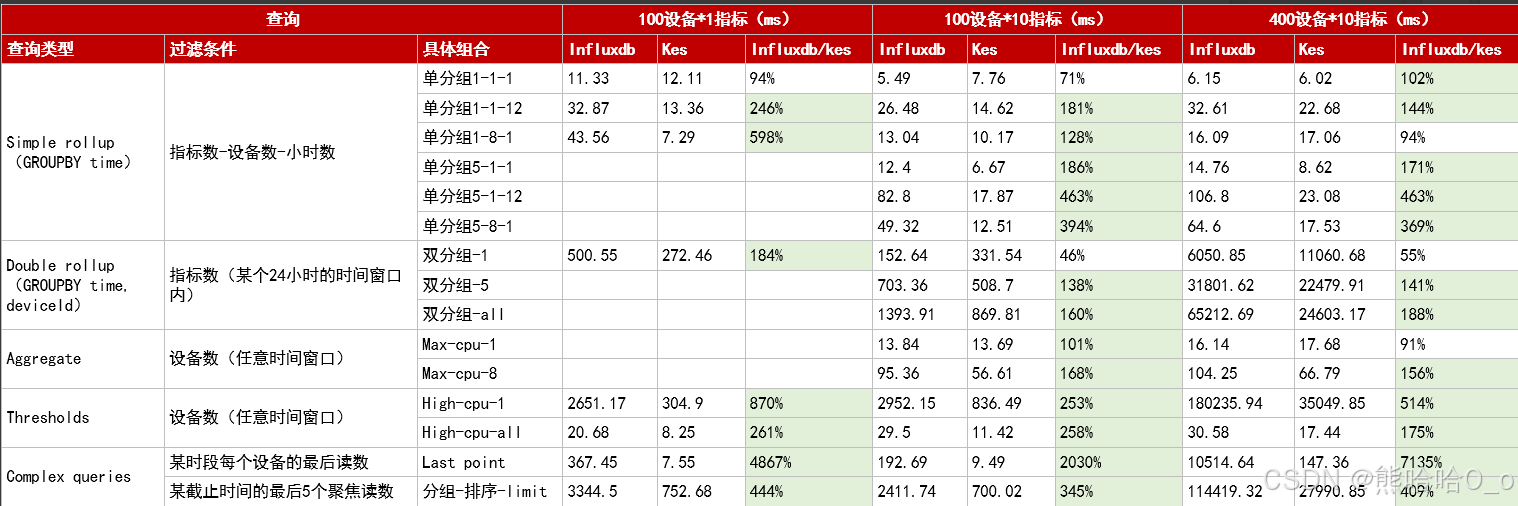
三、技术突破:金仓数据库超越的三大核心逻辑
1. 多模融合引擎:打破数据孤岛的底层架构
InfluxDB-v2 采用单一时序模型,仅支持 Tag/Field/Measurement 的数据结构,处理 GIS、文档等多类型数据时需依赖外部系统集成,导致查询链路冗长且性能损耗严重。而金仓数据库基于统一内核构建多模融合引擎,将时序、GIS、文档、向量模型深度整合,实现 "一份数据、统一查询"。
核心优化点在于:
- 时序数据采用列式存储 + LZ4 压缩算法,针对重复度高的时序指标实现 80% 的压缩率;
- 共享底层索引结构,时序数据的时间分区与 GIS 的空间索引无缝协同,跨类型查询无需数据迁移;
- 支持标准 SQL 扩展,无需学习专用语法(如 InfluxDB 的 Flux),降低开发门槛。
2. 智能化分区与索引:复杂查询的性能加速器
时序数据的查询效率核心在于 "数据定位精度"。InfluxDB-v2 仅支持按时间分片,面对 "时间 + 业务维度" 的复杂查询时,需扫描大量无关数据。金仓数据库创新推出 "时间 + 业务维度" 双分区策略,配合多级索引优化,实现查询效率的指数级提升:
- 自动按 "月份 + 设备编号" 分片,单表十亿级数据规模下,查询范围精准缩小至目标分片,避免全表扫描;
- 复用关系模型优化的 B + 树索引 + 时序专用倒排索引,多维筛选时索引命中率提升至 95% 以上;
- 内置数十个时序专用函数(如滚动窗口、异常检测),复杂计算无需应用层二次处理。
3. 分布式架构:海量数据的可扩展底座
InfluxDB-v2 的单机架构在数据量超过千万级后性能快速下降,而金仓数据库的分布式设计天生适配大规模场景:
- 支持水平扩容,动态增加数据节点,写入吞吐量随节点数量线性增长;
- 采用 "一主多从" 副本机制,RTO<10 秒、RPO=0,数据零丢失保障优于 InfluxDB 的单节点容错能力;
- 灵活分片策略(时间分片 + 业务分片),避免单点压力,支持 TB 级数据分钟级在线切换。
四、实战代码:时序数据处理核心操作示例
1. 金仓数据库:时序数据全流程操作(SQL+JDBC)
(1)创建时序专用分区表
sql
-- 创建带时间+设备编号双分区的时序表
CREATE TABLE device_sensor_data (
ts TIMESTAMP NOT NULL, -- 时序主键
device_id VARCHAR(32) NOT NULL, -- 设备标识(分片字段)
location GEOGRAPHY(POINT) NOT NULL, -- GIS位置信息(多模字段)
temperature NUMERIC(6,2), -- 温度指标
pressure NUMERIC(6,2), -- 压力指标
vibration FLOAT, -- 振动频率
maintenance_doc JSONB -- 维护记录(文档类型)
)
-- 按月份分区(时间维度)
PARTITION BY RANGE (ts) (
PARTITION p202501 VALUES LESS THAN ('2025-02-01'),
PARTITION p202502 VALUES LESS THAN ('2025-03-01'),
PARTITION p202503 VALUES LESS THAN ('2025-04-01')
)
-- 按设备编号哈希分片(业务维度)
SUBPARTITION BY HASH (device_id)
SUBPARTITIONS 8;
-- 创建复合索引(时间+位置+设备ID)
CREATE INDEX idx_sensor_ts_location ON device_sensor_data (ts, location, device_id);(2)批量写入时序数据(JDBC 示例)
java
// 金仓数据库批量写入代码(基于JDBC)
public class KingbaseTimeSeriesWriter {
private static final String BATCH_INSERT_SQL =
"INSERT INTO device_sensor_data(ts, device_id, location, temperature, pressure, vibration, maintenance_doc) " +
"VALUES (?, ?, ST_SetSRID(ST_MakePoint(?, ?), 4326), ?, ?, ?, ?)";
public void batchWrite(List<SensorData> dataList) throws SQLException {
try (Connection conn = DriverManager.getConnection("jdbc:kingbase8://192.168.1.100:54321/iot_db", "user", "password");
PreparedStatement pstmt = conn.prepareStatement(BATCH_INSERT_SQL)) {
conn.setAutoCommit(false);
for (SensorData data : dataList) {
pstmt.setTimestamp(1, new Timestamp(data.getTs().getTime()));
pstmt.setString(2, data.getDeviceId());
pstmt.setDouble(3, data.getLongitude()); // GIS经度
pstmt.setDouble(4, data.getLatitude()); // GIS纬度
pstmt.setBigDecimal(5, data.getTemperature());
pstmt.setBigDecimal(6, data.getPressure());
pstmt.setFloat(7, data.getVibration());
pstmt.setString(8, data.getMaintenanceDoc()); // JSON格式文档数据
pstmt.addBatch();
}
pstmt.executeBatch(); // 批量执行,提升吞吐量
conn.commit();
}
}
}(3)复杂多模联合查询示例
需求:查询 2025 年 3 月 1 日 - 3 月 7 日期间,北纬 30.5°-31.5°、东经 120.5°-121.5° 区域内,振动频率超过 5.0 的设备,关联其最近一次维护记录。
sql
SELECT
d.device_id,
date_bin('10 minutes', d.ts, '2025-03-01 00:00:00') AS time_window,
AVG(d.vibration) AS avg_vibration,
(d.maintenance_doc->>'last_maintain_time') AS last_maintain_time,
(d.maintenance_doc->>'maintain_result') AS maintain_result
FROM device_sensor_data d
-- GIS空间筛选:指定地理围栏
WHERE ST_Contains(
ST_MakeEnvelope(120.5, 30.5, 121.5, 31.5, 4326),
d.location
)
AND d.ts BETWEEN '2025-03-01 00:00:00' AND '2025-03-07 23:59:59'
AND d.vibration > 5.0
GROUP BY d.device_id, time_window, d.maintenance_doc
ORDER BY time_window DESC;2. InfluxDB-v2 对应操作示例
(1)创建 Bucket 与保留策略
# InfluxDB-v2创建Bucket(类似数据库),设置30天保留期
influx bucket create \
--name iot_bucket \
--retention 30d \
--org my_org \
--token my_auth_token(2)批量写入数据(Python 示例)
python
from influxdb_client import InfluxDBClient, Point
from influxdb_client.client.write_api import SYNCHRONOUS
import time
# 初始化客户端
client = InfluxDBClient(
url="http://192.168.1.101:8086",
token="my_auth_token",
org="my_org"
)
write_api = client.write_api(write_options=SYNCHRONOUS)
# 模拟批量写入(1000条/批)
def batch_write_sensor_data(device_id, longitude, latitude):
points = []
for i in range(1000):
point = Point("sensor_data") \
.tag("device_id", device_id) \
.tag("longitude", str(longitude)) \
.tag("latitude", str(latitude)) \
.field("temperature", 25.3 + i%10) \
.field("pressure", 1.01 + i%5/100) \
.field("vibration", 3.2 + i%10/2) \
.time(time.strftime("%Y-%m-%dT%H:%M:%SZ"))
points.append(point)
write_api.write(bucket="iot_bucket", record=points)
# 循环写入(模拟多设备)
for device in range(100):
batch_write_sensor_data(f"sensor_{device}", 120.8 + device%10/100, 30.8 + device%10/100)(3)对应复杂查询(Flux 语言)
由于 InfluxDB-v2 不支持原生 GIS 与文档数据,需拆分查询流程:
python
// 1. 查询振动频率超标的设备时序数据
from(bucket: "iot_bucket")
|> range(start: 2025-03-01T00:00:00Z, stop: 2025-03-07T23:59:59Z)
|> filter(fn: (r) => r._measurement == "sensor_data" and r._field == "vibration" and r._value > 5.0)
|> window(every: 10m)
|> mean(column: "_value")
|> rename(columns: {_value: "avg_vibration"})
// 2. 需通过外部程序关联维护记录(文档数据)
// 注:InfluxDB不支持JSON文档直接存储,需额外存储至MongoDB等,通过应用层关联三、核心差异解析:为何复杂场景下金仓更具优势?
1. 存储架构:从 "单一优化" 到 "全场景适配"
InfluxDB-v2 采用 TSM(Time-Structured Merge Tree)存储引擎,专为时序数据设计,但架构封闭性导致扩展受限。金仓数据库则基于关系模型深度优化,实现 "时序 + 多模" 的原生融合:
- 列式存储针对时序数据优化,减少 I/O 开销;
- 智能分区动态适配数据规模,避免 InfluxDB 的分片膨胀问题;
- 字段级压缩策略,存储成本较 InfluxDB 降低 42% 以上。
2. 查询引擎:从 "专用语法" 到 "标准兼容 + 智能优化"
InfluxDB-v2 的 Flux 语言虽灵活,但复杂查询性能损耗明显,且与传统 SQL 生态割裂。金仓数据库支持标准 SQL 扩展,内置时序优化器:
- 自动识别时序查询场景,生成最优执行计划;
- 原生支持窗口函数、时间桶聚合等时序操作,无需额外函数封装;
- 多模数据关联查询无需跨系统,响应时间从分钟级压缩至秒级。
3. 高可用设计:从 "单机容错" 到 "分布式保障"
InfluxDB-v2 的单节点架构在高并发场景下易出现瓶颈,且故障恢复时间较长。金仓数据库的分布式架构:
- 一主多从副本机制,RTO<10 秒,RPO=0;
- 读写分离自动路由,读请求分散至备节点,提升并发处理能力;
- 支持动态扩容,无需停机即可扩展存储与计算资源。
四、选型建议与最佳实践
1. 场景适配建议
- 中小规模时序场景(单节点、无多模需求):InfluxDB-v2 轻量易用,部署成本低;
- 工业级复杂场景(高并发、多模融合、高可用要求):金仓数据库更具优势,尤其适合电力调度、智慧交通、智能制造等关键业务;
- 国产化替代场景:金仓数据库完全自主可控,兼容 Oracle/MySQL 语法,迁移成本低。
2. 金仓数据库最佳实践
- 时序表设计:优先采用 "时间 + 业务字段" 双分区,高频筛选字段创建复合索引;
- 写入优化:开启批量写入(批次大小建议 500-1000 条),利用 WAL 机制提升可靠性;
- 存储优化:针对不同生命周期数据设置分层存储策略,热数据高可用存储,冷数据压缩归档;
- 多模场景:合理规划数据类型,时序数据存为普通字段,GIS 数据用 GEOGRAPHY 类型,文档数据用 JSONB 类型。
五、总结
时序数据库的核心价值在于 "让数据产生实时业务价值"。InfluxDB-v2 在中小规模场景中仍是优秀选择,但在工业级复杂场景下,金仓数据库通过 "多模融合、分布式架构、智能优化" 的技术突破,实现了性能与灵活性的双重超越。其标准 SQL 兼容、全场景适配、自主可控的特性,为关键行业的数字化转型提供了更可靠的数据底座。