开源界又来了一位重量级新成员!小米今天正式推出并开源其最新模型 MiMo-V2-Flash。
该模型采用专家混合架构(MoE),总参数量达 3090 亿,活跃参数为 150 亿,性能表现足以与当前顶尖开源模型 DeepSeek-V3.2、Kimi-K2 等媲美。

此外,MiMo-V2-Flash 的代码遵循 MIT 开源协议,基础模型权重已同步上传至 Hugging Face 平台供公开使用。
更多AI大模型学习视频及资源,都在智泊AI。

抛开"开源"不谈,新模型的核心突破就是架构设计的颠覆性革新,实现150 tokens/秒的推理速度,并将成本控制在每百万token输入0.1美元、输出0.3美元,以极致性价比为最大卖点。(还得是小米!)
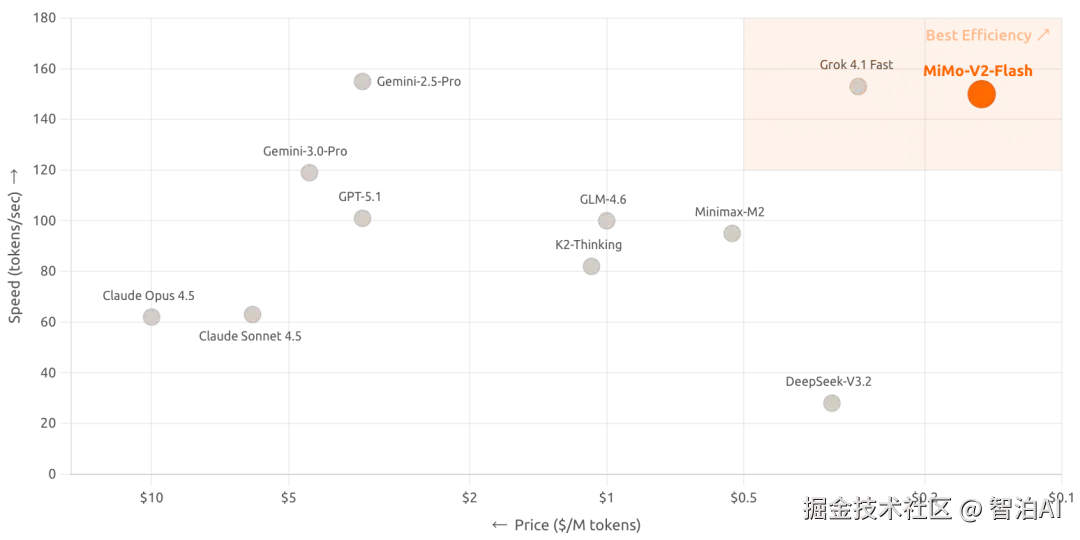
根据官方体验页面信息,MiMo-V2-Flash 还具备深度思考和联网搜索能力,不仅可用于日常对话交流,还能在获取实时数据、追踪最新动态或验证资料时发挥作用。

开源模型新标杆,MiMo-V2-Flash 跑分全线开花
性能表现方面,MiMo-V2-Flash的测试数据如下:
在AIME 2025数学竞赛与GPQA-Diamond科学知识测试中,该模型均位列开源模型前两名。
而且编程能力很突出!SWE-bench Verified测试以73.4%的得分率碾压所有开源模型,逼近GPT-5-High水平。该测试要求AI修复真实软件漏洞,73.4%的成功率充分证明其可应对绝大多数实际编程挑战。
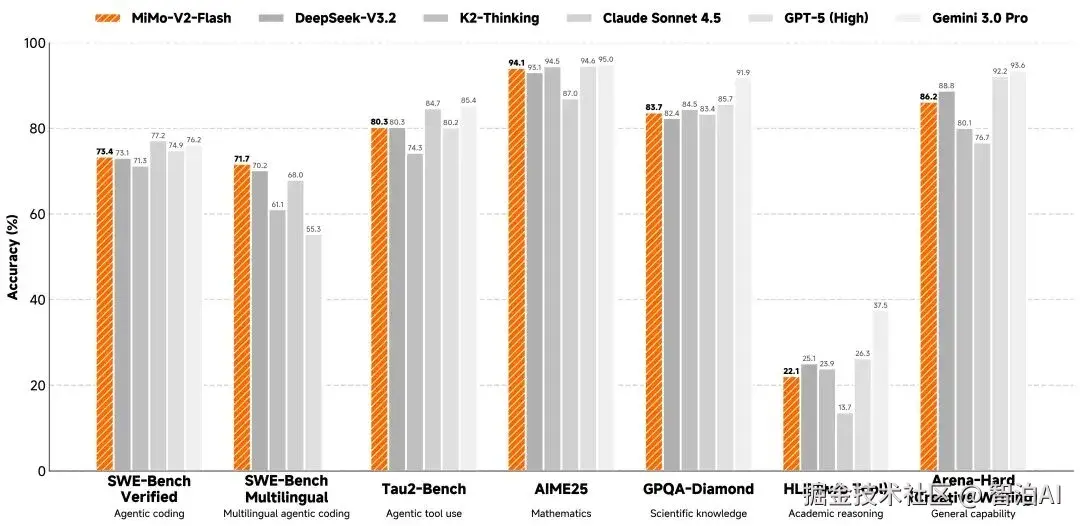
多语言编程基准测试表现
在SWE-Bench Multilingual的评估中,MiMo-V2-Flash展现出71.7%的代码问题解决率。
智能体任务性能分析
τ²-Bench分类得分:
通信领域以95.3分领先,零售类达79.5分,航空类为66.0分。
搜索代理能力:
BrowseComp初始得分45.4,通过上下文管理优化后显著提升至58.3分。
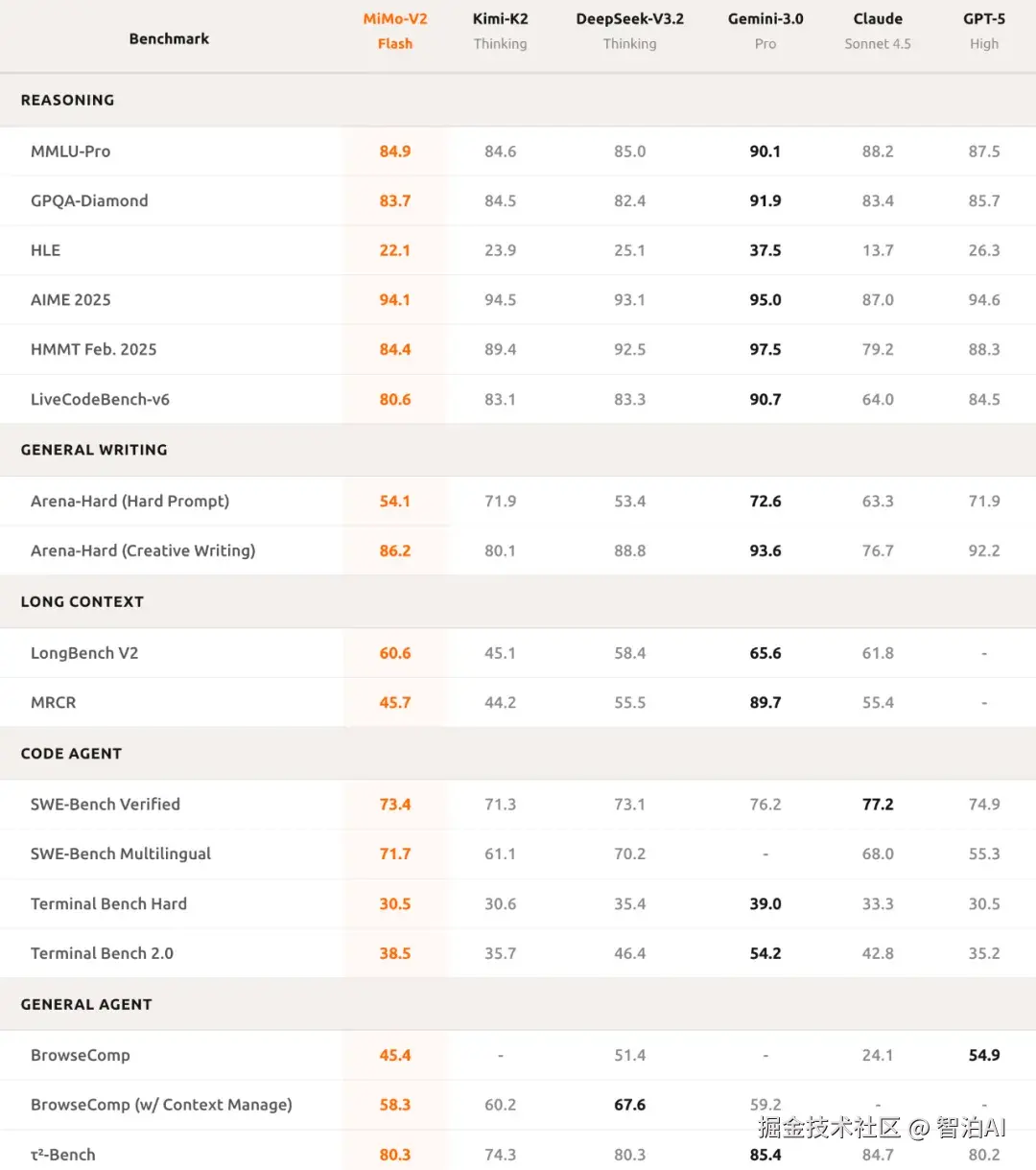
实验数据表明,MiMo-V2-Flash 不仅具备代码生成能力,更能深入解析复杂任务逻辑,实现多轮智能体协同交互。其写作质量媲美顶尖闭源模型,进一步验证了该模型不仅是高效工具,更能胜任日常辅助角色。
在维持长文本处理性能的前提下,MiMo-V2-Flash 显著降低了成本,这一突破源于两项关键技术革新:
混合滑动窗口注意力机制:传统大模型采用全局注意力机制时,计算复杂度呈二次增长,KV 缓存存储需求也随之激增。
创新架构设计:通过采用5:1的激进分层策略(5层滑动窗口注意力与1层全局注意力交替运行),滑动窗口仅聚焦128个token。该方案使KV缓存存储量缩减约6倍,同时完整保留了256k上下文窗口的长文本处理能力。
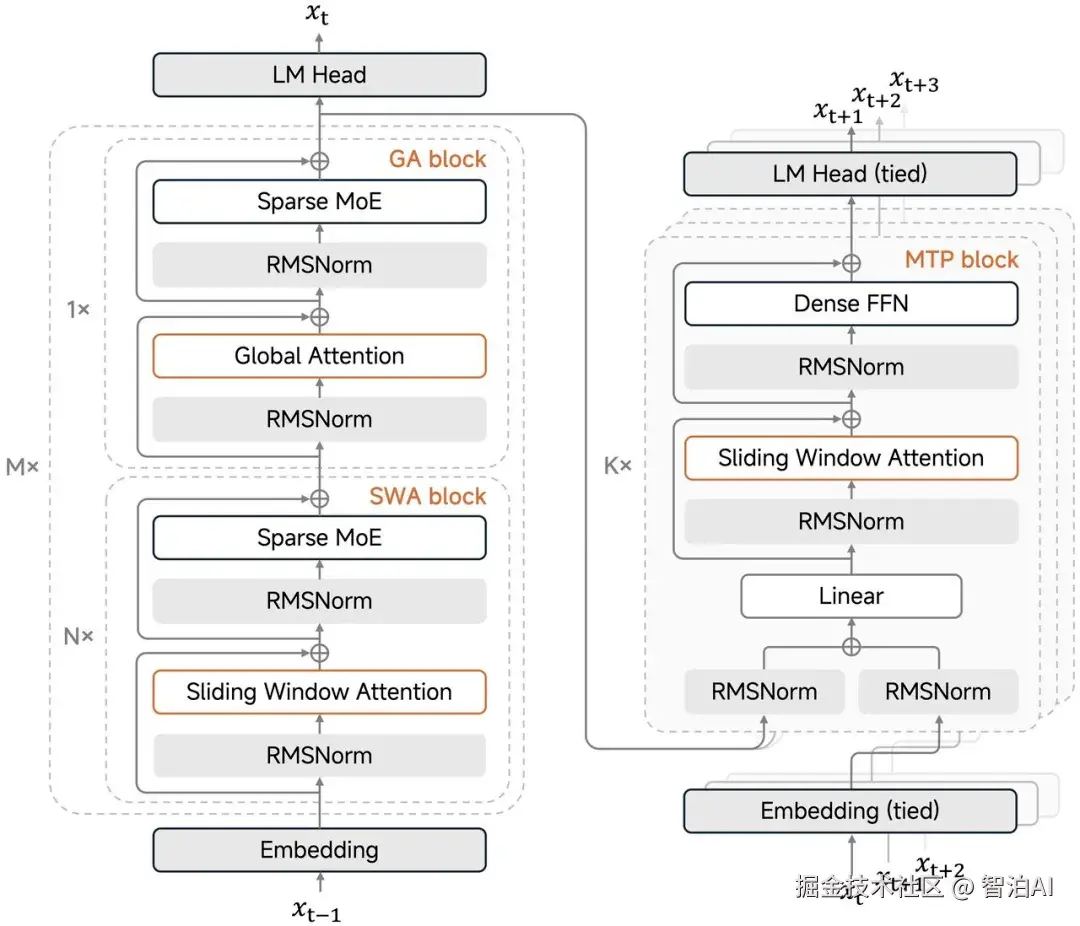
尽管采用如此激进的窗口配置,模型仍能保持长文本处理的稳定性。罗福莉在社交媒体上揭示了一个违反直觉的结论:窗口尺寸128被验证为"最优甜点值"。
实验数据显示,过度扩展窗口(例如提升至512)将直接引发性能衰减。此外,她明确强调,在该机制的应用过程中,sink values的保留对性能维持至关重要,任何情况下均不可省略。

这项创新技术名为轻量级多Token预测(MTP)。传统文本生成模型每次仅能输出一个Token,如同逐字输入的打字机。而MiMo-V2-Flash凭借其内置的MTP模块,可同步预测后续多个Token,实现"一猜多词"的高效输出。
实际测试显示,该技术平均每次可处理2.8至3.6个Token,推理效率提升达2至2.6倍。其优势不仅体现在推理环节,还能优化训练过程中的采样速度,降低GPU闲置率,达成训练与推理的双重加速效果。
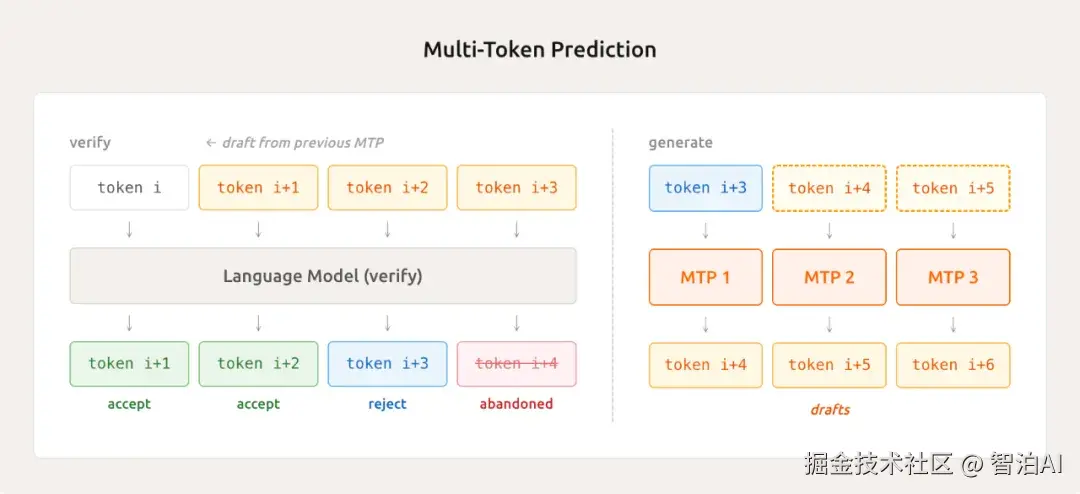
罗福莉指出,采用三层MTP架构时,实验数据显示平均接受长度突破3,编码效率提升至原有水平的2.5倍。该方法显著改善了小批量On-Policy强化学习场景中因"长尾样本"导致的GPU资源闲置问题。
所谓长尾样本,即那些复杂度高、耗时长的任务,会阻塞后续任务执行,导致GPU处于等待状态。MTP技术通过创新机制解决了这一瓶颈,实现资源利用率的大幅提升。
同时罗福莉说明,由于项目周期限制,当前尚未完成MTP与RL训练循环的全面整合,但两者在架构设计上具有高度兼容性。小米已开放三层MTP的源代码,开发者可将其直接应用于实际项目中进行二次开发。
算力只用 1/50,性能如何不打折?
预训练阶段
新模型采用FP8混合精度训练框架,在规模达27万亿token的数据集上完成训练,并原生支持32k超长序列处理。FP8混合精度通过压缩数值位宽实现高效计算,在显著降低显存占用的同时维持模型精度,当前行业应用较少,需对底层计算架构进行针对性优化。
后训练阶段
小米团队创新性地开发了多教师在线策略蒸馏(MOPD)方法。传统监督微调结合强化学习的训练管线存在训练波动大、计算资源消耗高等缺陷。MOPD的核心机制是:通过学生模型自主采样策略分布,由多专家教师网络对每个token实施高密度奖励反馈,从而提升训练效率与稳定性。
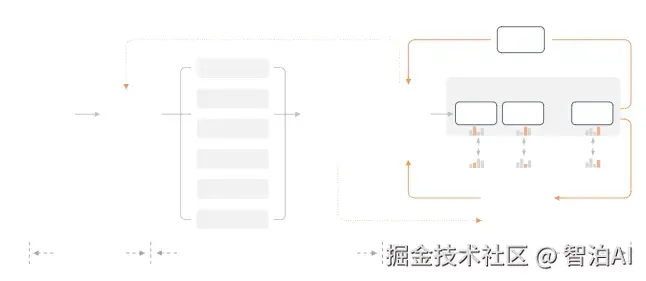
通俗来讲,学生模型就像在实时完成作业,教师模型会对每个字即时打分,无需等待整篇作业提交。这种机制让学生模型能快速吸收教师模型的精华,同时训练过程更加稳定。
最惊人的是效率突破。MOPD仅需传统方法1/50的算力,就能让学生模型达到教师模型的性能巅峰。这使得小米能够以更低的资源消耗实现更快速的模型迭代。
此外,MOPD具备动态接入新教师的能力,成长后的学生模型可反向担任教师角色,构建"教学相长"的闭环进化系统。今天的学员、明天的导师、后天培养出更优秀的学生,这种层层递进的强化机制确实颇具创新性。
正如罗福莉所述,团队基于Thinking Machine的On-Policy Distillation方法论,通过融合多个强化学习模型,实现了效率的显著提升。这不仅建立了自我强化的循环系统基础,更使得学生模型能持续进化,最终超越教师模型的能力边界。
在智能体强化学习领域扩展方面,小米MiMo-V2-Flash研究团队通过真实GitHub issue构建了规模达10万+的可验证任务体系。其自动化流水线部署于Kubernetes集群环境,支持最高10000+ Pod并发运行,实现70%的环境部署成功率。
针对网页开发场景的创新设计体现在多模态验证机制上,采用动态视频录制替代传统静态截图验证,有效规避视觉误差问题,精准保障代码执行准确性。该模型与开发者生态的兼容性表现突出,可无缝集成Claude Code、Cursor、Cline等主流开发工具,凭借256K超长上下文窗口容量(相当于一部中篇小说或数十页技术文档的文本量),支持数百轮智能体交互与复杂工具调用流程的稳定执行。
技术开源方面,小米不仅将完整推理代码贡献至SGLang项目,还通过LMSYS博客公开了深度优化经验。技术报告披露了全量模型参数细节,包含MiMo-V2-Flash-Base在内的所有模型权重均通过Hugging Face平台以MIT协议开放。这种程度的开源实践在国内头部科技企业中具有显著突破性。当前该模型已在API Platform提供限时免费服务,开发者可立即接入实际开发环境进行体验验证。

小米的 AI 野心,不止于手机助手
MiMo-V2-Flash的推出,展现了小米在AI领域的战略布局全面升级。
据罗福莉在社交媒体披露的最新动态,"MiMo-V2-Flash现已开放使用。这仅是我们在AGI发展路径中的第二个里程碑。" 仅第二步便已具备如此突破性,后续的技术演进更令人充满想象空间。
小米的技术文档同时指出,当前MiMo-V2-Flash性能仍领先闭源模型存在提升空间。但企业战略清晰可见:将通过扩展模型参数与计算资源投入持续优化性能边界,同步推进更可靠、更敏捷的智能体框架研发。

在MOPD框架中,教师模型与学生模型通过双向迭代实现协同进化,为后续的性能拓展保留了充分潜力。从战略层面审视,这标志着小米对AI生态体系的一次关键布局。面对手机、IoT设备与智能汽车构成的硬件矩阵,小米亟需一个支撑全域的AI核心架构,而MiMo-V2-Flash正是为此战略需求打造的基座型解决方案。
正如2011年小米手机以1999元颠覆旗舰机定价体系,当前MiMo-V2-Flash凭借极致的成本控制与73.4%的SWE-Bench基准表现,正在重塑开源大模型的价值标杆。这场技术上的革新,无疑迎来了开源领域小米的爆发时刻。
更多AI大模型学习视频及资源,都在智泊AI。